RandLa-Net学习笔记
RandLa-Net开创了使用随机采样来处理点云的先河,并在大规模点云上取得了非常好的效果,远超基于PointNet的方法几条街。但是,作者在论文中只讲述了如何搭建模型和为什么要选择随机下采样,这对分析和理解整个点云处理过程是不够的。
因此,本文将从数据的角度出发,探析RanLa-Net数据预处理的方式,详细分析RandLa-Net的模型结构,从头开始重新理解点云分割。
作者温馨提示:本文干货满满,请各位同学系好安全带,酌情观看!
1. 引言
作者在论文中开片就提出了PointNet++中对数据进行采样存在的缺陷:
1.FPS仅适应小规模点云,对大规模点云采样速度过慢。
2.将点云分割为局部图像,会割裂物体之间的联系,导致网络无法感知全局信息。
对于第一个问题比较好理解,因为FPS算法计算量大,因此大规模点云采样速度会变慢。但是对于第二个问题,需要仔细阅读PointNet++的源码才能知道其原因。感兴趣的朋友可以看一下我这篇文章,它对PointNet++处理S3DIS数据集进行了详细的分析。
为了直观的讲解一下RanLa-Net与PointNet系列预处理方式的不同,我用2d图像来类比一下3d点云。下面假设这张图像就对应一个3d点云:

那么PointNet系列的采样方式就是如下图所示

PointNet系列一次采样就只采出了如图中红色框的区域,通过随机选取中心点,通过多次迭代,希望模型能够学习到全局的信息。
不同于PointNet,RandLA-Net的采样方式如下:

可以发现,它不仅会将原始图像(点云)进行下采样,缩小图像尺寸,还会扩大原始的采样区域,使其尽可能的覆盖整个区域。这种采样方式从直观上就要明显好于PointNet的采样方式,所以也是更利于模型学习的。此外,作者还进行很多这样类似的优化处理,这些内容将会在后面的章节进行逐一分析。
1.数据预处理
引言部分已经大致介绍了RandLA-Net与PointNet++采样的区别,接下来我们将对RanLa-Net采样代码进行详细分析。当我们按照作者ReadMe的提升,下载并将S3DIS数据集放到指定位置后,运行data_prepare_s3dis.py,对数据进行预处理,我们会获得以下两个文件
第一个文件是主要用来训练的文件,里面的分布如下图所示

对于每一个训练区域,都会生成一个ply文件和KDTree.pkl proj.pkl文件,前两个文件是用来训练的。第一个ply文件是将原始点云进行栅格采样后的输出结果,KDTree.pkl里面记录的是一个KDTree,用来快速实现查找邻居。这里不需要你知道它们具体如何使用,只需要知道有这个文件就可以,后面的内容会逐一进行介绍。
1.1 栅格采样与“概率采样”
对于一个数百万个点的点云数据来说,直接将其放入模型进行训练是不太现实的,因为需要花费昂贵的内存开销。因此,在点云处理的过程中通常也会先进行采样,先降低点的数量。
RandLa-Net首先会对点云进行栅格下采样,栅格采样能够极大的降低点的数量,同时尽可能的保证点云的几何结构,栅格采样后的点存放在ply文件中,是我们训练主要使用的文件。下面放一组点云栅格采样前后的对比图:
从中可以很明显的发现点变稀疏了,但基本上保留该点云的几何信息,不懂栅格采样的同学可以查看我的这篇文章。该操作与图像的缩放比较相似,都能够起到降低尺寸,保留空间信息的功能。但是,我们只能控制栅格采样的尺寸,也就是说只能控制采样点的间距,无法控制输出采样点的个数,这一点与图像缩放有较大差别。这样就导致每个点云的点数不一样。
虽然经过栅格采样,但是整个数据集点云的数量仍然很多,对于神经网络来说还是太多了。我们对S3DIS数据集进行统计,并将栅格采样后的点数进行了可视化:

从中可以发现,每个样本的数量仍然很多,且点数不均匀,因此还需要进行采样操作将输点云分割为数量统一的,能够送入模型训练的数据。
对于如何将点云采样到同一个点数,这里面又是一个深坑,不同的方法处理都不一样,这里就不过多介绍其他方法,直接开始讲解RandLA-Net是如何处理。
我们以S3DIS数据集为例,默认区域5为测试区域,其他区域用来训练,默认采样点数为40960。作者会为每个点云生成一个概率,也会为点云图像的每个颜色生成一个概率,利用概率对图像进行采样。下面我们直接以代码为例进行讲解:
self.possibility[self.split] = []
self.min_possibility[self.split] = []
for i, tree in enumerate(self.input_colors[split]):
self.possibility[split] += [np.random.rand(tree.data.shape[0]) * 1e-3]
self.min_possibility[split] += [float(np.min(self.possibility[split][-1]))]
这个代码通过for循环迭代遍历每个ply文件,也就是栅格采用后的文件中的颜色信息,其中split变量是用来区分训练集和验证集的,这里可以忽略。从代码中可以发现,self.possibility列表中每次会为每个点云生成一个概率。
例如一个点云的有N个点,那么它就会为每个点生成一个随机值,放入该列表中。self.min_possibility每次就将N个点中的最小的值存放进来。
这么直接讲可能还有点抽象,还是画图来说吧:
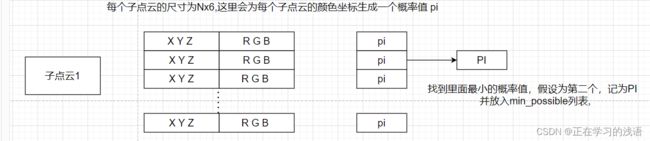
注意区分子点云的每个点的概率是小写的pi,这些点中最小的值为PI,存放在min_possibility中。
通过迭代遍历后,会得到下图所示的结果:

即min_possibility将每个子点云中的所有点的最小值存放了起来。此时,min_possibility列表中每个元素都是一个随机数,用来代表选取点该子点云的概率。
接下来,选取min_possibility中值最小的元素对应的索引,从所有点云样本中(即S3DIS对应的子房间数)将其作为本轮训练选中的样本,然后再次选中该样本中值最小的点的索引,并通过该索引找到子点云中对应的点,选中这个点作为采样的中心点,记为Center_point。
# Add noise to the center point
noise = np.random.normal(scale=cfg.noise_init / 10, size=center_point.shape)
pick_point = center_point + noise.astype(center_point.dtype)
继续为这个中心点添加一下噪声,增加更多的的随机性。
# Check if the number of points in the selected cloud is less than the predefined num_points
if len(points) < cfg.num_points:
# Query all points within the cloud
queried_idx = self.input_trees[self.split][cloud_idx].query(pick_point, k=len(points))[1][0]
else:
# Query the predefined number of points
queried_idx = self.input_trees[self.split][cloud_idx].query(pick_point, k=cfg.num_points)[1][0]
不知道大家是否记得前面说过的KDTree文件,之前一直没有用到它,现在终于可以用到它了。 我们以这个中心点为查询点去KDTree中查询它的40960个邻居点(返回为邻居值的索引),视为本次的采样点(感兴趣的同学可以了解一下这个是如何查询的)。下面的这个判断条件是用来解决查询点数不够的情况,如果不够40960个点就进行重复采样。
到了这里只是完成了对采样中心点的确认,我们还要对其进行更新,保证每次采样都能获得获得不一样的结果。每个点云的概率公式更新如下:
# 更新每个点的概率 方便下次选择
dists = np.sum(np.square((points[queried_idx] - pick_point).astype(np.float32)), axis=1) #计算查询点与中心点的距离
delta = np.square(1 - dists / np.max(dists)) # 对距离进行归一化,然后用1减
#这个delta是概率的更新量,距离越近,delta越大
self.possibility[self.split][cloud_idx][queried_idx] += delta #子点云的每个点都加上偏移量
self.min_possibility[self.split][cloud_idx] = float(np.min(self.possibility[self.split][cloud_idx])) #代表这个子点云的概率重新更新,再次选取所有点中的最小值。
1.2 数据的预准备
前面的小节讲了每轮数据是如何进行采样,并更新采样概率,为了进一步提升模型速度,作者还对数据输入做了手脚。
正常的模型训练都是将原始点云准备好,然后逐层进行前向传播,边传播边计算。但是,RandLA-Net貌似开创了先把每层的数据准备好,再开始训练的先河(我也不知道他是不是第一个,但是我是第一次见 -_-!~)
在学习具体怎么实现之前可以先想一个问题:即在目前点云的分割方法里,都是根据初始点的坐标开始下采样的,然后第二次下采样在第一次下采样的结果是继续进行下采样。这样我们就能够提前将它们下采样好,然后当模型需要这些时候就给他们送进去,这样模型就不需要在训练的时候进行邻居搜索的计算。这个代码如下所示:
for i in range(cfg.num_layers): # 模型的层数
##计算所有的点的邻居索引
neighbour_idx = DP.knn_search(batch_xyz, batch_xyz, cfg.k_n)
#对实际的点和邻居的索引进行下采样(DP.knn_search每次会打乱这个邻居索引)
sub_points = batch_xyz[:, :batch_xyz.shape[1] // cfg.sub_sampling_ratio[i], :]
pool_i = neighbour_idx[:, :batch_xyz.shape[1] // cfg.sub_sampling_ratio[i], :]
#通过下采样的点和未下采样的点计算 上采样的索引
up_i = DP.knn_search(sub_points, batch_xyz, 1)
input_points.append(batch_xyz)
input_neighbors.append(neighbour_idx)
input_pools.append(pool_i)
input_up_samples.append(up_i)
batch_xyz = sub_points
其实这个过程非常简单,现在看来,作者只是将模型训练采集邻居的时间,搬到了dataset中去采集而已(可能会在速度上有提示吧)。
2.模型结构
本小节将将从整体到局部逐一拆解详细分析RandLa-Net的模型结构。
2.1整体结构
该模型整体采取U-Net这样对称的编码-解码结构,充分融合不同维度的特征信息。下面以输入点数为40960为例进行讲解:
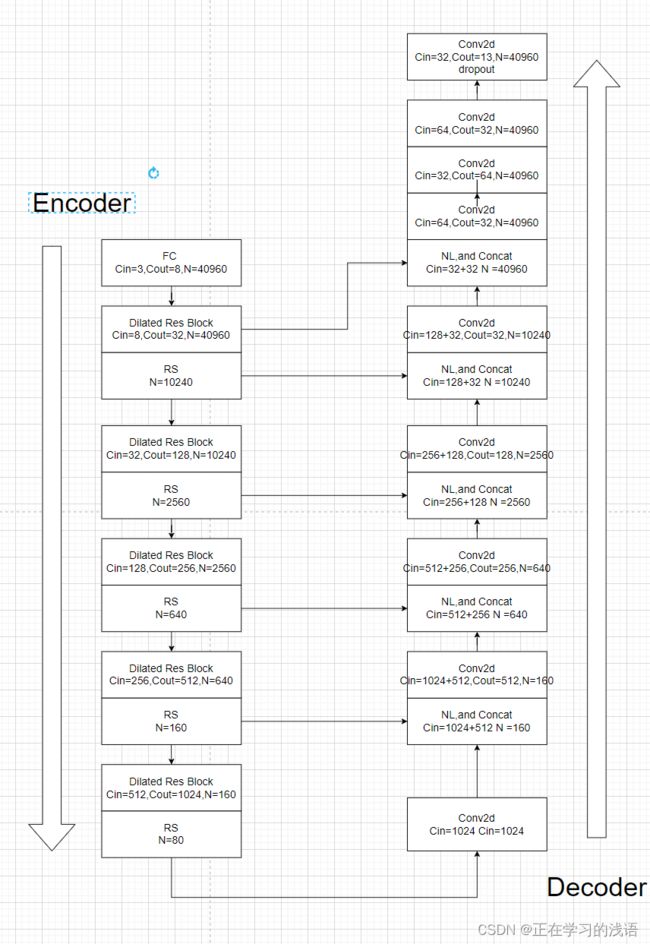
其中,Dliated Res Block 对应论文中的局部特征聚合结构,RS表示随机采样,NL表示邻近点插值(用来对图像进行上采样),每个模块的输入通道用Cin表示,输出用Cout表示,N表示点的数量,Concat表示拼接操作。每个模块的细节将会在之后详细讲解。
该模型整体结构比较简单,通过一系列的Dialted Res Block模块的堆叠组成,总共经历五次下采样和五次上采样。值得注意的是最后一次上采样后是与第一个Dilated模块的输出进行拼接的。
2.2 Dilated Res Block
这个模块是该模型的核心模块,主要结构如下所示:

这里就是一个简单的残差连接,并不是这里的重点。请注意图中画的通道数是指模型输出的通道数(不是输入)。该模块最主要的就是building block,它主要完成了论文里说的局部特征聚合。它的结构如下所示:

相对位置编码(res_psition_encoding)是将第i层的xyz坐标信息进行整合,添加额外的坐标信息,具体的实现方式就是将原始xyz坐标,坐标邻居小组的偏移量,坐标的距离求和坐标邻居小组进行拼接,具体代码如下所示:
def relative_pos_encoding(self, xyz, neigh_idx):
# xyz shape : BxNx3
num_knn = neigh_idx.size()[2] # k
grouped_xyz = self.gather_neighbour(xyz, neigh_idx).permute(0, 2, 1, 3) # BxNxKx3
xyz_tile = torch.unsqueeze(xyz, dim=2).repeat(1, 1, num_knn, 1) # B,3,N,k
relative_xyz = xyz_tile - grouped_xyz
relative_dis = torch.sqrt(torch.sum(relative_xyz ** 2, dim=-1, keepdim=True)) # B,1,N,K
relative_feature = torch.cat([grouped_xyz, relative_xyz, xyz_tile, relative_dis], dim=-1)
return relative_feature
因此,该模块每次输出的通道数是固定的,都是10(3+3+3+1)。至于为什么要这么做,这里作者应该是直接借鉴了RS-CNN的思想。将相对位置编码的结果进行一次卷积后,与第i层特征邻域分组(对应图中的Feature_Neighbour)的结果进行拼接送入Attention Pooling(AP)。
AP主要是为了聚合邻居特征,这里主要使用注意力机制对邻居信息进行聚合,它的结构图如图所示:

首先将原来坐标和特征的拼接结果送入FC层进行线性映射,然后利用Softmax进在邻居位置获取注意力分数,然后将其与原始输入进行点乘**,并将所有的邻居特征累加到一起**,最后利用卷积调整通道获得输出。
通过重复堆叠两次上述操作,就能够获得该模块的输出。
2.3 随机采样
可能很多小伙伴会觉得这个随机采样有啥好讲的,但是这个模块我感觉也是比较重要的。通过上面的操作,我们可以得到一个CxN的特征,此时我们需要将其下采样到C’xN。通过第一节我们知道,RanLa-Net会获得每层的邻居索引和下采样后邻居的索引。这里这个下采样后邻居的索引就起到作用了。它利用这个索引索引出下采样点后的邻居,先获得一个C’xNxK的特征领域组,然后在利用max函数进行筛选最大邻居。感觉这里和PointNet++有很大的区别,值得注意一下。
2.4邻近点插值
这一部分也是比较容易,因为前面我们已经记录了NxC下采样到N’xC这个过程那些点被下采样了,我们只需要再次计算N’xC,中离NxC中较近的点,将其填充到NxC个点即可。感觉这样讲还是比较抽象,还是通过画图比较容易理解
假设未下采样的点的分布如图所示:

图中共有6个点,我们已经选择将其下采样到4个点,如图中红色点所示:

这个过程与Dilated Res Block是对应的。我们现在要如何将4个点进行插值,上采样到原来的6个点,与编码器的特征进行拼接呢?
其实非常简单,我们只需要将红色的点与每个黑色点计算距离,将离最近的那个红色点作为插值后的点。
例如1号点与红色8号点距离最小,因此插值后1好点的位置右8号点代替。
2号点与7号点距离最小,插值后用7号点代替。
。。。。。
通过上述操作,我们可以将红色点从4个插值到6个,对应的编号为8,7,9,8,9,10。相当于在少的点里面进行重复采样。
3. S3DIS数据集Pytorch实现
啊,又是很长一段 ,,,等以后有时间再写吧