SpringBoot集成Hasor-Dataway数据查询接口
目录
一、前言
1、Hasor Core
Core 容器框架
设计思想
特性
2、Hasor Web
Web 框架
3、Hasor DB
JDBC 框架
特性
4、Hasor DataQL
DataQL 服务查询引擎
设计思想
特性
数据类型
计算精度
表达式计算
基础语法
5、Hasor Boot
Hasor Boot框架
6、Hasor tConsole
Telnet Colsole 框架
7、Hasor Plugins
插件集
8、RSF Framework
RSF 分布式RPC框架
介绍
9、RSF Registry
Rsf-Center Rsf服务注册中心
架构
二、了解一下Hasor
三、创建一个SpringBoot项目,添加Hasor依赖
(1)项目的整体结构
(2)XML
(3)SQL
四、整合SpringBoot和Hasor
(1)config
(2)启动类
(3)application.yml文件--->主要是开启和配置Dataway
(4)application-dev.yml--->主要是配置数据源
五、新建一个Dataway接口
六、总结
一、前言
Hasor:一款强大的 Java 应用开发框架,它的目标是提供一个简单、且必要的全栈环境。开发者可以在此基础上快速开发软件。
1、Hasor Core
Core 容器框架
Hasor 是一款基于 Java 语言的应用程序开发框架,它的核心设计目标是提供一个简单、且必要的环境给开发者。开发者可以在此基础上,通过 Hasor 强有力的粘合机制,构建出更加完善的应用场景。
设计思想
Hasor 提倡开发者充分利用编程语言的优势进行三方整合和模块化设计。同时 Hasor 也主要是通过这种“ 微内核+插件 ”的方式丰富开发所需的所有功能。
决定避开 COC 原则的原因是,COC 虽然已约定的方式降低了整个框架的设计复杂度,但同时也最大限度的牺牲了框架的灵活性。缺少灵活性的框架在应用场景上会受到极大的制约。而 Hasor 的设计则更加通用,因此需要更多的灵活性。
Hasor 强大的灵活性表现在模块整合能力上,对于某一个领域开发方面 Hasor 依然强调并力推 COC 。小而美的核心,大而全的生态圈是 Hasor 的目标。
特性
(1)IoC/Aop编程模型,设计精巧,使用简单。
(2)COC原则的最佳实践,‘零’配置文件。
(3)微内核 + 扩展,基于微内核,让您有无限的可能。
(4)真正的零开发,解析项目特有的自定义 Xml 配置。
(5)支持模板化配置文件,程序打包之后一套配置通吃(日常、预发、线上)以及其它各种环境。
(6)内置事件机制,方便进行业务深度解耦,使业务逻辑更佳清晰。
(7)支持log4j、logback等多种主流日志框架。
(8)体积小,无第三方依赖。
2、Hasor Web
Web 框架
(1)支持 Web 类型项目开发,提供 restful 风格的 mvc 开发方式。
(2)支持Form表单验证、支持场景化验证。
(3)提供开放的模版渲染接口,支持各种类型的模版引擎。
(4)支持 传统 webmvc 方式开发。
(5)支持 RESTful 风格开发。
(6)内置文件上传组件,无需引入任何jar包。
(7)支持自定义请求拦截器。
(8)内置表单验证框架。
3、Hasor DB
JDBC 框架
Hasor-DB 是一款基于jdbc的数据库框架,针对 Spring-JDBC 做了80% 缩减之后在进行大量重构才有了它。
特性
(1)完备的 JDBC 操作接口,支持 Result -> Object 映射。
(2)提供三种途径控制事务,支持七种事务传播属性,标准的事务隔离级别。
(3)支持注解控制事务。
(4)支持多数据源、及多数据源下的事务控制(非JPA)。
(5)集成 MyBatis3。
4、Hasor DataQL
DataQL 服务查询引擎
DataQL 是一款服务查询框架,你可以把任意的服务通过 DataQL 进行查询整合形成新的结果来使用。使用DataQL 将会极大的满足业务灵活性上的开发需要。
因此也可以称 DataQL 为服务聚合引擎。
设计思想
DataQL 的设计思想借鉴了 GraphQL。在借鉴的同时使用了全新的语法,同时增加了一些新特性。这些新特性会让您用起来比 GraphQL 更加舒心,更加接地气。
例如:在 DataQL 中您可以进行常规的表达式计算、也可以执行 if 逻辑判断、它还支持 lambda 函数、甚至您可以在应用中调用 DataQL定义的 lambda 函数。
特性
(1)融入脚本特性,突破 GraphQL 只能做数据组织的界限,让业务开发更加容易。
(2)采用编译执行,拥有飞快的执行速度。
(3)支持使用 lambda 在查询中定义函数。
(4)支持表达式计算。
(5)灵活的 UDF 扩展函数。
(6)完全独立,脱离 Hasor 依然可用。
(7)DataQL 支持 JSON 数据输入。
(8)支持运算符重载(功能暂不开放)
(9)支持DataQL 查询结果返回一个 lambda 定义的 UDF 函数。
(10)支持 JSR223
数据类型
(1)在 DataQL 中总共包含三大数据类型。
1.基本类型
2.原始类型
