从《开源大数据热力报告》看大数据技术发展
01 《开源大数据热力报告》简单介绍
《开源大数据热力报告》是开放原子基金会、开放实验室X-lab、阿里巴巴开源联合出品的,关于定量分析“后Hadoop时代”开源项目和技术趋势的分析报告,报告对开源大数据的技术趋势发展,以及开源社区的运作模式对技术走向的助推作用进行分析。
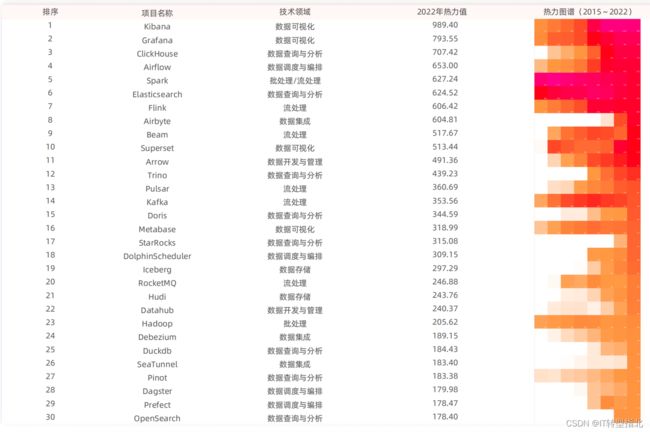
报告通过热力值进行定量分析,热力值指标刻画了开源项目的活跃度以及受欢迎程度,指标从项目关注(star)、社区反馈(issue)以及开发协作(pr、review、merge)加权计算获得。
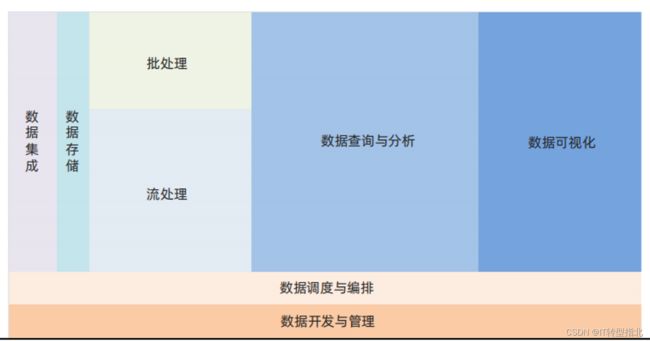
按照数据处理的生命周期,对开源大数据项目做了技术分类,包括数据集成、数据存储、批处理、流处理、数据查询和分析、数据可视化、数据调度与编排、数据开发与管理。
(关注公众号:IT转型指北,回复【开源大数据】,下载报告)
02 报告之我见
开源大数据技术的发展反映了用户痛点的产生和转移,以解决用户的需求为核心。
从功能层面,解决用户的实际问题
从效率层面:对使用用户而言,追求极致的用户体验,使用门槛不能太高,过程是低代码化的;从架构层面出发,大数据各领域通过与云原生结合,解决了弹性和韧性的问题
从成本层面:大数据技术向一体化方向发展,从技术的更新迭代来看,技术领域的马太效应会更加明显,针对应用场景单一、多栈融合门槛较高的技术会加速淘汰。趋向单一技术栈解决多场景问题,这个从某种程度上降低了企业技术架构的复杂度,有效控制了管理成本。
我们以这个思路带入再来看整个报告:
热力变迁反映技术趋势,但同时热力变迁所在的领域,也反映了用户痛点的产生和转移。
一、数据查询与分析连续8年位于热力值榜首
连续8点位于榜首传递两个信息,第一个是离业务最近的地方往往痛点更容易被发现,第二个是当下的技术仍在一个不断探索和发展的阶段。
信息化阶段基于信息技术驱动构建能力,对数据的重视度不够,而到了企业数字化阶段,基于数据驱动决策智能,企业对数据查询与分析的需求也越来越旺盛, 其一是从能查跃迁到查得快,一大批开源/商业化产品致力于解决这个问题,各种benchmark测试结果的宣推铺天盖地,在某个系分场景下都会说自己是第一。其二是从聚焦在特定领域出发解决查询和分析需求,如应对海量IOT相关数据的快速查询等。
本次开源大数据项目热力TOP30中,有8个数据查询与分析领域的项目上榜,分别是ClickHouse、Elasticsearch、Trino、Doris、StarRocks、Duckdb、Pinot、OpenSearch。而传统大数据领域的解决方案项目如hive、hbase、phoenix、kylin、tez、pig已经远远落后于榜上的同领域项目,企业需要对基线和目标做差距分析,并制定一定的迁移规划,来完成技术的迭代升级。
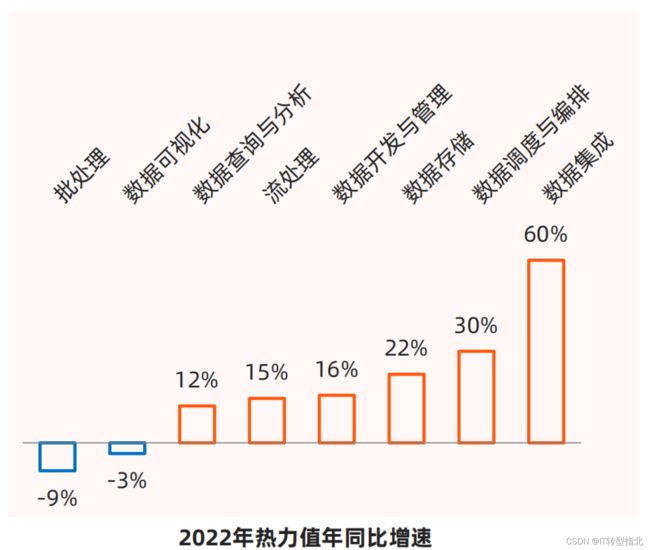
二、2017年流处理热力值超过了批处理,大数据处理进入实时阶段
