Tensorflow&numpy&keras比较详细的学习笔记(附每一个函数的示例代码和练习程序)
笔者结合北京大学Tensorflow学习笔记和一些个人在书籍中的理解以及对Tensorflow官方的学习对Tensorflow进行了系统化的Tensorflow常用函数和变量的笔记总结,里面包括了从基础的张量创建到深入的初步和进阶的进行构造BP,CNN,RNN等网络模型的Tensorflow_keras实现和改进,同时介绍并实现了了五大经典CNN网络LeNet,AlexNet,VGGNet,InceptionNet,ResNet
和经典LSTM股票预测等程序。
本文可供神经网络初学者使用和参考,也可供时间不允许,需要迅速使用网络框架的学者参考,如需查阅详细CNN,RNN,LSTM,DHNN等详细网络构造和数学推导,笔者这里推荐各位一本不错的书:《Neural Networks and Deep Learning》,编者邱锡鹏,机械工业出版。这本书里粗略的介绍了网络的构造和一些浅显的数学推导,如需了解神经网络构造和工作原理的读者,感兴趣的可以参考电子书籍《Neuronal DynamicsFrom single neurons to networks and models of cognition》,电子书原文地址如下:
https://neuronaldynamics.epfl.ch/index.html
北京大学Tensorflow学习网课原地址如下,如需要的读者可以自行查看
https://www.icourse163.org/learn/PKU-1002536002?tid=1462067447#/learn/announce,本文的绝大部分内容来自本人在此记的笔记。
本文不包含严格数学推导和过多的原理介绍!仅包含代码应用。
阅读本文需要先对神经网络的基本框架构造和基础计算方式如CNN的卷积办法,RNN的结构,LSTM的门控办法等有所了解才能看的懂一些,如需了解,可参考周志华《机器学习》中BP神经网络的工作方法和上述两本书中RNN,LSTM和CNN的工作原理。
本文内容仅供初学者进行初步了解和快速学习Tensorflow相关的应用,如需进一步了解和系统化学习请各位查看Tensorflow官方说明,更全更准确。
文章目录
- 一、Tensor张量创建和张量转换
-
- 1.1、Tensor张量创建
-
- 1.1.1、函数的用法解释和说明:
-
- example1:
- 1.2、Tensor张量转换
-
-
- example2:
-
- 二、Tensorflow常用函数
-
- 2.1、 tf.zeros(),tf.ones()tf.fill()
-
-
- example3:
-
- 2.2、正态分布(截断与非截断)&均匀分布
-
- 2.2.1、函数的用法解释和说明:
-
- example4:
- 2.3、其他常用的一些基本的重要操作
-
-
- example5:
-
- 三、Tensorflow网络框架基础函数用法
-
- 3.1、网络参数的初始化和可训练函数tf.Variable()
-
- 3.1.1、函数的用法解释和说明:
-
- example6:
- 3.2、损失函数&激活函数
-
- 3.2.1、损失函数loss()及其类型
-
- example7:
- example8:自定义损失函数loss:
- 3.2.2、激活函数及其类型
- 3.3、经典BP网络梯度的计算和tf.GradientTape()的梯度用法
-
- 3.3.1、函数的用法解释和说明:
- 3.4、网络训练前对数据特征处理和参数选择。
- 3.5、特征,标签合并和喂入网络的batch选取函数
-
- 3.5.1、函数的用法解释和说明:
- 3.6、其他重要的函数:
-
-
- example9:
- example10:
- example11:
- example12:
-
- 四、最基础的神经网络TensorFlow构建
-
- step1:import相关的库函数
- step2:读取相关特征标签,并进行初设置网络内容。
- step3:搭建网络框架
- step4:正向传播和反向传播更新参数
- step5:验证网络的好坏并进行测试对比
-
-
- example13:
-
- 五、网络动态学习率&网络正则化
-
- 5.1、网络优化方法一:动态学习率
- 5.2、网络优化方法二:正则化操作
-
- 5.2.1、L1正则化
- 5.2.2、L2正则化
- 六、网络动量优化
-
- 6.1、一阶动量和二阶动量:
- 6.2、网络参数更新过程
- 6.3、网络优化器
-
-
- example14:以example13为例子的优化器。
-
- 七、keras网络搭建和构造
-
- 7.1、六步法搭建神经网络
-
- 7.1.1、import相关库文件
- 7.1.2、定义训练集和测试集及其各自的特征和标签
-
- example15:
- 7.1.3、搭建网络函数model=tf.keras.models.Sequential([网络结构])
-
- example16:
- 7.1.4、构建网络方法model.compile()
-
- example17:
- 7.1.5、网络方法model.fit()
-
- example18:
- 7.1.6、网络总结model.summary()
- 八、MINIST&FASHION数据集实训
-
- 8.1、example19(MNIST):
- 8.2、example20(FASHION):
- 九、class定义神经网络model
- 十、数据增强&参数提取
-
- 10.1、数据增强
-
-
- example21(数据增强):
-
- 10.2、参数提取
-
- 10.2.1、np控制输出print
- 十一、网络预测&断点续训
-
- 11.1、断点续训-保存文件
-
-
- example22(断点续训-保存文件):
-
- 11.2、断点续训-读取文件
-
-
- example23(断点续训-读取文件):
- example24(断点续训完整版本):
-
- 11.3、网络预测predict()函数
-
-
- example25(网络预测):
-
- 十二、卷积神经网络(CBAPD)
-
- 12.1、感受野
- 12.2、零填充
- 12.3、Tensorflow卷积函数tf.keras.layers.Conv2D()
- 12.4、批次标准化BN层&池化层&舍弃层
-
-
- example26(卷积网络model)(CBAPD原则):
-
- 十三、卷积神经网络在cifar10上的应用
-
-
-
- example27(cifar10数据集两层卷积两层池化,两层全连接):
-
-
- 十四、LeNet,AlexNet,VGGNet网络架构及其实现
-
- 14.1、LeNet网络结构框架(1998)
-
-
- example28(LeNet):
-
- 14.2、AlexNet网络结构框架(2012)
-
-
- example29(AlexNet):
-
- 14.3、VGGNet网络结构框架(2014)
-
-
- example30(16=13+3dense的VGGNet):
-
- 十五、ResNet,InceptionNet网络架构及其实现
-
- 15.1、InceptionNet网络结构框架(2014)
-
- 15.1.1、InceptionNet结构块功能:
-
- example31(InceptionNet结构块定义)
- example32(InceptionNet网络):
- 15.2、ResNet网络结构框架(2015)
-
- 15.2.1、ResNet结构块功能:
-
- example33(ResNet结构块定义):
- example34(ResNet):
- 十六、循环神经网络
-
- 16.1、循环核
- 16.2、Tensorflow的tf.keras.layers.SimpleRNN()
-
- 16.2.1、函数详解
- 16.2.2、API维数要求
- 16.3、独热编码——字母预测
-
- 16.3.1、特征转独热编码:
-
- example35(字母预测abcdef-不按照时间展开):
- example36(字母预测abcdef-按照时间展开):
- 16.4、Embedding编码
-
- 16.4.1、Embedding编码函数:
- 16.4.2、Embedding编码维度要求:
-
- example37(改example35成Embedding编码):
- 16.5、RNN股票预测
-
-
- example38(RNN股票预测):
- 16.5.1、RNN-预测效果
- 16.5.2、预测说明
-
- 16.6、长短时记忆神经网络LSTM
-
- 16.6.1、原理说明:
- 16.6.2、Tensorflow LSTM函数
- 16.6.3、LSTM改进股票预测
-
- example39(LSTM改进股票预测):
- 16.6.4、LSTM-预测效果
- 16.7、GRU网络
-
- 16.7.1、Tensorflow GRU函数
- 16.7.2、GRU改进股票预测
-
- example40(GRU改进股票预测):
- 16.7.3、GRU-预测效果
- 十七、本文总结
一、Tensor张量创建和张量转换
1.1、Tensor张量创建
Tensorflow的张量定义如下::
tf.constant(张量内容,dtype=数据类型)
1.1.1、函数的用法解释和说明:
①常用的dtype示例如下:
| 序号 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 类型 | t f . i n t tf.int tf.int | t f . f l o a t tf.float tf.float | t f . f l o a t 32 tf.float32 tf.float32 | t f . f l o a t 64 tf.float64 tf.float64 | t f . i n t 32 tf.int32 tf.int32 |
当然不局限于表格里面这些,比如一些tf.string和tf.bool等不常用的笔者未列出,想要用的读者可以详细查找。
②张量内容可以是一维数值,二维向量,或者三维矩阵,n维向量···
example1:
tf.constant(35,dtype=tf.int64)#这是数的定义
tf.constant([1.1,2.2,3.3],dtype=tf.float32)#这是向量的定义
tf.constant([[1.1,2.2],[3.3,4.4]],dtype=tf.float32)#这是矩阵的定义
以此类推,你想要去定义多少维就可以定义多少维。
Tensorflow的张量转换函数如下:
1.2、Tensor张量转换
Tensorflow的张量转换如下::
tf.convert_to_numpy(要转换的数据名,dtype=数据类型)
由于日常生活中导入python的数据类型经常以numpy的np对象来导入,因此需要进行np和tf之间的数据转换。
example2:
import numpy as np
import tensorflow as tf
data=np.arange(0,10,1)
n_data=tf.convert_to_tensor(data,dtype=tf.int64)#数据转换为tf类型数据
二、Tensorflow常用函数
2.1、 tf.zeros(),tf.ones()tf.fill()
tf.zeros(维度),tf.ones(维度),tf.fill(维度,指定填充值)
example3:
tf.zeros([2,2])#——生成2×2的零矩阵。
tf.ones(7)#——生成7个1,一维向量。
tf.fill([4,4],9)#——生成4×4的全9矩阵。
2.2、正态分布(截断与非截断)&均匀分布
①tf.random.normal(维度,mean=均值,stddev=标准差)
②tf.random.truncated_normal(维度,mean=均值,stddev=标准差)
③tf.random.uniform(维度,minval=最小值,maxval=最大值
2.2.1、函数的用法解释和说明:
第一个是表示生成正态分布随机数的,第二个表示生成截断式正态分布随机数的,这里的截断式表示生成以均值为原点,两倍标准差为变化范围的正态分布数据,相当于截断了两边的尾。第三个函数为生成均匀分布[minval,maxval]的数据。
example4:
tf.random.normal([2,2],mean=5,stddev=1)
#2×2维正态分布随机数,满足均值是5,方差是1
tf.random.truncated_normal([2,2],mean=5,stddev=1)
#截断式正态分布,其余和上面一样。
tf.random.uniform([2,2],minval=-1,maxval=6)
#生成[-1,6]的均匀分布2×2矩阵数据。
2.3、其他常用的一些基本的重要操作
①tf.cast(张量名称,dtype=数据类型)——张量强制转换
②tf.reduce_min(张量名称,axis=0 or 1)——求最小值,axis为0代表按列求(每一列的最小),axis为1代表按行求最小(即每一行的最小)。
③tf.reduce_max(张量名称,axis=0 or 1)——求最大值,axis为0代表按列求(每一列的最大),axis为1代表按行求(即每一行的最大)。
④tf.reduce_mean(张量名称,axis=0 or 1) ——求平均值,axis为0代表按列求(每一列的平均值),axis为1代表按行求(即每一行的平均值)。
⑤tf.reduce_sum(张量名称,axis=0 or 1)——求和,axis为0代表按列求(每一列的和),axis为1代表按行求(即每一行的和)
⑥tf.add(张量1,张量2)(张量1+张量2),tf.subtract(张量1,张量2)(张量1-张量2),tf.multiply(张量1,张量2)(张量1×张量2),tf,divide(张量1,张量2)(张量1÷张量2),tf.square(张量1)(张量1平方),tf.pow(张量1,张量2)(张量1的张量2次幂),tf.sqrt(张量1)(张量1开方),tf.matmul(张量1,张量2)(张量1×张量2的矩阵乘法,tf.greater(张量1,张量2)返回张量一是否大于张量二的bool阵。
⑦tf.where(条件语句,A,B)——条件语句为真执行A,否则执行B
example5:
import tensorflow as tf
tf.compat.v1.disable_eager_execution()#2.0版本没办法兼容Session
data=tf.constant([[1.1,2.2],[3.3,4.4],[5.5,6.6]],dtype=tf.float32)
tf.cast(data,dtype=tf.float64)#强制转换数据
tf.reduce_min(data,axis=1)#按列求最小,结果为[1.1,3.3,5.5]
tf.reduce_min(data,axis=0)#按行求最小,结果为[1.1,2.2]
tf.reduce_max(data,axis=1)#按列求最大,结果为[2.2,4.4,6.6]
tf.reduce_max(data,axis=0)#按行求最大,结果为[5.5,6.6]
tf.reduce_mean(data,axis=1)#按列求平均,结果为[1.6500001,3.85,6.05]
tf.reduce_mean(data,axis=0)#按行求平均,结果为[3.3 4.4]
tf.reduce_sum(data,axis=1)#按列求和,结果为[3.3000002,7.7,12.1]
tf.reduce_sum(data,axis=0)#按行求和,结果为[9.9,13.200001]
data1=tf.constant(1,dtype=tf.float64)
data2=tf.constant(5,dtype=tf.float64)
data3=tf.constant([[1,2,3],[4,5,6],[7,8,9]],dtype=tf.int32)
tf.add(data1,data2)#加法,结果是6
tf.subtract(data1,data2)#减法,结果是-5
tf.multiply(data1,data2)#乘法,结果是5
tf.divide(data1,data2)#除法,结果是0.2
tf.square(data1)#平方,结果是1
tf.pow(data1,data2)#乘方,结果是1
tf.sqrt(data1)#开方,结果是1
tf.matmul(data3,data3)#矩阵乘法,结果如下:
#[[ 30 36 42], [ 66 81 96], [102 126 150]]
sess=tf.compat.v1.Session()#2.0版本没办法兼容Session。
A=tf.where(tf.greater(data1,data2),1,0)#data1是否比data2大?是则1,否则0
print(sess.run(A))#因为data1
#输出为0
y1=tf.constant([0.1,0.6,0.3],dtype=tf.float32)
y_1=tf.constant([0.2,0.7,0.1],dtype=tf.float32)
B=tf.where(tf.greater(y1,y_1),1,0)#y1是否比y_1大?是则1,否则0
print(sess.run(B))#输出为[0 0 1]
三、Tensorflow网络框架基础函数用法
3.1、网络参数的初始化和可训练函数tf.Variable()
可训练函数定义如下:
tf.Variable(张量)
3.1.1、函数的用法解释和说明:
tf.Variable(张量)将张量设置成为可训练的参数,在神经网络中可以进行训练和反向传播等操作。
example6:
w1=tf.Variable(tf.random.truncated_normal([2,35],mean=0,stddev=1))
b1=tf.Variable(tf.constant(0.01,shape=[35]))#2*35第一层
w2=tf.Variable(tf.random.truncated_normal([35,6],mean=0,stddev=1))
b2=tf.Variable(tf.constant(0.01,shape=[6]))#35*6第二层
w3=tf.Variable(tf.random.truncated_normal([66,1],mean=0,stddev=1))
b3=tf.Variable(tf.constant(0.01,shape=[1]))#6*1第三层
这里笔者定义了一个三层的神经网络参数,假定我们的输入是二维向量,为1×2的,第一层是2×35个参数,偏置为1×35,第一层走过之后为1×35的向量,现在走第二层,第二层是35×6个参数,偏置为1×6,第二层走过后为1×6的向量,我们假定输出为1个值,那么第三层为6×1个参数,偏置为1×1,这样输出就是1×1个值。在这里我们定义了6个可训练变量,可以在今后的反向传播和其他操作中使用这六个变量。
3.2、损失函数&激活函数
首先介绍softmax函数:
①tf.nn.softmax(X)
它将输入的N维向量X按照概率分布 p i p_i pi输出如下:
p i = e ( x i ) ∑ j = 1 N e ( x j ) p_i=\frac{e^{(x_i)}}{\sum_{j=1}^Ne^{(x_j)}} pi=∑j=1Ne(xj)e(xi)
3.2.1、损失函数loss()及其类型
我们假设真实值为y1,网络输出值为y_1
Ⅰ、平方损失函数tf.reduce.mean(tf.square(y_1-y1))
Ⅱ、交叉熵损失函数tf.losses.categorical_crossentropy(y_1,y1)
交叉熵损失函数重点用法:送入交叉熵函数的y1和y_1比如都是概率分布!
