整合:qlib的AI导向的框架与backtrader的事件驱动与实盘
原创文章第100篇,专注“个人成长与财富自由、世界运作的逻辑, AI量化投资”。
今天是第100天!连续100天,包括周末,挺好。1000天计划一个非常好的开始。
我观察分析了一下,星球会员群里主要是两类用户,一类是工程师,算法专家等,熟悉python,对金融量化感兴趣;另一类是金融行业从业者,私募,基金,券商或者银行,做研究分析或者本身就是资管。共同点是大家都对量化感兴趣。
从大的技术路线上来看,AI量化肯定是对的方向,这个不需要怀疑,只是所处的阶段,有多少能够落地这个需要时间来论证。
大家的需求有几个方面:首先是量化的知识体系,如何体系化的入门到精通,需要一个更加结构化的知识体系。最终目的当然是做出策略,可以实盘。若要简化为一个目的,那所有人都是一样:做出可持续的实盘策略。
当然,策略不是静态的,一劳永逸的东西,它是一个体系,需要可迭代会随市场自我进化,并不存在永恒的圣杯,这是金融与物理最大的差别。物理定律就在那里,你发现或者不发现,它都不会变,它就等着你去发现。金融模型是用的人多了,就没有了路,而且还要叠加人性的疯狂。
我们需要一个”策略工厂“,需要一条“流水线”,而不是指望憋出一个终极策略,根本没有这么一个东西。我们把这个策略工厂搭建起来,把qlib的AI导向的框架与backtrader的事件驱动与实盘整合起来,再加上wxPython的GUI。
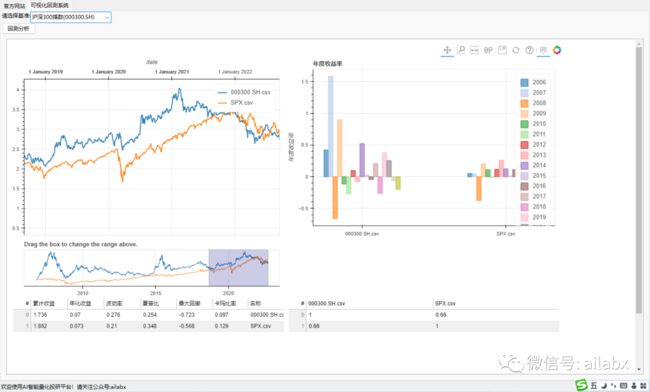
昨天我们把机器学习应用于量化简单串了一下:AI量化与机器学习流程:从数据到模型。今天继续。
01 数据准备封装
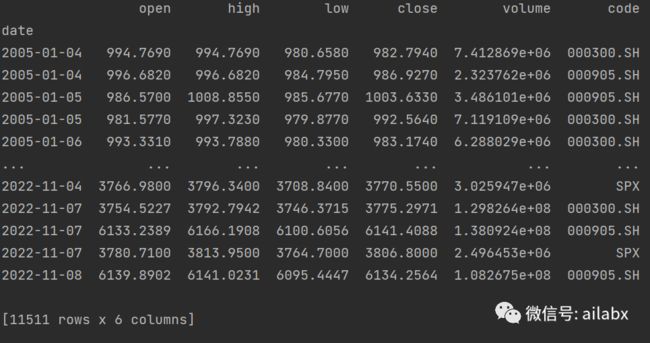
之前我封装对csv,还有arctic,今天补充一个hdf5。
# encoding:utf8
import datetime
import pandas as pd
class Hdf5DataFeed:
def __init__(self, db_name='index.h5'):
self.code_dfs = {}
def get_df(self, code, db=None):
if code in self.code_dfs.keys():
return self.code_dfs[code]
with pd.HDFStore('../../data/hdf5/index.h5') as store:
#print(store.keys())
df = store[code]
#print(df)
df = df[['open','high','low','close','volume','code']]
self.code_dfs[code] = df
return df
def get_one_df_by_codes(self, codes):
dfs = [self.get_df(code) for code in codes]
df_all = pd.concat(dfs, axis=0)
df_all.dropna(inplace=True)
df_all.sort_index(inplace=True)
return df_all
def get_returns_df(self, codes):
df = self.get_one_df_by_codes(codes)
all = pd.pivot_table(df, index='date', values='close', columns=['code'])
returns_df = all.pct_change()
returns_df.dropna(inplace=True)
return returns_df
def get_returns_df_ordered(self, codes):
dfs = []
for code in codes:
df = self.get_df(code, cols=['close'])
close = df['close']
close.name = code
dfs.append(close)
all = pd.concat(dfs, axis=1)
returns_df = all.pct_change()
returns_df.dropna(inplace=True)
return returns_df
if __name__ == '__main__':
feed = Hdf5DataFeed()
print(feed.get_df('SPX'))
df = feed.get_one_df_by_codes(['000300.SH','000905.SH','SPX'])
print(df)
02 特征工程
特征工程,首选“因子表达式”。
fields += [