1.udf函数调用后未经处理的原始数据,原始数据可能是任何一个 java 中的对象。
3.集合类型(List)
2.数组、多维数组、List、Set。在 DataQL 中都可以作为集合类型进行处理。
3.默认集合类型采用的是 ArrayList 保存和处理。
4.结构体(struts)
4.通常指的是具有一个或多个属性集合的数据对象。任何一个 java 对象都可以在 DataQL 当做结构体。
5.当访问结构体中的属性时将会通过 get/set or field 进行读取和访问。
(2)基本类型定义及其取值范围(基本与Java相同)
1.布尔(boolean)
1. true、false
2.数值(number)
1.字节型(byte),长度8, 取值范围:-128 ~ 127
2.短整型(sort),长度16,取值范围:-32768 ~ 32768
3.整型(int), 长度32,取值范围:-2147483648 ~ 2147483648
4.长整型(long),长度64,取值范围:-9233372036854477808 ~ 9233372036854477808
5.浮点型(float),长度32,取值范围:-3.40292347E+38 ~ 3.40292347E+38
6.双精度(double),长度64,取值范围:-1.79769313486231570E+308 ~ 1.79769313486231570E+308
7.大整数(BigInteger),取值范围:java.math.BigInteger
8.大浮点数(BigDecimal),取值范围:java.math.BigDecimal
3.字符串(string)
1.双引号括起来的,或者是单引号括起来的:”xxx” or ‘xxx’
4.空或未定义
1.null
计算精度
(1)浮点数计算精度,默认值保留小数点后20位。
(2)您可以通过 “option MAX_DECIMAL_DIGITS = 20” 来硒鼓改浮点数的默认保留位数。
(3)小数默认舍入规则为:四舍五入。如需更换舍入规则需要通过 “option NUMBER_ROUNDING = “HALF_EVEN” ” 更换
1.UP:向远离零的方向舍入。舍弃非零部分,并将非零舍弃部分相邻的一位数字加一。
2.DOWN:向接近零的方向舍入。舍弃非零部分,同时不会非零舍弃部分相邻的一位数字加一,采取截取行为。
3.CEILING:向正无穷的方向舍入。如果为正数,舍入结果同ROUND_UP一致;如果为负数,舍入结果同ROUND_DOWN一致。注意:此模式不会减少数值大小。
4.FLOOR:向负无穷的方向舍入。如果为正数,舍入结果同ROUND_DOWN一致;如果为负数,舍入结果同ROUND_UP一致。注意:此模式不会增加数值大小。
5.HALF_UP:向“最接近”的数字舍入,如果与两个相邻数字的距离相等,则为向上舍入的舍入模式。如果舍弃部分>= 0.5,则舍入行为与ROUND_UP相同;否则舍入行为与ROUND_DOWN相同。这种模式也就是我们常说的我们的“四舍五入”。
6.HALF_DOWN:向“最接近”的数字舍入,如果与两个相邻数字的距离相等,则为向下舍入的舍入模式。如果舍弃部分> 0.5,则舍入行为与ROUND_UP相同;否则舍入行为与ROUND_DOWN相同。这种模式也就是我们常说的我们的“五舍六入”。
7.HALF_EVEN:向“最接近”的数字舍入,如果与两个相邻数字的距离相等,则相邻的偶数舍入。如果舍弃部分左边的数字奇数,则舍入行为与 ROUND_HALF_UP 相同;如果为偶数,则舍入行为与 ROUND_HALF_DOWN 相同。注意:在重复进行一系列计算时,此舍入模式可以将累加错误减到最小。此舍入模式也称为“银行家舍入法”,主要在美国使用。四舍六入,五分两种情况,如果前一位为奇数,则入位,否则舍去。*/
8.UNNECESSARY:断言请求的操作具有精确的结果,因此不需要舍入。如果对获得精确结果的操作指定此舍入模式,则抛出ArithmeticException。
表达式计算
(1)算数运算:加(+)、减(-)、乘(*)、除(\)、整除(/)、求余(%)、取反(-)
(2)逻辑运算:与(&&)、或(||)、非(!)、异或(^)
(3)比较运算:大于(>)、大于等于(>=)、小于(<)、小于等于(<=)、不等于(!=)、等于(==)
(4)二进制位运算:与(&)、或(|)、异或(^)、向左位移(<<)、向右位移(>>)、不带符号向右位移(>>>)
基础语法
(1)设置查询选项:”option key = value;”
(2)执行查询:”var query = …”
(3)结束查询并返回结果:”return …”
(4)退出整个查询并返回结果:”exit …”
(5)中断查询并抛出异常:”throw …”
(6)定义函数:”var name = lambda : () -> …”
(7)调用UDF或lambda函数:”var name = udfName() …”
(8)未完待续…
5、Hasor Boot
Hasor Boot框架
HasorBoot 是一个快速帮助用户启动运行基于 Hasor 框架应用的启动器。
@SetupModule()
public class ConsoleDemo implements Module {