流处理可以分为流计算引擎和消息队列,流处理2022年的热力值同比增速15%,虽然不是最高的,有一个核心原因是是流处理领域的技术解决方案相对比较单一,Flink作为流处理计算引擎堪称绝对的核心,而且整个流处理生态的上下游,只要涉及到数据操作的,Flink都能做。
本次开源大数据项目热力TOP30中,有5个流处理领域的项目上榜,分别是Flink、Beam、Pulsar、Kafka、RocketMQ,以中间件居多。
三、数据集成、数据调度与编排、数据开发与管理在爆发式增长。
这三个是DataOps的核心部分,数据集成的快速发展,一方面在解决数据规模大、数据结构多样化的显性问题外,还一个重要的原因,这是企业应用的多云架构与当下集中式数据架构(中台、仓、湖)的冲突体现,每天大量的物理搬迁工作需要被稳定执行,技术也在支持更多的数据源类型、与分布式计算融合上方向上发展,过程中如对数据源的支持度较差的sqoop已经逐步被淘汰。本次开源大数据项目热力TOP30中,3个项目上榜,分别是Airbyte、Debezium、SeaTunnel。
数据开发与管理上,领域较广,可切入的角度也比较多,比如做安全相关的Knox、做交互式开发的Zeppelin、Notebook,LinkedIn开源的元数据管理的Datahub、大数据权限管理Ranger等等。但从事数据开发的都知道,数据的标准、质量是要在数据操作的过程中落地,只有前向治理才是长效的运营机制,所以未来的数据开发与管理需要平台化,这个平台提供一体化的能力,技术发展的百花齐放一定程度上也带来技术体系难融合的问题。本次开源大数据项目热力TOP30中,有2个项目上榜,分别是Arrow、Datahub。
针对数据调度与编排领域,报告中并没有给太多的数据,但是企业仍旧面临多云统一调度的联动、以及如何与数据集成、数据开发做深度融合的实际问题。其中,多云统一调度的联动并非简单的技术替换,而是融合。企业内部的环境比较复杂,面临着商业产品、开源产品并存,以及多技术体系的并存问题,整体替换的成本和风险较大。本次开源大数据项目热力TOP30中,有4个项目上榜,分别是Airflow、DolphinScheduler、Dagster、Prefect。
这三个领域的联动性比较大,很难拆开来看,企业更倾向于通过集中化平台去完成集成、开发、调度和管理。市面上类似这样的商业化数据平台也被厂商冠上“数据中台”去推广和售卖。
四、数据湖相关技术以年均34%的复合增长率高居热点技术领域第一名
随着大数据应用场景和数据规模的不断增多,企业越来越注意到数据的低成本管理、存储和分析。数据湖技术的诞生,给了一个新的视角来看数据架构,一直在讨论的话题包括数据湖和数据仓库的关系、数据湖和数据中台的关系等等,从技术的本质讲,数据湖技术的出现解决了数据更新的问题,提到的存算分离架构,通过对象存储来解决低成本存储的问题并不仅仅是数据湖的特性。数据湖技术代表项目包括Iceberg、Hudi、DeltaLake。报告中提到了Alluxio,也算作数据湖的技术范围内,我认为在这个领域提到Alluxio,那么它和Juicefs一样,主要是解决存算分离下的数据缓存加速问题,以及与Presto集成加速数据查询。