所以一般先通过softmax将它化成概率分布后再进行交叉熵计算,交叉熵计算方法如下:H(y_1,y1)= − ∑ -\sum −∑(y_1)log(y1)
Ⅲ、不需要softmax直接可以计算的交叉熵损失函数,相当于softmax和交叉熵的合体版本:tf.nn.softmax_cross_entropy_with_logits(y_1,y)
example7:
y1=tf.constant([0.1,0.6,0.3],dtype=tf.float32)
y_1=tf.constant([0.2,0.7,0.1],dtype=tf.float32)
y2=tf.constant([1,6,3],dtype=tf.float32)
y_2=tf.constant([2,9,4],dtype=tf.float32)
tf.losses.categorical_crossentropy(y_1,y1)#交叉熵损失,结果为0.938
tf.reduce_mean(tf.square(y_1-y1))#平方损失,结果为0.020000001
tf.nn.softmax_cross_entropy_with_logits(y_2,y2)#直接计算交叉熵损失,结果为22.82478(不需要softmax了)
Ⅴ、自定义损失函数:例如以下分段函数:
loss(y1,y_1)=0.3(y_1-y1)(y_1>y1)
loss(y1,y_1)=0.5(y1-y_1)(y_1
example8:自定义损失函数loss:
loss=tf.reduce_sum(tf.where(tf.greater(y_1,y1),0.3(y_1-y1),0.5(y1-y_1)))
print(sess.run(loss))#结果为0.16,请自行计算验证正确性
3.2.2、激活函数及其类型
一般来说,如过网络上一层输入是 x x x的话,不加任何激活,这一层的输出 y y y应该是如下所示的:其中 w w w为权重矩阵, b b b为偏置向量。
y = − x T w + b y=-x^Tw+b y=−xTw+b
但是这样,是一个线性方程,而我们的神经网络目的是去模拟非线性的居多,因此需要增加非线性因素进来,如何增加非线性因素呢?这就引入了激活函数的出现。
激活函数改进点在于将原来的输出不再是线性的而是增加了非线性因素:
y = f ( − x T w + b ) y=f(-x^Tw+b) y=f(−xTw+b)
这里的 f f f我们称之为激活函数,上式也是正向传播的关键。激活函数有以下几个大类:
Ⅰ、sigmod: f ( x ) = 1 1 + e x f(x)=\frac{1}{1+e^x} f(x)=1+ex1容易梯度消失
Ⅱ、tanh: f ( x ) = 1 − e − 2 x 1 + e − 2 x f(x)=\frac{1-e^{-2x}}{1+e^{-2x}} f(x)=1+e−2x1−e−2x容易梯度消失
Ⅲ、Relu: f ( x ) = 0 ( x < 0 ) , x ( x ≥ 0 ) f(x)=0(x<0),x(x≥0) f(x)=0(x<0),x(x≥0)解决了大于零的梯度消失但是没解决小于零的,收敛速度慢
Ⅳ、Leaky Relu: f ( x ) = m a x ( a x , x ) f(x)=max(ax,x) f(x)=max(ax,x) a a a是超参数,一般由我们自己去给定,这个可以解决小于零的梯度消失问题,但是这个函数用的很少。
Ⅴ、其他的自定义激活函数
激活函数的好坏实际上也决定了网络搭建的好坏程度,因此,我们激活函数选取较好,网络效果和准确率也就越高,反之,如果你觉得你的网络训练的不好可以从激活函数下手,也可以从后面的网络优化入手来进行调整。
3.3、经典BP网络梯度的计算和tf.GradientTape()的梯度用法
这里mooc给出了一种利用with…as结构的梯度计算方式,大家参考一下,它有点类似一种简单省略版的try…except语句,详细用法本人不在这里赘述。
3.3.1、函数的用法解释和说明:
with tf.GradientTape() as tp:
#这里面写网络的正向传播公式。
#写完网络的正向传播公式之后,写网络的损失函数loss的定义
grades=tp.gradient(loss,待求偏导的参数列表)#求出梯度
我们知道,在传统BP神经网络中,最经典的就是反向传播了,反向传播需要学习率和梯度来更新我们之前所设置的 w w w权重矩阵和 b b b偏置向量。也即给定了某个学习率 L R LR LR后,梯度更新规则为(以 w w w和 b b b举例):
w ∗ = w − L R × g r a d e s w ( g r a d e s w 为 w 的 梯 度 ) w^*=w-LR×grades_w(grades_w为w的梯度) w∗=w−LR×gradesw(gradesw为w的梯度)
b ∗ = b − L R × g r a d e s b ( g r a d e s b 为 b 的 梯 度 ) b^*=b-LR×grades_b(grades_b为b的梯度) b∗=b−LR×gradesb(gradesb为b的梯度)
在这里有些读者看完这个结构肯定会非常疑惑,不知道这是干什么的,怎么去用。但是没关系,我们先留下一个悬念,记住这个形式和反向传播的办法以及明白这个函数是求梯度的就可以了,我在后面给出完整的BP网络模型。我会为大家进行解释。
3.4、网络训练前对数据特征处理和参数选择。
下面这两个原则比较重要,大家一定要记住了,我们假设待训练的特征为N个。即需要输入到网络的特征数为N
①初始化网络的参数 α α α要满足以下正态分布:
α ~ N ( 0 , 2 N ) α~N(0,\sqrt{\frac{2}{N}}) α~N(0,N2)
②输入的特征需要中心化,服从以下正态分布:
N ( 0 , 1 ) N(0,1) N(0,1)
3.5、特征,标签合并和喂入网络的batch选取函数
tf.data.Dataset.from_tensor_slices(输入特征,输出标签).batch( 2 n 2^n 2n)
3.5.1、函数的用法解释和说明:
batch代表喂入神经网络训练的基本单位,通常为2的n次幂,n为自己给定,比如取2的5次幂32,那么就以32个为一组喂入神经网络进行训练,这个函数是将特征和标签进行整体打包并为神经网络后续函数调用做铺垫的,换而言之,这是一个合并函数。
3.6、其他重要的函数:
①enumerate枚举函数,用在for循环里面不仅可以得到元素值,而且还可以获得元素的对应位置,一举两得,不用在写繁琐的for函数了:
example9:
list1=[34,35,36]
for location,value in enumerate(list1):
print(location,value)#location返回位置,value返回对应位置的值
#结果为0 34,1 35,2 36.
变量.assign_sub(自减内容)
example10:
a=1
a.assign_sub(2)#相当于a变成了1-2=-1,这句话就是a=a-2
a.assign_sub(-2)#相当于a变成了1-(-2)=3这句话就是a=a-(-2)
numpy下的np.mgrid[起始值:结束值:步长],.ravel(),np.c_[数组1,数组2]
example11:
import numpy as np
a=np.mgrid[-3:3:1]#a=[-3 -2 -1 0 1 2]
[a,b]=np.mgrid[-3:3:1,-5:5:1]
a.ravel()#拉直a成为一列
b.ravel()#拉直b成为一列
K=np.c_[a.ravel(),b.ravel()]#换成坐标点
独热编码tf.one_hot(labels,depth=几类)用于把标签集进行独热编码形式的分类(概率分布分类)
换而言之,独热编码就是把原始数据转换成为概率分布。
example12:
label_classes=5#分成五类
Labels=tf.constant([1,0,2,3,4])
tf.one_hot(Labels,depth=label_classes)
"""输出结果:是下面五类
[[0. 1. 0. 0. 0.]
[1. 0. 0. 0. 0.]
[0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0.]
[0. 0. 0. 0. 1.]]
