谷歌FLAN-T5作者亲讲:5400亿参数,1800个任务,如何实现大语言模型“自我改进”...
2021年,谷歌的研究者们提出了FLAN大模型,其基于Instruction Tuning的方式,极大地提升了大语言模型的理解能力。同时,各种Prompting方法的涌现预示着针对大模型的下游微调将成为研究领域关注的重点。
近日,谷歌研究者们再一次推进了Instruction Tuning的性能水平,模型模型参数上升至540B,微调任务的数量则高达1800多个,此外他们还采用了最新的Prompting机制——Chain of Thought(CoT),让语言模型有了自我改进的能力。
智源社区邀请了该工作的主要研究者——谷歌软件高级工程师侯乐博士。请他讲解新型微调方式在提升大规模语言模型性能方面的思路。

侯乐
侯乐博士近期在Google的研究主要集中在NLP方面,包括高效的语言模型训练、指令微调和提示工程等。他的一个核心兴趣是通过更好的微调和提示工程来提高最先进语言模型的推理能力。在加入谷歌之前,侯乐在纽约州立大学石溪分校获得了博士学位。博士在读期间,他专注于分析高分辨率图像,如卫星和医学图像。
作者:侯乐
整理:白鹏

“
背景:从Fine-tune到Prompting,
提升大模型性能方法有多少?
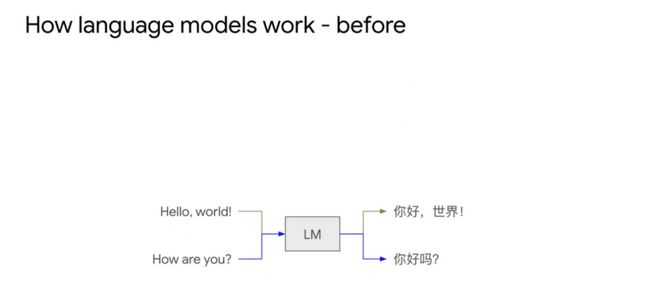
3-4年前的语言模型主要是用具体的数据在特定任务上训练,比如翻译任务,通过大量训练数据来训练翻译模式。

BERT出现以后,先有了Pretrain然后再进行Finetune。预训练时候会训练模型对语言的理解能力,比如BERT是一个Mask Language model。如果是只有解码器的模型,那就让模型做Next token prediction,比如已知“你好”,让模型预测“吗”。预训练后做下游的具体任务效果会好很多。
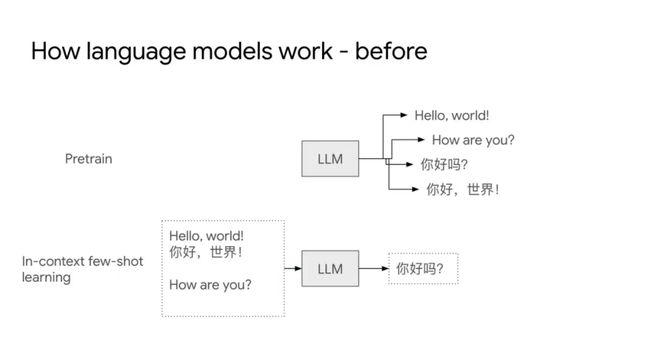
随着GPT-3等大模型出现,Language model(LM)变成了Large Language model(LLM),会出现新的应用方法,就是In-context few-shot learning。由于训练数据集有“问题1,解答1。问题2,解答2。”这样的数据存在,模型可以自动预测下一句。例如模型输入是“Hello, world!(你好,世界!)How are you?”,模型可以预测出“你好吗?”。所以这样的模型是一个In-context的样例学习模式,例子是什么格式,模型可以做Next token prediction。这样学习的好处是可能很少的训练样本就可以让大语言模型微调训练的很好。

我们将例子中“Hello, world!你好,世界!How are you?”就称为Prompt,Prompt工程是指如何改变输入Prompt的格式,能够更加发挥大模型的特性。
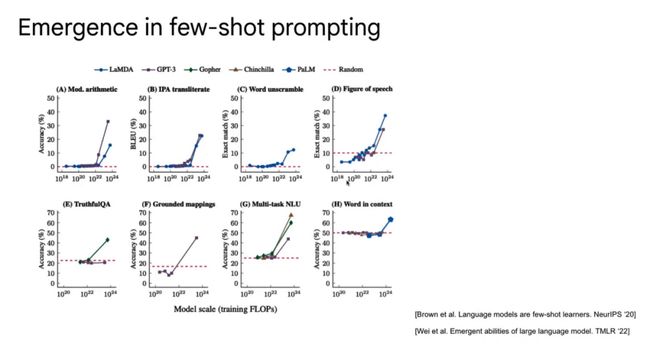
这个工作《Emergent abilities of large language model》是研究在语言模型足够大的时候,出现并解决In-context few-shot问题的能力。

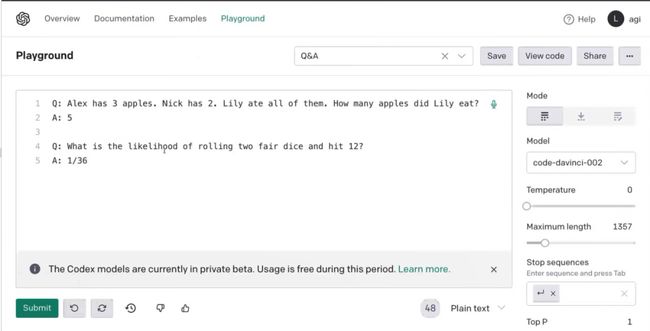
在Open AI的一些例子中,也可以看出模型学习样例的能力也很强。
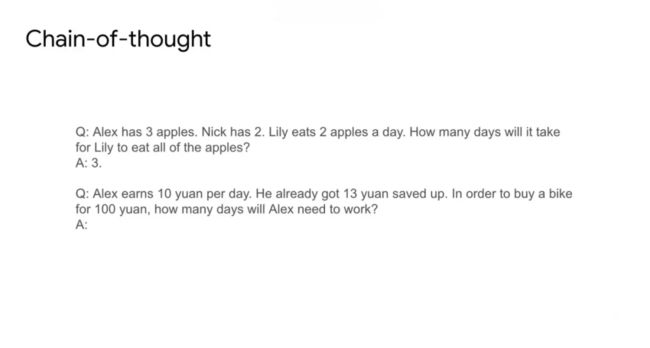
今年随着Chain of thought概念的兴起,也是Prompt工程中里程碑意义的方法,使得模型不仅能学习解答问题,更能学习解答问题的方式。
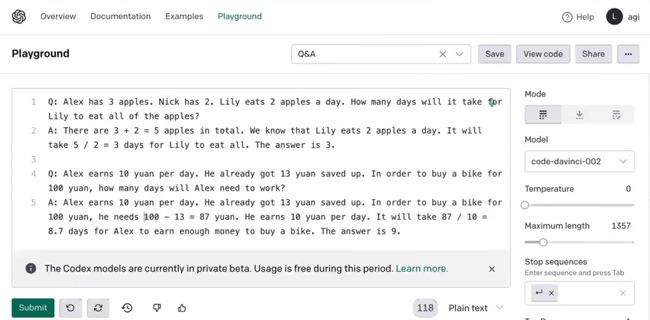
上面例子也能说明这一点,在训练数据中要有思考方式的数据,模型才能完成思考的推理输出,明显加强了模型的预测能力,模型也变得较慢,原来的模型只需要预测结果的Token,现在需要预测推理的所有结果Token。实际是用计算量换取模型结果准确率,模型更具有解释性,对于可解释AI也很重要。

在SuperGLUE的Benchmark中,模型已经比人类要强很多。

模型现在已经很强,只要你给它3-5个例子,让模型做什么它就能完成什么。已经不是原来的该需要输入成千上万数据的情况。

人类在学习时当然也基于事例,很多时候更是基于指令学习或者根据指令知道要做什么。实际中给定事例比给定指令要更好,但是我们实际中给定指令也基本是知道要怎么做。
“
遵循人类指令,
举一反三地完成任务:指令微调

在SAT exam样例中,同样是告诉我们如何做的指令,所以你也根据指令去做就能完成任务,受到以上的启发,我们提出了指令微调Instruction finetuning[1]。

