YOLOv5 的个人理解
相比前代的改进
YOLOv5其实就是YOLOv4的工程化的版本,v5版本并没有对v4版本进行大规模的改进创新,所以有人称v5是v4.5。v5或者是v4的版本改进我觉的是一下几点。
- 数据增强。采用了马赛克数据增强,就是从train的数据集中选择四张图片,在一张大图上的一定范围随机选择中心点,在中心点的左上,左下,右上,右下放置一张图片。这样做在一定程度上增加了batch size,四合一图片吗。当然,四张图片上面的label也要做相应的更新;
- DropBlock机制。防止过拟合很常用的方法就是Dropout,即随机杀死一些神经元,DropBlock则是随机杀死一片区域的神经元。例如,之前是把狗狗图片的眼睛一个像素点删掉了,现在是整个眼睛都删掉了;
- Label Smoothing。让标签平滑一些,目的是让神经网络不那么自信。例如,softmax的结果:(1,0)->[1,0]*(1-0.1)+0.05=[0.95,0.05];
- 损失函数:
边框回归:采用了CIoU
Objectness(置信度损失):采用了BCEWithLogitsLoss和CIoU
分类损失:采用了交叉熵损失函数BCEWithLogitsLoss
三种损失平衡:边框:Objectness:分类=0.05:1:0.5
三个检测层的损失平衡是:4.0, 1.0, 0.4对应8,16,32的输出层

在GitHub的yolov5代码中,lbox表示边框回归,lobj表示置信度损失,lcls表示分类损失,我对主要的compute_loss函数做注释如下:
def compute_loss(p, targets, model): # predictions, targets, model
device = targets.device
lcls, lbox, lobj = torch.zeros(1, device=device), torch.zeros(1, device=device), torch.zeros(1, device=device) # 初始化各个部分损失
tcls, tbox, indices, anchors = build_targets(p, targets, model) # 经过坐标变换获得标签分类,边框,索引,anchor
h = model.hyp # hyperparameters
# Define criteria BCELoss(损失函数) 该类主要用来创建衡量目标和输出之间的二进制交叉熵的标准,BCEWithLogitsLoss 这个loss类将sigmoid操作和与BCELoss集合到了一个类
BCEcls = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['cls_pw']])).to(device)
BCEobj = nn.BCEWithLogitsLoss(pos_weight=torch.Tensor([h['obj_pw']])).to(device)
# Class label smoothing https://arxiv.org/pdf/1902.04103.pdf eqn 3 label Smoothing
cp, cn = smooth_BCE(eps=0.0) # 标签平滑,eps默认为0,其实是没用上。
# Focal loss
g = h['fl_gamma'] # focal loss gamma# 如果设置了fl_gamma参数,就使用focal loss,默认也是没使用的
if g > 0:
BCEcls, BCEobj = FocalLoss(BCEcls, g), FocalLoss(BCEobj, g)
# Losses
nt = 0 # number of targets
no = len(p) # number of outputs
# 设置三个特征图对应输出的损失系数
balance = [4.0, 1.0, 0.4] if no == 3 else [4.0, 1.0, 0.4, 0.1] # P3-5 or P3-6
for i, pi in enumerate(p): # layer index, layer predictions
# 根据indices获取索引,方便找到对应网格的输出
b, a, gj, gi = indices[i] # image, anchor, gridy, gridx
tobj = torch.zeros_like(pi[..., 0], device=device) # target obj
n = b.shape[0] # number of targets
if n:
nt += n # cumulative targets
# 找到对应网格的输出
ps = pi[b, a, gj, gi] # prediction subset corresponding to targets
# Regression 对输出xywh做反算 边框回归
pxy = ps[:, :2].sigmoid() * 2. - 0.5
pwh = (ps[:, 2:4].sigmoid() * 2) ** 2 * anchors[i]
pbox = torch.cat((pxy, pwh), 1).to(device) # predicted box
# 计算边框损失,注意这个CIoU=True,计算的是ciou损失
iou = bbox_iou(pbox.T, tbox[i], x1y1x2y2=False, CIoU=True) # iou(prediction, target)
lbox += (1.0 - iou).mean() # iou loss
# Objectness # 根据model.gr设置objectness的标签值
tobj[b, a, gj, gi] = (1.0 - model.gr) + model.gr * iou.detach().clamp(0).type(tobj.dtype) # iou ratio
# Classification 设置如果类别数大于1才计算分类损失
if model.nc > 1: # cls loss (only if multiple classes)
t = torch.full_like(ps[:, 5:], cn, device=device) # targets
t[range(n), tcls[i]] = cp
lcls += BCEcls(ps[:, 5:], t) # BCE
# Append targets to text file
# with open('targets.txt', 'a') as file:
# [file.write('%11.5g ' * 4 % tuple(x) + '\n') for x in torch.cat((txy[i], twh[i]), 1)]
# 计算objectness的损失
lobj += BCEobj(pi[..., 4], tobj) * balance[i] # obj loss
s = 3 / no # output count scaling
# 根据超参数设置的各个部分损失的系数 获取最终损失
lbox *= h['box'] * s
lobj *= h['obj'] * s * (1.4 if no == 4 else 1.)
