2_paddleOCR训练自己的模型
paddleOCR模型训练&评估&测试教程
目录
paddleOCR模型训练&评估&测试
下载工具安装及使用
下载迅雷
使用迅雷下载文件
文本检测模型
资料准备
下载数据集
下载标注文件
组织数据集路径
开始训练
下载预训练模型
组织预训练模型路径
确定配置文件路径
修改配置文件1
修改配置文件2
开始训练
模型评估
修改配置文件
指定评估的数据集和标签路径
进行评估
模型测试
修改配置文件
进行模型测试
文本识别模型
资料准备
下载数据集
下载标注文件
组织数据集路径
准备字典集
开始训练
下载预训练模型
组织预训练模型
确定配置文件路径
修改配置文件1
修改配置文件2
开始训练
模型评估
修改配置文件
指定评估的数据集和标签路径
进行评估
模型测试
修改配置文件
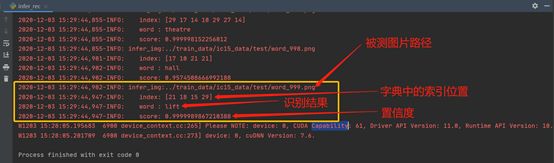
进行模型测试
下载工具安装及使用
下载迅雷
下载地址:https://www.xunlei.com/

使用迅雷下载文件
步骤1:打开迅雷软件,单击“+”图标。

步骤2:弹出如下对话框,将下载链接复制到对话框中,完成下载

例如:下载“icdar2015标注文件”:

文本检测模型
本文以icdar2015数据集为例,介绍PaddleOCR中检测模型的训练,评估和测试。
资料准备
下载数据集
icdar2015数据集可从官方网站(https://rrc.cvc.uab.es/?ch=4&com=downloads)下载,需先注册,下载后只使用图片集,不采用配套的标注文件,标注文件的获取见下节。

下载界面

数据集形式
下载标注文件
使用迅雷软件,下载标注文件,下载连接如下:
https://paddleocr.bj.bcebos.com/dataset/train_icdar2015_label.txt
https://paddleocr.bj.bcebos.com/dataset/test_icdar2015_label.txt
标注文件形式如下:

组织数据集路径
按照如下形式将数据集和标注文件放置在PaddleOCR目录中,分别是两个文件夹和两个文件。
按照如下形式将数据集和标注文件放置在PaddleOCR目录中,分别是两个文件夹和两个文件。

开始训练
下载预训练模型
PaddleOCR的检测模型当前支持3个主干,即MobileNetV3,ResNet18_vd和ResNet50_vd,可以根据需要使用PaddleClas中的模型替换主干,使用迅雷软件,下载预训练模型文件,下载连接如下:
| MobileNetV3预训练模型连接: https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV3_large_x0_5_pretrained.tar ResNet18_vd预训练模型连接: https://paddle-imagenet-models-name.bj.bcebos.com/ResNet18_vd_pretrained.tar ResNet50_vd预训练模型连接: https://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_vd_ssld_pretrained.tar |
组织预训练模型路径
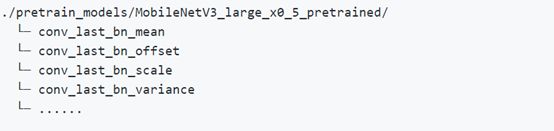
按照如下形式将解压后的预训练模型放置在PaddleOCR目录中
确定配置文件路径
打开program.py脚本,找到class ArgsParser构造函数,修改为如下形式(注意相对路径填写正确):

修改配置文件1
在config/det文件夹下找到det_mv3_db_v1.1.yml文件,只需要将“pretrain
_weights”指定为2.2.1节获取的预训练模型路径。
(注意相对路径填写正确,“./ ”表示同级目录,“../”表示上级目录,“../../”表示上上级目录,以运行的.py文件为当前路径)
若电脑性能不足,将配置文件中“train_batch_size_per_cart”修改为2。

