Pytorch:制作自己的数据集并实现图像分类三部曲
Pytorch:制作自己的数据集并实现图像分类三部曲
开发环境:
Pycharm + Python 3.7.9
torch 1.10.2+cu102
torchvision 0.11.3+cu102
一、上网搜取相关照片作为数据
制作了四个文件夹,每个文件夹50张照片,分别是刹车盘,刹车鼓,刹车片,刹车蹄

这是brake_disc文件夹里面的内容,请注意图片命名格式
二、定义自己的数据类并读入图片数据
1.引入相关库
代码如下:
import glob
import torch
from torch.utils import data
from PIL import Image
import numpy as np
from torchvision import transforms
import matplotlib.pyplot as plt
2.继承Dataset实现Mydataset子类
代码如下:
# 通过创建data.Dataset子类Mydataset来创建输入
class Mydataset(data.Dataset):
# init() 初始化方法,传入数据文件夹路径
def __init__(self, root):
self.imgs_path = root
# getitem() 切片方法,根据索引下标,获得相应的图片
def __getitem__(self, index):
img_path = self.imgs_path[index]
# len() 计算长度方法,返回整个数据文件夹下所有文件的个数
def __len__(self):
return len(self.imgs_path)
3、使用glob方法来获取数据图片的所有路径
代码如下:
# 使用glob方法来获取数据图片的所有路径
all_imgs_path = glob.glob(r"./images/*/*.jpg") # 数据文件夹路径
for var in all_imgs_path:
print(var
三、为图片制作标签,并划分训练集和测试集
1、利用自定义类Mydataset创建对象brake_dataset
# 利用自定义类Mydataset创建对象brake_dataset
brake_dataset = Mydataset(all_imgs_path)
print(len(brake_dataset)) # 返回文件夹中图片总个数
print(brake_dataset[12:14]) # 切片,显示第12张、第十三张图片,python左闭右开
brake_dataloader = torch.utils.data.DataLoader(brake_dataset, batch_size=4) # 每次迭代时返回4个数据
# print(next(iter(break_dataloader)))
2、为每张图片制作相应的标签
# 为每张图片制作对应标签
species = ['disc', 'drum', 'pad', 'shoe']
species_to_id = dict((c, i) for i, c in enumerate(species))
print(species_to_id)
id_to_species = dict((v, k) for k, v in species_to_id.items())
print(id_to_species)
# 对所有图片路径进行迭代
all_labels = []
for img in all_imgs_path:
# 区分出每个img,应该属于什么类别
for i, c in enumerate(species):
if c in img:
all_labels.append(i)
print(all_labels)

3、完善Mydataset类,将图片数据转换成Tensor,并展示部分图片与标签对应关系
代码如下
# 对数据进行转换处理
transform = transforms.Compose([
transforms.Resize((256, 256)), # 做的第一步转换
transforms.ToTensor() # 第二步转换,作用:第一转换成Tensor,第二将图片取值范围转换成0-1之间,第三会将channel置前
])
class Mydatasetpro(data.Dataset):
def __init__(self, img_paths, labels, transform):
self.imgs = img_paths
self.labels = labels
self.transforms = transform
# 进行切片
def __getitem__(self, index):
img = self.imgs[index]
label = self.labels[index]
pil_img = Image.open(img) # pip install pillow
pil_img = pil_img.convert('RGB')
data = self.transforms(pil_img)
return data, label
# 返回长度
def __len__(self):
return len(self.imgs)
BATCH_SIZE = 4
brake_dataset = Mydatasetpro(all_imgs_path, all_labels, transform)
brake_dataloader = data.DataLoader(
brake_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
imgs_batch, labels_batch = next(iter(brake_dataloader))
print(imgs_batch.shape)
plt.figure(figsize=(12, 8))
for i, (img, label) in enumerate(zip(imgs_batch[:6], labels_batch[:6])):
img = img.permute(1, 2, 0).numpy()
plt.subplot(2, 3, i + 1)
plt.title(id_to_species.get(label.item()))
plt.imshow(img)
plt.show() # 展示图片
运行结果:

4、划分数据集和测试集
代码如下
# 划分数据集和测试集
index = np.random.permutation(len(all_imgs_path))
all_imgs_path = np.array(all_imgs_path)[index]
all_labels = np.array(all_labels)[index]
# 80%做训练集
s = int(len(all_imgs_path) * 0.8)
print(s)
train_imgs = all_imgs_path[:s]
train_labels = all_labels[:s]
test_imgs = all_imgs_path[s:]
test_labels = all_labels[s:]
train_ds = Mydatasetpro(train_imgs, train_labels, transform) # TrainSet TensorData
test_ds = Mydatasetpro(test_imgs, test_labels, transform) # TestSet TensorData
# print(train_ds)
# print(test_ds)
print("**********")
train_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True) # TrainSet Labels
test_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True) # TestSet Labels
# 划分数据集和测试集
index = np.random.permutation(len(all_imgs_path))
all_imgs_path = np.array(all_imgs_path)[index]
all_labels = np.array(all_labels)[index]
# 80%做训练集
s = int(len(all_imgs_path) * 0.8)
print(s)
train_imgs = all_imgs_path[:s]
train_labels = all_labels[:s]
test_imgs = all_imgs_path[s:]
test_labels = all_labels[s:]
train_ds = Mydatasetpro(train_imgs, train_labels, transform) # 训练集数据
test_ds = Mydatasetpro(test_imgs, test_labels, transform) # 测试集数据
# print(train_ds)
# print(test_ds)
print("**********")
train_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True) # 训练集标签
test_dl = data.DataLoader(train_ds, batch_size=BATCH_SIZE, shuffle=True) # 测试集标签
# print(train_dl)
# print(test_dl)
三、使用自己的数据集做图像分类
1、新建一个py文件
引用相关库
import torch
import torchvision.models as models
from torch import nn
from torch import optim
from data_production import brake_dataloader
from data_production import train_dl, test_dl
接下来检测一下我们的机器是否拥有GPU用于训练(使用GPU进行训练速度至少要快十倍哦~),然后加载一个预训练模型(在这里我们使用的是ResNet50):
# 判断是否使用GPU
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_ft = models.resnet50(pretrained=True) # 使用迁移学习,加载预训练权
2、训练数据集
in_features = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(in_features, 256),
nn.ReLU(),
# nn.Dropout(0, 4),
nn.Linear(256, 4),
nn.LogSoftmax(dim=1))
model_ft = model_ft.to(DEVICE) # 将模型迁移到gpu
# 优化器
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(DEVICE) # 将loss_fn迁移到GPU
# Adam损失函数
optimizer = optim.Adam(model_ft.fc.parameters(), lr=0.003)
3、循环迭代过程
epochs = 50 # 迭代次数
steps = 0
running_loss = 0
print_every = 10
train_losses, test_losses = [], []
for epoch in range(epochs):
model_ft.train()
# 遍历训练集数据
for imgs, labels in brake_dataloader:
steps += 1
labels = torch.tensor(labels, dtype=torch.long)
imgs, labels = imgs.to(DEVICE), labels.to(DEVICE)
optimizer.zero_grad() # 梯度归零
outputs = model_ft(imgs)
loss = loss_fn(outputs, labels)
loss.backward() # 反向传播计算梯度
optimizer.step() # 梯度优化
running_loss += loss.item()
if steps % print_every == 0:
test_loss = 0
accuracy = 0
model_ft.eval()
with torch.no_grad():
# 遍历测试集数据
for imgs, labels in test_dl:
labels = torch.tensor(labels, dtype=torch.long)
imgs, labels = imgs.to(DEVICE), labels.to(DEVICE)
outputs = model_ft(imgs)
loss = loss_fn(outputs, labels)
test_loss += loss.item()
ps = torch.exp(outputs)
top_p, top_class = ps.topk(1, dim=1)
equals = top_class == labels.view(*top_class.shape)
accuracy += torch.mean(equals.type(torch.FloatTensor)).item()
train_losses.append(running_loss / len(train_dl))
test_losses.append(test_loss / len(test_dl))
print(f"Epoch {epoch + 1}/{epochs}.. "
f"Train loss: {running_loss / print_every:.3f}.. "
f"Test loss: {test_loss / len(test_dl):.3f}.. "
f"Test accuracy: {accuracy / len(test_dl):.3f}")
running_loss = 0
model_ft.train()
torch.save(model_ft, "aerialmodel.pth")
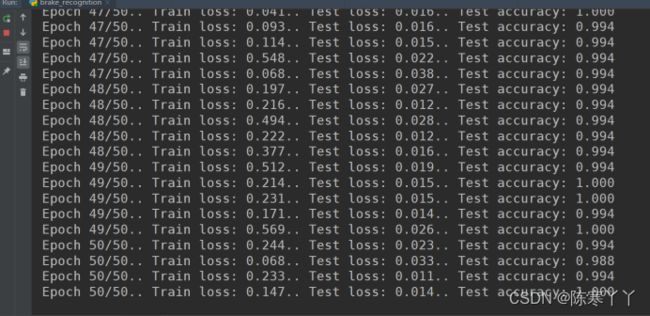
至此,训练就结束了,将模型保存下来以便之后进行预测!
4、实现自己的图像分类
代码如下:
import os
import torch
from PIL import Image
from torch import nn
from torchvision import transforms, models
i = 0 # 识别图片计数
# 这里最好新建一个test_data文件随机放一些上面整理好的图片进去
root_path = r"E:\DeepLearning\images\test_data" # 待测试文件夹
names = os.listdir(root_path)
for name in names:
print(name)
i = i + 1
data_class = ['disc', 'drum', 'pads', 'shoe'] # 按文件索引顺序排列
image_path = os.path.join(root_path, name)
image = Image.open(image_path)
print(image)
transform = transforms.Compose([transforms.Resize((256, 256)),
transforms.ToTensor()])
image = transform(image)
print(image.shape)
model_ft = models.resnet50()
in_features = model_ft.fc.in_features
model_ft.fc = nn.Sequential(nn.Linear(in_features, 256),
nn.ReLU(),
# nn.Dropout(0, 4),
nn.Linear(256, 4),
nn.LogSoftmax(dim=1))
model = torch.load("aerialmodel.pth", map_location=torch.device("cpu"))
image = torch.reshape(image, (1, 3, 256, 256)) # 修改待预测图片尺寸,需要与训练时一致
model.eval()
with torch.no_grad():
output = model(image)
print(output) # 输出预测结果
# print(int(output.argmax(1)))
# 对结果进行处理,使直接显示出预测的种类
print("第{}张图片预测为:{}".format(i, data_class[int(output.argmax(1))]))
运行结果:

到这里,我们就实现了一个简单的深度学习图像识别示例。