谷歌云计算平台GCP介绍
云计算的概况
国内外多个大厂都提供了自己的云计算平台,包括亚马逊的AWS,微软的Azure,Google的GCP(Google Cloud Platform),国内的有腾讯云,阿里云,华为云等。对于国际大公司来说,要想给全球用户一个良好的产品使用体验(低延迟),必然要在全球主要节点部署机房,构建数据中心。对于小公司来说,没有这个财力进行全球部署,大公司从中看到了商机,既然小公司有这个需求、自身也为此维持了相当的人力成本,那为何不多部署一些,分隔成可精确计费的服务(IaaS,PaaS,FaaS),然后售卖给小公司呢?AWS等云计算平台可以做到按请求次数、计算资源使用时间(100毫秒)来计费。
这样一来,云计算平台上面既运行着自家的产品,也对外提供计算、存储、网络、机器学习、大数据分析处理等各种能力与服务。打开手机QQ,初始界面下方有一行字“腾讯云提供计算服务”。从2017年开始,腾讯要求内部服务都逐渐迁移到腾讯云上面,迁移的过程总是缓慢的,但是一旦上云上就再也不想回去了。在以前,升级一个公众号消息发送服务(有100多台8核8GB内存机器)需要花费小半天:先将待升级的机器上面的流量切走,开始升级,升级完之后观察没有问题后再接入流量,为避免将剩余的机器压爆,每次升级的时候最多升总量的10%~15%。这样来回切,费时费力。以容器和K8S为代表的先进技术出现后,服务的扩容、缩容、升级基本不再花费开发的额外精力。
云计算平台的全球市场占有份额分布如下(Canalys 2020年5月统计数据):AWS(32%)、微软Azure(17%)、谷歌云(6%)、阿里云(6%),剩下的是一些其他云计算平台,包括IBM、Oracle、华为云、腾讯云等。国内市场占用份额分布如下(Canalys 2020年 Q1数据):阿里云 44.5%、华为云 14.1%、腾讯云 13.9%、百度云 8.6%。
计算、存储、网络是云计算平台提供的三个最基本的服务,称之为基础架构(IaaS),就像一个城市的水、电、公共交通,当从自建的数据中心迁移上云,首先想到的就是这些基础设施。但是光有这些还是不够,优秀的云提供商,还会提供各种PaaS、FaaS服务,例如,客户只负责选择需要的计算节点个数,剩下的由云计算平台负责搭建和维护K8S集群。更进一步,客户只需要写事件触发函数(Function),完全不用关心后面需要多少计算资源,如何做负载均衡,如何配置网络拓扑等。
机房选址、硬件服务器资源购买、网络设置、多机房异地容灾、全球负载均衡、边缘计算节点部署、防止网络攻击(例如DDoS),对小公司、初创公司或者个人开发者,几乎是不可能完成的事情,对大公司来说,这些都已经做过一遍了,是现成的。有买方,有卖方,生意就这样做起来了。
NIST对云计算(Cloud Computing)的定义
-
按需自助服务:只需使用一个简单的界面,就可以获得所需的计算能力、存储和网络,而无需人工干预。
-
广泛的网络接入:可以从任何想要的地方通过网络访问这些资源。
-
资源池:这些资源的提供者拥有一个很大的资源池,并将其分配给该资源池之外的客户。通过批量购买获得规模经济,并将节省下来的钱转嫁给使用者,资源使用者不必知道或关心这些资源的确切物理位置。
-
资源可快速伸缩:可以快速的进行资源的扩容和缩容。
-
服务可度量:只为使用的服务计费,停止服务则停止计费。
接下来从以下几方面介绍一下Google的GCP:
-
IAM(Identity And Access Management)与资源管理
-
网络
-
计算
-
存储与数据库
-
App Engine、GKE与Cloud Function
-
Stackdriver
-
数据处理、大数据分析与机器学习
IAM与资源管理
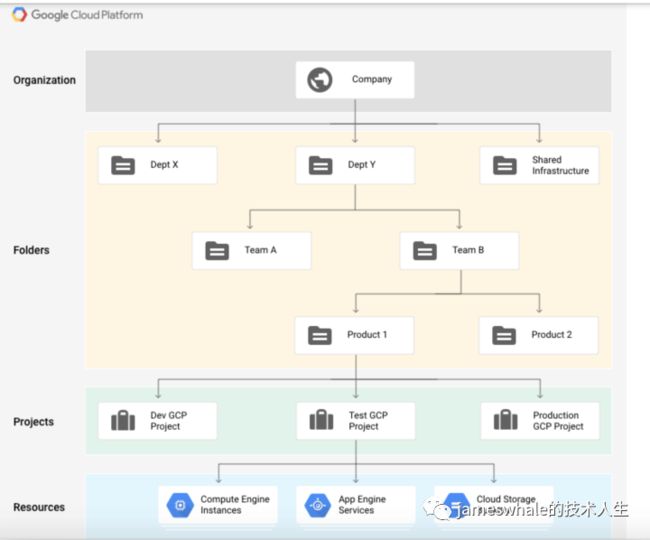
Google Cloud 资源层次结构与传统操作系统中的文件系统类似,能够以分层方式组织和管理实体。每项资源有且仅有一个父项。通过这种分层化的资源组织方式,可以对父资源设置访问权限控制政策与配置设置,并且子资源可以继承这些政策与 Identity and Access Management (IAM) 设置,子节点策略不能限制已经在父层节点授予的访问权限:
-
Organization: Organization是顶层节点,没有父节点,代表整个组织,管理者多个部门Folder,包含所有计费账号。
-
Folders: Folder管理者Project,为了管理方便,会有多个层级的Folders,例如,一个产品Folder管理者多个Project,一个团队Folder管理者多个产品Folder。一个部分Folder管理者多个团队Folder。
-
Project: 管理Resource中资源,包括资源的访问与授权、配额管理、计费等,一个Project关联一个计费账号,每个Project可以创建最多5个VPC(Virtual Private Cloud)网络。通过配额管理,可以防止因错误或者恶意攻击导致的资源滥用和费用突增,可以强制进行资源控制和周期review。
-
Resource: 包括计算、网络、存储、App Engine、GKE等资源,一个资源只能属于一个且只能是一个Project。根据作用范围不同,分为Global、Regional、Zonal,如下图所示:
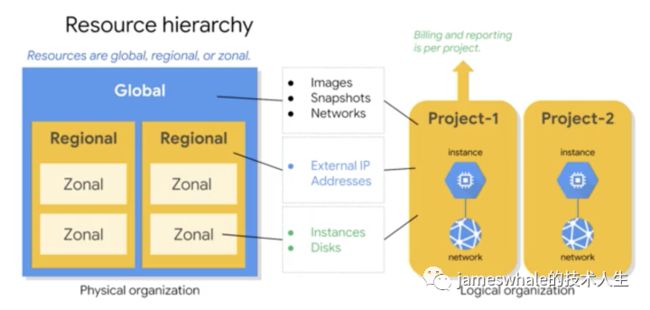
Organization、Folder、Project、Resource关系图:
三种类型的IAM Roles:
-
Primitive: IAM Primitive Roles适用于一个Project中所有的GCP服务,提供了固定的、粗粒度的访问控制,包括Owner、Editor、Viewer和Billing Administrator,Owner有Editor的所有权限,Editor有Viewer的所有权限,Billing Administrator有管理账单和增删管理者的权限,具体如下图所示:

-
Predefined:IAM Predefined Roles适用于一个Project中具体的某一个GCP服务,针对具体服务提供了较细粒度的许可控制,比如InstanceAdminRole包括的compute.instance.start, compute.instance.stop, compute.instance.list等许可。
-
Custom: IAM Custom Roles可以按照要求定义一组许可列表。
服务账户
服务账户提供了服务与服务之间进行交互的一个标识,是一个email地址,例如,[email protected],有三种类型的服务账户:
-
自定义服务账户,包括Predefined Roles。
-
默认服务账户,Compute Engine和App Engine都有默认的服务账户,包括IAM Primitive和Predefined Roles。
-
Google API 服务账户,代表调用方运行内部Google进程。
它有如下2个好处:
-
运行在Compute Engine实例中的程序能够自动获得有效的Access Token。
-
Access Tokens可用于访问Project中的任意服务API和授权给此服务账户的任意服务。
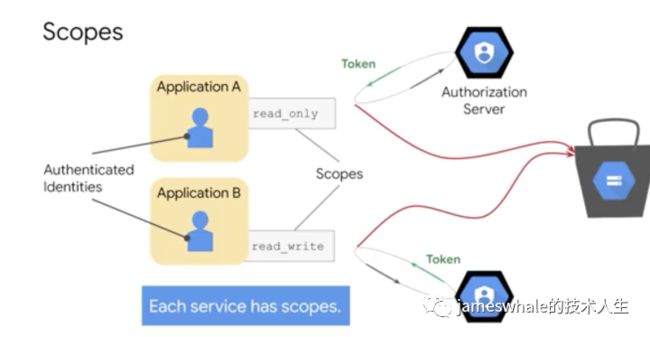
可以通过如下两种方式管理服务账号认证所需的Key:
-
GCP-managed: 不可以下载,可以自动轮换。
-
User-managed:自行创建、管理、轮换。
网络
GCP中很重要的一个概念是VPC,即Virutal Private Cloud,通过此来隔离云上的多个使用者,它是一个全球网络,包括如下元素:
-
Virtual machines(VMS): 在一个物理机器上面通过虚拟机技术(VMM/Hypervisor)可以虚化出多个VM,提高资源的利用率。云计算中的Compute Instance是以VM为粒度的。