"Std(Abs($close/Ref($close, 1)-1)*$volume, 30)/(Mean(Abs($close/Ref($close, 1)-1)*$volume, 30)+1e-12)"
]
names += ['WVMA30']
使用因子表达式,可以写出复杂的公式,类似worldquant的alpha101。这要是自己编码不仅效率太低,而且很容易出错。
import pandas as pd
from engine.datafeed.expr.expr_mgr import ExprMgr
class Dataloader:
def __init__(self):
self.expr = ExprMgr()
def load(self, codes, names, fields):
dfs = []
for code in codes:
df = pd.DataFrame()
for name, field in zip(names, fields):
exp = self.expr.get_expression(field)
se = exp.load(code)
df[name] = se
df['code'] = code
dfs.append(df)
all = pd.concat(dfs)
all.sort_index(ascending=True, inplace=True)
all.dropna(inplace=True)
return all
if __name__ == '__main__':
names = []
fields = []
fields += ["($high-$low)/$open"]
names += ['KLEN']
fields += ["$close"]
names += ['close']
fields += ["$close/Ref($close,1) - 1"]
names += ['return_1']
fields += ["Ref($close,-1)/$close - 1"]
names += ['label']
all = Dataloader().load(['SPX', '000300.SH'], names, fields)
print(all)
完成数据特征工程与自动标注(这里的因子表达式,我从qlib的代码里独立出来,不使用qlib的数据库,而使用更为简单的hdf5)
03 模型
基于keras建立深度模型:
import random
import numpy as np
import tensorflow as tf
from keras.layers import Dense, Dropout
from keras.models import Sequential
from keras.regularizers import l1
from keras.optimizers import Adam
from sklearn.metrics import accuracy_score
def set_seeds(seed=100):
random.seed(seed)
np.random.seed(seed)
tf.random.set_seed(seed)
set_seeds()
optimizer = Adam(learning_rate=0.0001)
def create_model(hl=2, hu=128, dropout=False, rate=0.3,
regularize=False, reg=l1(0.0005),
optimizer=optimizer, input_dim=None): # input_dim = len(features)
if not regularize:
reg = None
model = Sequential()
model.add(Dense(hu, input_dim=input_dim,
activity_regularizer=reg,
activation='relu'))
if dropout:
model.add(Dropout(rate, seed=100))
for _ in range(hl):
model.add(Dense(hu, activation='relu',
activity_regularizer=reg))
if dropout:
model.add(Dropout(rate, seed=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizer,
metrics=['accuracy'])
return model
if __name__ == '__main__':
set_seeds()
model = create_model(hl=2, hu=64)
这里每个环节都需要持续去强化,优化,但这个框架会逐步稳定下来。
全部系统的代码和数据,请前往星球下载。
AI量化与机器学习流程:从数据到模型
知识星球