"""
四、最基础的神经网络TensorFlow构建
有了我们上述描述的内容和知识,我们可以开始着手搭建我们的第一个神经网络。本实例文件利用了mooc提供的dot.csv文件。以下我将分步骤进行讲解。
step1:import相关的库函数
我们需要pandas进行csv文件的读取,需要numpy对读取的数据进行预处理,需要tensorflow进行网络的构建,当然最好有图片画出来更完美了,因此我们需要这四个库进行调用。
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
step2:读取相关特征标签,并进行初设置网络内容。
以下是我用的数据集,它有两个特征x1和x2,他有一个输出y_c,因此我们选择的时候首先根据9,初始化网络参数时候他们都应该服从 N ( 0 , 1 ) N(0,1) N(0,1)正态分布,大家可以自行选择数据集进行训练或者上我给的mooc官网下载dot数据集
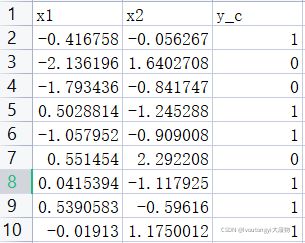
file=pd.read_csv('C:/Users/DELL/Desktop/dot.csv')#读取文件信息
x_data=np.array(file[['x1','x2']])#把file中名为这两列挑出来
y_data=np.array(file['y_c'])#把file中名为y_c的挑出来
x_train=np.vstack(x_data).reshape(-1,2)#垂直堆叠,并且转化成两列
y_train=np.vstack(y_data).reshape(-1,1)#垂直堆叠,并且转化成一列
#这里np.vstack函数代表垂直堆叠的意思
#reshape(-1,2)代表转化成两列(因为两个特征)
x_train=tf.cast(x_train,tf.float32)#转换数据类型为tf对象类型
y_train=tf.cast(y_train,tf.float32)#转换数据类型为tf对象类型
data=tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)
#32一组喂入神经网络,合并成总数据集
Ir=0.005#设置网络的学习率
epoch=3000#设置网络的训练轮数
step3:搭建网络框架
笔者这里选取了三层神经网络框架,相信看完了之前笔记部分,大家对我怎么搭建的有所了解了,看不懂的见example6。
w1=tf.Variable(tf.random.normal([2,35]),dtype=tf.float32)
b1=tf.Variable(tf.constant(0.01,shape=[35]))#1*35第一层输出
w2=tf.Variable(tf.random.normal([35,7]),dtype=tf.float32)#35*7第二层
b2=tf.Variable(tf.constant(0.01,shape=[7]))#1*7第二层输出
w3=tf.Variable(tf.random.normal([7,1]),dtype=tf.float32)#7*1第三层
b3=tf.Variable(tf.constant(0.01,shape=[1]))#1*1第三层输出
step4:正向传播和反向传播更新参数
相信大家已经记住了那个结构了吧,那么应该很容的能看懂这些都在干什么了:
for epoch in range(epoch):#训练3000轮
for i,(x_train,y_train) in enumerate(data):#进行data的迭代
with tf.GradientTape() as tape:#以下先进行正向传播
h1=tf.matmul(x_train,w1)+b1#wx+b
h1=tf.nn.relu(h1)#激活
h2=tf.matmul(h1,w2)+b2#wx+b
h2=tf.nn.relu(h2)#激活
y=tf.matmul(h2,w3)+b3#wx+b
#正向传播结束
loss=tf.reduce_mean(tf.square(y_train-y))#定义损失函数
variables=[w1,b1,w2,b2,w3,b3]#设置待求梯度的参数都有哪些
grads=tape.gradient(loss,variables)#loss对每个变量求梯度
w1.assign_sub(Ir*grads[0])#以下是参数更新过程,反向传播
b1.assign_sub(Ir*grads[1])
w2.assign_sub(Ir*grads[2])
b2.assign_sub(Ir*grads[3])
w3.assign_sub(Ir*grads[4])
b3.assign_sub(Ir*grads[5])#六个参数都更新完,结束
if(epoch%20==0):#每迭代20轮输出以下loss有多大
print(epoch,float(loss))
step5:验证网络的好坏并进行测试对比
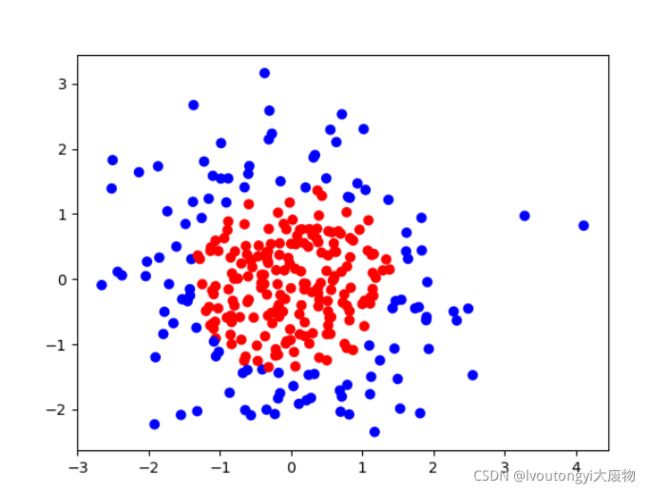
这样我们已经构建完了网络,但是不知道网络的好坏,我们首先需要画出我们的训练集散点图,这里我们要给两种颜色:
Y_c=[['red' if y else 'blue'] for y in y_train]#将0-1换成颜色列表
#如果y_train里面是1,那么赋值成'red',否则赋值成'blue'
x1=x_data[:,0]#第一个坐标
x2=x_data[:,1]#第二个坐标
plt.scatter(x1,x2,color=np.squeeze(Y_c))#画出它的图像
结果如下所示
 下面我们自己创造一些x1和x2作为测试数据来看看网络的训练效果
下面我们自己创造一些x1和x2作为测试数据来看看网络的训练效果
xx,yy=np.mgrid[-3:3:0.1,-3:3:0.1]
#设置网格点,步长是0.1,对应的为x1和x2
grid=np.c_[xx.ravel(),yy.ravel()]
#ravel是扁平化函数,将他们扁平化。
#np.c将它转化成网格坐标点,xx.ravel()为横坐标,yy.ravel()为纵坐标
grid=tf.cast(grid,tf.float32)#数据转换,便于进行计算
probs=[]#存储输出的y
for x_test in grid:#代入到训练好的网络中去
h1=tf.matmul([x_test],w1)+b1
h1=tf.nn.relu(h1)
h2=tf.matmul(h1,w2)+b2
h2=tf.nn.relu(h2)
y=tf.matmul(h2,w3)+b3
probs.append(y)#加入到数组中
probs=np.array(probs).reshape(xx.shape)#转化成和xx形状一样,便于画图
plt.contour(xx,yy,probs,levels=[0.5])
plt.scatter(x1,x2,color=np.squeeze(Y_c))#画出它的图像
plt.show()
以下是效果图:
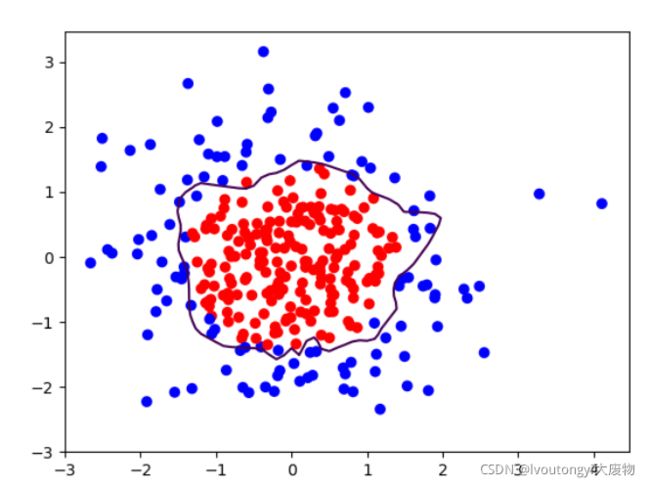
很明显的看出来了,这里面存在了过拟合现象!也就是这个曲线不平稳,这也就是我们现在要说的模型优化问题了。
这样我们将上面的代码合并起来,就得到了完整的网络结构和源代码,如下所示:
example13:
import tensorflow as tf
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
file=pd.read_csv('C:/Users/DELL/Desktop/dot.csv')#读取文件信息存储成csv文件
x_data=np.array(file[['x1','x2']])#把file中名为这两列挑出来
y_data=np.array(file['y_c'])#把file中名为y_c的挑出来
x_train=np.vstack(x_data).reshape(-1,2)#转化成两列合并
y_train=np.vstack(y_data).reshape(-1,1)#转化成一列合并
Y_c=[['red' if y else 'blue'] for y in y_train]#将0-1换成颜色列表
x_train=tf.cast(x_train,tf.float32)#转换数据类型
y_train=tf.cast(y_train,tf.float32)#转换数据类型
data=tf.data.Dataset.from_tensor_slices((x_train,y_train)).batch(32)#32一组喂入神经网络,合并成总数据集
w1=tf.Variable(tf.random.normal([2,35]),dtype=tf.float32)
b1=tf.Variable(tf.constant(0.01,shape=[35]))#2*35第一层输出
w2=tf.Variable(tf.random.normal([35,7]),dtype=tf.float32)#35*36第二层
b2=tf.Variable(tf.constant(0.01,shape=[7]))#2*36第二层输出
w3=tf.Variable(tf.random.normal([7,1]),dtype=tf.float32)#36*1第三层
b3=tf.Variable(tf.constant(0.01,shape=[1]))
Ir=0.005#学习率
epoch=2000#训练轮数
for epoch in range(epoch):
for i,(x_train,y_train) in enumerate(data):
with tf.GradientTape() as tape:
h1=tf.matmul(x_train,w1)+b1
h1=tf.nn.relu(h1)
h2=tf.matmul(h1,w2)+b2
h2=tf.nn.relu(h2)
y=tf.matmul(h2,w3)+b3
"""
loss_regular=[]#加入网络正则化L2正则化
loss_regular.append(tf.nn.l2_loss(w1))
loss_regular.append(tf.nn.l2_loss(w2))
loss_regular.append(tf.nn.l2_loss(w3))
sum_loss=tf.reduce_sum(loss_regular)
+0.03*sum_loss#计算误差(正则化后把它加在loss后面去)
"""
loss=tf.reduce_mean(tf.square(y_train-y))
variables=[w1,b1,w2,b2,w3,b3]
grads=tape.gradient(loss,variables)
w1.assign_sub(Ir*grads[0])
b1.assign_sub(Ir*grads[1])
w2.assign_sub(Ir*grads[2])
b2.assign_sub(Ir*grads[3])
w3.assign_sub(Ir*grads[4])
b3.assign_sub(Ir*grads[5])
if(epoch%20==0):
print(epoch,float(loss))
xx,yy=np.mgrid[-3:3:0.1,-3:3:0.1];
print(xx,yy)
grid=np.c_[xx.ravel(),yy.ravel()]
grid=tf.cast(grid,tf.float32)
probs=[]
for x_test in grid:
h1=tf.matmul([x_test],w1)+b1