修改配置文件2
在config/det文件夹下找到det_db_icdar15_reader.yml文件,将下图所示的四个路径正确填写。

开始训练
运行train.py脚本,始模型训练,训练界面如下:
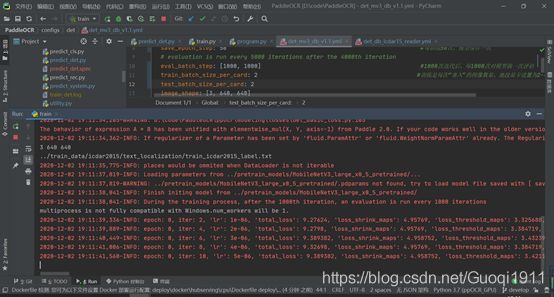
训练结果保存在文件“./output/det_db/”文件夹下,如下图所示:

模型评估
PaddleOCR有三个用于评估OCR检测任务性能的指标:Precision,Recall和Hmean。
修改配置文件
假设模型训练结果如下,在det_db文件夹下,我们使用训练400代的模型对测试集做评估,查看训练效果。

打开“det_mv3_db_v1.1.yml”文件,指定“checkpoints”为400代训练后的模型(注意:在对模型做评估时,“infer_img”要为空,否则报错,未详阅代码,原因暂时不详!!!)。

指定评估的数据集和标签路径
参考2.2.5节内容,在det_db_icdar15_reader.yml文件中,EvalReader字段下设置评估的数据集和标签文件路径。
进行评估
运行“eval.py”脚本,在控制台会打印出Precision,Recall和Hmean测试结果。

模型测试
修改配置文件
假设模型训练结果如下,在det_db文件夹下,我们使用训练400代的模型对测试集做检测,查看训练效果。

打开“det_mv3_db_v1.1.yml”文件,
- 指定“checkpoints”为400代训练后的模型;
- 指定“infer_img”为测试集路径(注意相对路径的书写格式)。

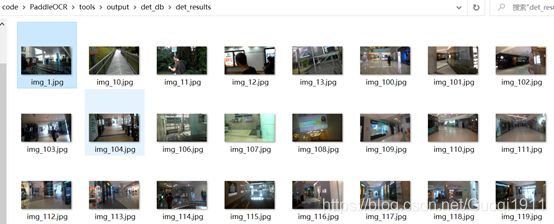
进行模型测试
运行脚本“infer_det.py”文件,开始对指定路径下的图片做检测,检测结果保存在“./output/det_db/det_results/”文件夹下,如下图所示:
文本识别模型
资料准备
下载数据集
登录官方网站icdar2015上(https://rrc.cvc.uab.es/?ch=4&com=downloads),需要注册后才可下载,下载后只需要图片文件,自带的标注文件不需要。



数据集如下所示:
下载标注文件
使用迅雷软件,下载标注文件,下载连接如下:
| 训练集标注文件下载链接: https://paddleocr.bj.bcebos.com/dataset/rec_gt_train.txt 测试集标注文件下载链接: https://paddleocr.bj.bcebos.com/dataset/rec_gt_test.txt |
标注文件形式如下,注意按照实际情况修改标注文件中存放图像的文件夹名称。
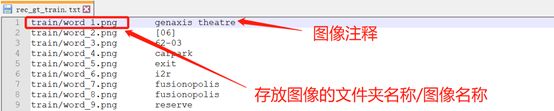
组织数据集路径
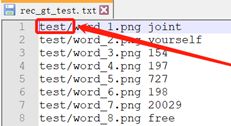
将数据集和标间文件放置在“./train_data/ic15_data/”文件夹下,共两个文件夹两个文件,形式如下所示:

训练数据集标注文件,注意测试数据集存放在“train”文件夹下,标注文件要做响应修改,否则训练时提示找不到图片。

准备字典集
最后,需要提供字典({word_dict_name} .txt),以便在训练模型时,可以将出现的所有字符映射到字典索引。
因此,词典需要包含所有您希望正确识别的字符。{word_dict_name} .txt必须以以下格式编写并以utf-8编码格式保存:

源码提供了众多的字典集,无特殊需要,不需要自己组织字典集,字典集存储路径如下:
| 存储路径 |
说明 |
| ppocr/utils/ppocr_keys_v1.txt |
是具有6623个字符的中文词典。 |
|
|
是一本具有63个字符的英语词典 |
|
|
是一本具有118个字符的法语词典 |
|
|
是日本字典,有4399个字符 |
|
|
是韩文字典,有3636个字符 |
|
|
是一本具有131个字符的德语词典 |
开始训练
下载预训练模型
首先下载预训练模型,您可以下载训练后的模型以对icdar2015数据进行训练。
使用迅雷软件,下载预训练模型,下载连接如下:
| https://paddleocr.bj.bcebos.com/rec_mv3_none_bilstm_ctc.tar |
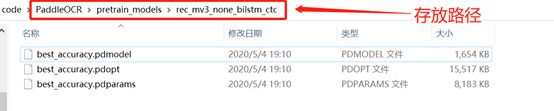
组织预训练模型
按照如下形式将解压后的预训练模型放置在PaddleOCR目录中:
确定配置文件路径
打开program.py脚本,找到class ArgsParser构造函数,修改为如下形式(注意相对路径填写正确):

修改配置文件1
在config/rec文件夹下找到rec_icdar15_train.yml文件,只需要将“pretrain_ weights”指定为3.2.1节获取的预训练模型路径
(注意相对路径填写正确,“./ ”表示同级目录,“../”表示上级目录,“../../”表示上上级目录,以运行的.py文件为当前路径)
若电脑性能不足,将配置文件中“train_batch_size_per_cart”修改为20。

修改配置文件2
在config/det文件夹下找到rec_icdar15_reader.yml文件,将下图所示的四个路径正确填写。
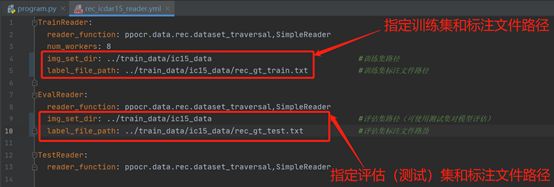
开始训练
运行train.py脚本,始模型训练,训练界面如下:

训练结果保存在文件“./output/rec_CRNN/”文件夹下,如下图所示:
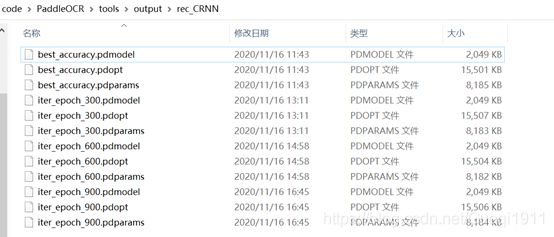
模型评估
修改配置文件
假设我们对3.2.6节训练的模型做评估,查看训练效果,查看./output/rec_CRNN文件夹下,会发现最终模型训练次数为900代,我们对该模型做评估

打开“rec_icdar15_train.yml”文件,指定“checkpoints”为900代训练后的模型(注意:在对模型做评估时,“infer_img”要为空,否则报错,未详阅代码,原因暂时不详!!!)。

指定评估的数据集和标签路径
参考3.2.5节内容,在rec_icdar15_reader.yml文件中,EvalReader字段下设置评估的数据集和标签文件路径。
进行评估
运行“eval.py”脚本,运行界面如下,评估结果:精度为0.68,评估样本数:2077,正确识别数:1414.

模型测试
修改配置文件
假设模型训练结果如下,在rec_RCNN文件夹下,我们使用训练900代的模型对测试集做检测,查看训练效果。
打开“rec_icdar15_train.yml”文件,
- 指定“checkpoints”为900代训练后的模型;
- 指定“infer_img”为测试集路径(注意相对路径的书写格式)。

进行模型测试
运行脚本“infer_rec.py”文件,开始对指定路径下的图片做检测,检测结果显示在控制台上,如下图所示