【PyTorch深度强化学习】DDPG算法的讲解及实战(超详细 附源码)
需要源码请点赞关注收藏后评论区留言留下QQ~~~
一、DDPG背景及简介
在动作离散的强化学习任务中,通常可以遍历所有的动作来计算动作值函数q(s,a)q(s,a),从而得到最优动作值函数q∗(s,a)q∗(s,a) 。但在大规模连续动作空间中,遍历所有动作是不现实,且计算代价过大。针对解决连续动作空间问题,2016年TP Lillicrap等人提出深度确定性策略梯度算法(Deep Deterministic Policy Gradient,DDPG)算法。该算法基于深度神经网络表达确定性策略μ(s)μ(s),采用确定性策略梯度来更新网络参数,能够有效应用于大规模或连续动作空间的强化学习任务中。
景
(1) PG法
构建策略概率分布函数π(a∣s,θπ)π(a∣s,θπ),在每个时刻,Agent根据该概率分布选择动作:
其中,θπθπ是一个关于随机策略ππ的参数。
由于PG算法既涉及到状态空间又涉及到动作空间,因此在大规模情况下,得到随机策略需要大量的样本。这样在采样过程中会耗费较多的计算资源,相对而言,该算法效率较为低下。
(2) DPG算法
构建确定性策略函数μ(s,θμ)μ(s,θμ),在每个时刻,Agent根据该策略函数获得确定的动作:
其中,θμθμ表示这是一个关于确定性策略μμ的参数。
由于DPG算法仅涉及状态空间,因此与PG算法相比,需要的样本数较少,尤其在大规模或连续动作空间任务中,算法效率会显著提升。
(2) DDPG法
深度策略梯度方法在每个迭代步都需要采样NN个完整情节{ϖi}Ni=1{ϖi}i=1N来作为训练样本,然后构造目标函数关于策略参数的梯度项以求解最优策略。然而在许多现实场景下的任务中,很难在线获得大量完整情节的样本数据。例如在真实场景下机器人的操控任务中,在线收集并利用大量的完整情节会产生十分昂贵的代价,并且连续动作的特性使得在线抽取批量情节的方式无法覆盖整个状态特征空间。这些问题会导致算法在求解最优策略时出现局部最优解。针对上述问题,可将传统强化学习中的行动者评论家框架拓展到深度策略梯度方法中。这类算法被统称为基于AC框架的深度策略梯度方法。其中最具代表性的是深度确定性策略梯度(DDPG)算法,该算法能够解决一系列连续动作空间中的控制问题。DDPG算法基于DPG法,使用AC算法框架,利用深度神经网络学习近似动作值函数Q(s,a,w)Q(s,a,w)和确定性策略μ(s,θ)μ(s,θ),其中ww和θθ分别为值网络和策略网络的权重。值网络用于评估当前状态动作对的Q值,评估完成后再向策略网络提供更新策略权重的梯度信息,对应AC框架中的评论家;策略网络用于进行选择策略,对应AC框架中的行动者。它主要涉及以下概念:
(1) 行为策略ββ:一种探索性策略,通过引入随机噪声影响动作的选择;
(2) 状态分布ρβρβ :Agent根据行为策略ββ产生的状态分布;
(3) 策略网络:或行动者网络:DDPG使用深度网络对确定性策略函数μ(s,θ)μ(s,θ)进行逼近,θθ为网络参数,输入为当前的状态ss,输出为确定性的动作值aa。有时θθ也表示为θμθμ;
(4) 价值网络:或评论家网络,DDPG使用深度网络对近似动作值函数Q(s,a,w)Q(s,a,w)进行逼近,ww为网络参数。有时ww也表示为θQθQ。
相对于DPG法,DDPG法的主要改进如下:
(1) 采用深度神经网络:构建策略网络和价值网络,分别用来学习近似性策略函数μ(s,θ)μ(s,θ)和近似动作值函数Q(s,a,w)Q(s,a,w),并使用Adam训练网络模型;
(2) 引入经验回放机制:Agent与环境进行交互时产生的经验转移样本具有时序相关性,通过引入经验回放机制,减少值函数估计所产生的偏差,解决数据间相关性及非静态分布问题,使算法更加容易收敛;
(3) 使用双网络架构:策略函数和价值函数均使用双网络架构,即分别设置预测网络和目标网络,使算法的学习过程更加稳定,收敛更快。
核心思想
DDPG的价值网络作为评论家,用于评估策略,学习Q函数,为策略网络提供梯度信息;策略网络作为行动者,利用评论家学习到的Q函数及梯度信息对策略进行改进;同时还引入了带噪声的探索机制和软更新方法。本节将介绍DDPG法的核心思想和主要技术。
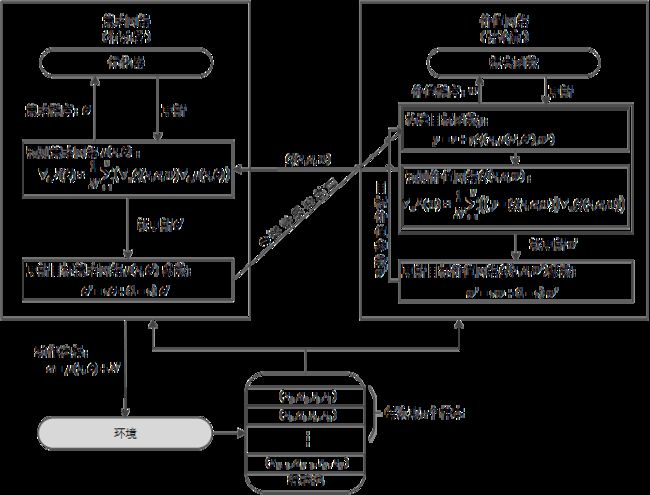
DDPG算法流程图如下
二、DDPG算法实现结果
实验环境:OpenAI Gym工具包中的MuIoCo环境,用了其中四个连续控制任务,包括Ant,HalfCheetah,Walker2d,Hopper
每次训练 均运行1000000步,并每取5000步作为一个训练阶段,每个训练阶段结束,对所学策略进行测试评估 与环境交互十个情节并取平均返回值
结果可视化如下 横轴为训练时间步数,纵轴为训练不同阶段评估所得到的平均回报
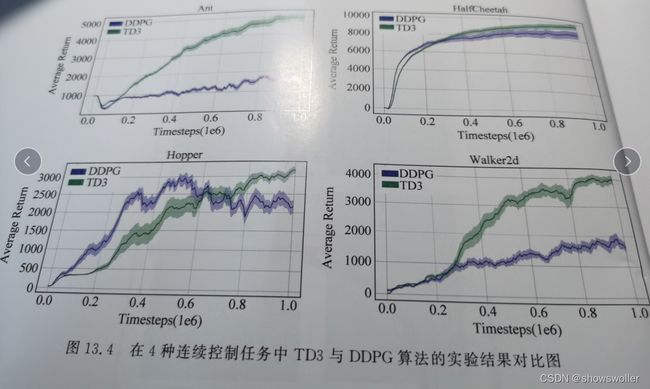
从图中可以看出,在Ant以及Walker2d任务中,DDPG算法有明显的波动,但是总体上随着训练的不断进行,表现性能呈现稳步提升的趋势,在Hopper任务中,在500000步左右性能达到峰值,此后性能下降,在HalfCheetah任务中,DDPG算法表现相对稳定,后期收敛
三、代码
部分源码如下
#深度强化学习——原理、算法与PyTorch实战,代码名称:代40-DDPG算法的实验过程.py