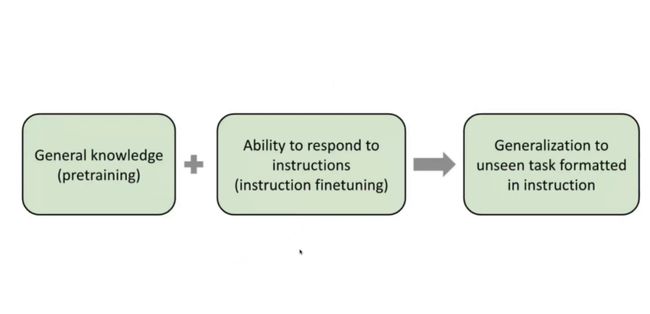
Instruction finetuning,主要是想让语言模型学习理解指令,不是想让语言模型解决成千上万任务,当然训练方式中是有很多任务,因为不同任务有不同的指令,所以目的还是想让模型理解这些指令,解决各种任务问题。在真实世界中,总会有新任务,模型只要学习新任务的新指令,那么就能解决新任务。指令学习本质是把语言模型的问题用语言讲出来。

这是我们在Hugging Face上的一个演示模型,i-like-flan。Flan就是指令微调的语言模型,现在在Hugging Face上可以看到Flan-T5。
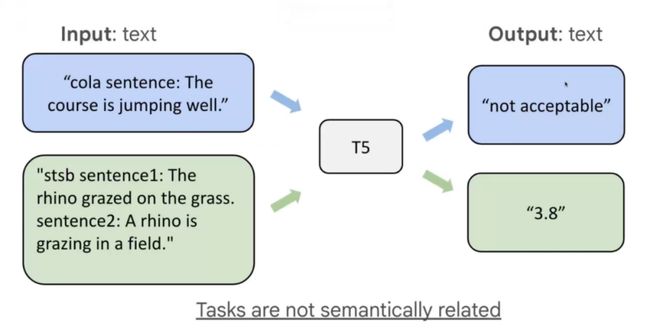
T5原本的训练方式是通过prefix,实际不是通过自然语言方式告诉模型想要模型做什么。
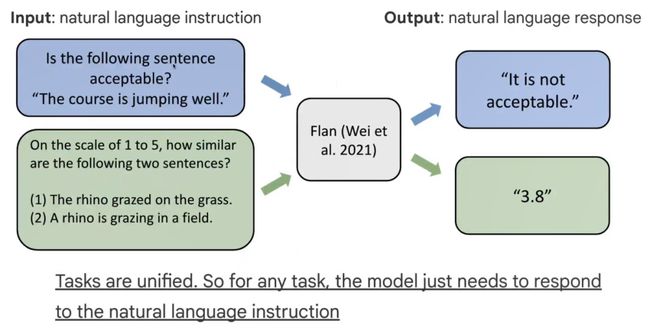
Flan这种方式通过Instruction方式,也就是人类可以看懂的方式去告诉模型要做什么。
“
更大规模、更多任务:
指令微调的大规模扩展

我们最新的工作Scaling Instruction-Finetuned Language Models[2]将现有的几乎所有任务都加进去,用上大模型,进行指令微调看模型的极限效果。
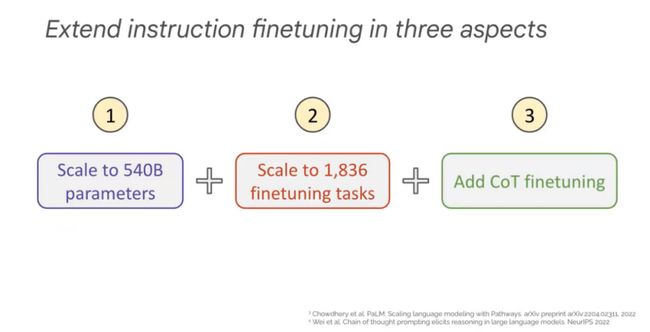
我们从三个方面改变指令微调,一是改变模型参数,提升到了540B,二是增加到了1836个微调任务,三是加上Chain of thought微调的数据。
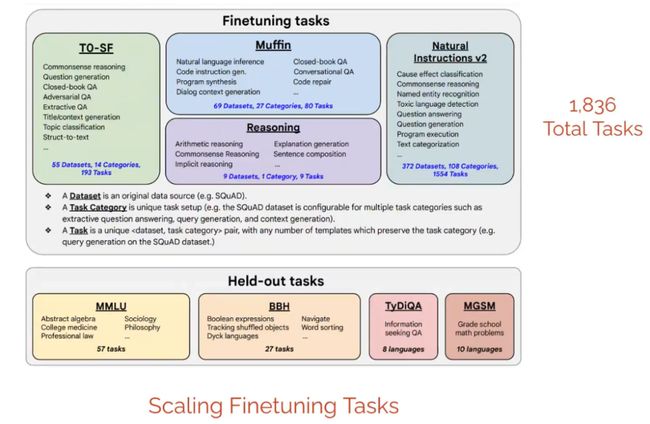
训练模型时的微调任务主要有Muffin、T0-SF、Reasoning、Natural Instructions v2四类一共1836个任务,每个任务大概10个zero-shot指令。测试模型的任务有MMLU、BBH、TyDiQA与MGSM的多语言多任务的考试任务。