-
Zone: Zone可以理解成机房,但是和机房不是一一对应的。
-
Region: 一个VPC包括至少一个Region, 一个Region至少包括2个Zone,Region之间至少相距160KM,通过专线连接,确保低延迟。在多个Region中部署相同的业务,当一个Region失效后,其他Region可以继续工作,进一步提高了业务的容灾能力。Region内部通过TCP/UDP协议来实现负载均衡,多个Region之间通过http/https协议来实现负载均衡,可以支撑全球的业务发展,业务只需对外暴露一个IP,极大简化了网络层次。
-
Subnetwork: 可以跨越多个Zone,在同一Subnetwork下的多个Zone中部署相同的业务,一个Zone失效后,其他Zone可以继续工作,即方便的进行容灾部署。同一个Subnetwork共用一个Firewall规则,通过tag可以很方便的确定允许通过Firewall的流量。
-
Network: 包括默认、自动、自定义三种模式,是全球的,可以跨越多个Region,包含多个Subnetwork,没有所谓的IP Address 区间。在同一个网络中的VM,即使分布在不同的Region也可以通过内网地址进行访问,在不同网络中的VM,即使分布在同一个Region也需要通过外网地址才能访问。
-
Projects: 关联可计费的对象和服务,最多可以有5个Network(shared或者peered)。
-
IP addresses: 分内部地址、外部地址,VM可以有内部和外部两个地址,内部地址是根据Subnetwork的地址范围由DHCP分配的,DHCP的租约每24小时更新一次;外部地址可从IP地址pool分配(临时)或者保留IP地址(静态),外部地址可以映射到内部地址,VM不知道外部地址的存在。
-
Routes: 路由。
-
Firewall rules: Inbound/Outbound Firewall rules, 可基于IP和tag。
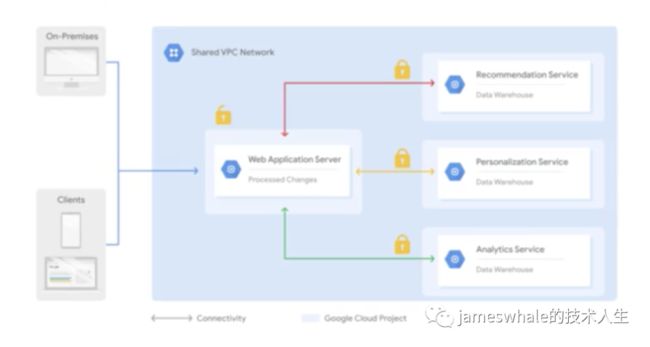
VPC的分类:
-
Shared VPC,所有的服务和网络元素都在一个VPC中,中心化管理,不能跨越不同的组织。
-
VPC peering,两个组织或者实体分处在两个VPC中,互相设置自己为对方的peer,可通过Private IP进行访问,去中心管理。

为避免业务计算实例受到外界的攻击,GCP提供了多种措施,包括检测恶意流量引到DDoS、防火墙、API GateWay、NAT等。通过NAT,内网机器可以访问外网资源,但是外网无法访问内网机器。

负载均衡
GCP提供了如下几种负载均衡方式:
-
HTTP(s) load balancing, 全局负载均衡,自动扩缩容,URL映射,架构如下:
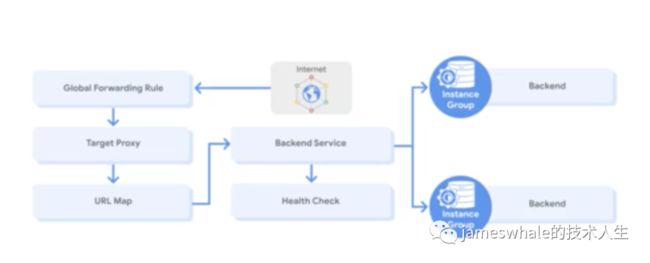
-
SSL proxy load balancing,为加密的非HTTP流量提供全局负载均衡,智能路由,认证管理,安全补丁,SSL策略。
-
TCP proxy load balancing,为非加密的非HTTP流量提供全局负载均衡,智能路由,安全补丁。

-
Network load balancing, Region范围的非proxy的的负载均衡,支持UDP、TCP/SSL流量。
-
Internal load balancing,Region范围的private负载均衡,支持UDP、TCP流量,支持3-tier web服务。
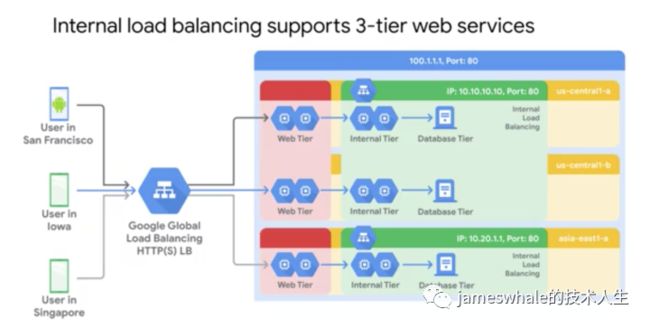
汇总如下:

计算
多种机型:
-
网络容量每vCPU 扩缩 2Gbps
-
理论上最多32Gbps(16个vCPU)或者100Gbps(T4或者V100 GPU),1 vCPU = 1个硬件超线程
Compute Engine:
-
Computer Engine提供可管理的虚拟机,这是从自有机房迁移到云首先想到的资源,IaaS。
-
支持Linux和Windows Server两种虚拟机镜像,采用KVM作为其虚拟机的VMM/Hypervisor。
-
预定义或者用户自行挑选合适的内存大小、CPU核数、硬盘类型(持久化的SSD,Local SSD等),若有需要,可以选择GPU。
-
计算资源按秒计费,可以横向(申请多个虚拟机)或者纵向(选择大的内存、更多的CPU核数,更大的磁盘空间)扩展。
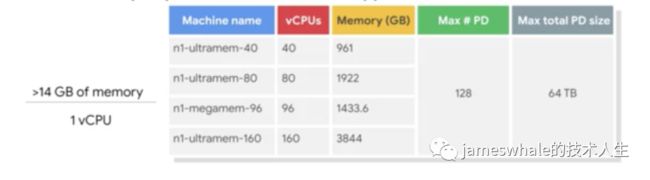
预定义机型按照1 vCPU对应的内存大小可分为:
-
标准

