使用torchvision处理图片数据
torchvision是基于Pytorch处理图像视频的工具集,类似地还有处理自然语言的torchtext,处理音频的torchaudio等工具集。
torchvision包含以下几个包:
- datasets : 下载或加载几个常用视觉数据集,例如MNIST、CIFAR
- models : 流行的模型,例如 AlexNet, VGG, ResNet 和 Densenet 以及 与训练好的参数。
- transforms : 常用的图像操作,例如:随机切割,旋转,数据类型转换,图像到tensor ,numpy 数组到tensor ,tensor 到 图像等。
- utils : 其他图像处理工具
transform预处理操作
torchvision的transform库中定义了许多图片变换操作,例如
裁剪Crop
transforms.RandomCrop(size) # 依据给定的size随机裁剪
transforms.CenterCrop(size) # 依据给定的size从中心裁剪
transforms.FiveCrop(size) # 对图片进行上下左右以及中心裁剪,获得5张图片,返回一个4D-tensor
TenCrop(size, vertical_flip=False) # 对图片进行上下左右以及中心裁剪,然后全部翻转(水平或者垂直),获得10张图片
# 随机大小,随机长宽比裁剪原始图片,最后将图片resize到设定好的size
RandomResizedCrop(size, scale=(0.08, 1.0), ratio=(0.75, 1.3333333333333333), interpolation=2)
翻转和旋转——Flip and Rotation
RandomHorizontalFlip(p=0.5) # 依据概率p对PIL图片进行水平翻转
RandomVerticalFlip(p=0.5) # 依据概率p对PIL图片进行垂直翻转
图像变换
Resize(size, interpolation=2) # 重置图像大小
Normalize(mean, std) # 对数据按通道进行标准化,即先减均值,再除以标准差
ToTensor() # 将输入的PIL Image或ndarray 转换为tensor,并且归一化至[0-1]
ColorJitter(brightness=0, contrast=0, saturation=0, hue=0) # 修改修改亮度、对比度和饱和度
LinearTransformation(transformation_matrix) # 对矩阵做线性变化,可用于白化处理
使用ImageFolder加载图片
使用torchvision.datasets.ImageFolder()函数可以自动扫描指定文件夹并加载指定分类的图片,例如root目录下有cat、dog两个文件夹,其中分别为cat、dog的图片,那么通过ImageFolder会自动加载其图片资源并匹配对应的分类
root/dog/xxx.png
root/dog/xxy.png
root/dog/xxz.png
root/cat/123.png
root/cat/nsdf3.png
root/cat/asd932_.png
其函数原型如下:
dataset=torchvision.datasets.ImageFolder(
root, # 图片存储的根目录
transform=None, # 对图片进行预处理的操作
target_transform=None, # 对图片类别索引进行预处理的操作
loader=<function default_loader>, # 表示数据集加载方式,通常默认加载方式即可
is_valid_file=None) # 获取图像文件的路径并检查该文件是否为有效文件的函数
返回的dataset有如下三个属性,classes是由文件夹名获得的分类名称,class_to_idx为图片类别对应索引,img为图片路径和对应索引的Map
print(dataset.classes) # 根据分的文件夹的名字来确定的类别
print(dataset.class_to_idx) #按 顺序为这些类别定义索引为0,1...
print(dataset.imgs) # 从所有文件夹中得到的图片的路径以及其类别
'''
输出:
['cat', 'dog']
{'cat': 0, 'dog': 1}
[('./data/train\\cat\\1.jpg', 0),
('./data/train\\cat\\2.jpg', 0),
('./data/train\\dog\\1.jpg', 1),
('./data/train\\dog\\2.jpg', 1)]
'''
在获得dataset对象后,可以进一步封装为Dataloader,可以使用迭代器对dataloader进行遍历,并按批次返回batch_size个数据,如下所示为完整的图片加载过程
import torch
import torchvision
from torchvision import transforms
# 定义图片变换操作
transform = transforms.Compose([
transforms.Resize((500, 500)), # 重置图片大小
transforms.ToTensor(), # 将图片转换为Tensor,归一化至[0,1]
transforms.Normalize(mean=[.5, .5, .5], std=[.5, .5, .5]) # 图片数据标准化
])
# 加载图片数据集
dataset = torchvision.datasets.ImageFolder('./data/ship_images', transform=transform)
# 封装为批数据
train_loader = torch.utils.data.DataLoader(dataset, batch_size=4, shuffle=True, num_workers=2)
# 获取一个批次的训练图片
images, labels = iter(train_loader).next()
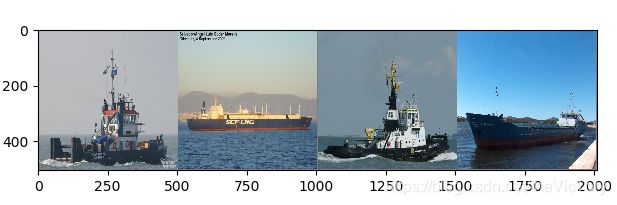
我们可以借助matplotlib查看一个批次的数据,由于之前对图片进行了标准化,且均值、方差为0.5,所以需要进行反标准化还原图片像素信息。通过torchvision.utils.make_grid()将一个批次images的4张图片拼接在一起
import matplotlib.pyplot as plt
import numpy as np
# 输出图像的函数
def imshow(img):
img = img / 2 + 0.5 # 反标准化
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
# 获取一个批次的训练图片、标签并显示
images, labels = iter(train_loader).next()
imshow(torchvision.utils.make_grid(images))
加载并显示一个批次图片如下: