【Dense Res2net:两个非局部注意模型:IVIF】
Res2Fusion: Infrared and Visible Image Fusion Based on Dense Res2net and Double Nonlocal Attention Models
(Res2Fusion: 基于密集Res2net和双非局部注意模型的红外和可见光图像融合)
红外和可见光图像融合旨在生成具有出色场景表示和更好视觉感知的合成图像。现有的基于深度学习的融合方法仅利用卷积操作来提取具有局部感受野的特征,而没有充分考虑其多尺度和远程依赖特性,这可能无法保留源图像中一些必要的全局上下文。为此,我们基于密集的Res2net和双重非局部注意模型 (称为Res2Fusion) 开发了一种新颖有效的融合网络。我们将Res2net和密集连接引入具有多个可用感受域的编码器网络,用于提取多尺度特征,并可以为融合任务保留尽可能多的有意义的信息。此外,我们开发了双重非局部注意力模型作为融合层,以对局部特征的远程依赖性进行建模。具体来说,这些注意力模型可以完善编码器网络获得的特征图,以更加关注突出的红外目标和明显的可见细节。最后,综合注意力图用于通过简单解码器网络生成融合结果。
介绍
为了克服上述挑战,我们提出了一种基于密集Res2net和双重非局部注意力模型 (称为Res2Fusion) 的新颖有效的融合网络。我们的Res2Fusion提出了一种编码器-解码器网络,以促进融合规则的设计。在编码器网络中,我们引入Res2net块来提取具有多个可用感受域的多尺度特征图,并应用密集连接以进一步提高特征表示能力。在融合层中,我们采用双重非局部注意力模型来对局部特征的远程依赖进行建模,并生成其相应的空间和通道注意力图。与编码器网络提取的特征图相比,获得的注意力图更多地关注显着的热目标和通常可见的细节。最后,由解码器网络组合并重建注意力图,以生成最终的融合结果。
贡献
1)我们提出了一种新颖有效的融合网络,该网络将Res2net作为卷积块和密集连接引入编码器网络。我们的编码器网络可以有效地提取多尺度深度特征,而无需下采样操作或可变的内核大小,并为融合任务保留更有意义的信息。
2)我们提出了双重非局部注意模型作为融合策略,该模型可以从通道和空间位置建立对局部特征的长期依赖性,以细化特征图,从而更加关注源图像的典型目标和细节。我们的结果在保留典型的热目标和丰富的可见细节之间获得了更好的视觉效果。
3)我们在公开可用的数据集 (即TNO和Roadscene) 上进行了大量实验,结果表明,我们的方法从主观和客观分析中获得了出色的融合性能,超越了其他先进的融合方法。此外,我们的方法在不同的测试数据集上具有很强的鲁棒性。
相关工作
Deep Learning-Based Image Fusion
(对于一些融合方法的表述:略)
尽管这些方法取得了良好的融合性能,但一个不争的事实是,它们的结果不能有效地同时保留高亮度和丰富纹理细节的显著目标。在本文中,我们介绍了一种具有双重非局部注意模型的新颖融合网络,以克服上述问题。与他们的方法不同,我们的Res2Fusion有两个主要的技术贡献。首先,通过引入Res2net作为多尺度卷积块,我们的融合网络是一种新颖而有效的方法,与其他通过利用下采样操作或可变内核大小的方法不同。我们的方法可以有效地提取不同尺度的深层特征,并为融合任务保留更有意义的信息。其次,我们开发了双重非局部注意力模型作为融合层,该模型可以对局部特征的远程依赖性进行建模,以获得其相应的注意力图。这些综合注意力图可以促进融合网络更加关注红外图像的显著目标和可见光图像的典型纹理细节,进一步提高融合性能。
Res2net
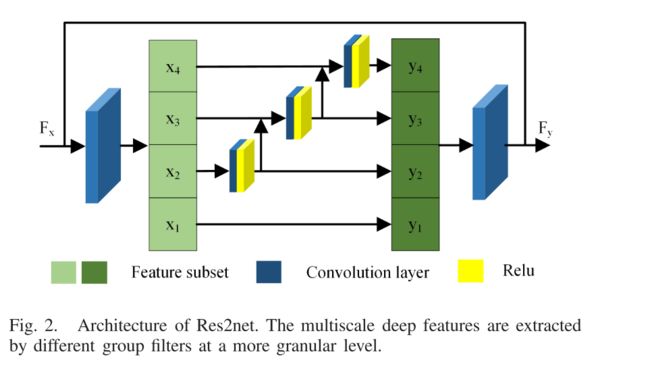
为了加强CNN的多尺度特性,Gao等人开发了一种新颖的多尺度主干体系结构Res2net,用于对象检测,语义和实例分割等。Res2net的框架如图2所示。Res2net采用不同的数字和不同的比例内核,以分层残差状的方式表示具有不同组滤波器的多个可用接受字段。
对于输入的特征图,首先使用1 × 1卷积来转换通道,并将获得的特征图拆分为s个特征子集。对于每个子集,都有相同的空间大小和1/s通道号,其中s是一个比例控制参数。除第一个子集外的每个子集均由同源3 × 3卷积操作,并添加到下一个特征子集中。然后,将获得的特征图输入到1 × 1卷积层中,并与原始特征级联以获得最终结果。
在我们的工作中,将Res2net作为卷积块引入编码器网络,并采用密集连接来进一步提高特征表示能力。与Res2net不同,我们仅保留卷积层和ReLU层,并删除批归一化层。此外,我们在随后的实验中选择s = 4作为比例控制参数。
方法
Network Architecture

