移动深度学习:人工智能的深水区
人工智能技术经历6年的快速发展,重新定义了很多行业的用户体验,而这仅是开始。
随着5G商用大规模落地,以及智能手机硬件性能越来越强、AIoT设备的快速普及,基于云-边缘-端算法和算力结构的移动端人工智能,仍有非常大的发展空间,亟待我们快速理解移动端深度学习的原理,掌握如何将其应用到实际业务中。

在互联网行业中,在移动端应用深度学习技术的案例越来越多。从深度学习技术的运行端来看,主要可以分为下面两种。
一种是完全运行在移动端,这种方式的优点显而易见,那就是体验好。在移动端高效运行神经网络,用户使用起来会感觉没有任何加载过程,非常流畅。前面的“拾相”和手机百度中的图像搜索都属于这一流派,还有其他一些比较好的应用,典型的如识别植物花卉的App“识花”。
另一种是在服务器端运行深度学习技术,移动端只负责UI展示。在第一种流派出现之前,绝大部分App都是使用这种在服务器端运算、在移动端展示的方式的。这种方式的优点是实现相对容易,开发成本低。
** ▊植物花卉识别**
花卉识别的App近两年来颇多,“识花”是微软亚洲研究院推出的一款用于识别花卉的 App,如下图所示,用户可以在拍摄后查看花卉信息,App会给出该类花卉的详细相关信息。精准的花卉分类是其对外宣传的一大亮点。

识花App
▊ 奇妙的风格化效果
将计算机视觉技术应用在App中,可以为图片实现滤镜效果。使用深度学习技术实现的风格化滤镜效果非常魔幻。例如,Philm这款App就可以提供非常出色的体验,它使用了深度学习技术,有不少风格化滤镜效果,下面第一张图是原图,第二张是增加滤镜效果之后的图。


Philm的滤镜效果展示
除此之外,还有许多产品也尝试了在移动端支持视频、图片的风格化,如Prisma和Artisto这两款App也都可以实现风格化的效果。
▊视频主体检测技术在App中的应用
深度学习技术在移动端的应用越来越多,视频主体检测技术在App中的应用也在加速。目前,手机使用视频主体检测技术进行身份认证已经是非常普遍的事。视频主体检测技术主要根据物体的特征来进行判别,整个流程(如识别和监测这样的操作)包含大量的神经网络计算。下图是我们团队在2017年做的一个Demo,它通过实时识别视频中的图像主体,再通过该区域进行图像搜索,就可以得到商品、明星等多种垂直分类相关图片的信息。
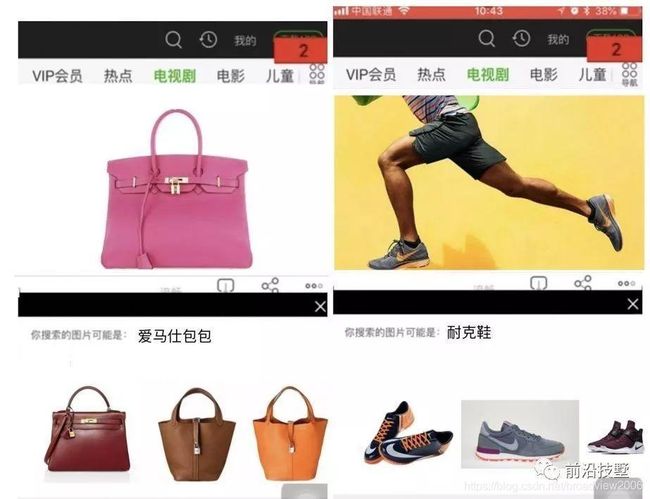
移动端视频播放器中的视频主体检测效果
你可能会问,这一功能的意义是什么?直接来看,我们可以利用此技术为视频动态添加演员注解,并且动态支持“跳转到xxx(某个明星的名字)出现的第一个镜头”这样的命令。扩展来看,我们还可以思考一下这一功能实现商业化的方式可能有哪些。例如,假设某个女士看到视频中出现了她喜欢的包包,但是不知道在哪里能够买到。使用了视频主体检测技术后,可以让用户自行筛选,然后在视频中自动提示包包的产地、品牌等信息,甚至可以让用户直接购买。这样就能扩展出非常多的移动AI场景。

在移动端应用深度学习技术,要考虑各种机型和App指标的限制,因此难点较多。如何使深度学习技术稳定高效地运行在移动设备上是最大的考验。拆解落地过程中的复杂算法问题,就是移动端团队面临的首要挑战。
▊在服务器端和移动端应用深度学习技术的难点对比
通过对比服务器端的情况,更容易呈现移动端应用深度学习技术的难点,对比如下表所示。
表:在服务器端和移动端应用深度学习技术的难点对比

在移动端App的开发过程中,需要克服以上所有困难,才能在移动端应用相关技术。将Demo的演示效果转化为亿级安装量的App线上效果,并不是一件容易的事情。在移动端和嵌入式设备的App中使用深度学习技术,可以大大提升App给用户带来的体验。但是,只应用深度学习技术还不能实现所有想要的效果,往往还要结合计算机视觉相关的技术,才能解决从实验到上线的难题。工程师需要具备很高的将工程与算法结合的能力,才能综合运用多种技术解决问题。在移动端应用深度学习技术时,往往没有太多可以查阅和参考的资料,需要开发人员活学活用,因地制宜。接下来通过实例看一下,如何使用诸多办法来实现AR实时翻译功能。
**▊ **实现AR实时翻译功能
AR实时翻译能够实现所见即所得的翻译效果,什么意思呢?来看下面的实例,在下图中,电脑屏幕上有“实时翻译”四个字,将其放在百度App图像搜索实时翻译框中,就能得到“Real-Time translation”,而且手机上的文字和电脑屏幕上的文字具有同样的背景色和字色。