-
高内存

-
高CPU

-
内存优化
-
计算优化

-
共享Core

托管的计算实例组,极大减少了运维成本:
-
根据实例模板可以部署完全一样的计算实例。
-
确保所有计算实例都是正常运行的。
-
实例组的所有计算实例可以在同一个Zone或者跨Zone,但必须在同一个Region。
-
实例组提供自动扩缩容能力,根据负载的增加减少自动增加减少计算实例,自动扩缩容的策略包括CPU使用率、负载均衡容量、监控的预定义或者自定义指标、基于队列的负载。
计算实例的镜像(Image),安装在虚拟机的VMM/Hypervisor之上,包括如下内容:
-
加载引导程序(Boot loader)
-
操作系统(Guest)
-
文件系统
-
自定义软件
镜像可以通过如下方式获取:
-
公共基础镜像,Google、第三方品牌商、社区,分为Linux(CentOS,CoreOS,Debian,RHEL(p),SUSE(p),Ubuntu,openSUSE,FreeBSD)和Windows(Windows Server 2019(p),2016(p),2012-r2(p))
-
自定义镜像,以现有的计算实例创建镜像,从自建机房、工作站、其他云提供商导入的镜像
存储与数据库
GCP提供了多种类型的硬盘:
-
持久化的标准硬盘、SSD硬盘,这些存储不会随着虚拟机的删除而消失。
-
Local SSD,速度更快,当虚拟机删除的时候会同时删除。
GCP也提供了多种数据库(关系型和非关系型):
-
Cloud Storage
-
Cloud Bigtable
-
Cloud Datastore
-
Cloud Firestore
-
Cloud SQL
-
Cloud Spanner
-
Cloud Memorystore
Cloud Storage
Cloud Storage是一个对象存储服务,高性能,自动扩容,用户不需要管理容量。例如,新增一个Bucket,然后将图片等文件上传到指定的Bucket。根据不同场景,可选择Multi-regional,Regional,Nearline, Coldline, 前面两种存储单价(GB/月)高,后两种存储单价低,但是单位GB的提取访问单价高。
-
可以用客户自己提供的加密key(CSEK)。
-
对象生命周期管理,自动删除或者归档对象。
-
对象版本管理,可以管理一个对象的多个版本,可以获取已删除或者已覆写的对象。
-
对象变更通知,对象更新或者新增到Bucket的时候可以触发通知应用程序。
-
强一致性,提供全局的强一致性。
Cloud Bigtable
托管的NoSQL大数据数据库服务,适合Ad Tech,Fintech,IoT等业务场景,机器学习应用理想的存储引擎,支持同一row的transaction,不支持跨row的transaction,可方便的和开源的大数据工具结合起来。
-
PB级数据扩展
-
低于10毫秒的延迟
-
平滑的扩缩容能力
-
学习和自动调整访问方式
Cloud Bigtable的存储模式:
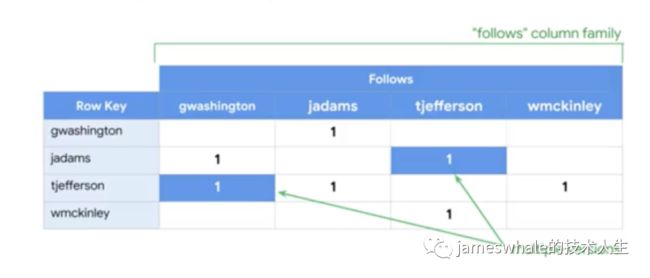
处理和存储是分开来的,可以通过增加Bigtable node节点方便的提高处理能力,同时,node节点故障后不会导致数据丢失。
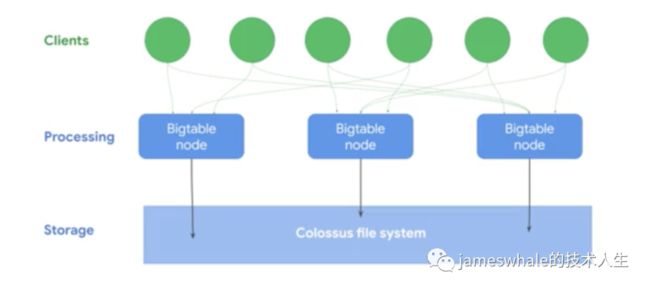
能够自己学习和调整访问方式
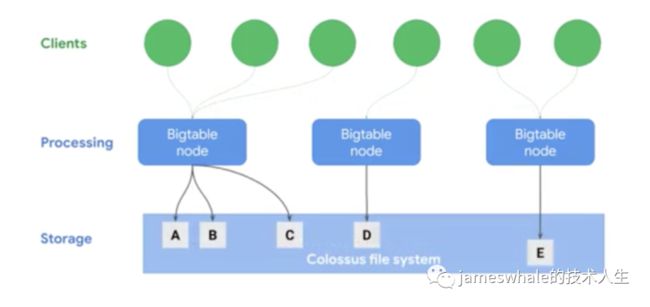
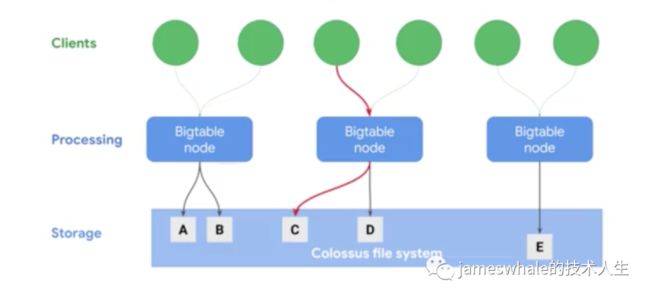
吞吐量可以随着Bigtable node节点数量线性扩缩