public static void main(String[] args) {
HasorLauncher.run(ConsoleDemo.class, args);
}
public void loadModule(ApiBinder apiBinder) throws Throwable {
System.out.println("HelloWord");
}
}
下面是一个通过 HasorBoot 快速实现命令路由的例子。下面共有两个命令:hello、help 当执行 main 方法时 第 0 个参数作为路由命令的参数。
@SetupModule()
public class CommandDemo implements Module {
public static void main(String[] args) {
HasorLauncher.run(CommandDemo.class, args);
}
public void loadModule(ApiBinder apiBinder) throws Throwable {
// - 注册命令
apiBinder.tryCast(BootBinder.class).addCommand(0, "hello", new HelloCommand());
apiBinder.tryCast(BootBinder.class).addCommand(0, "help", new HelloCommand());
}
}
public class HelloCommand implements CommandLauncher {
public void run(String[] args, AppContext appContext) {
System.out.println("hello word!");
}
}
public class ShowCommand implements CommandLauncher {
public void run(String[] args, AppContext appContext) {
System.out.println("show help!");
}
}6、Hasor tConsole
Telnet Colsole 框架
提供一个 Telnet 环境支持,给予没有界面类的应用一个可以通过命令行进行交互的工具。
实现一个 命令。
public class HelloWordExecutor implements CommandExecutor {
/** 命令的帮助信息,在 help 时候输出这个信息 */
public String helpInfo() {
return "hello help.";
}
/** 命令输入时,是否接受多行输入?*/
public boolean inputMultiLine(CmdRequest request) {
return false;
}
/** 执行命令体 */
public String doCommand(CmdRequest request) throws Throwable {
return "you say ->" + request.getCommandString();
}
} 注册命令,并设定命令的名为:hello。
Hasor.createAppContext(new Module() {
public void loadModule(ApiBinder apiBinder) throws Throwable {
apiBinder.tryCast(ConsoleApiBinder.class).addCommand(new String[] { "hello" }, HelloWordExecutor.class);
}
});7、Hasor Plugins
插件集
(1)jfinal 插件
(2)junit 插件
(3)web 页面渲染器,json 对象渲染引擎
(4)web 页面渲染器,Freemarker 页面渲染器。
8、RSF Framework
RSF 分布式RPC框架
一个高可用、高性能、轻量级的分布式服务框架。支持容灾、负载均衡、集群。一个典型的应用场景是,将同一个服务部署在多个
Server上提供 request、response 消息通知。使用RSF可以点对点调用,也可以分布式调用。部署方式上:可以搭配注册中心(详细..),也可以独立使用。
介绍
特色功能:
(1)支持服务热插拔:支持服务动态发布、动态卸载
(2)支持服务分组:支持服务分组、分版本
(3)支持多种方式调用:同步、异步、回调、接口代理
(4)支持多种模式调用:RPC模式调用、Message模式调用 RPC 模式: 远程调用会等待并返回执行结果。适用于一般方法。遇到耗时方法会有调用超时风险 Message 模式: 远程调用当作消息投递到远程机器,不会产生等待,可以看作是一个简单的 MQ。适合于繁重的耗时方法
(5)支持点对点调用。RSF的远程调用可以点对点定向调用,也可以集群大规模部署集中提供同一个服务
(6)支持虚拟机房。通过配置虚拟机房策略可以降低跨机房远程调用
(7)支持泛化调用。简单的理解,泛化调用就是不依赖二方包,通过传入方法名,方法签名和参数值,就可以调用服务