h1=tf.nn.relu(h1)
h2=tf.matmul(h1,w2)+b2
h2=tf.nn.relu(h2)
y=tf.matmul(h2,w3)+b3
probs.append(y)
x1=x_data[:,0]
x2=x_data[:,1]
probs=np.array(probs).reshape(xx.shape)
plt.scatter(x1,x2,color=np.squeeze(Y_c))
plt.contour(xx,yy,probs,levels=[0.5])
plt.show()
中间绿色注释掉的暂时不要看,在接下来的正则化部分中介绍它的作用。
五、网络动态学习率&网络正则化
通过上面我们发现了,网络存在着明显的过拟合现象,也就是虽然误差比较小,但是网络并不满足我们的要求,因此我们现在需要对网络进行优化,以下是笔者总结的比较重要的网络优化方法,便于大家对自己的网络进行改进
5.1、网络优化方法一:动态学习率
我们都知道,之前的学习率 L R LR LR是给定的,那么这个给定的数值会影响网络的效果,我们不能把学习率给的太大,同时又不能给的太小,如果太大,则很容易越过梯度为0的点,如果太小,则收敛太慢甚至需要轮数太大,因此,我们可以采用动态学习率来进行改进这一缺点,定义动态学习率如下:
L R m = L R ∗ β 当 前 轮 数 多 少 轮 衰 减 一 次 ( β 为 给 定 的 学 习 率 衰 减 率 ) LR_m=LR*β^{\frac{当前轮数}{多少轮衰减一次}}(β为给定的学习率衰减率) LRm=LR∗β多少轮衰减一次当前轮数(β为给定的学习率衰减率)
比如我们定义如下,我们定义 β β β为0.8,设置初始学习率为0.9,定义2轮训练学习率就衰减一次,则第 K K K轮的学习率为:
L R m = 0.9 × 0. 8 K 2 LR_m=0.9×0.8^{\frac{K}{2}} LRm=0.9×0.82K
这样学习率会随着轮数的增加,越来越小,这就是动态学习率的意义,在程序中,将 L R LR LR随着动态改变
5.2、网络优化方法二:正则化操作
针对网络的过拟合,往往可以采用增加正则化参数,提高网络数据集样本数量,采用网络正则化的办法来缓解过拟合问题,下面介绍两种正则化办法,相关两种正则化的原理和理论请参考其他博客,这里直接介绍。
我们一般正则化网络中的 w w w,而很少正则化网络中的 b b b
正则化即更改原来的损失函数,增加正则化损失即可。
5.2.1、L1正则化
l o s s ( w ) = ∑ j ∣ w j ∣ loss(w)={\sum_{j}|w_j|} loss(w)=j∑∣wj∣
5.2.2、L2正则化
l o s s ( w ) = ∑ j ∣ w j 2 ∣ loss(w)={\sum_{j}|w_j^{2}|} loss(w)=j∑∣wj2∣
更改后的 l o s s ∗ loss^* loss∗为:
l o s s ∗ = l o s s + γ l o s s ( w ) 。 loss^*=loss+γloss(w)。 loss∗=loss+γloss(w)。
其中 γ γ γ为正则化权重,自行给定。
下面我们在example13的基础上增加网络的正则化代码,即加入这几行代码就可以了,就是注释的部分(笔者采用L2正则化操作)
loss_regular=[]#加入网络正则化L2正则化
loss_regular.append(tf.nn.l2_loss(w1))#w1的l2正则化
loss_regular.append(tf.nn.l2_loss(w2))#w2的l2正则化
loss_regular.append(tf.nn.l2_loss(w3))#w3的l2正则化
sum_loss=tf.reduce_sum(loss_regular)#计算总的正则化loss
loss=tf.reduce_mean(tf.square(y_train-y))+0.03*sum_loss
#正则化权重0.03
再加入网络的动态学习率变化:
Irbase=0.01#基础学习率
Ir=Irbase*(0.99**(epoch/1))#一轮迭代一次
但是改进的动态学习率不宜过高,因为轮数过大,会使得后者趋于0,那么这个时候学习率就是0了!那就不会再有参数更新的过程了,因此不宜取过大的epoch轮数。
下图是加入网络的正则化后,网络的训练效果,可以明显地看到,过拟合有一定的缓解了,曲线变得平缓了,正则化得到了缓解,如下图所示,大家可以自己试一下
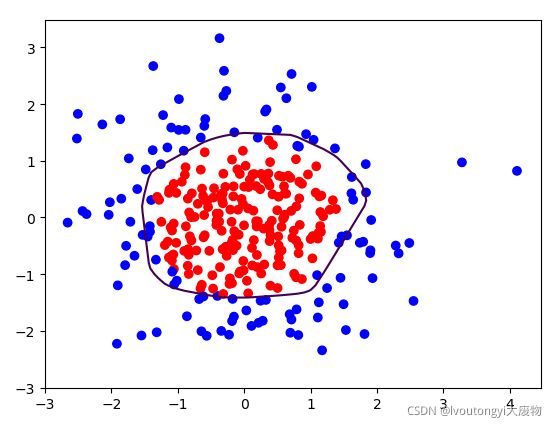
笔者这里和北京大学mooc代码有所不同,笔者自己架构的三层神经网络,大家可以按照mooc一样架构一层即可。
六、网络动量优化
我们知道,以上我们使用的是BP神经网络,用的是传统的梯度下降办法,接下来介绍几种可以代替梯度下降法的几种网络优化算法,大家可以应用在自己的模型中
先介绍几个概念:
6.1、一阶动量和二阶动量:
m t = f ( ▽ ) m_t=f(▽) mt=f(▽),二阶动量 v t = f ( ▽ 2 ) v_t=f(▽^2) vt=f(▽2)分别代表它们是梯度相关的函数和梯度平方相关的函数
6.2、网络参数更新过程
假设我们待更新参数为 θ \theta θ,则更新规则为:
θ ∗ = θ − L R m t v t \theta^*=\theta-LR\frac{m_t}{\sqrt{v_t}} θ∗=θ−LRvtmt
6.3、网络优化器
下面介绍几种网络优化器:
SGD优化: m t = g r a d e t ( 梯 度 ) m_t=grade_t(梯度) mt=gradet(梯度), v t = 1 v_t=1 vt=1。
这个时候就是传统的梯度下降法了。
②SGDM优化:
m t = β m t − 1 + ( 1 − β ) g r a d e t m_t=βm_{t-1}+(1-β)grade_t mt=βmt−1+(1−β)gradet, v t = 1 v_t=1 vt=1,初始化 m 0 = 0 , β m_0=0,β m0=0,β为超参数经验值一般为0.9。
③Adagrad优化(自适应学习率优化):
m t = g r a d e t m_t=grade_t mt=gradet, v t = ∑ j = 1 t g r a d e j 2 v_t=\sum_{j=1}^t grade_j^2 vt=∑j=1tgradej2
④RMSProp优化:
m t = g r a d e t m_t=grade_t mt=gradet, v t = β v t − 1 + ( 1 − β ) g r a d e t 2 , v_t=βv_{t-1}+(1-β)grade_t^2, vt=βvt−1+(1−β)gradet2,初始化 v 0 = 0 , β v_0=0,β v0=0,β为超参数经验值一般为0.9。
⑤Adam优化:
m t = α m t − 1 + ( 1 − α ) g r a d e t m_t=αm_{t-1}+(1-α)grade_t mt=αmt−1+(1−α)gradet, v t = β v t − 1 + ( 1 − β ) g r a d e t 2 v_t=βv_{t-1}+(1-β)grade_t^2 vt=βvt−1+(1−β)gradet2
初始化 v 0 = 0 , m 0 = 0 , α , β v_0=0,m_0=0,α,β v0=0,m0=0,α,β为超参数,初始自己给定。
并且以此推出更新的修正式 m ^ t \hat m_t m^t和 v ^ t \hat v_t v^t
m ^ t = m t 1 − α t \hat m_t=\frac{m_t}{1-α^t} m^t=1−αtmt
v ^ t = v t 1 − β t \hat v_t=\frac{v_t}{1-β^t} v^t=1−βtvt
用 m ^ t \hat m_t m^t和 v ^ t \hat v_t v^t代替 m t m_t mt和 v t v_t vt代入公式求出修正后的参数更新公式。
example14:以example13为例子的优化器。
#SGD优化器:
m_texample11=grads[0],m_texample12=grads[1],m_texample13=grads[2]
m_texample14=grads[3],m_texample15=grads[4],m_texample16=grads[5]
v_texample1=1;
w1.assign_sub(Ir*m_texample11/sqrt(v_texample1))
b1.assign_sub(Ir*m_texample12/sqrt(v_texample1))
w2.assign_sub(Ir*m_texample13/sqrt(v_texample1))
b2.assign_sub(Ir*m_texample14/sqrt(v_texample1))
w3.assign_sub(Ir*m_texample15/sqrt(v_texample1))
b3.assign_sub(Ir*m_texample16/sqrt(v_texample1))
#SGDM优化器
m_texample21=0,m_texample22=0,m_texample23=0
m_texample24=0,m_texample25=0,m_texample26=0
beta=0.9,v_texample2=1#初始化
m_texample21=beta*m_texample21+(1-beta)*grads[0]
m_texample22=beta*m_texample22+(1-beta)*grads[1]
m_texample23=beta*m_texample23+(1-beta)*grads[2]
m_texample24=beta*m_texample24+(1-beta)*grads[3]
m_texample25=beta*m_texample25+(1-beta)*grads[4]
m_texample26=beta*m_texample26+(1-beta)*grads[5]
w1.assign_sub(Ir*m_texample21/sqrt(v_texample2))
b1.assign_sub(Ir*m_texample22/sqrt(v_texample2))
w2.assign_sub(Ir*m_texample23/sqrt(v_texample2))
b2.assign_sub(Ir*m_texample24/sqrt(v_texample2))
w3.assign_sub(Ir*m_texample25/sqrt(v_texample2))
b3.assign_sub(Ir*m_texample26/sqrt(v_texample2))
#其余的优化器类似,笔者这里不一一书写了,请仿照我给的公式进行自己编程。
七、keras网络搭建和构造
上述的代码不由得非常的繁琐,写起来非常的长,因此下面笔者将介绍利用python的keras来进行网络的搭建。
keras搭建网络只需要上述我们的神经网络只需要以下几个步骤就可以达到效果了
7.1、六步法搭建神经网络
①import相关库文件。②定义训练集和测试集及其各自的特征和标签
③网络结构搭建④网络方法,损失和优化设置⑤网络训练⑥网络总结
接下来逐一为大家介绍和讲解:
7.1.1、import相关库文件
这个比较传统,比如import numpy as np,import tensorflow as tf,如果你需要画图,增加一个from matplotlib import pyplot as plt等等啊,这些都是按照个人需求进行import的。
