Hive基本操作--2018安徽省大数据竞赛赛题2(hive数据清洗)
Hive的基本操作
hive有自己的一套SQL,与Mysql等关系数据库的SQL略有不同,但简单的查询等预期基本一致。
题目描述:
“安徽省大数据学院”跟学校进行校企合作,提供了一些商品交易的数据源给学校学生进行数据清洗,想请你帮他们完成数据的清洗。
/root/目录下有shop_1.txt和shop_2.txt数据源,里面是一些商品的交易记录,数据格式如下:
其中,数据源属性从左往右以此是id(商品记录id),goods_name(商品名称), biz_price(商品交易金额),count(商品交易数量),biz_date(商品交易日期)

- 创建raw_test数据库,进入raw_test数据库
创建数据库较为简单,使用create database 命令即可,补充关于数据库修改编码方式为utf-8的内容,因为在一般的场景中经常会出现导入文件后,数据库表中文内容乱码需要修改编码,因此如果在创建数据库时便指定则能节省一些精力。
由于hive是以mysql作为元数据库的,因此需要修改mysql元数据库的编码格式
##创建hive元数据库hive,并指定utf-8编码格式
mysql>create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci;
##修改已存在的hive元数据库,字符编码格式为utf-8
mysql>alter database hive character set utf8;
##进入hive元数据库
mysql>use hive;
##查看元数据库字符编码格式
mysql>show variables like 'character_set_database';
此题的创建数据库的命令为:
hive>create database raw_test;
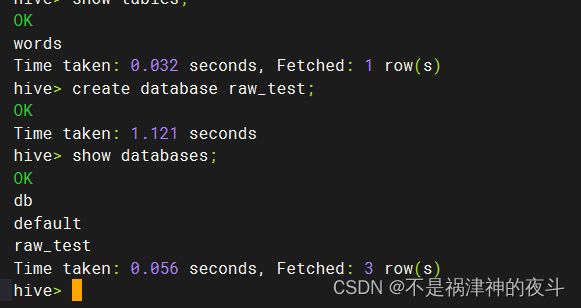
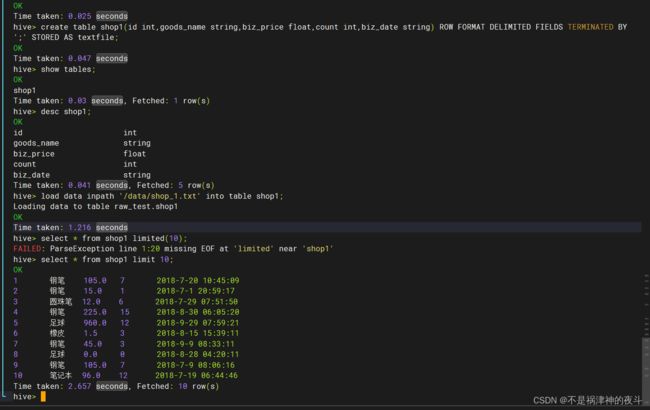
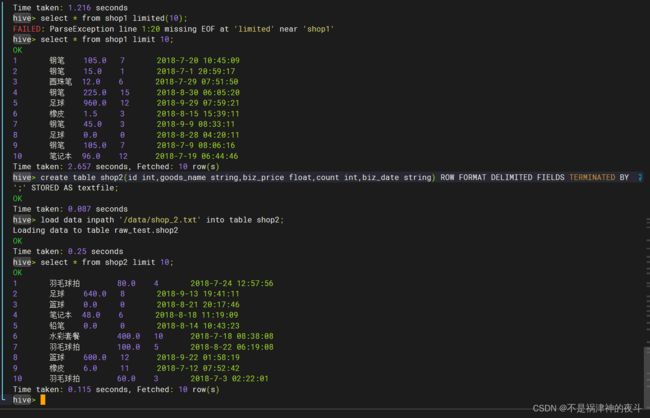
- 基于raw_test数据库,创建shop1,shop2表,将数据源shop_1.txt和shop_2.txt分别导入对应的表中。分别查询两个表中的前十条数据并将这两个截图保存到答题纸任务2-1-2中。(10分)
创建表,关于hive支持的数据类型详见:hive表的字段数据类型
参考题目描述,创建表的sql语句如下:
hive>create table shop1(id int,goods_name string,biz_price float,count int,biz_date string) row format delimited fields terminated by ';' stored as textfile;