(8)支持隐式传参。可以理解隐式传参的含义为,不需要在接口上明确声明参数。在发起调用的时传递到远端
(9)内置 Telnet 控制台,可以命令行方式直接管理机器
(10)支持 offline/online 动作扩展性:
(1)支持第三方集成,可以独立使用,也可以和 Spring、Jfinal等第三方框架整合使用
(2)支持拦截器RsfFilter,开发者可以通过扩展 Filter 实现更多需求
(3)支持自定义序列化。默认使用内置 Hessian 4.0.7 序列化库
(4)支持Telnet控制台自定义指令。通过扩展控制台指令,可以发挥更大想象空间稳定性(参数可配置):
(1)最大发并发请求数配置(默认:200)
(2)最大发起请求超限制策略设置: A-等待1秒重试、B-抛异常(默认:B-抛异常)
(3)Netty线程数配置(默认: 监听请求线程数: 1,IO线程数: 8)
(4)提供者调用队列容量配置(默认: 队列容量: 4096)
(5)Work线程数配置(默认: 处理调用线程数: 4)
(6)请求超时设置。支持服务提供者,服务订阅者独立配置各自的超时参数(默认 6000毫秒)
(7)双向通信。RSF会合理利用Socket连接,双向通信是指当A机器发起远程调用请求之后,RSF会建立长连接 – 如果B机器有调用A机器的需求则直接使用这个连接不会重新创建新的连接,双向通信会大量降低集群间的连接数
(8)支持优雅停机。应用停机,Center会自动通知整个集群。即便所有 Center 离线,RSF也会正确处理失效地址健壮性:
(1)每小时地址本动态备份。当所有注册中心离线,即便在没有注册中心的情况下应用程序重启,也不会导致服务找不到提供者的情况
(2)当某个地址失效之后,RSF会冻结一段时间,在这段时间内不会有请求发往这个地址
(3)支持请求、响应分别使用不同序列化规则可维护性:
(1)支持QoS流量控制。流控可以精确到:接口、方法、地址
(2)支持动态路由脚本。路由可以精确到:接口、方法、参数
(3)通过路由脚本可以轻松实现接口灰度发布安全性:
(1)支持发布服务授权
(2)支持服务订阅授权
(3)支持匿名应用
9、RSF Registry
Rsf-Center Rsf服务注册中心
RSF 的注册中心
架构
一个节点上同一个服务只能以一种身份发布。不能即是消费者也是提供者
暂时不支持多协议下发,因为 rsf 客户端不支持。
二、了解一下Hasor
先给出大家官方网站地址,毕竟官方的才是最权威的。
Hasor官方文档
从官网上,我们可以大致看到Hasor、DataQL、DataWay 三者之间的关系。
Hasor:是由多个不同系列框架组合而成的一个框架体系。插件化是Hasor的基础,DataQL便是其中的一款插件。
DataQL:Hasor的插件之一,是一种查询语言,有自身语法规范,主要作用就是为客户端应用程序提供直观、灵活的数据需求和交互。
DataWay:基于DataQL的可视化服务聚合能力管理平台,主要作用是对DataQL的接口进行配置管理。
注意:上述三段说明是三者关系最浅显的说明,方便刚接触的同事对此三者关系有个大概的了解。此三者的具体的作用,特点,关系 参见官网给出的官方定义。
因此,我们使用DataWay平台开发管理接口,主要参考DataQL的官方文档
Hasor有着自己的独立的生命周期与Spring的不同,是一套完整的体系,最低环境要求是JDK1.8,所以说这个东西很新,提供了注入DataQL、Dataway、hasor-web等等,让你的代码无需在写Controller、Service、Dao、BO、VO、mapper等等东西,这是一个数据聚合项目,有优点也有不足,主要看具体的需求环境是否合适,合适的才是最好的!
我为什么要用Hasor写一个的demo呢?我的需求场景:工作有一套系统对接了一个项目A,项目A会将数据推送到我们这里,我们对数据进行校验并保存请求记录,如果通过了我们的校验,我们在将数据封装推送给另一个项目C。我们的角色有点网关的意思哈,当然这个数据传输过程中的数据交换格式,以及数据内容什么的会发生一些变化。这个时候项目A的开发人员经常会询问我是否已经将数据推送给项目C,每次都需要我打开数据库,写上两行SQL去查询我们数据库中关于这条数据的状态是否已经成功推送到项目C;这是一种及其无聊且没有难度的重复性活动,我怎么会一直手动去数据库中一直给他查数据状态。这个时候的我就看上了Hasor中不用写Controller、service、dao以及各种model、mapper,我想要的只不过是将我在数据库查询到的结果反馈给项目A的开发人员即可。
三、创建一个SpringBoot项目,添加Hasor依赖
(1)项目的整体结构
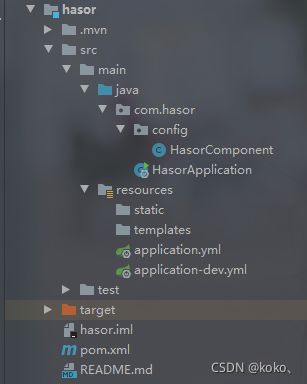
(2)XML
创建一个简单的SpringBoot项目,然后在Maven中添加hasor-spring连通Hasor和Spring,使得能够在SpringBoot中使用hasor,添加hasor-dataway让我们能够不用写Controller这些东西而通过页面配置接口的方式将数据和接口设计出来;一个Jdbc连接,用于连接Mysql数据库,注意使用Hasor-dataway必须使用数据库,配置也必须在数据库中配置两个表.