7.1.2、定义训练集和测试集及其各自的特征和标签
就是将你的训练数据和特征数据分开来,并存储起来,注意一定要将训练数据随机打乱,而且保证你的标签和你训练数据对应着一起被相应的去打乱,想做到这样的话我们需要进行下面两个函数的调用,假设我们有了训练集的特征和标签分别是x_train和y_train,如何随机打乱这些数据呢?
example15:
np.random.seed(195)#设定初始随机种子这样产生的随机数是一样的
np.random.shuffle(x_train)#随机打乱数据x,shuffle函数是打乱用的函数
np.random.seed(195)#设定一样的随机种子,这样产生的随机数是一样的
np.random.shuffle(y_train)#随机打乱数据y,shuffle函数是打乱用的函数
7.1.3、搭建网络函数model=tf.keras.models.Sequential([网络结构])
这里先介绍全连接层和拉直层的网络结构,卷积CNN和LSTM的keras结构在之后的内容中进行介绍。
Ⅰ、拉直层网络介绍tf.keras.layers.Flatten()
这个函数将数据拉直成为一个向量,便于喂入神经网络进行训练。
Ⅱ、全连接层网络结构如下:tf.keras,layers.Dense(当前层神经元个数,activation=‘激活函数’,kernel_regularizer=‘哪种正则化’)
常用的激活函数如下所示
| activation | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 类型 | ′ s o f t m a x ′ 'softmax' ′softmax′ | ′ r e l u ′ 'relu' ′relu′ | ′ t a n h ′ 'tanh' ′tanh′ | ′ s i g m o i d ′ 'sigmoid' ′sigmoid′ | ⋅ ⋅ ⋅ ··· ⋅⋅⋅ |
常用的两种正则化如下所示
| kernel_regularizer | 1 | 2 |
|---|---|---|
| 类型 | t f . k e r a s . r e g u l a r i z e r s . l 2 ( ) tf.keras.regularizers.l2() tf.keras.regularizers.l2() | t f . k e r a s . r e g u l a r i z e r s . l 1 ( ) tf.keras.regularizers.l1() tf.keras.regularizers.l1() |
下面我给各位举个例子就知道了这个函数的用法了,其实很简单的。
example16:
model=tf.keras.models.Sequential([
tf.keras.layers.Dense(3,activation='softmax',kernel_regularizer=tf.keras.regularizers.l2())
])#网络架构,当前层三个神经元,softmax激活,l2正则化。
7.1.4、构建网络方法model.compile()
方法如下:model.compile(optimizer=优化器,loss=损失,metrics=[准确度测评指标])
Ⅰ、常用的优化器如下所示:
Ⅰ、tf.keras.optimizers.SGD(learning_rate=学习率,momentum=动量参数)
Ⅱ、tf.keras.optimizers.Adagrad(learning_rate=学习率)
Ⅲ、tf.keras.optimizers.Adadelta(learning_rate=学习率)
Ⅳ、tf.keras.optimizers.Adam(learning_rate=学习率,beta_1=第一个参数值,beta_2=第二个参数值)
或者采用单引号的形式来表示这些优化器,比如:
‘adam’,‘sgd’,‘adagrad’,'adadelta’等等。
Ⅱ、常用的损失如下所示:
Ⅰ、tf.keras.losses.MeanSquaredError()平方损失误差
Ⅱ、tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False)
交叉熵损失误差
Ⅲ、参数说明:
from_logits代表网络输出是以概率分布输出还是不是,如果以概率分布输出,那这个值是False,如果输出是原值,那么这个值是True
Ⅳ、准确度测评指标
Ⅰ、'accuracy’当神经网络输出的y值和需要预测的y值都是数值使用这个指标
Ⅱ、'categorical_accuracy’当两者都是独热编码(概率分布)时候使用这个指标)
Ⅲ、'sparse_categorical_accuracy’当两者一个是独热编码(概率分布)一个是数值使用这个指标
独热编码是什么,以及优化器上方笔者已经介绍过了。
下面就来举一个例子说明这个函数是如何用的:
example17:
model.compile(optimizer=tf.keras.optimizers.SGD(learning_rate=0.1),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy']
)
#选择SGD优化器,学习率为0.1。
#使用交叉熵损失函数,按照概率输出
#因为我们网络输出和真实输出一个是概率输出一个是数值所以用第三个指标。
7.1.5、网络方法model.fit()
他的详细用法如下
网络方法model.fit(训练集特征,训练集标签,batch_size=每次喂入神经网络的组数,epochs=网络轮数,validation_data=(测试集的输入特征,测试集的输入标签),validation_split=从训练集中取出百分之多少给测试集,validation_freq=多少个epoch测试一次)
example18:
model.fit(x_train,y_train,batch_size=32,epochs=500,validation_split=0.2,validation_freq=20)#设置训练集和测试集数据
#batch_size=32,32为一组喂入神经网络
#epochs为500轮,循环迭代500轮
#validation_split=0.2,从训练集中拿出20%作为测试集
#validation_freq=20代表20轮进行一次测试
7.1.6、网络总结model.summary()
这个比较简单,直接打印出网络的训练参数情况和可训练和不可训练参数情况,直接代码打出model.summary()就可以了。
八、MINIST&FASHION数据集实训
下面我们以MNIST手写数据集为测试来验证我们之前学过的网络,大家顺便复习和熟悉之前学习的内容,每一行我都进行了注释和标记。
8.1、example19(MNIST):
import tensorflow as tf
mnist=tf.keras.datasets.mnist
(xtrain,ytrain),(xtest,ytest)=mnist.load_data()#读取mnist数据集数据,是灰度值,我们将它归一化处理
xtrain=xtrain/255#数据归一化
xtest=xtest/255#数据归一化
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(120,activation='relu'),#使用relu激活
tf.keras.layers.Dense(10,activation='sigmoid'),#使用sigmoid激活
tf.keras.layers.Dense(10,activation='softmax')#使用softmax激活
#第三层网络使输出服从概率分布三层架构
])#网络架构
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
model.fit(xtrain,ytrain,batch_size=32,epochs=15,validation_data=(xtest,ytest),validation_freq=1)#设置训练集和测试集数据
model.summary()
我这里得到的训练集准确率0.9959,测试集准确率为0.9773
提醒大家,不是万不得已或者过拟合不要加正则化参数,否则容易欠拟合,效果很差,消除过拟合或者梯度消失时候网络正则化才起到作用,正则化并不是万能的,只是改进网络的一种办法。比如在这里你如果加入正则化参数,那测试集准确率就比较低了,大概只有0.92左右。
8.2、example20(FASHION):
读者可以自行练习,完全仿照上面即可
fashion=tf.keras.datasets.fashion_mnist
(xtrain,ytrain),(xtest,ytest)=fashion.load_data()#读取mnist数据集数据,是灰度值,我们将它归一化处理
xtrain=xtrain/255#数据归一化
xtest=xtest/255#数据归一化
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(160,activation='relu'),
tf.keras.layers.Dense(35,activation='relu'),
tf.keras.layers.Dense(36,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
#第四层网络使输出服从概率分布四层架构
])#网络架构
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
model.fit(xtrain,ytrain,batch_size=32,epochs=50,validation_data=(xtest,ytest),validation_freq=1)#设置训练集和测试集数据
model.summary()
训练集准确率大约在0.9573,测试集准确率大约在0.8899。
九、class定义神经网络model
注意到用Sequential搭建的网络存在一个相当大的弊端,因为我们知道Sequential上一层的输出是作为下一层的输入的,但是很多情况下,我可能不想要这一层的输出作为输入,而是做一些其他的变换,那这样Sequential搭建的网络就实现起来非常困难了,这也就是自定义网络的办法,下面用类来进行网络的定义,这样为以后的网络自定义提供了方便。
我们以fashion数据集代码为例,model的class写法如下程序代码所示:
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras import Model
import tensorflow as tf
class new_Model(Model):#Model继承了Tensorflow的Model类
def __init__(self):
super(new_Model,self).__init__()#new_Model是类名,这句话统一
#从这里开始定义你的网络结构块
self.flatten=Flatten()#拉直成为向量
self.d1=Dense(160,activation='relu')#第一层
self.d2=Dense(35,activation='relu')#第二层
self.d3=Dense(36,activation='relu')#第三层
self.d4=Dense(10,activation='softmax')#第四层输出
