会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]
目录
-
- Caser
-
- 3 模型
-
- 3.1 嵌入层
- 3.2 卷积层
- 3.3 全连接层
- 3.4 训练
- 3.6 与一些模型的关系
- SASRec
-
- 2 RELATED WORK
- 3 METHODOLOGY
-
- 3.1 嵌入层
- 3.2 自注意力block
- 3.3 堆叠自注意力层
- 3.4 预测层
- 3.5 网络训练
- 3.7 讨论
- 4 实验
-
- 4.1 数据集
- 4.2 对比模型
- 4.3 实验细节
- 4.4 评价指标
- 4.5 推荐表现
- 4.6 消融实验
- 4.8 注意力权重可视化
- BERT4Rec
-
- ABSTRACT
- 2 RELATED WORK
-
- 2.1 通常的RS
- 2.2 序列推荐
- 2.3 注意力机制
- 3 BERT4REC
-
- 3.1 问题定义
- 3.2 模型架构
- 3.3 Transformer 层
- 3.4 嵌入层
- 3.5 输出层
- 3.6 模型学习
- 3.7 讨论
Caser
2018-WSDM-Personalized Top-N Sequential Recommendation via Convolutional Sequence Embedding
卷积序列推荐模型Caser,使用CNN从近期items序列中以局部特征的方式提取序列模式。
3 模型
为了捕获
- 用户的整体偏好和序列模式
- 联合级别和单独级别的i2i
- skip行为连接
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第1张图片](http://img.e-com-net.com/image/info8/095d132299884b5581814ac5068aa6d9.jpg)
3.1 嵌入层
user和item都有嵌入,在t时刻user的items集合是L个:
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第2张图片](http://img.e-com-net.com/image/info8/49b3b0f30bba4b678bee726ee79575fe.jpg)
3.2 卷积层
把 E 矩阵 L×d 看作"image",把序列模式看作 “image” 中的局部特征。
-
Horizontal 卷积
h×d,捕获联合级别的序列模式*(不会在嵌入维度之间进行卷积,就像textcnn一样)*
这个h就是 联合级别中联合的size -
行为序列(image): L×d
-
1个卷积核:h×d (如果num个filter h×d×num)
-
卷积操作:[L-h+1] ×1 (如果num个filter [L-h+1] ×1×num)
-
max pooling:1×1 (如果num个filter 1 ×1×num)
(总之每个filter最终提取的feature结果一定是1维的)
然后可以有不同h的卷积核,每个h的卷积核也可以有数量;最后得到的feature维度是 1× filter数量。k是filter的idx:
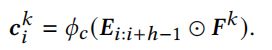
卷积操作
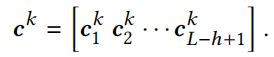
第k个filter卷积后得到的feature map (后续max池化就变成1维了)
![]()
n个filter池化后得到的feature
-
Vertical 卷积
L×1 卷积核,通过加权组合pre items得到特征向量,捕获单独级别的序列模式。 -
行为序列(image): L×d
-
1个卷积核:L×1 (如果num个filter L×1×num)
-
卷积操作:1×d (如果num个filter 1 ×d×num)
(总之每个filter最终提取的feature结果一定是d维的)
其实这种卷积就相当于对items的加权组合,卷积核 L×1 对应的就是这L个物品的权重,最后得到 num×d 的聚合特征:


3.3 全连接层
将Horizontal 卷积和Vertical 卷积得到的特征concat+MLP,得到卷积序列嵌入:

将卷积序列嵌入和user嵌入concat+MLP+sigmoid得到预测输出概率:
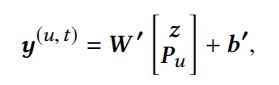
3.4 训练
注意为了捕获skip行为,预测的是next,next+1,next+2,…next+T-1;即:
![]()
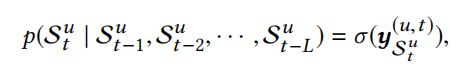