比如,Massive Multitask Language Understanding(MMLU)数据集中的数据考验模型对于世界理解的能力,模型必须得具备大量知识。

BIG-Bench Hard(BBH)是在BIG-Bench的subset上所有具有挑战性的任务,因为已经有不少任务对于大模型来说已经可以解决的不错。上图例子中问题就很难,问的是坐标连起来是什么图形。

MGSM是一个多语言的问答问题,考验模型跨语言回答问题的能力。
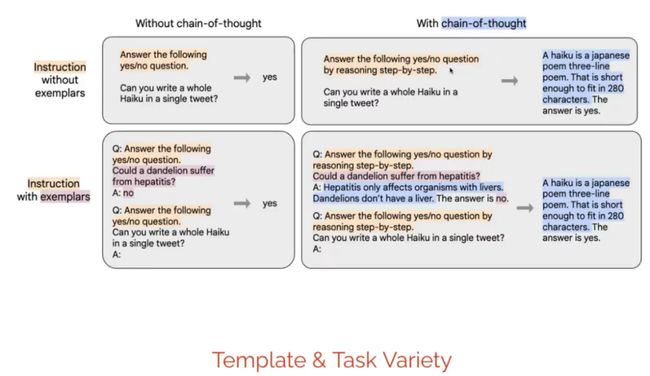
Instruction Template也很重要,模板越多,模型能够更好的学习指令。当然我们也设置了很多指令模板,是Instruction、exemplar、Chain of thought的组合,最终指令模板有1500多个。
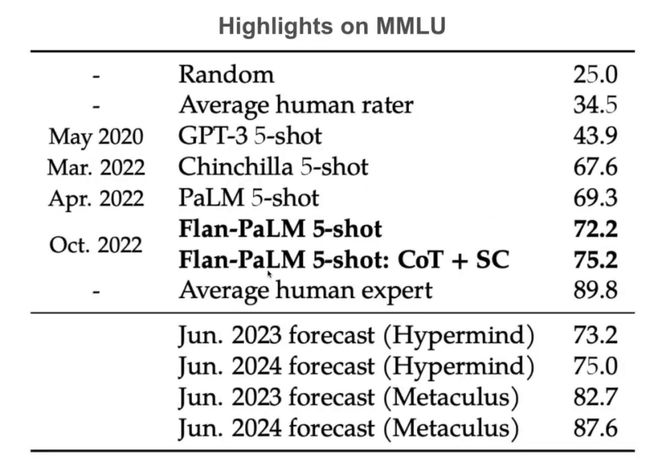
通过实验,模型在MMLU任务上表现很好。Chinchilla是Deep Mind的提出的方法,Chinchilla 5-shot达到67.6%时已经很震撼,我们的Flan-PaLM 5-shot:Cot+SC可以达到75.2%。MMLU任务重要性在于主要考验模型对于世界的理解能力。语言模型大部分还是跟对于世界理解能力很相关的。
Hypermind在我们论文出来之前已经预测过在2023年模型的得分能达到73.2%,2024年达到75%。我们现在已经达到了。斯坦福的Metaculus小组提出我们如果可以结合很多模型,如果某个模型在数学上好,就用这个模型在MMLU的数学subset上面学习,另外模型在物理上表现好,就用那个模型在MMLU的物理subset上面学习。如果这样,在2023年他们预测能达到82.7%,在2024年达到87.6%。