Cloud Datastore
托管的NoSQL存储服务,基于Bigtable的架构进行设计,并做了增强和改进,例如,Bigtable仅支持同一row的transaction,Datastore最多支持25个row的transaction。提供SQL类的查询,利用索引搜索符合条件的Object,可作为应用程序的后端存储。
Cloud Firestore
Cloud Firest是Cloud Datastore下一代产品,托管的 NoSQL 文档数据库,能够自动扩缩、具备出色的性能,并且易于进行应用开发。虽然 Firestore 界面具有许多与传统数据库相同的功能,但作为 NoSQL 数据库,它与传统数据库在描述数据对象间关系的方式方面有所不同。允许文档数据上运行复杂的 ACID 事务,能更灵活地设置数据结构。内置实时同步和离线模式,可以在移动 Web 和 IoT 设备上轻松构建多用户协作式应用,例如,实时资产跟踪、活动跟踪、实时分析、媒体和商品清单、通信、社交媒体用户资料和游戏排行榜等。支持两种模式:
-
Datastore模式,与Datastore应用兼容,强一致性。
-
Native模式,文档数据模式,支持实时更新。
Cloud SQL
Cloud SQL是托管的Mysql和PostgreSQL数据库,具备高可靠性和高扩展性,每个VM提供高达30TB的存储容量、40,000 IOPS、416 GB的内存,自动完成备份、复制、更新等事宜。因为它也使用Compute Engine,可以通过故障恢复来保障高可用性。写只能纵向扩展,读既可以纵向扩展也可以横向扩展。
Cloud Spanner
Cloud Spanner是托管的可横向扩展的关系型数据库,支持自动备份、复制、更新,结合了关系型数据库结构的好处与非关系型数据库可横向扩展两个优点于一身。
-
PB级数据的扩展
-
强一致性
-
高可靠,可用于金融和库存相关的行业,Monthly uptime,Multi-Regional:99.999%, Regional:99.99%。
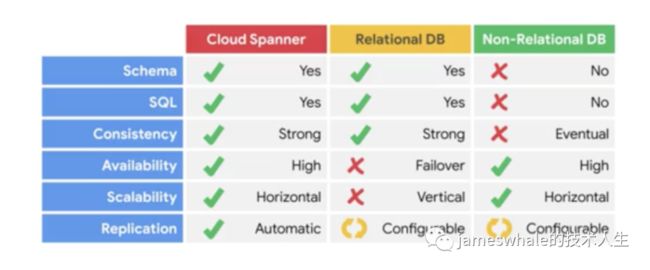
Cloud Spanner的架构,在多个Zone中部署多个副本,避免一个Zone灾难后数据丢失。
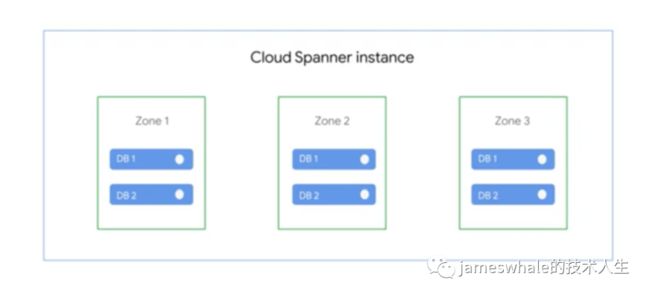
通过Google的全局光纤网络在多个Zone之间同步数据的更新

Cloud Memorystore
Cloud Memorystore是托管的Redis服务。
-
全内存的数据存储服务。
-
高可靠,故障自动恢复、监控。
-
小于1毫秒的访问延迟。
-
最多可达300GB的容量。
-
网络带宽可达12Gpbs。
App Engine、GKE与Cloud Function
App Engine
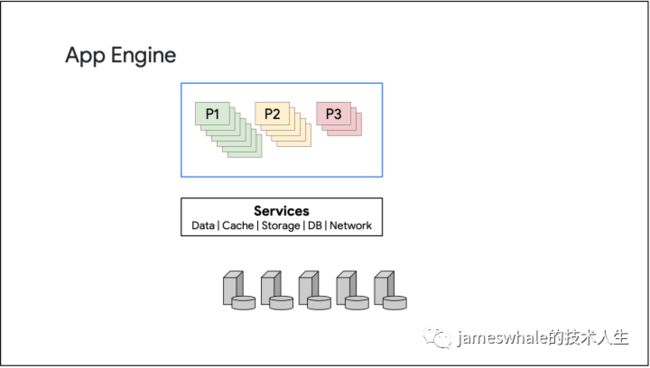
托管的平台,客户不需要关注基础架构事务(包括计算、存储、网络等资源,负责均衡、防火墙规则、角色管理、TSL/SSL等),只需关注具体业务代码逻辑,App Engine会根据流量情况自动扩缩容,且只有代码运行的时候才需付费。分为标准环境(App Engine Standard environment)和灵活环境(App Engine Flexible environment),标准环境有一些限制,比如只支持Java、Python、PHP和GO,不允许写本地文件,所有请求的最大超时时间是60秒。
GKE(Google Kubernetes Engine)
从头搭建一个K8S集群,需要做如下事情,可以看到还是挺繁琐的,都是一些体力活。
-
在Master、Node节点安装、配置Docker。
-
修改docker cgroup驱动,与k8s一致,使用systemd。
-
在Master、Node节点安装kubelet kubeadm kubectl。
-
创建集群准备工作,在Master、Node端拉取相关镜像、修改镜像tag、删除旧镜像等。
-
使用kubeadm创建集群,设置配置权限,应用flannel网络,将多个Node加入集群。
-
安装dashboard,设置监控、告警。
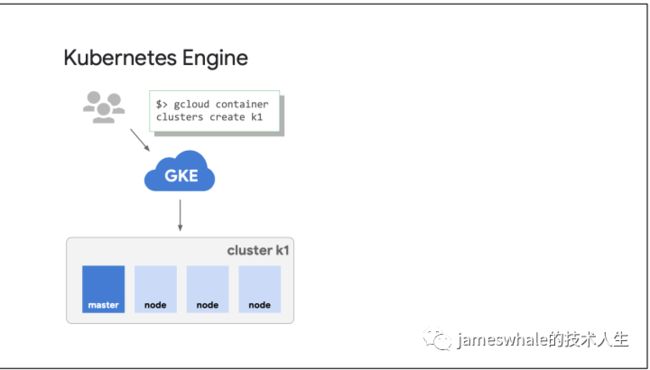
通过GKE , 用户只需选择Node的个数,其他都是自动完成的,包括集群的告警、监控等,这就极大的提升了生产力。
容器(Container)
通过Compute Engine(虚拟机)当然可以进行自动扩容,但是因为虚拟机中Guest OS占用较大空间,启动、停止虚拟机耗时时间较长,不能随心所欲的扩缩容业务所需资源。反过来讲,为了不浪费资源,必须能够方便和快速的进行业务资源的扩容和缩容,这是云计算平台所要必备的(参考云计算平台定义),容器技术也是在这个背景下快速发展和应用到云计算平台中。容器只镜像了业务和所依赖的环境和库,没有Guest OS,所以额外开销很小,启动、停止都会很快。一个应用可以拆分成多个逻辑,每个逻辑就是一个微服务,运行在可扩展的容器中,这些容器运行在多个Host中。每个Host可以运行多少个容器,若Host挂了,其中的Container如何迁移等,Kubernetes就是用来解决这些常见的工程问题的。Kubernetes使得在许多Host上协调多个容器、将它们扩展为微服务以及部署发版和回滚变得非常容易。上面也提到,部署Kubernetes集群纯粹就是一个体力活,这个时候Google的Kubernetes Engine出现了,客户只选择用几个Node来承载应用的容器,其他的都不用关心了。细究的话,Container和Kubernetes介于IaaS和PaaS之间。
容器只包含应用程序和其依赖的库,比虚拟机要轻量很多

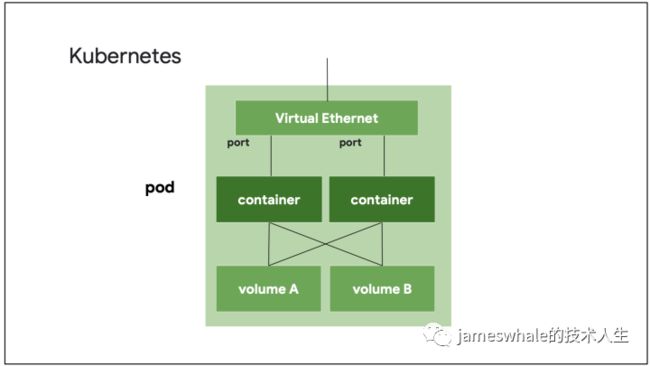
Kubernetes架构,master节点管理者若干node节点,并对外提供管理api,真正的业务(若干个pod)跑在node节点上面。