def call(self,x):
x=self.flatten(x)#调用网络结构块实现向前传播
x=self.d1(x)
x=self.d2(x)
x=self.d3(x)
y=self.d4(x)#向前传播结束
return y
model=new_Model()#产生model
#上述代码可以代替以下定义的Sequential内容:
"""
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(160,activation='relu'),
tf.keras.layers.Dense(35,activation='relu'),
tf.keras.layers.Dense(36,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
#第四层网络使输出服从概率分布四层架构
])#网络架构
"""
十、数据增强&参数提取
10.1、数据增强
数据增强函数如下所示:
tf.keras.preprocessing.image.ImageDataGenerator()
用于数据不够用,数据增强可以加强网络的泛化能力,增加网络的应用性,而不是单一的只针对某个问题的网络,这里介绍对图像的数据增强,对图像的数据增强就是对图片进行简单的形变。
下面介绍它的具体用法如下代码所示:
img_gen_train=tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1/255,#图像中所有的数据点都乘以这个rescale
#这里相当于归一化255操作了
rotation_range=45,#图像随机旋转角度范围大小,这里是45°
width_shift_range=0.15,#随机宽度偏移量的大小,这里是15
height_shift_range=0.15,#随机高度偏移量的大小,这里是15
horizontal_flip=False,#是否进行水平反转,是则True,否则False
zoom_range=0.5#图像随机缩放阈,这里是0.5
)
xtrain=xtrain.reshape(x_train.shape[0],28,28,1)
img_gen_train.fit(xtrain)#img_gen_train.fit函数输入一定是一个四维度数组
这里解释一下上面的操作,为什么要将x_train进行reshape呢,这是因为,我们下方的函数输入需要是一个四维数组,而图像我们知道是三维的,比如之前我们的数据集就是60000×28×28的,现在要把它变成单通道的,最后加一个1就可以了。
下面把增强后的数据添加到模型中去就可以了
model.fit(img_gen_train.flow(xtrain,ytrain,batch_size=32),epochs=50,validation_data=(xtest,ytest),validation_freq=1)#设置训练集和测试集数据
"""替换后面这一行
model.fit(xtrain,ytrain,batch_size=32,epochs=50,validation_data=(xtest,ytest),validation_freq=1)#设置训练集和测试集数据
"""
下面我们更改之前example20(FASHION)的代码,将它数据增强。
example21(数据增强):
import tensorflow as tf
from tensorflow.keras.preprocessing.image import ImageDataGenerator
fashion=tf.keras.datasets.fashion_mnist
(xtrain,ytrain),(xtest,ytest)=fashion.load_data()#读取mnist数据集数据,是灰度值,我们将它归一化处理
xtrain=xtrain/255#数据归一化
xtest=xtest/255#数据归一化
xtrain=xtrain.reshape(xtrain.shape[0],28,28,1)
img_gen_train=tf.keras.preprocessing.image.ImageDataGenerator(
rescale=1./1.,#不变动大小
rotation_range=45,#图像随机旋转角度范围大小,这里是45°
width_shift_range=0.15,#随机宽度偏移量的大小,这里是15
height_shift_range=0.15,#随机高度偏移量的大小,这里是15
horizontal_flip=True,#是否进行水平反转,是则True,否则False
zoom_range=0.5#图像随机缩放阈,这里是0.5
)
img_gen_train.fit(xtrain)#img_gen_train.fit函数输入一定是一个四维度数组
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(160,activation='relu'),
tf.keras.layers.Dense(35,activation='relu'),
tf.keras.layers.Dense(36,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
#第四层网络使输出服从概率分布四层架构
])#网络架构
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
model.fit(img_gen_train.flow(xtrain,ytrain,batch_size=32),epochs=5,validation_data=(xtest,ytest),validation_freq=1)#设置训练集和测试集数据
model.summary()
10.2、参数提取
参数提取函数如下:
model.trainable_variables
从表面理解就能够看出该函数的用途了,提取的是可训练的参数出来。
首先介绍控制print输出格式的函数:
10.2.1、np控制输出print
①np.set_printoptions(threshold=np.inf)(threshold=多少代表超过多少省略显示)
然后直接进行下一步就可以了~,应该猜到如何进行参数提取了吧。
np.set_printoptions(threshold=np.inf)#设置成无穷大,不省略
print(model.trainable_variables)#输出网络参数
#也可以存储在文本文件file中。这里不具体操作,可以查阅python写文件办法。
十一、网络预测&断点续训
我们训练好了一个网络,如何进行网络参数的保留,以便于我们日后利用模型时候可以直接进行参数的存储,同样的,我们的模型如何进行应用?比如手写数据集,我们如何让我们自己的手写图片给予网络让网络训练出一个结果反馈给我们?这就是接下来笔者要为大家介绍的内容了,先介绍存储网络参数和读取网络参数的办法——断点续训,本例子里面以mnist数据集作为例子进行操作。
11.1、断点续训-保存文件
分成两步
①step1:
cp_callback=tf.keras.callbacks.ModelCheckpoint(filepath=要存储的文件路径,save_weights_only=True/False,save_best_only=True/False)
②step2:
history=model.fit(callbacks=[cp_callback])
example22(断点续训-保存文件):
lotypath="./lotydata/mnist.ckpt"#设置要存储mnist网络参数的文件路径。
cp_callback=tf.keras.callbacks.ModelCheckpoint(filepath=lotypath,save_weights_only=True,save_best_only=True)
#save_weights_only为是否只保留模型参数
#save_best_only为是否只保留最优结果
history=model.fit(xtrain,ytrain,batch_size=32,epochs=15,validation_data=(xtest,ytest),validation_freq=1,callbacks=[cp_callback])#设置训练集和测试集数据
#加入了callbacks=[cp_callback]这一选项
11.2、断点续训-读取文件
load_weights(路径文件名称)
example23(断点续训-读取文件):
import os
lotypath="./lotydata/mnist.ckpt"#设置mnist的文件路径。
if os.path.exists(lotypath+'.index'):#如果路径文件存在着索引表
model.load_weights(path)#读取网络参数
#在此之前需要先构建好model模型,然后再读取参数~
example24(断点续训完整版本):
import tensorflow as tf
import os
mnist=tf.keras.datasets.mnist
(xtrain,ytrain),(xtest,ytest)=mnist.load_data()#读取mnist数据集数据,是灰度值,我们将它归一化处理
xtrain=xtrain/255#数据归一化
xtest=xtest/255#数据归一化
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(120,activation='relu'),#使用relu激活
tf.keras.layers.Dense(10,activation='sigmoid'),#使用sigmoid激活
tf.keras.layers.Dense(10,activation='softmax')#使用softmax激活
#第三层网络使输出服从概率分布三层架构
])#网络架构
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
lotypath='C:/Users/DELL/Desktop/lotydata/mnist.ckpt'
#设置mnist的文件路径。"
if os.path.exists(lotypath+'.index'):#如果路径文件存在着索引表
model.load_weights(lotypath)#读取网络参数
#在此之前需要先构建好model模型,然后再读取参数~
cp_callback=tf.keras.callbacks.ModelCheckpoint(filepath=lotypath,
save_weights_only=True,
save_best_only=True)
#save_weights_only为是否只保留模型参数
#save_best_only为是否只保留最优结果
history=model.fit(xtrain,
ytrain,
batch_size=32,
epochs=15,
validation_data=(xtest,ytest),
validation_freq=1,
callbacks=[cp_callback])#设置训练集和测试集数据
#加入了callbacks=[cp_callback]这一选项
model.summary()
上述操作实现了将网络参数写入文件,并且运行一次的时候开始进行写入,第二次运行时候就是以之前网络的模型继续进行训练了!这可以非常有效的存储我想要的模型及其参数!所以断点续训这个办法大家一定要掌握!