项目的Maven依赖如下:(以下依赖最好使用Hasor的最新版本,现在迭代速度还是很快的,旧版本可能会存在一些问题)
4.0.0
com.hasor
hasor
0.0.1-SNAPSHOT
hasor
SpringBoot整合Hasor实践
1.8
UTF-8
UTF-8
2.3.7.RELEASE
org.springframework.boot
spring-boot-starter-web
net.hasor
hasor-spring
4.1.7
net.hasor
hasor-dataway
4.1.7
mysql
mysql-connector-java
runtime
org.springframework.boot
spring-boot-starter-jdbc
org.springframework.boot
spring-boot-devtools
runtime
true
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.junit.vintage
junit-vintage-engine
org.springframework.boot
spring-boot-dependencies
${spring-boot.version}
pom
import
org.apache.maven.plugins
maven-compiler-plugin
3.8.1
1.8
1.8
UTF-8
org.springframework.boot
spring-boot-maven-plugin
2.3.7.RELEASE
com.hasor.HasorApplication
repackage
repackage
(3)SQL
打开数据库,创建两个新的表,用于维护dataway的API,建表建议参考官方网站的,因为不同版本的Hasor依赖的表的字段可能是不同的。
建表语句如下(如果出现表问题,可以参照官方网站修改)
CREATE TABLE `interface_info` (
`api_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`api_method` varchar(12) NOT NULL COMMENT 'HttpMethod:GET、PUT、POST',
`api_path` varchar(512) NOT NULL COMMENT '拦截路径',
`api_status` int(2) NOT NULL COMMENT '状态:0草稿,1发布,2有变更,3禁用',
`api_comment` varchar(255) DEFAULT NULL COMMENT '注释',
`api_type` varchar(24) NOT NULL COMMENT '脚本类型:SQL、DataQL',
`api_script` mediumtext NOT NULL COMMENT '查询脚本:xxxxxxx',
`api_schema` mediumtext COMMENT '接口的请求/响应数据结构',
`api_sample` mediumtext COMMENT '请求/响应/请求头样本数据',
`api_option` mediumtext COMMENT '扩展配置信息',
`api_create_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`api_gmt_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '修改时间',
PRIMARY KEY (`api_id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8mb4 COMMENT='Dataway 中的API';
CREATE TABLE `interface_release` (
`pub_id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'Publish ID',
`pub_api_id` int(11) NOT NULL COMMENT '所属API ID',
`pub_method` varchar(12) NOT NULL COMMENT 'HttpMethod:GET、PUT、POST',
`pub_path` varchar(512) NOT NULL COMMENT '拦截路径',
`pub_status` int(2) NOT NULL COMMENT '状态:0有效,1无效(可能被下线)',
`pub_type` varchar(24) NOT NULL COMMENT '脚本类型:SQL、DataQL',
`pub_script` mediumtext NOT NULL COMMENT '查询脚本:xxxxxxx',
`pub_script_ori` mediumtext NOT NULL COMMENT '原始查询脚本,仅当类型为SQL时不同',
`pub_schema` mediumtext COMMENT '接口的请求/响应数据结构',
`pub_sample` mediumtext COMMENT '请求/响应/请求头样本数据',
`pub_option` mediumtext COMMENT '扩展配置信息',
`pub_release_time` datetime DEFAULT CURRENT_TIMESTAMP COMMENT '发布时间(下线不更新)',
PRIMARY KEY (`pub_id`),
KEY `idx_interface_release` (`pub_api_id`)
) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8mb4 COMMENT='Dataway API 发布历史。';
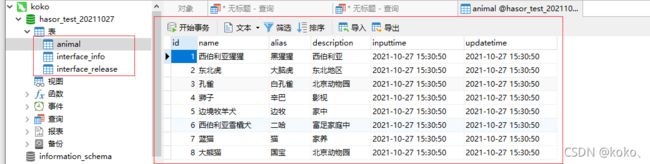
