基于Mxnet实现实例分割-MaskRCNN【附部分源码】
文章目录
- 前言
- 一、什么是实例分割
- 二、数据集的准备
-
- 1.数据集标注
- 2.VOC数据集转COCO数据集
- 三、基于Mxnet搭建MaskRCNN
-
- 1.引入库
- 2.CPU/GPU配置
- 3.获取训练的dataset
-
- 1.coco数据集
- 2.自定义数据集
- 4.获取类别标签
- 5.模型构建
- 6.数据迭代器
- 7.模型训练
-
- 1.优化器设置
- 2.loss计算
- 3.acc计算
- 4.循环训练
- 8.模型预测
- 四、训练预测代码主入口
- 五、效果展示
-
- 1.训练过程可视化
- 2.预测效果
- 总结
前言
本文实现基于mxnet实现MaskRCNN示例分割算法
一、什么是实例分割
实例分割是目标检测和语义分割的结合,在图像中将目标检测出来(目标检测),然后对每个像素打上标签(语义分割)
二、数据集的准备
1.数据集标注
数据标注主要使用labelImg工具,python安装只需要:pip install labelme 即可,然后在命令提示符输入:labelme即可,如图:
在这里只需要修改“OpenDir“,“OpenDir“主要是存放图片需要标注的路径
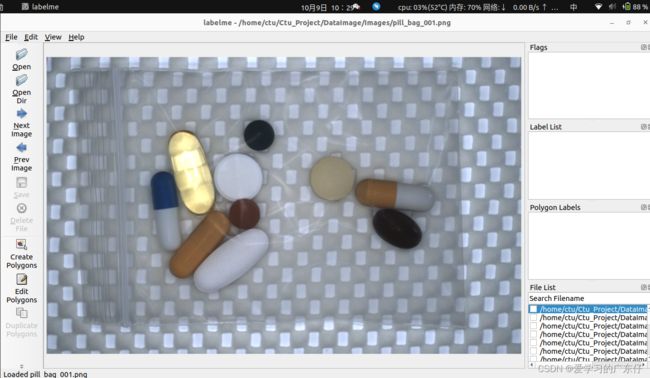
选择好路径之后即可开始绘制:
我在平时标注的时候快捷键一般只用到:
createpolygons:(ctrl+N)开始绘制
a:上一张
d:下一张
绘制过程如图:
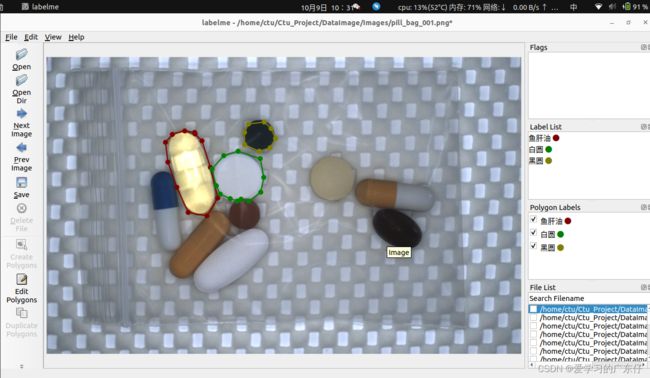
就只需要一次把目标绘制完成即可。
2.VOC数据集转COCO数据集
def JSON2COCO(DataDir, SaveDir,split_train):
if os.path.exists(SaveDir):
for root, dirs, files in os.walk(SaveDir, topdown=False):
for name in files:
os.remove(os.path.join(root, name))
for name in dirs:
os.rmdir(os.path.join(root, name))
os.removedirs(SaveDir)
if not os.path.exists(os.path.join(SaveDir, 'annotations')):
os.makedirs(os.path.join(SaveDir, 'annotations'))
if not os.path.exists(os.path.join(SaveDir, 'images','train_data')):
os.makedirs(os.path.join(SaveDir, 'images','train_data'))
if not os.path.exists(os.path.join(SaveDir, 'images','val_data')):
os.makedirs(os.path.join(SaveDir, 'images','val_data'))
train_data_list,val_data_list, classes_names = CreateDataList_Seg(DataDir, split_train)
with open(os.path.join(SaveDir, 'train.txt'), 'w', encoding='utf-8') as f:
for file_name in train_data_list:
fn = os.path.basename(file_name.split('.')[0]+'.bmp')
f.write(os.path.join(SaveDir, 'images', 'train_data',fn) + '\n')
with open(os.path.join(SaveDir, 'val.txt'), 'w', encoding='utf-8') as f:
for file_name in val_data_list:
fn = os.path.basename(file_name.split('.')[0]+'.bmp')
f.write(os.path.join(SaveDir, 'images', 'val_data',fn) + '\n')
with open(os.path.join(SaveDir, 'labels.txt'), 'w', encoding='utf-8') as f:
for cls in classes_names:
f.write(cls + '\n')
labelme2coco(train_data_list, os.path.join(SaveDir,'images','train_data'), os.path.join(SaveDir, 'annotations', 'instances_train_data.json'))
labelme2coco(val_data_list, os.path.join(SaveDir,'images','val_data'), os.path.join(SaveDir, 'annotations', 'instances_val_data.json'))
参数定义:
DataDir:存放标注json文件所在的文件夹目录
SaveDir:输出coco数据集的保存目录
split_train:训练集和验证集的分割
生成后的目录环境如下:

instances_train_data.json:包含了训练数据集的标注信息
instances_val_data.json:包含了验证数据集的标注信息
train_data:保存训练集的原始图像
val_data:保存验证集的原始图像
labels.txt:保存本次训练存在的类别数
train.txt:保存训练集的图像路径
val.txt:保存验证集的图像路径
三、基于Mxnet搭建MaskRCNN
项目目录结构:

core:源码文件夹,保存标准的核心验证模型算法
data:源码文件夹,保存数据加载器和迭代器
nets:MaskRCNN源码实现文件夹
utils:标准的算法库
Ctu_MaskRCNN.py:MaskRCNN类及调用方式
1.引入库
import os, time, sys, json, colorsys, cv2
import mxnet.ndarray as nd
import numpy as np
import mxnet as mx
from mxnet import gluon
from mxnet.contrib import amp
from nets.mask_rcnn.predefined_models import mask_rcnn_resnet18_v1b_coco,mask_rcnn_resnet50_v1b_coco,mask_rcnn_resnet101_v1d_coco