import numpy as np
import torch
import gym
import os
import copy
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
class ReplayBuffer(object):
def __init__(self, state_dim, action_dim, max_size=int(1e6)):
self.max_size = max_size
self.ptr = 0
self.size = 0
self.state = np.zeros((max_size, state_dim))
self.action = np.zeros((max_size, action_dim))
self.next_state = np.zeros((max_size, state_dim))
self.reward = np.zeros((max_size, 1))
self.not_done = np.zeros((max_size, 1))
self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
def add(self, state, action, next_state, reward, done):
self.state[self.ptr] = state
self.action[self.ptr] = action
self.next_state[self.ptr] = next_state
self.reward[self.ptr] = reward
self.not_done[self.ptr] = 1. - done
self.ptr = (self.ptr + 1) % self.max_size
self.size = min(self.size + 1, self.max_size)
def sample(self, batch_size):
ind = np.random.randint(0, self.size, size=batch_size)
return (
torch.FloatTensor(self.state[ind]).to(self.device),
torch.FloatTensor(self.action[ind]).to(self.device),
torch.FloatTensor(self.next_state[ind]).to(self.device),
torch.FloatTensor(self.reward[ind]).to(self.device),
torch.FloatTensor(self.not_done[ind]).to(self.device)
)
class Actor(nn.Module):
def __init__(self, state_dim, action_dim, max_action):
super(Actor, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400, 300)
self.l3 = nn.Linear(300, action_dim)
self.max_action = max_action
def forward(self, state):
a = F.relu(self.l1(state))
a = F.relu(self.l2(a))
return self.max_action * torch.tanh(self.l3(a))
class Critic(nn.Module):
def __init__(self, state_dim, action_dim):
super(Critic, self).__init__()
self.l1 = nn.Linear(state_dim, 400)
self.l2 = nn.Linear(400 + action_dim, 300)
self.l3 = nn.Linear(300, 1)
def forward(self, state, action):
q = F.relu(self.l1(state))
q = F.relu(self.l2(torch.cat([q, action], 1)))
return self.l3(q)
actor1=Actor(17,6,1.0)
for ch in actor1.children():
print(ch)
print("*********************")
critic1=Critic(17,6)
for ch in critic1.children():
print(ch)
class DDPG(object):
def __init__(self, state_dim, action_dim, max_action, discount=0.99, tau=0.001):
self.actor = Actor(state_dim, action_dim, max_action).to(device)
self.actor_target = copy.deepcopy(self.actor)
self.actor_optimizer = torch.optim.Adam(self.actor.parameters(), lr=1e-4)