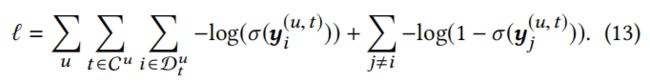
刚开始这个输出有点没看明白,以为要输出next item是所有候选item的概率(理论上应该要的),但一般都是softmax-每个正样本负采样-层次softmax-得到正样本+负样本的sigmoid loss,看这个意思就是:
- z是卷积序列嵌入,它是从t时刻前L个item的嵌入上整合出来的特征,或者说user的短期兴趣
- u是user嵌入,可以认为是user的长期兴趣
- 最后一层MLP的参数 W ′ W' W′ 可以看作item 作为target时的嵌入表,它的维度取决于 z维度+u维度 ;将target item 嵌入与 concat(z,uid) 做简单的MLP+sigmoid,得到在当前uid、t时刻items的情况下target item的概率(也可以认为就是target item 和cur sqe+uid 的表示做内积+sigmoid)
3.6 与一些模型的关系
很喜欢这一部分
- MF

- FPMC

- Fossil

SASRec
2018-ICDM-Self-Attentive Sequential Recommendation
序列动态,基于用户近期的行为,寻求捕获用户活动的上下文。两种方法:MC,认为next item和近几个item相关,适用于稀疏数据集;RNN,能捕获长距离的关系,适用于更密集的数据集。本文提出SASRec,能够捕获长距离语义,又能使用注意力机制让其预测基于相关的少量行为。
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第3张图片](http://img.e-com-net.com/image/info8/5ceb92cfd74449af89ffb40c1b60cecd.jpg)
2 RELATED WORK
-
常规(通用)的推荐*(不知道咋翻译合适)*
- MF
- ISM,不学习用户的嵌入,只学习i2i相似度矩阵,衡量target item和user history items的相似度
- DL,(1)使用nn提取item特征;(2)替代MF中的内积,如NCF、AutoRec
-
时间的推荐
- 显式对用户活动的时间戳进行建模,TimeSVD++,适用于展现出时间漂移的数据集
- 注:时间的推荐和序列推荐(next item rs)是不同的,序列推荐只考虑行为的序关系,对序列模式(是独立于时间之外的)建模
-
序列推荐
- i2i转移矩阵,FPMC(一阶MC)、Caser(高阶MCs)
- RNN类,GRU4Rec
-
注意力机制
- 作为附加组件+原始模型
- Transfomer,完全依靠自注意力机制
3 METHODOLOGY
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第4张图片](http://img.e-com-net.com/image/info8/1c28f636961c4279ac52fa219226cb8a.jpg)
输入:
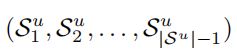
期望输出:
![]()
3.1 嵌入层
固定输入序列长度为n,不够的用pad填充,pad的嵌入为常数0向量
位置嵌入P,加上物品嵌入E,得初始嵌入:
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第5张图片](http://img.e-com-net.com/image/info8/ded15c7a80604d93ad47c73347f46256.jpg)
3.2 自注意力block

自注意力层:在NLP中,通常K=V(RNN encoder-decoder翻译任务,encoder隐藏层做K和V,decoder隐藏层做Q)
本文的自注意力层以 E ^ \hat E E^ 为输入,通过三个投影矩阵进行线性映射做Q K V,
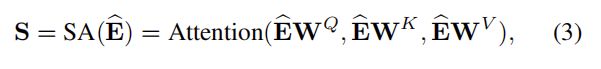
(这种投影让模型更灵活,比如 < q i , k j >
<qi,kj> 和 < q j , k i >
<qj,ki> 可以是不同的)
因果关系:考虑 t+1 的item时,应该只考虑前t个items,所以禁止 j > i j>i j>i的 Q i , K j Q_i,K_j Qi,Kj
Ponit-Wise 的FFN:虽然自注意力能够自适应的赋予previous items的权重,但它仍然是一个线性模型。为了赋予模型非线性并且考虑不同隐维度之间的交互作用,对于所有的S添加了两层FFN
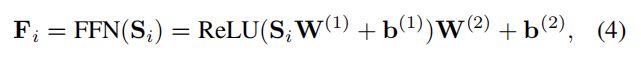
3.3 堆叠自注意力层
堆叠多个自注意力层可能有助于学习更复杂的物品转移关系:
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第6张图片](http://img.e-com-net.com/image/info8/c3a969b0c9ad4ae2a0b5080d4bb1124b.jpg)
随着网络加深,带来一些问题:
- 过拟合
- 训练过程不稳定(梯度消失等)
- 更多的参数加大训练时间
解决方法:
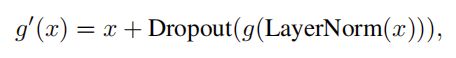
对于 1)自注意力层和 2)FFN:
输入x——LN(x)——送入函数g()——dropout(输出)——残差add输入x
残差连接:核心思想是通过残差连接将低层的特征传播到更高的层
层归一化:normalize the inputs across features,有助于稳定和加速神经网络的训练
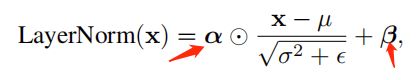
丢弃
3.4 预测层
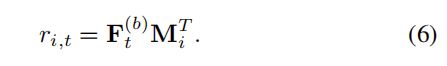
预测某个序列 t+1 时刻的item时,我们基于 序列 t 时刻的模型输出和所有target item的嵌入 做内积

(注:提到了FPMC需要使用不同的item嵌入,应该是说 item 做序列中的 history一项 的嵌入和 item 做 target的嵌入不同,这是为了构造不对称的转移关系;而本文的F和M共享 Items嵌入,因为模型设计的 i j 输出 和 j i输出不对称)
显式用户建模,两种方式:
- 学显式的用户嵌入来表示用户偏好
- 考虑用户之前的history,从history items中产生一个隐式的用户嵌入
本文对于一个序列产生的 F n F_n Fn 就可以看作是第2种方法,即将序列的最终表示作为用户表示;也可以用第1种方法,再加一个用户嵌入表 U,把 F n F_n Fn 看作history 表示,U+F 联合表示用户+his序列 ;
![]()
本文使用的是方法2。
3.5 网络训练
给定输入序列 s = s 1 , s 2 , s 3 , . . . , s n s={s_1,s_2,s_3,...,s_n} s=s1,s2,s3,...,sn,t时刻的期望输出为:
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第7张图片](http://img.e-com-net.com/image/info8/413b2b5821b74fa9be05c539313e26be.jpg)
注意输入和输出长度相同都为n,因为输入 s1,s2,…sn;label是s2,s3,…,sn+1。
(这才知道序列推荐是seq2seq,不知道是不是全是这样,还是可以只考虑预测 n+1时刻)
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第8张图片](http://img.e-com-net.com/image/info8/71b00fffaa644927b9911e18defd80b4.jpg)
每个epoch,要为 st 随机采样负样本
3.7 讨论
可以看成这些模型的扩展版:
- Factorized Markov Chains—FMC
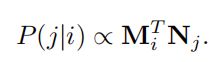
- Factorized Personalized Markov Chains—FPMC
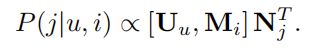
- Factorized Item Similarity Models—FISM;移去FFN,自注意力层设为平均权重
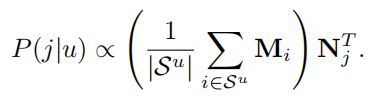
4 实验
4.1 数据集
数据集划分成三部分,每个用户的行为序列中:
- 最后一个item做test
- 倒数第二个item做valid
- 0-倒数第三个 做train
- 注意:test的时候,train+valid做train
4.2 对比模型
4.3 实验细节
2层自注意层
4.4 评价指标
Hit Rate@10、NDCG@10
4.5 推荐表现
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第9张图片](http://img.e-com-net.com/image/info8/bc1e509767114f708a2229b6dd534abb.jpg)
4.6 消融实验
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第10张图片](http://img.e-com-net.com/image/info8/0aecab7d8b4e4a68ab612261ed4f5add.jpg)
4.8 注意力权重可视化
在不同time上,近15个item位置上的平均注意力得分
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第11张图片](http://img.e-com-net.com/image/info8/c6b0028d4f8b416a9232e1c564af06df.jpg)
item之间的注意力得分,能够证明注意力机制能够识别出相似的(同一类)items,即attention score更高:
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第12张图片](http://img.e-com-net.com/image/info8/5fbcf1bde5224df39bd4b05e7cc9f3c9.jpg)
BERT4Rec
2019-CIKM-BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer
ABSTRACT
之前的研究使用序列神经网络,从左到右编码用户的交互记录,编码为隐藏表示。本文认为这种从左到右的单向模型是次优解,因为:
- 单向架构限制了用户行为序列中隐藏表示的能力;
- 它们通常假设有一个严格有序的顺序,而这并不总是实际的。
本文提出BERT4Rec,采用Cloze task的损失函数(为了避免信息泄露),联合使用左右上下文来预测随机mask的物品。
2 RELATED WORK
2.1 通常的RS
-
早期的CF:
- MF
- item-based neighborhood methods,衡量target item和user的历史交互Items的相似度 (根据预先计算好的i2i相似性)
-
Deep Learning:
- 整合从side info中学习到的item表示
- 代替传统的内积:NCF、AutoRec、CDAE
2.2 序列推荐
- MC马尔可夫链,一阶MCs、高阶MCs
- RNN,将用户之前的记录encode一个向量
- GRU4Rec、DREAM、NARM
- 其他DL网络
- Caser、记忆网络、STAMP
2.3 注意力机制
- 把注意力机制当作原始模型的一个附加组件
- Transformer、BERT完全建立在多头自注意力机制上, SASRec
3 BERT4REC
3.1 问题定义
用户的时间顺序交互序列:

任务,建模用户在下一时刻对所有物品的点击可能性:
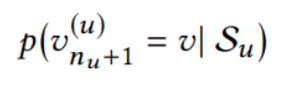
3.2 模型架构
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第13张图片](http://img.e-com-net.com/image/info8/5f8e1923fa494644a228a1cc2591b485.jpg)
不同于RNN和SASRec的单向建模,本文的模型是双向建模
3.3 Transformer 层
多头自注意力
d维的表示,线性投影到h个子空间中,每个子空间中纬度 d/h;每层的投影矩阵有3个,并且不同层之间的投影矩阵不共享
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第14张图片](http://img.e-com-net.com/image/info8/46707e686f0a42e695ac3cd8641908b2.jpg)
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第15张图片](http://img.e-com-net.com/image/info8/be8b865b1e454ecb82bc0ff0e69efd49.jpg)
按位置的前馈神经网络
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第16张图片](http://img.e-com-net.com/image/info8/04d3a1069c314c289b0632cb1bc72aaf.jpg)
W、b这些参数在不同的层与层之间是不同的
堆叠Transformer层
堆叠更多的Transformer层来学习更复杂的item转移模式;由于多层训练困难,增加了残差连接+dropout+LN:

总结:
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第17张图片](http://img.e-com-net.com/image/info8/8f83a67a41f24e7f85f6c42d0350d6c0.jpg)
3.4 嵌入层
在多层Trim的最底部加上位置嵌入p
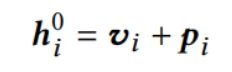
3.5 输出层
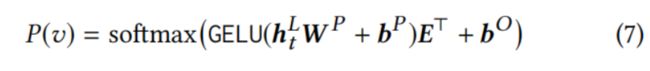
其中E是物品的嵌入表,在输入和输出使用共享的物品嵌入表来缓解过拟合和减少参数
(Q:共享item嵌入表指的是,h的输入就是E吗?)
3.6 模型学习
传统的单向序列推荐,预测输入序列的下一个物品;即输入【 v 1 , . . . , v t v_1,...,v_t v1,...,vt】,traget是【 v 2 , . . . , v t + 1 v_2,...,v_{t+1} v2,...,vt+1】
本文训练目标使用Cloze task (Masked Language Model),在每个train step,随机mask掉输入序列 ρ比例的items,使用其左右来预测它:
![会话/序列推荐:Caser、SASRec、BERT4Rec [Session based / Sequential Recommendation]_第18张图片](http://img.e-com-net.com/image/info8/3a9d36d8ce294a5f8dee9d67521cd064.jpg)
这种task是预测随机mask处,为了适合序列推荐,在用户历史序列最后加入了一个特殊的token [mask],基于最终token的表示来预测next item;因此训练的时候也mask掉每个输入序列的最后一个item。
(Q:这为啥类似于 fine-tuning ?)