实时翻译效果图
AR实时翻译功能最早在Google翻译软件中应用并上线,Google使用了翻译和OCR(图片转文本)模型全部离线的方式。翻译和OCR离线的好处是,用户不联网也能使用实时翻译功能,且每帧图像在及时处理运算后实时贴图,以达到即视效果。
但是全部离线的方式也有弊端,那就是OCR和翻译模型体积较大,且需要用户下载到手机中才可以使用。另外离线OCR和离线翻译模型压缩体积后会导致准确率降低,用户体验变差:Google翻译App中的词组翻译效果较好,在翻译整句和整段时表现就不够理想。
2017年下半年,笔者参与并主导了百度App中的实时翻译工作的落地。在开始时,团队面对的首要问题是,翻译计算过程是使用服务器端返回的结果,还是使用移动端的本地计算结果?如果使用移动端的计算结果,用户就不需要等待服务器端返回结果,能够减少不必要的延迟。我们只需要针对移动端的OCR和翻译的计算过程,在移动端做性能调优,即可保证每一帧图像都可以快速贴图。移动端性能优化技术其实是我们更擅长的。这样看来,似乎使用移动端计算结果的优点很多,但是其缺点也不容忽视——长文本可能出现“不说人话”的翻译效果。经过分析和讨论,我们回到问题的本质:AR实时翻译的本质是要给用户更好的翻译效果,而不是看似酷炫的实时贴合技术。
最后,我们选择了使用服务器端的返回结果。下图就是上线第一个版本后的试用效果,左边是原文,右边是融合了翻译结果和背景色的效果。

实时翻译效果图
上图中的效果,如果从头做这件事,应该如何拆解过程?首先,需要将文本提取和翻译分成两部分;接着,拿到翻译结果后,还需要找到之前的位置,准确地贴图。依次介绍如下。
- OCR提取文本
-
需要把单帧图片内的文本区域检测出来。a. 检测文本区域是典型的深度学习技术范畴,使用检测模型来处理。b. 对文本区域的准确识别决定了贴图和背景色的准确性。
-
要对文本的内容进行识别,就要知道写的具体是什么。a. 识别文本内容需要将图像信息转化为文本,这一过程可以在移动端进行,也可以在服务器端进行。其原理是使用深度学习分类能力,将包含字符的小图片逐个分类为文本字符。b. 使用的网络结构GRU是LSTM网络的一种变体,它比LSTM网络的结构更加简单,而且效果也很好,因此是当前非常流行的一种网络结构。
- 翻译获取
-
如果是在移动端进行文本提取,那么在得到提取的文本后,就要将文本作为请求源数据,发送到服务器端。服务器端返回数据后,就可以得到这一帧的最终翻译数据了。
-
请求网络进行图像翻译处理,移动端等待结果返回。
- 找到之前的位置
当翻译结果返回后,很可能遇到一个类似“刻舟求剑”的问题:在移动端发送请求并等待结果的过程中,用户可能移动了手机摄像头的位置,服务器端返回的结果就会和背景脱离关系,从而无法贴合到对应的位置,这是从服务器端提取结果的弊端。解决这一问题需要使用跟踪技术。
-
需要用一个完整的三维坐标系来描述空间,这样就能知道手机现在和刚才所处的位置。
-
需要倒推原来文本所在位置和现在的位置之间的偏移量。
-
在跟踪的同时需要提取文字的背景颜色,以尽量贴近原图效果。文字和背景的颜色提取后,在移动端学习得到一张和原文环境差不多的背景图片。
-
将服务器端返回的结果贴合在背景图片上,大功告成。
下图是我们团队在初期对AR实时翻译功能进行的技术拆解,从中可以看到,在移动端进行AI创新,往往需要融合使用深度学习和计算机视觉等技术。

实时翻译流程图
如果你看过AR实时翻译的案例后仍然觉得晦涩,请不要着急,等学过移动端的机器学习、线性代数、性能优化等后,就会觉得明朗许多。


移动深度学习需要克服模型压缩、编译裁剪、代码精简、多平台支持、汇编优化等诸多挑战,本书正是基于作者在此过程中的实战经验。首先介绍基础的数学原理和深度学习模型,然后深入移动计算设备的体系结构,以及如何在这种体系结构上进行高效的深度学习计算。
▶ 关 于 本 书
本书由浅入深地介绍了如何将深度学习技术应用到移动端运算领域,书中尽量避免罗列公式,尝试用浅显的语言和几何图形去解释相关内容。本书第1章展示了在移动端应用深度学习技术的Demo,帮助读者建立直观的认识;第2章至第4章讲述了如何在移动端项目中应用深度学习技术;第5章至第8章的难度略大,主要讲述如何深入地调整框架,适配并定制自己的框架。本书适合移动端研发工程师阅读,也适合所有对移动端运算领域感兴趣的朋友阅读。
▶ 关 于 作 者
李永会
百度App移动研发部资深工程师。2015年起在百度从事图像搜索和语音搜索客户端研发工作,主持了多个重要创新项目,包括百度Lens、实时翻译等。同时负责开源移动端深度学习框架Paddle-Lite的开发,长期从事移动端AI高性能计算优化工作,在多种软硬件平台上高性能运行深度学习技术。在工作之余有读史、书法等爱好。
![]()
本文由博客一文多发平台 OpenWrite 发布!