为了演示效果,我新建一个了animal表作为演示用,里面的inputtime和updatetime主要用于演示DataQL,建表语句如下:
CREATE TABLE `animal` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '自增主键',
`name` varchar(20) NOT NULL COMMENT '动物名称',
`alias` varchar(40) NOT NULL COMMENT '动物别名',
`description` varchar(300) DEFAULT '' COMMENT '动物描述',
`inputtime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '动物信息入机时间',
`updatetime` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '动物信息更新时间',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
插入几条测试数据 :
INSERT INTO animal (name,alias,description) VALUES ('西伯利亚猩猩','黑猩猩','西伯利亚');
INSERT INTO animal (name,alias,description) VALUES ('东北虎','大脑虎','东北地区');
INSERT INTO animal (name,alias,description) VALUES ('孔雀','白孔雀','北京动物园');
INSERT INTO animal (name,alias,description) VALUES ('狮子','辛巴','影视');
INSERT INTO animal (name,alias,description) VALUES ('边境牧羊犬','边牧','家中');
INSERT INTO animal (name,alias,description) VALUES ('西伯利亚雪橇犬','二哈','富足家庭中');
INSERT INTO animal (name,alias,description) VALUES ('蓝猫','猫','家养');
INSERT INTO animal (name,alias,description) VALUES ('大熊猫','国宝','北京动物园');
测试数据如下:
四、整合SpringBoot和Hasor
SpringBoot整合Hasor中的dataway主要是将数据也配置到Hasor中,同时在启动入口开启Hasor和Hasor-web。整合起来也是十分的简单。
(1)config
package com.hasor.config;
import net.hasor.core.ApiBinder;
import net.hasor.core.DimModule;
import net.hasor.db.JdbcModule;
import net.hasor.db.Level;
import net.hasor.spring.SpringModule;
import org.springframework.stereotype.Component;
import javax.sql.DataSource;
/**
* @author 刘芳
*/
@DimModule //Hasor中的标签,表明时一个Hasor中的一个Model
@Component //Spring中的标签,表明是一个组件
public class HasorComponent implements SpringModule {
private DataSource dataSource;
public HasorComponent(DataSource dataSource){
this.dataSource = dataSource;
}
/**
* Hasor 启动的时候会调用 loadModule 方法,
* 在这里再把 DataSource 设置到 Hasor 中。
* @param apiBinder
* @throws Throwable
*/
@Override
public void loadModule(ApiBinder apiBinder) throws Throwable {
apiBinder.installModule(new JdbcModule(Level.Full, this.dataSource));
}
}
(2)启动类
package com.hasor;
import net.hasor.spring.boot.EnableHasor;
import net.hasor.spring.boot.EnableHasorWeb;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
/**
* 启用Hasor
*/
@EnableHasor
@EnableHasorWeb // 将 hasor-web 配置到 Spring 环境中,Dataway 的 UI 是通过 hasor-web 提供服务。
@SpringBootApplication
public class HasorApplication {
public static void main(String[] args) {
SpringApplication.run(HasorApplication.class, args);
}
}
(3)application.yml文件--->主要是开启和配置Dataway
server:
port: 9800
spring:
profiles:
active: dev
# 是否启用 Dataway 功能(必选:默认false)
HASOR_DATAQL_DATAWAY: true
# 是否开启 Dataway 后台管理界面(必选:默认false)
HASOR_DATAQL_DATAWAY_ADMIN: true