这里需要注意的是创建表时的语句,因为后面要导文件进入hive表,因此在创建时要指定表中数据的组织方式。
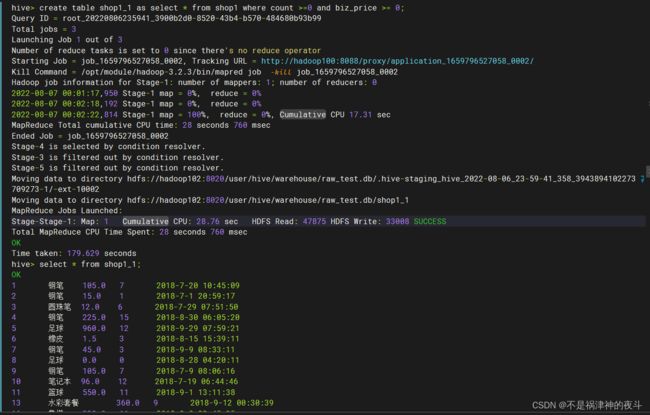
- 创建shop1_1表,过滤掉shop1表中交易金额为负数或者交易数量为负数的记录,并将结果保存到shop1_1表中。查询shop1_1表中的记录总数并将结果截图保存到答题纸任务2-1-3中。(5分)
hive> create table shop1_1 as select * from shop1 where biz_price >= 0 and count >= 0;
- 创建shop1_2表,过滤掉shop1表中存在字段为空的记录,并将结果保存到shop1_2表中。查询shop1_2表中的记录总数并将结果截图保存到答题纸任务2-1-4中。(5分)
create table shop1_2 as select * from shop1 where id is not null and goods_name != '' and biz_price is not null and count is not null and biz_date != '';
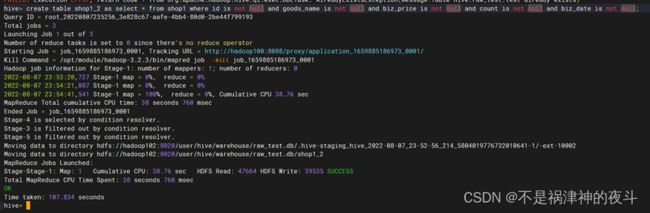
未过滤空值表中数据个数
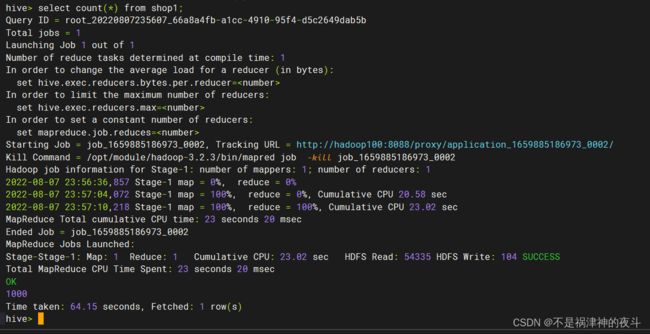
过滤后:
经查看表中无空值
- 创建shop2_1表,过滤掉shop2表中重复的记录(除id字段外,其他字段都相同的记录被认为重复记录;如果存在2条及2条以上的重复记录,则只保留1条记录),并将结果保存到shop2_1表中。查询shop2_1表中的记录总数并将结果截图保存到答题纸任务2-1-5中。(5分)
hive>create table shop1_2 as select * from (select id, goods_name,biz_price,count,biz_date,ROW_Number() over(partition by goods_name,biz_price,count,biz_date order by count) rank from shop1) m where m.rank=1;
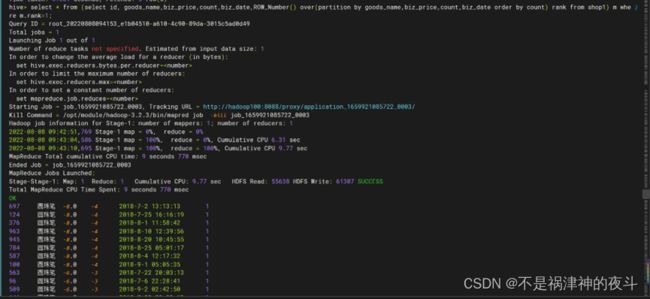
这其实是一个分组过程。
补充partition by
over(partion by) 开窗函数
任务:统计每种类型商品的最高交易价格(可能不是最优的思路)
hive> select goods_name,max_price from (select id,goods_name,biz_price,count,biz_date,max(biz_price) over(partition by goods_name) max_price from shop1) mm group by goods_name,max_price;