Kubernetes中,最小的调度单元是pod,一个pod可能包含多个container,pod中的多个container共享一个网络接口。
GKE,极大的提升了生产力,只需一个命令即可创建出来一个Kubernetes集群。
Cloud Function
利用可伸缩的函数即服务 (FaaS) 运行代码,用多少付多少,并且无需执行任何服务器管理工作。
-
不必预配、管理或升级服务器
-
根据负载自动扩缩
-
集成式监控、日志记录和调试功能
-
基于最小权限原则的角色和函数级别的内置安全性
-
适用于混合云和多云端方案的关键网络功能。
-
简化开发者体验,提高开发速度。
Stackdriver
-
集成monitoring、logging、diagnostics
-
跨平台管理,包括GCP和AWS
-
强大的数据和分析工具
-
和第三方软件的合作
logging
-
可以搜集平台、系统、应用程序日志,最多保留30天,提供API来写日志。
-
可搜索、查看、过滤日志。
-
基于日志的metics。
-
可基于日志事件来设置告警。
-
日志可以被导入到Cloud Storage,BigQuery and Cloud Pub/Sub。

Monitoring
-
动态设置和智能常规默认值
-
摄取平台、系统、应用程序metics,事件,元数据,生成dashboards、表格、告警。
-
Uptime/Health check
Tracing
-
跟踪系统,近实时的展现数据,请求latency报告,URL latency采样。
-
收集latency数据,包括App Engine,Google Http(s) load balancers,包含Stackdriver Trace SDKs的应用程序。
Error Reporting
聚合和展现运行的云服务的错误
-
错误通知
-
错误dashboard
数据处理、大数据分析与机器学习
BigQuery
BigQuery是GCP提供的serverless、高可扩展、低成本的cloud data warehouse。
-
完全托管
-
PB级数据扩展
-
提供SQL接口
-
非常快
Cloud Dataflow
Cloud Dataflow是托管的数据pipeline,集群大小可自动伸缩,基于数据转换的编程模式,例如,以BigQuery数据源,经过Dataflow处理后,落入Cloud Storage。主要使用场景包括:1)ETL(extract/transform/load),作为转移、筛选、丰富加强、规整数据的一个管道;2)数据分析,批量计算和流连续计算。
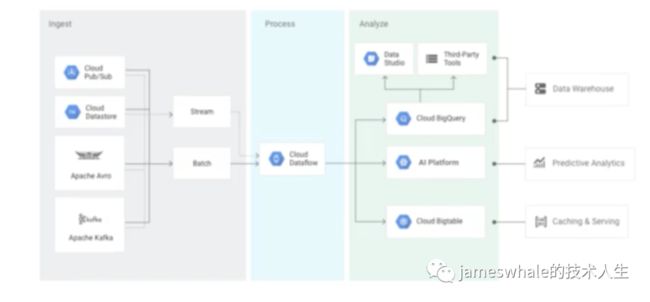
Cloud Dataprep
Cloud Dataprep可可视化的挖掘、清洗、准备数据,用于分析和机器学习。
-
serverless,可任意扩展。
-
理想的数据转换服务。
-
聚焦于数据分析。

Cloud Dataproc
Cloud Dataproc是运行Apache Spark和Apache Hadoop集群的服务。
-
低成本(可抢占)
-
可快速的进行启动、扩缩、关闭
-
托管的服务
Pub/Sub
可扩展的可靠消息系统,支持多对多的异步消息传递,push/pull两种消息订阅方式,可以和Dataflow,IoT一起协同工作。作用和Kafka一样,但是是完全托管的,不需要考虑扩容、维护等相关事宜。
机器学习
-
开源工具构建和运行神经网络模型,支持CPU、GPU,移动端、服务、云等。
-
完全托管的机器学习服务,基于notebook的开发环境,和BigQuery、Cloud Storage高度协同。
-
谷歌提供的预训练的机器学习模型,包括:1)Speech,实时流结果,可以检测80+语言;2)Vision,物体识别,标记,文字,内容;3)Translate,语言检测与翻译;4)自然语言,文字结构化与理解。
总结
依稀记得有一位大佬说过,云计算不过是“新瓶装旧酒”,没有实质的东西,仔细拆分来看,的确没有额外新的技术,但是它代表了一种商业模式的转换,无需提前规划购买资源、只为使用的资源付费、可快速扩缩容,这正是它的强大之处。
文章首发于微信公众号【jameswhale的技术人生】,因精力有限,会不定期将文章同步到CSDN平台。