from data.data_loader import COCOInstance,COCOInstanceMetric
from data.batchify_fn import MaskRCNNTrainBatchify,Tuple,Append
from data.data_sampler import SplitSortedBucketSampler
from data.data_transform import MaskRCNNDefaultTrainTransform,MaskRCNNDefaultValTransform
from data.json2coco import get_coco_data
from core.loss import RPNAccMetric, RPNL1LossMetric, RCNNAccMetric, RCNNL1LossMetric, MaskAccMetric, MaskFGAccMetric
from nets.mask_rcnn.data_parallel import ForwardBackwardTask
from utils.parallel import Parallel
from nets.nn.bbox import BBoxClipToImage
from utils.mask import mask_fill
from utils.image import resize_short_within
2.CPU/GPU配置
self.ctx = [mx.gpu(int(i)) for i in USEGPU.split(',') if i.strip()]
self.ctx = self.ctx if self.ctx else [mx.cpu()]
3.获取训练的dataset
1.coco数据集
train_dataset = COCOInstance(ImgDir=os.path.join(self.DataOutPutDir, "coco", "images", "train2017"), jsonFile=os.path.join(self.DataOutPutDir,"coco","annotations","instances_train2017.json"))
val_dataset = COCOInstance(ImgDir=os.path.join(self.DataOutPutDir, "coco", "images", "val2017"), jsonFile=os.path.join(self.DataOutPutDir,"coco","annotations","instances_val2017.json"), skip_empty=False)
self.val_metric = COCOInstanceMetric(val_dataset, self.DataOutPutDir, use_ext=False, starting_id=0)
self.classes_names = train_dataset.classes_names
2.自定义数据集
get_coco_data(DataDir,self.DataOutPutDir,train_split)
4.获取类别标签
self.classes_names = train_dataset.classes_names
5.模型构建
self.modelDict = {
'mask_rcnn_resnet18_v1b_coco': mask_rcnn_resnet18_v1b_coco,
'mask_rcnn_resnet50_v1b_coco': mask_rcnn_resnet50_v1b_coco,
'mask_rcnn_resnet101_v1d_coco': mask_rcnn_resnet101_v1d_coco
}
self.model = self.modelDict[self.model_name](self.classes_names,min_size=self.min_size,max_size=self.max_size, per_device_batch_size=self.batch_size // len(self.ctx))
self.model.initialize()
6.数据迭代器
self.train_loader = mx.gluon.data.DataLoader(train_dataset.transform(
MaskRCNNDefaultTrainTransform(self.model.short, self.model.max_size, self.model, ashape=self.model.ashape, multi_stage=False)),
batch_sampler=train_sampler, batchify_fn=train_bfn, num_workers=num_workers)
self.val_loader = mx.gluon.data.DataLoader(
val_dataset.transform(MaskRCNNDefaultValTransform(short, self.model.max_size)), len(self.ctx), False,
batchify_fn=val_bfn, last_batch='keep', num_workers=num_workers)
7.模型训练
1.优化器设置
trainer = gluon.Trainer(self.model.collect_train_params(), 'sgd', optimizer_params, update_on_kvstore=(False if self.ampFlag else None), kvstore=kv)
2.loss计算
rpn_cls_loss = mx.gluon.loss.SigmoidBinaryCrossEntropyLoss(from_sigmoid=False)
rpn_box_loss = mx.gluon.loss.HuberLoss(rho=1./9.) # == smoothl1
rcnn_cls_loss = mx.gluon.loss.SoftmaxCrossEntropyLoss()
rcnn_box_loss = mx.gluon.loss.HuberLoss(rho=1.) # == smoothl1
rcnn_mask_loss = mx.gluon.loss.SigmoidBinaryCrossEntropyLoss(from_sigmoid=False)
metrics = [mx.metric.Loss('RPN_Conf'),
mx.metric.Loss('RPN_SmoothL1'),
mx.metric.Loss('RCNN_CrossEntropy'),
mx.metric.Loss('RCNN_SmoothL1'),
mx.metric.Loss('RCNN_Mask')]
3.acc计算
rpn_acc_metric = RPNAccMetric()
rpn_bbox_metric = RPNL1LossMetric()
rcnn_acc_metric = RCNNAccMetric()
rcnn_bbox_metric = RCNNL1LossMetric()
rcnn_mask_metric = MaskAccMetric()
rcnn_fgmask_metric = MaskFGAccMetric()
metrics2 = [rpn_acc_metric, rpn_bbox_metric,
rcnn_acc_metric, rcnn_bbox_metric,
rcnn_mask_metric, rcnn_fgmask_metric]
4.循环训练
for i,batch in enumerate(self.train_loader):
batch = self.split_and_load(batch)
metric_losses = [[] for _ in metrics]
add_losses = [[] for _ in metrics2]
if executor is not None:
for data in zip(*batch):
executor.put(data)
for j in range(len(self.ctx)):
if executor is not None:
result = executor.get()
else:
result = rcnn_task.forward_backward(list(zip(*batch))[0])
for k in range(len(metric_losses)):
metric_losses[k].append(result[k])
for k in range(len(add_losses)):
add_losses[k].append(result[len(metric_losses) + k])
trainer.step(self.batch_size)
for metric, record in zip(metrics, metric_losses):
metric.update(0, record)
for metric, records in zip(metrics2, add_losses):
for pred in records:
metric.update(pred[0], pred[1])
msg = ','.join(['{}={:.3f}'.format(*metric.get()) for metric in metrics + metrics2])
batch_speed = self.batch_size / (time.time() - btic)
speed.append(batch_speed)
print('[Epoch {}][Batch {}], Speed: {:.3f} samples/sec, {}'.format(epoch, i, batch_speed, msg))
btic = time.time()
8.模型预测
def predict(self,img):
from matplotlib import pyplot as plt
import gluoncv as gcv
img = nd.array(img)
x, img = self.transform_test([img], short=self.min_size, max_size=self.max_size, mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
x = x.as_in_context(self.ctx[0])
ids, scores, bboxes, masks = [xx[0].asnumpy() for xx in self.model(x)]
masks, _ = gcv.utils.viz.expand_mask(masks, bboxes, (img.shape[1], img.shape[0]), scores)
img = gcv.utils.viz.plot_mask(img, masks)
cv2.imwrite('1.bmp',img)
fig = plt.figure(figsize=(15, 15))
ax = fig.add_subplot(1, 1, 1)
ax = gcv.utils.viz.plot_bbox(img, bboxes, scores, ids, class_names=self.model.classes, ax=ax)
plt.show()
四、训练预测代码主入口
if __name__ == '__main__':
# ctu = Ctu_MaskRCNN(USEGPU='0',ampFlag = False,min_size = 416,max_size=416)
# ctu.InitModel(DataDir = r'E:\DL_Project\DataSet\DataSet_Segmentation\DataSet_YaoPian\DataImage',train_split=0.9, batch_size=1, num_workers=0, model_name='mask_rcnn_resnet18_v1b_coco')
# ctu.train(TrainNum=2000,learning_rate=0.0001,lr_decay_epoch='30,70,150,200',lr_decay=0.9,disable_hybridization=False,ModelPath='./Ctu_Model')
ctu = Ctu_MaskRCNN(USEGPU='0',ampFlag=False)
ctu.LoadModel(r'./Ctu_Model_mask_rcnn_resnet18_v1b_coco')
cv2.namedWindow("result", 0)
cv2.resizeWindow("result", 640, 480)
index = 0
for root, dirs, files in os.walk(r'E:\DL_Project\DataSet\DataSet_Segmentation\DataSet_YaoPian\DataImage'):
for f in files:
img_cv = ctu.read_image(os.path.join(root, f))
if img_cv is None:
continue
ctu.predict(img_cv)
五、效果展示
1.训练过程可视化
2.预测效果
备注:训练次数不多,以往模型没保存因此大概训练了一下

总结
本文章主要是基于Mxnet实现实例分割MaskRCNN