《DETRs with Collaborative Hybrid Assignments Training》 加入one to many matching 辅助头训练的DETR
DETRs with Collaborative Hybrid Assignments Training
- 背景
- 原理
- 实验

最近看到一篇不错的DETR论文,翻译了下,以作记录。
论文地址:https://arxiv.org/pdf/2211.12860.pdf
开源地址:https://github.com/Sense-X/Co-DETR
背景
自DETR新范式提出以来,有很多文章都致力于解决DETR模型训练慢、精度一般的问题。DETR将对象检测视为集合预测(set prediction)问题,并引入基于transformer encoder-decoder架构的一对一匹配(one to one matching )方法。以这种方式,每个GT将单独分配给一个query,不再需要一对多匹配(one to many matching)的先验设计(如anchor、手工设计的GT匹配机制等)。DETR简化了检测的pipeline(指不需要nms),作为一种新范式引发了诸多DETR的变体。Deformable DETR作为DETR变体中的佼佼者,将稀疏的可变形transformer、二阶段检测、级联更新bbox等操作引入到DETR中,得到了相当不错的效果。
最近(2022年)不少论文都将目光集中在了one to one matching机制上,年初CVPR的Denosing DETR认为one to one matching机制在模型训练的初期导致了损失不稳定,GT无法很好的与query稳定的进行匹配,因此提出了加入噪声干扰的GT输入作为query,与GT进行损失计算来辅助加速DETR模型训练,该课题组在此基础上提出了DINO、Mask DINO等模型,将DETR模式推到了SOTA的水平。此后,Group DETR、H-DETR等论文通过扩展query的方式将DETR的one to one matching转换为one to many matching的模式来加速模型训练,并取得了不错的效果。
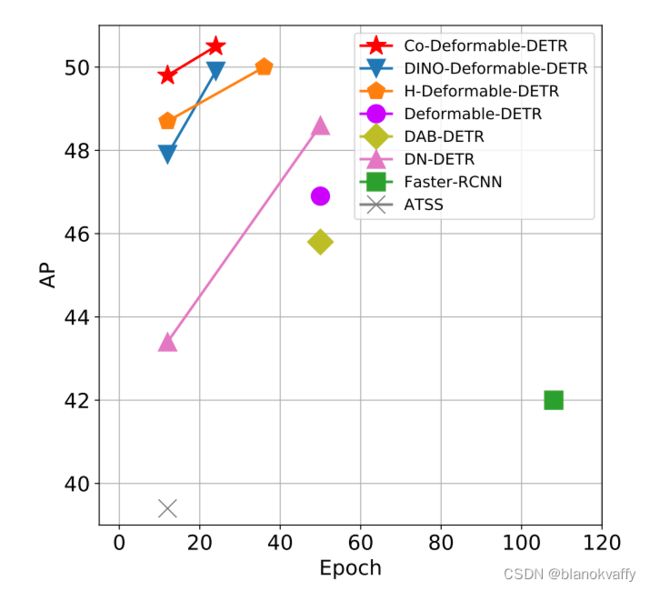
本篇论文同样将目光放在了DETR的one to one matching 问题上,作者分析了Deformable DETR,认为one to one matching探索了不太积极的query,从而导致了训练的低效。作者从encoder生成的潜在表示和decoder中的attention学习两个方面对此进行了详细分析。首先比较了Deformable DETR和one to many matching方法之间潜在特征的可分辨性得分,其中作者用ATSS的检测头替换decoder,利用每个空间坐标中特征的l2范数来表示可分辨性得分。给定encoder的输出 F ∈ R C × H × W F∈ R^{C×H×W} F∈RC×H×W,可以得到可分辨性得分图 S ∈ R 1 × H × W S∈ R^{1×H×W} S∈R1×H×W。当相应区域的分数较高时,可以更好地检测对象。如下图所示,通过对可分辨性得分应用不同的阈值来演示IoF-IoB曲线(IoF:前景相交,IoB:背景相交)。

ATSS中较高的IoF-IoB曲线表明其相较于Defomable DETR更容易区分前景和背景。进一步可视化可分辨性得分图 S ∈ R 1 × H × W S∈ R^{1×H×W} S∈R1×H×W:

很明显,一些显著区域中的特征在one to many matching方法中被充分激活,但在one to one matching中很少被激活。
为了探索decoder的训练问题,作者还基于Deformable DETR和Group DETR(其将更多的正样本query引入到decoder中)演示了decoder中cross attention的IoF-IoB曲线。

如图所示,太少正样本query也会影响atttention的学习,而在decoder中增加更多的正样本query可以稍微缓解这种情况。
原理
作者提出一种简单有效的辅助训练模型Co-DETR,使用通用的one to many matching来提高encoder和decoder的训练效率。具体而言,就是将一些原有的one to many matching辅助检测头(如ATSS、Faster RCNN的检测头)加在encoder的输出后进行损失训练,并将结果输出到decoder中辅助decoder进行训练。这些辅助检测头可以通过one to many matching进行监督。不同的标签分配丰富了对encoder的监督,这迫使encoder具有足够的辨别力,以支持这些辅助检测头的损失收敛。one to many matching可以引入大量正样本作为query输入decoder中,以提高decoder的训练效率。并且Co-DETR只在训练阶段加入辅助检测头,因此仅在训练阶段中引入额外的计算开销,不会影响到模型推理的效率。Co-DETR的网络结构如下图所示:
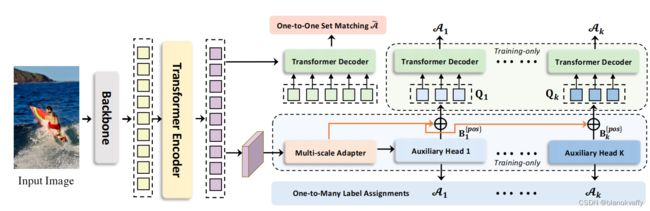
具体而言,给定encoder的输出特征 F F F,首先通过多尺度适配器将其转换为特征金字塔 { F 1 , . . . , F J } \{F_1,...,F_J\} {F1,...,FJ},其中 J J J表示具有 2 2 + J 2^{2+J} 22+J下采样步长的特征图。特征金字塔由单尺度encoder中的单个特征图构建,使用双线性插值和3×3卷积进行上下采样。对于多尺度encoder,只对多尺度encoder特征F中最粗糙的特征进行下采样以构建特征金字塔。定义了 K K K个具有相应标签分配方式 A k A_k Ak的辅助头,对于第 i i i个辅助头, { F 1 , . . . , F J } \{F_1,...,F_J\} {F1,...,FJ}被发送给它以获得预测 P ^ i \hat P_i P^i。在第 i i i个头, A i A_i Ai用于计算 P ^ i \hat P_i P^i中正样本和负样本的监督目标。将 G G G表示为GT集,辅助头 A i A_i Ai的计算可表示为:
P i { p o s } , B i { p o s } , P i { n e g } = A i ( P ^ i , G ) \mathbf P^{\{pos\}}_i, \mathbf B^{\{pos\}}_i, \mathbf P^{\{neg\}}_i = A_i(\hat\mathbf P_i, \mathbf G) Pi{pos},Bi{pos},Pi{neg}=Ai(P^i,G)
式中, B i { p o s } \mathbf B^{\{pos\}}_i Bi{pos}是空间正样本所在的位置的集合。 P i { p o s } \mathbf P^{\{pos\}}_i Pi{pos}和 P i { n e g } \mathbf P^{\{neg\}}_i Pi{neg}是相应位置的监督目标,包括类别和回归偏移。损失函数可以定义为:
L i e n c = L i ( P ^ i { p o s } , P i { p o s } ) + L i ( P ^ i { n e g } , P i { n e g } ) L^{enc}_i = L_i(\hat P^{\{pos\}}_i, P^{\{pos\}}_i) + L_i(\hat P^{\{neg\}}_i, P^{\{neg\}}_i) Lienc=Li(P^i{pos},Pi{pos})+Li(P^i{neg},Pi{neg})