lcls *= h['cls'] * s
bs = tobj.shape[0] # batch size
loss = lbox + lobj + lcls
return loss * bs, torch.cat((lbox, lobj, lcls, loss)).detach()
其他的像激活函数细节,我就不赘述了。下一个模块来介绍网络模型。
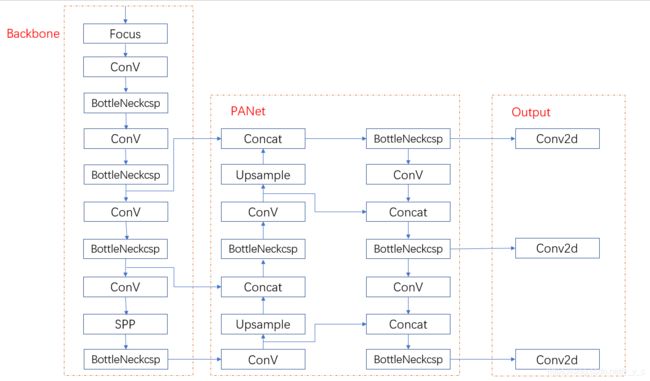
网络模型
网络的整体架构,笔者把大的模块进行介绍。
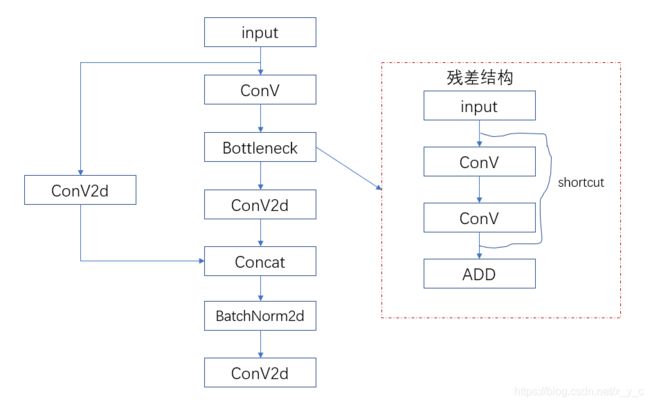
Focus模块:

BottleneckCSP模块:
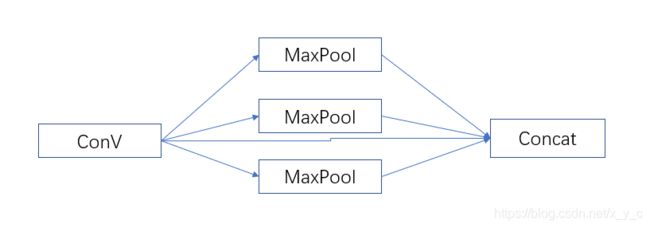
SSP模块:
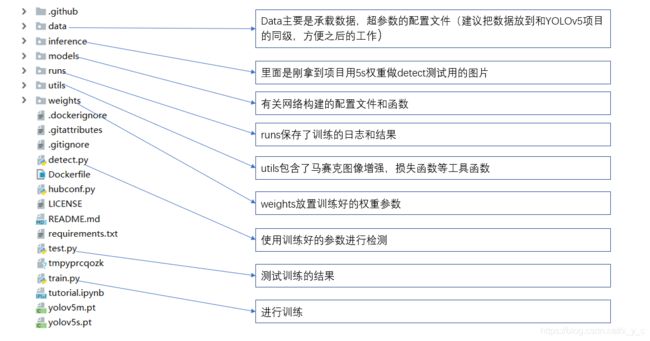
项目代码整体介绍
代码的整体框架介绍如下:
# parameters
nc: 80 # number of classes 当前任务的类别
depth_multiple: 0.33 # model depth multiple 网络的深度
width_multiple: 0.5 # layer channel multiple 每层的通道数
#其实YOLOv5的几个版本区别就是在这两个参数,参数越大网络结构越深,通道数越多
# anchors 三个检测头所用的检测框的大小
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
# from代表在哪个层的下面,-1代表在接上一层
#number表示有几个改模块,number*depth_multiple才是真实的
#module表示模块的名字
#args表示输出的通道数(实际要×width_multiple),卷积核大小,步长
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
# YOLOv5 head [-1, 6]代表上一层和6层做融合
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
未完待续