所提出的Res2Fusion如图3所示,它包含三个主要部分,即编码器部分、融合层和解码器部分。
1) Encoder Part:
我们的编码器网络包含一个普通的卷积 (C1) 和两个Res2net块 (Res2net1和Res2net2)。普通卷积层用于提取低级特征,而Res2net块分层聚合多个可用感知域以生成多尺度高级特征。此外,密集连接适用于保留中间特征图,可以很好地重复使用以提高特征表示能力。与现有的提出多核卷积或下采样操作来提取多尺度特征的方法不同,后者不可避免地会丢失一些有用的特征,我们的编码器网络可以在不进行下采样和上采样操作的情况下为图像融合任务保留尽可能多的多尺度特征信息。
2) Decoder Part:
我们的解码器网络由四个普通卷积组成,用于重建结果。所有卷积层均为3 × 3内核大小,具有ReLU激活函数。填充和步幅分别设置为1。因此,我们的融合网络适用于任意分辨率的图像,并保持源图像与特征图具有相同的大小。此外,我们的编码器-解码器网络具有相同的权重,这对于设计某些融合策略很容易且可行。
3) Fusion Layer:
特别是在测试阶段,将源图像单独输入编码器网络以获得其对应的特征图,然后,双非局部注意模型通过计算位置/通道处的响应作为所有位置/通道处特征的加权和,直接建立远程依赖关系。根据特征图的亮度和纹理的相似性,获得的注意力图更多地关注典型目标和细节。
Fusion Strategy

为了满足上述训练的编码器-解码器网络,需要设计一种融合策略来生成它们的融合特征图,以便可以通过解码器网络获得融合的结果。实际上,卷积操作是处理本地邻域信息的构建块,并用于生成具有3-D张量的特征。因此,受非局部神经网络的启发,我们设计了双重非局部注意力模型作为融合层,以建模远程依赖关系。图4给出了双非局部注意模型的相应细节。对于多尺度特征图ΦI和ΦV,采用双非局部注意模型来获得它们各自的空间和通道注意图。随后,通过加权融合策略获得双重融合注意力图,称为 Φ s a Φ^{sa} ΦsaF和 Φ c a Φ^{ca} ΦcaF。最后,我们提出了一个加法融合规则来生成最终的融合注意图F,该图由以下定义:

1) Spatial Nonlocal Attention Model:
(本章节:一定一定要注意上标,注意维度)
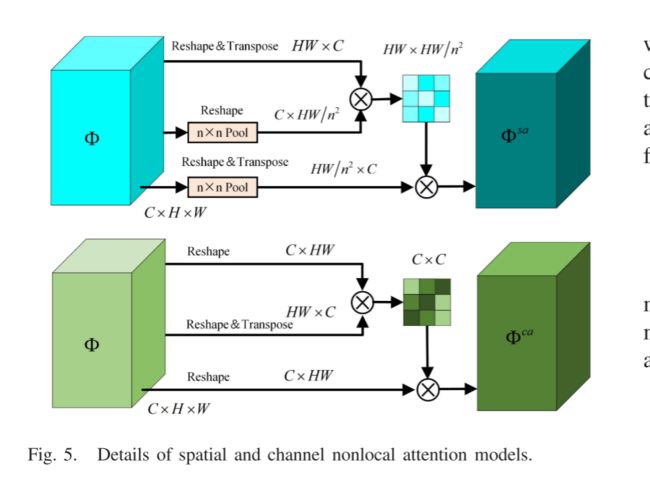
如图5所示,对于特征图 Φ∈ R C × H × W R^ {C×H×W} RC×H×W,我们首先对其进行整形并转置为X ∈ R H W × C R^{HW × C} RHW×C,然后使用n × n池化操作,并对其进行整形以生成两个特征图 Φ Y Φ^Y ΦY, Φ Z Φ^Z ΦZ ∈ $R^{C × HW/ n 2 n^2 n2 } 。 然 后 , 我 们 对 。然后,我们对 。然后,我们对 Φ X Φ^X ΦX 和 Φ Y Φ^Y ΦY进行矩阵乘法,并应用softmax运算来计算空间注意图 S s a S^{sa} Ssa ∈ $R^{HW× HW/ n 2 n^2 n2 } $,以下内容:


其中R(·) 和 ( ⋅ ) T (·)^T (⋅)T分别出现重塑(reshape)和转置操作。基于上述建模,将多尺度特征图ΦI和ΦV分别输入到空间非局部注意力模型中,可以获得它们的空间注意力图,称为 Φ s a Φ^{sa} ΦsaI和 Φ s a Φ^{sa} ΦsaV,然后,通过以下方法计算它们的加权空间注意力系数:

最后,融合的空间注意力图 Φ s a Φ^{sa} ΦsaF(i,j)由以下内容计算

在空间注意力模型中,使用n × n池化操作来降低计算复杂度。
2) Channel Nonlocal Attention Model:

如图5所示,首先将特征图Φ从 R C × H × W R^{C × H × W} RC×H×W重塑为 R C × H W R^{C × HW} RC×HW,然后在重塑Φ和Φ的转置之间执行矩阵乘法。最后,我们应用softmax运算来获得通道注意图 S c a S^{ca} Sca ∈ R C × C R^{C × C} RC×C,其定义如下:

其中 S c a S^{ca} Sca表示第c通道对另一个第c通道的影响。随后,我们再次对$S^{ca}和重塑Φ进行矩阵乘法,并对结果进行重塑以获得通道注意图 Φ c a Φ^{ca} Φca ∈ R c × h × w R^{c × h × w} Rc×h×w,该图由以下公式表示:

类似地,通过通道注意模型获得多尺度特征图ΦI和ΦV的通道注意图,称为 Φ c a Φ^{ca} Φca I和 Φ c a Φ^{ca} ΦcaV,然后,它们的加权通道注意系数的计算方法如下:

最后,融合通道注意特征 Φ c a Φ^{ca} ΦcaF(i,j)计算如下:
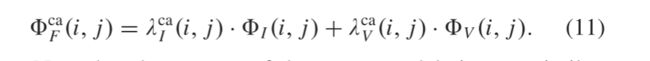
请注意,这两个模型的过程非常相似,只是通道模型的第一步是在通道维度上计算相应的注意矩阵。