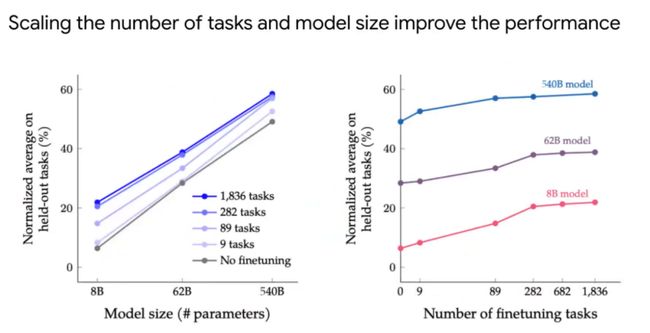
实验中,我们也比较了指令的数量与模型大小哪一个更重要?如果目的是使得模型达到人类水平,重点是训练更大模型还是增加更多指令微调的任务。左边图可以看出,在一定的任务数量下,模型参数从8B到62B到540B,模型效果有明显提升。如果在一定参数量下,增加任务模型效果会有提升,但在一定数量任务后,会达到饱和。右图也是说明同样的问题。
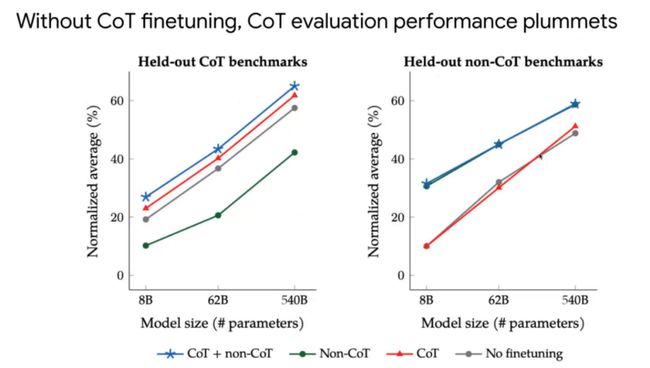
我们也验证了加了Reasoning数据的结果,也就是加上Chain of thought的数据去微调的结果,整体加上Chain of thought的数据去微调效果会更好。
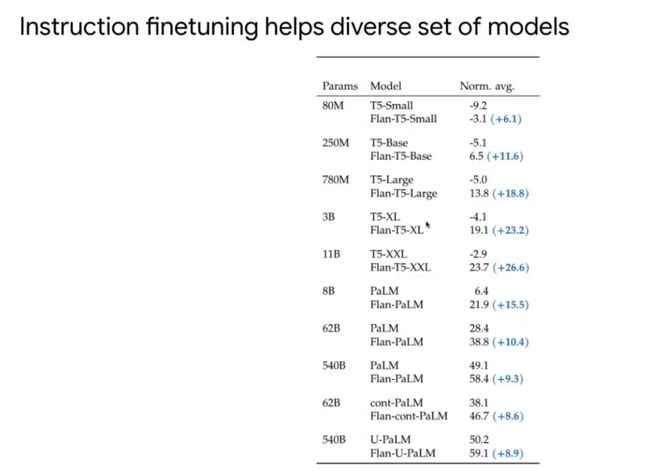
我们也测试了T5、PaLM系列模型的结果,T5是编码器-解码器架构,PaLM的一个解码器架构,加上我们的指令微调方式后效果都有提升。

最终,我们想说明的是我们应该永远都微调一个模型,而不是用一个预训练的模型做Prompt工程。微调模型用到的资源只有预训练用到资源的百分之零点几,我们可以得到明显效果的提升,对于大、小模型都适用。

“
大模型也可以自我思考:
让模型自己改进自己
机器学习还是需要成千上万的任务与数据,人类大脑可能可以直接冥想思考,也是无监督训练方式,我们这里起名叫Self-Improve,比较接近人类思考方式。我们最近的工作[3]就在研究这个问题。