# dataway API工作路径(可选,默认:/api/)
HASOR_DATAQL_DATAWAY_API_URL: /interface/
# dataway-ui 的工作路径(可选,默认:/interface-ui/)
HASOR_DATAQL_DATAWAY_UI_URL: /config/
# SQL执行器方言设置(可选,建议设置)
HASOR_DATAQL_FX_PAGE_DIALECT: mysql
(4)application-dev.yml--->主要是配置数据源
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/hasor_test_20211027?characterEncoding=UTF-8&serverTimezone=UTC&useSSL=false&allowPublicKeyRetrieval=true
username: root
password: 123456
driver-class-name: com.mysql.cj.jdbc.Driver
五、新建一个Dataway接口
首先介绍一些Dataway的基本知识,Dataway可以通过UI页面定义数据接口,然后通过自测和冒烟以后才能发布这个接口,当接口发布成功以后,就可以通过我们定义的接口路径来访问获取数据了,这些接口数据都是保存在我们上面创建的interface_info表中的,当然接口发布以后也可以修改,也即接口可以有历史版本,这些信息保存在interface_release 表中,这也就是为什么我们什么要在上面定义这两个表;(Ps:当然Dataway也可以通过编写代码来实现)在Dataway的数据访问中使用的是一种名字叫做DataQL的脚本语言,类似JavaScript 先来一段官网的说明定义:
DataQL(Data Query Language)DataQL 是一种查询语言。旨在通过提供直观、灵活的语法来描述客户端应用程序的数据需求和交互。
数据的存储根据其业务形式通常是较为简单的,并不适合直接在页面上进行展示。因此开发页面的前端工程师需要为此做大量的工作,这就是 DataQL 极力解决的问题。另外还支持使用SQL来,但是SQL在Dataway中最终也都是转换成DataQL

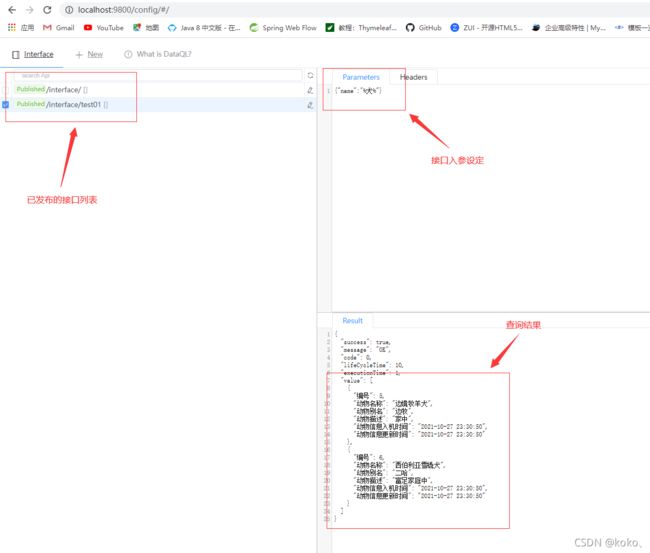
Dataway页面说明:
1、功能按钮:可以查看所有已经发布的接口
2、功能按钮:可以创建新的接口
3、链接:打开DataQL接口说明
4、请求方式:Http请求方式定义,默认是POST方法
5、接口路径:定义接口的请求路径,/interface/为配置文件中HASOR_DATAQL_DATAWAY_API_URL属性事先定义的值,后面补充路径,当接口路径发布后,后面定义的接口请求路径不能重名
6、接口说明:可以为接口添加中文说明
7、使用DataQL编写接口,默认选择为DataQL
8、使用SQl编写接口
9、接口编写代码部分
10、功能按钮:保存9部分编写的代码,注意只有先保存才能进行冒烟测试
11、功能按钮:测试按钮,当编写接口代码时,使用此按钮进行接口测试
12、功能按钮:冒烟测试按钮,通过了冒烟测试以后才能发布
13、功能按钮:发布接口,发布接口以后以后就可以通过发布的接口获取数据
14、功能按钮:接口编辑历史记录,可以通过历史记录回滚9区域的代码
15、功能按钮:删除按钮,点击删除后删除已经发布的接口(数据库中也会清除这条记录)
16、18功能区域:这个区域可以设置接口的请求参数例如通过POST方法传输一个请求报文,在此区域定义
17、功能按钮:设置接口的请求头参数
19、功能区域:测试接口区域,点击11测试按钮或者12冒烟以后在此区域显示测试结果
1)在介绍完了页面的基本功能以后,新建一个请求接口。
在页面中点击【new】新建一个数据接口,请求方式设置为【GET】方法,路径为【querytest】,接口说明为【请求接口GET方法测试】,选择使用【DataQL】开发(功能会更强大一点),编写代码部分的主要功能为查询数据中动物表(animal)中的(name)字段中包含犬的数据,接口参数设置为【name】传输要查询包含某个字的动物数据代码如下:
// 查询动物表中名字中包含犬的数据
// 定义一个函数,将函数的查询结果存贮在querydog中
// @@sql()为插入外部SQL代码,<% %>为SQl代码区域
// name为函数的参数,如果想要在SQL使用这个参数,需要使用#{name}来使用
// #,$,@都为特殊符号,一般情况下用法一致,更多用法可参考官方说明
var querydog = @@sql(name)<%
select * from animal where name like #{name}
%>
// 返回上述SQL查询到的数据
// 通过$获取Parameters中的传过来的name 参数值
return querydog(${name});
运行效果如下:
我们在接口返回中可以看见我们创建的animal表中的动物信息入机时间和更新时间都是时间戳,我们通过DataQL查询出来的也为时间戳,这个时候我们就可以借助DataQL的函数对数据进行一个转换
,与此同时,我们还可以借助lambda解析数据,将代码改为如下:
// 查询动物表中名字中包含犬的数据
// 定义一个函数,将函数的查询结果存贮在querydog中
// @@sql()为插入外部SQL代码,<% %>为SQl代码区域
// name为函数的参数,如果想要在SQL使用这个参数,需要使用#{name}来使用
// #,$,@都为特殊符号,一般情况下用法一致,更多用法可参考官方说明
var querydog = @@sql(name)<%
select * from animal where name like #{name}
%>
// 返回上述SQL查询到的数据
// 通过$获取Parameters中的传过来的name 参数值
// 修改返回报文中的将id换成编号,name 换成动物名称 诸如此类......