self.critic = Critic(state_dim, action_dim).to(device)
self.critic_target = copy.deepcopy(self.critic)
self.critic_optimizer = torch.optim.Adam(self.critic.parameters(), weight_decay=1e-2)
self.discount = discount
self.tau = tau
def select_action(self, state):
state = torch.FloatTensor(state.reshape(1, -1)).to(device)
return self.actor(state).cpu().data.numpy().flatten()
def train(self, replay_buffer, batch_size=64):
# Sample replay buffer
state, action, next_state, reward, not_done = replay_buffer.sample(batch_size)
# Compute the target Q value
target_Q = self.critic_target(next_state, self.actor_target(next_state))
target_Q = reward + (not_done * self.discount * target_Q).detach()
# Get current Q estimate
current_Q = self.critic(state, action)
# Compute critic loss
critic_loss = F.mse_loss(current_Q, target_Q)
# Optimize the critic
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Compute actor loss
actor_loss = -self.critic(state, self.actor(state)).mean()
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
# Update the frozen target models
for param, target_param in zip(self.critic.parameters(), self.critic_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
for param, target_param in zip(self.actor.parameters(), self.actor_target.parameters()):
target_param.data.copy_(self.tau * param.data + (1 - self.tau) * target_param.data)
def save(self, filename):
torch.save(self.critic.state_dict(), filename + "_critic")
torch.save(self.critic_optimizer.state_dict(), filename + "_critic_optimizer")
torch.save(self.actor.state_dict(), filename + "_actor")
torch.save(self.actor_optimizer.state_dict(), filename + "_actor_optimizer")
def load(self, filename):
self.critic.load_state_dict(torch.load(filename + "_critic"))
self.critic_optimizer.load_state_dict(torch.load(filename + "_critic_optimizer"))
self.critic_target = copy.deepcopy(self.critic)
self.actor.load_state_dict(torch.load(filename + "_actor"))
self.actor_optimizer.load_state_dict(torch.load(filename + "_actor_optimizer"))
self.actor_target = copy.deepcopy(self.actor)
# Runs policy for X episodes and returns average reward
# A fixed seed is used for the eval environment
def eval_policy(policy, env_name, seed, eval_episodes=10):
eval_env = gym.make(env_name)
eval_env.seed(seed + 100)
avg_reward = 0.