我们如何教大语言模型思考?我们可以先让大语言模型生成一些问题,通过Few-shot方式生成。比如先给第一个、第二个问题,模型生成第三个问题。

模型生成成千上万的新问题,新问题没有答案,让模型利用计算资源尽可能去解决这些问题。
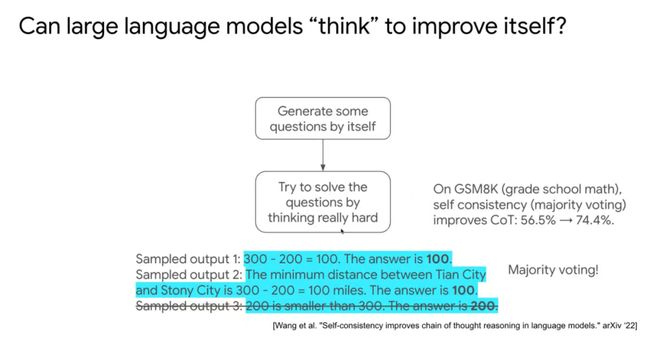
我们使用一种Majority voting的方式采样解码得出最后答案。这样可以明显提升模型的能力,比如在算术问题上准确率从56.5%提升到74.4%。然后再把这些生成的问题与答案当成训练数据再去训练模型。
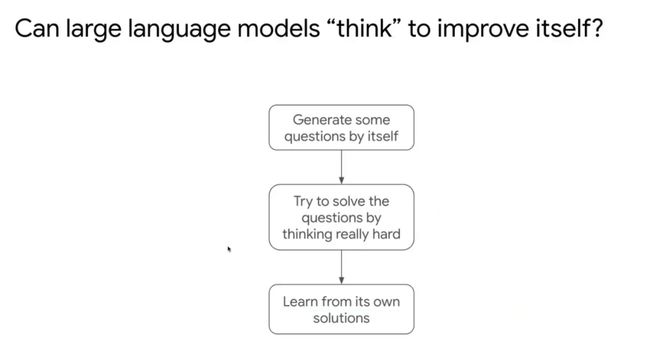
这样整个过程模拟人类的学习过程。

可以看到,算术能力从56.5%提升到了66.2%,如果加上self-consistency,可以从74.4%提升到78.1%。如果假设问题是完美的,只用数据集中的问题,不用问题的答案,那么提升效果更明显,算术能力从56.5%提升到了73.5%,如果加上self-consistency,可以从74.4%提升到82.1%,已经跟SOTA相近。
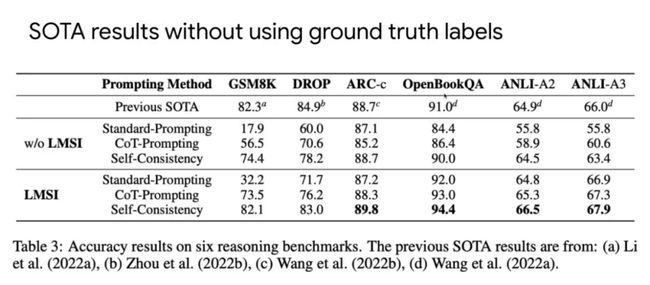
实验结果表明,在GSM8K、DROP上接近SOTA,在ARC-c、OpenBookQA、ANLI-A2、ANLI-A3上取得了SOTA结果。
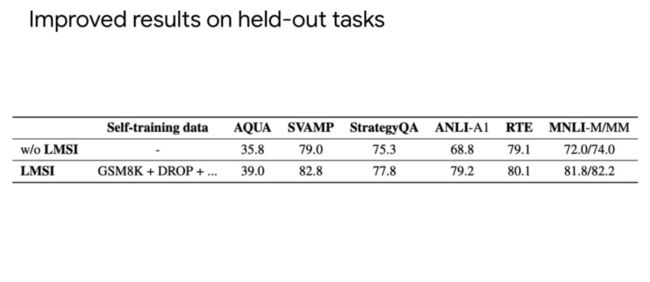
另外,实验结果也表明,即便是模型应用在没有见过的数据集上,效果仍然也有提升。所以,自我提升的学习并不是让模型适应了某些任务,而是让模型有更好能力的提升。

Instruction finetuning就是Finetuning language model to follow instructions,训练中有1800左右个任务,接近2000个Instruction Template。模型通过学习Instruction,在没有见过的任务上表现依旧不错。Self-improvement是让模型自己生成问题,自我思考,学习出答案,在推理任务上取得了SOTA结果。
参考文献
[1] Wei J, Bosma M, Zhao V Y, et al. Finetuned language models are zero-shot learners[J]. arXiv preprint arXiv:2109.01652, 2021.
[2] Chung H W, Hou L, Longpre S, et al. Scaling Instruction-Finetuned Language Models[J]. arXiv preprint arXiv:2210.11416, 2022.
[3] Huang J, Gu S S, Hou L, et al. Large Language Models Can Self-Improve[J]. arXiv preprint arXiv:2210.11610, 2022.
“
现场问答
1、在工程中,Prompt tuning中有哪些Tricks?
侯乐:Trick的复现性不是太高,换模型可能就不适用,做Prompt tuning时尽量做的是直接提升的方法,MMLU任务上我们用few-shot的方式解答,给了一个通用的Trick是训练时模型设计更多样,如果模板设计的好,能匹配到下游任务的提问,那么效果就会好一些。
2、对于没有Ground truth的任务,可以使用您总结中提到的两种方法吗?
侯乐:如果没有Ground truth的任务,对于Instruction finetuning就没有应用方式,但对于Self-improvement是可以的。因为Self-improvement是生成的Ground truth,在训练时也很有用。
3、语言模型是否可以拥有物理直觉?比如三个齿轮一字排开,相邻齿轮咬合,提问转动最左边的齿轮,最右边怎么转动?
侯乐:我觉得可能是可以做到的,因为训练数据中可能有这样的样本。首先模型做数学任务已经不错,也是通过数据硬学习。
4、Zero-shot CoT中效果貌似更差了,如果采用这个模型,是不是自己得准备很多样本?
侯乐:CoT不一定比没有CoT要好,因为CoT在推理问题上,有中间解答过程,回答时候推理出来可能效果比较好。但有一些问题要基于知识,推理不出来,那么这类问题可能效果就不好。所以分开推理的任务和知识的任务更能明显比较。此外,如果你不给模型few-shot的样子,肯定不如给样例的好。预训练的模型做CoT任务可能不如微调后做CoT。
5、现在已经有哪些模型开源了?
侯乐:T5系列在Hugging face上开源,也有Demo。尤其是Flan-T5。
6、大模型的评测指标中,可能与人类的指标相似,实际使用中,模型可能不好用,怎么看这种Gap?
侯乐:模型类似像一些有交流障碍的人,预训练相当于看了一堆书,很聪明,做题能力也挺强,但是没交流过,所以交流不通顺。我们经过指令微调后,会提升交流能力,但是也还是不高。
7、人类执行的指令经过大量学习,指令学习和预训练的结合怎么保持平衡?
侯乐:我认为如果指令微调的数据足够多,是不需要预训练的数据。目前预训练是因为没有太多的指令微调数据,指令微调数据需要人为构造,质量非常高。
8、Flan-T5可以做逻辑计算吗?
侯乐:这得看训练数据中是否有逻辑的问题,能否激发出模型的这方面能力。
9、垂直领域需要做文本摘要任务时,提取需要的文本关键信息,这种情况下使用Chain of thought会比Prompt更好吗?
侯乐:我认为不会,我们训练数据中没有摘要Chain of thought的数据。摘要这种任务还是不太适合Chain of thought。
10、语言模型对于长文本输入预训练有哪些技巧?将《三国演义》整本书输入,能生成故事线逻辑吗?
侯乐:Transformer的计算复杂度跟输入成平方关系,《三国演义》整本书太长了,没法计算。即便是能计算,但是attention效果也不太好。比如现在long-T5解决长文本的问题,attention到每一页的Token,但是我认为效果还不好。目前大约是处理1000个左右英文单词。
11、指令微调在推理或知识任务上进行过有效性分析吗?
侯乐:知识任务没有太多分析。我们也注意到在MMLU中,我认为99%以上知识都是从预训练的训练数据中学习来的,微调数据中没有知识,所以基本不会学习到知识。
12、指令微调如何结合预训练做更多的应用?
侯乐:现在已经有ex-T5,将下游微调的数据与预训练的数据混合在一起训练,但是规模还不大,比较有前景。现有针对各个任务数据再微调太麻烦。
13、指令微调对语言模型的落地应用有哪些帮助?
侯乐:会使得模型变得更鲁棒,更好应对各种情况。比如一个模型没有指令微调,不同人提问方式不同,答案可能有问题,所以这种也会提升鲁棒性,我们做的工作也在做这些工作。
活动视频回放:https://event.baai.ac.cn/activities/580
更多内容 尽在智源社区公众号