// 查询到的数据包含多个对象,注意格式 [{}],不然只显示一个
return querydog(${name})=>[{
"编号":id,
"动物名称":name,
"动物别名":alias,
"动物描述":description,
"动物信息入机时间":inputtime,
"动物信息更新时间":updatetime
}]
运行结果如下:

添加DataQL中的FunctionX函数将时间戳改为我们指定格式时间格式,首先需要引入日期这个函数,as的作用相当于起一个别名来使用这个函数:
import 'net.hasor.dataql.fx.basic.DateTimeUdfSource' as time;
在返回数据调用format方式格式化时间如下:
import 'net.hasor.dataql.fx.basic.DateTimeUdfSource' as time;
// 查询动物表中名字中包含犬的数据
// 定义一个函数,将函数的查询结果存贮在querydog中
// @@sql()为插入外部SQL代码,<% %>为SQl代码区域
// name为函数的参数,如果想要在SQL使用这个参数,需要使用#{name}来使用
// #,$,@都为特殊符号,一般情况下用法一致,更多用法可参考官方说明
var querydog = @@sql(name)<%
select * from animal where name like #{name}
%>
// 定义一个处理updatetime日期格式的函数
var formatupdatetime = (updatetime)->{
return time.format(updatetime, "yyyy-MM-dd HH:mm:ss")
}
// 返回上述SQL查询到的数据
// 通过$获取Parameters中的传过来的name 参数值
// 修改返回报文中的将id换成编号,name 换成动物名称 诸如此类......
// 查询到的数据包含多个对象,注意格式 [{}],不然只显示一个
// 调用日期函数,将Long类型的时间戳输出为格式化的时间
// dang然也可以定义一个函数来进行处理,如上的formatupdatetime函数
return querydog(${name})=>[{
"编号":id,
"动物名称":name,
"动物别名":alias,
"动物描述":description,
"动物信息入机时间":time.format(inputtime, "yyyy-MM-dd HH:mm:ss"),
"动物信息更新时间": formatupdatetime(updatetime)
}]
运行结果如下: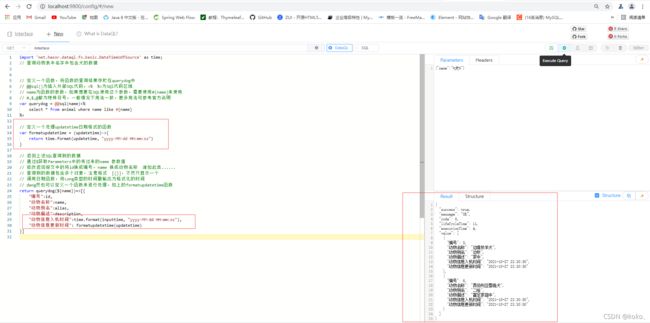
至此我们通过GET方法查询动物表中动物名称包含有犬的功能接口就开发完了,点击保存按钮进行保存,点击冒烟测试按钮进行测试,点击发布按钮进行发布。发布成功以后,我们就可以通过定义的API直接获取数据了,而不需要进行Controller、service、dao、Mapper等的书写;
然后我们在浏览器中直接输入已经发布的API ,测试能否获取我们预想的数据;
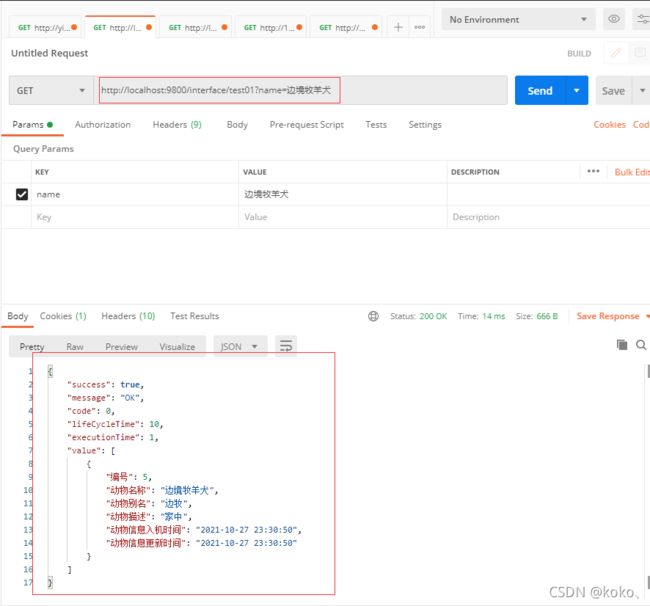
注意这里我们设置成GET请求方式,需要的入参为name的值,请求路径应如:http://localhost:9800/interface/test01?name=边境牧羊犬
这与POST请求方式不同;(这里的接口设计是有一定问题的,我们为了模糊查询在参数中传入了%,中文转码以后会有冲突,可以换成数据库name为边境牧羊犬进行查询或者使用Postman传参)

使用Postman的测试结果如下:
六、总结
总结一下,个人觉得Hasor还是有很多有点,例如可以很方便的和SpringBoot结合,可以不用写Controller、service、dao、mapper这一套东西,可以动态修改API等等;但是缺点也是有的,个人觉得这东西还很年轻,有一定的学习成本(例如要学习DataQL)等等这些。