for _ in range(eval_episodes):
state, done = eval_env.reset(), False
while not done:
action = policy.select_action(np.array(state))
state, reward, done, _ = eval_env.step(action)
avg_reward += reward
avg_reward /= eval_episodes
print("---------------------------------------")
print(f"Evaluation over {eval_episodes} episodes: {avg_reward:.3f}")
print("---------------------------------------")
return avg_reward
policy = "DDPG"
env_name = "Walker2d-v4" # OpenAI gym environment name
seed = 0 # Sets Gym, PyTorch and Numpy seeds
start_timesteps = 25e3 # Time steps initial random policy is used
eval_freq = 5e3 # How often (time steps) we evaluate
max_timesteps = 1e6 # Max time steps to run environment
expl_noise = 0.1 # Std of Gaussian exploration noise
batch_size = 256 # Batch size for both actor and critic
discount = 0.99 # Discount factor
tau = 0.005 # Target network update rate
policy_noise = 0.2 # Noise added to target policy during critic update
noise_clip = 0.5 # Range to clip target policy noise
policy_freq = 2 # Frequency of delayed policy updates
save_model = "store_true" # Save model and optimizer parameters
load_model = "" # Model load file name, "" doesn't load, "default" uses file_name
file_name = f"{policy}_{env_name}_{seed}"
print("---------------------------------------")
print(f"Policy: {policy}, Env: {env_name}, Seed: {seed}")
print("---------------------------------------")
if not os.path.exists("./results"):
os.makedirs("./results")
if save_model and not os.path.exists("./models"):
os.makedirs("./models")
env = gym.make(env_name)
# Set seeds
env.seed(seed)
torch.manual_seed(seed)
np.random.seed(seed)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.shape[0]
max_action = float(env.action_space.high[0])
kwargs = {
"state_dim": state_dim,
"action_dim": action_dim,
"max_action": max_action,
"discount": discount,
"tau": tau,
}
policy = DDPG(**kwargs)
if load_model != "":
policy_file = file_name if load_model == "default" else load_model
policy.load(f"./models/{policy_file}")
replay_buffer = ReplayBuffer(state_dim, action_dim)
# Evaluate untrained policy
evaluations = [eval_policy(policy, env_name, seed)]
state, done = env.reset(), False
episode_reward = 0
episode_timesteps = 0
episode_num = 0
for t in range(int(max_timesteps)):
episode_timesteps += 1
# Select action randomly or according to policy
if t < start_timesteps:
action = env.action_space.sample()
else:
action = (
policy.select_action(np.array(state))
+ np.random.normal(0, max_action * expl_noise, size=action_dim)
).clip(-max_action, max_action)
# Perform action
next_state, reward, done, _ = env.step(action)
done_bool = float(done) if episode_timesteps < env._max_episode_steps else 0
# Store data in replay buffer
re
if done:
# +1 to account for 0 indexing. +0 on ep_timesteps since it will increment +1 even if done=True
print(
f"Total T: {t + 1} Episode Num: {episode_num + 1} Episode T: {episode_timesteps} Reward: {episode_reward:.3f}")
# Reset environment
state, done = env.reset(), False
episode_reward = 0
episode_timesteps = 0
episode_num += 1
# Evaluate episode
if (t + 1) % eval_freq == 0:
evaluations.append(eval_policy(policy, env_name, seed))
np.save(f"./results/{file_name}", evaluations)
if save_model:
policy.save(f"./models/{file_name}")创作不易 觉得有帮助请点赞关注收藏~~~