对于 K K K个辅助检测头,其损失函数可定义为:
L e n c = ∑ i = 1 K L i e n c L^{enc}=\sum_{i=1}^KL^{enc}_i Lenc=i=1∑KLienc
在one to one matching中,每个GT框将仅分配给一个特定query作为监督目标。太少的正样本query导致decoder中的cross attentation学习效率低下。为了缓解这一问题,根据每个辅助头中的标签分配 A i A_i Ai生成了足够的正样本query。具体来说,给定第 i i i个辅助头中的正坐标集 B i { p o s } ∈ R M i × 4 \mathbf B^{\{pos\}}_i\in R^{M_i×4} Bi{pos}∈RMi×4 ,其中 M i M_i Mi是正样本的数量,额外的正样本query Q i ∈ R M i × C Q_i \in R^{M_i×C} Qi∈RMi×C可通过以下方式生成:
Q i = L i n e a r ( P E ( B i { p o s } ) ) + L i n e a r ( E ( F ∗ , p o s ) ) Q_i = Linear(PE(\mathbf B^{\{pos\}}_i)) + Linear(E({F_∗}, {pos})) Qi=Linear(PE(Bi{pos}))+Linear(E(F∗,pos))
因此,有 K + 1 K+1 K+1组query有助于单个one to one matching分支, K K K个分支在训练期间具有one to many matching。辅助one to many matching的分支与原始主分支中的 L L L个decoder层共享相同的参数。辅助分支中的所有query都被视为正样本query,因此匹配过程被丢弃。具体而言,第 i i i个辅助分支中的第 l l l个decoder层的损失可以定义为:
L i , l d e c = L ~ ( P ~ i , l , P i { p o s } ) . L^{dec}_{i,l} = \tilde L(\tilde \mathbf P_{i,l}, \mathbf P^{\{pos\}}_i). Li,ldec=L~(P~i,l,Pi{pos}).
Co-DETR的全体损失函数可被定义为:
L g l o b a l = ∑ j = 1 L ( L ~ l d e c + λ 1 ∑ i = 1 K L i , l d e c + λ 2 L e n c ) L^{global} = \sum^L_{j=1}(\tilde L^{dec}_l + \lambda_1 \sum^K_{i=1} L^{dec}_{i,l} + \lambda_2 L^{enc}) Lglobal=j=1∑L(L~ldec+λ1i=1∑KLi,ldec+λ2Lenc)
式中, L ~ l d e c \tilde L^{dec}_l L~ldec为原始主分支中 L L L个decoder层的损失。
实验
作者并保持训练设置与baseline一致,将Co-DETR引入到Deformable DETR++(two stage 和+iterative bounding box refinement)中。采用ATSS和Faster RCNN作为K=2的辅助头,采用ATSS作为K=1的辅助头。将query的数量设置为300,并默认将 λ 1 \lambda_1 λ1设为1.0, λ 2 \lambda_2 λ2设为2.0。
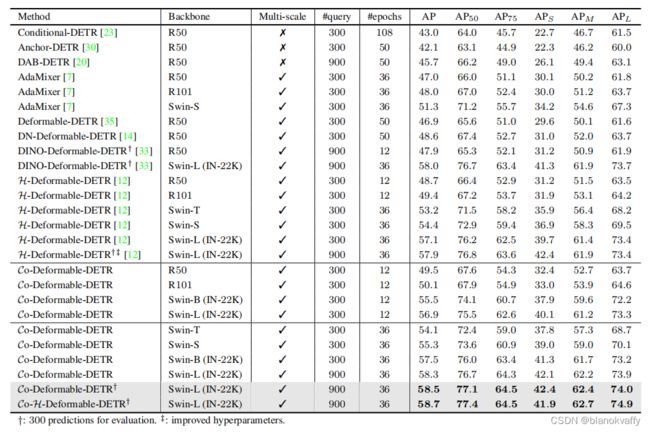
可以看到CO-DETR取得了相当不错的效果。

当采用MixMIM作为主干网络并采用Objects365进行预训练时,CO-DETR将COCO mAP提升到了64.4,几乎达到了SOTA水平。以更少的额外数据大小实现了卓越的性能。
如果与DINO中的Denosing机制联合使用,是否会带来更好的提升,希望可以看到后续跟进的report或者论文。