11.3、网络预测predict()函数
下面以我写的一些图片为例子,考虑一下如何实现我们之前实现的网络的预测,因为我们的目的是可以网络智能的识别生活中的物体,下面是我使用的手写图片测试如下所示:
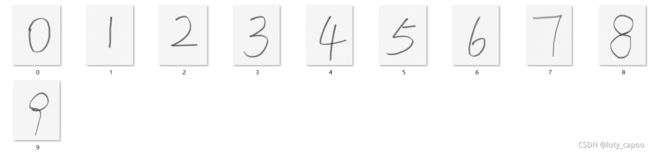
部分预测结果如下,这十个数的网络准确率应该是100%的。
下面利用我们之前断点续训的结果进行网络预测:
example25(网络预测):
from PIL import Image
import numpy as np
import tensorflow as tf#引入相关的库文件
import matplotlib.pyplot as plt
lotypath='C:/Users/DELL/Desktop/lotydata/mnist.ckpt'#设置mnist的文件路径。
model=tf.keras.models.Sequential([
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(120,activation='relu'),#使用relu激活
tf.keras.layers.Dense(10,activation='sigmoid'),#使用sigmoid激活
tf.keras.layers.Dense(10,activation='softmax')#使用softmax激活
#第三层网络使输出服从概率分布三层架构
])#定义网络的架构
model.load_weights(lotypath)#导入断点续训的网络参数数据
sum_number=int(input("请输入您要预测多少张图片"))
#下面进行循环
for range1 in range(sum_number):
imagepath=input("请输入您想要预测的图片")
#输入我想预测的图片
img=Image.open(imagepath)#打开这张图片
img=img.resize((28,28),Image.ANTIALIAS)
# 更改图片的大小为28*28的,因为MNIST是28*28的
img_array=np.array(img.convert('L'))
#将图片转换为灰度图
for i in range(28):
for j in range(28):
if(img_array[i][j]<200):
img_array[i][j]=255
# 如果灰度值小于200把它变成灰度值255为纯白色
else:
img_array[i][j]=0
img_array=img_array/255#归一化操作
xpredict=img_array[tf.newaxis,...]
#维度拓展,因为按照batch送入网络。是这种格式输入。
result=model.predict(xpredict)
pd=tf.argmax(result,axis=1)#找到那个最大的分类
tf.print(pd)#输出它的类别
以上便是所有的全连接神经网络的优化方法和一些详细操作和具体的实现步骤,相信大家看完可以自己构建任何层数的神经网络以及它的优化办法了。下面笔者将介绍其他两种经典的神经网络:卷积神经网络和循环神经网络。
十二、卷积神经网络(CBAPD)
先说一下为什么要有卷积神经网络,也是我自己的一些理解。
通过上面的介绍,大家会发现全连接神经网络是很香的,直接可以解决所有的问题,那对于彩色RGB图片,为什么不采用全连接直接进行网络训练呢?这是因为RGB有三个通道,这样而言所需训练参数过大,训练参数过大很容易导致一个后果就是模型的过拟合,也就是训练集你虽然能够准确率达到超高,但是测试集却低的恐怖,模型的泛化能力很弱,因此我们要采取卷积提取特征等办法让特征去进行全连接,这样大大减少了模型的网络参数,因此才会诞生卷积神经网络。
12.1、感受野
定义:原始图像经过卷积得到的卷积输出每一个小方块对应原始图像中n×n的特征方块,n称为感受野。
感受野反应卷积核提取特征的能力
比如一个5×5的原始图像,用一个3×3的卷积核去卷积得到一个3×3的卷积输出,这个3×3的输出每一个小块代表原始特征的3×3,因此这里的感受野是3。如果我们继续用3×3的卷积去二次卷积这个输出,会得到一个1×1的卷积输出,那么一个1×1的代表原始图像中的5×5特征,因此感受野就是5。
但是我们直接用5×5的卷积核直接进行卷积呢?那么显然直接得到了一个1×1的特征,那么这个时候感受野还是5,也就是说,一个5×5的卷积核和两个3×3的卷积核居然效果一样,那么,哪个更好一些呢?
这里用老师的图更好一些理解:
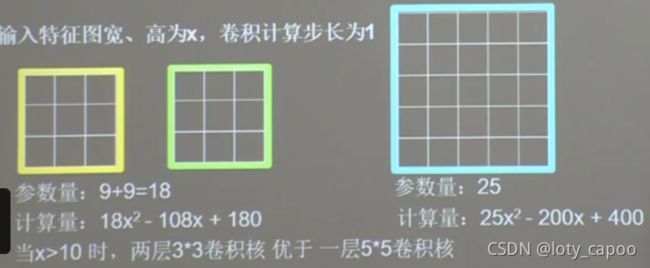
相比较而言这也就是为什么更喜欢用两个3×3代替一个5×5的原因了,因为参数计算量更少,但是他们特征提取的能力却一样!
12.2、零填充
零填充控制函数如下:
padding=‘SAME’/padding=‘VALID’(使用全零填充/不使用全零填充)
通过上述例子,我们发现卷积使得图的尺寸变小了,如果想要图的尺寸保持不变,那么就需要对我们原始的图周围“扩大”一圈,扩大这一圈用零来填充,因此全零填充目的是保证卷积图像大小不变,填充公式比较简单,这里就不过多的介绍了,请大家自行查阅一下。
12.3、Tensorflow卷积函数tf.keras.layers.Conv2D()
卷积函数用法如下:
tf.keras.layers.Conv2D(filters=卷积核个数,kernel_size=卷积核大小(正方形卷积核直接写)长方形要写(核高,核宽),strides=卷积核滑动步长大小,横纵向滑动相同写一个值即可,不同需要这样写(纵向滑动步长,横向滑动步长),padding=‘same’/padding=‘valid’,activation=激活方法,input_shape=(输入的高,输入的宽,输入的通道channel数))
这里先大致了解这个函数的作用,构建模型还需要它与接下来的批次标准化BN层&池化层&舍弃层合并才能构造,因此实例在后面。
12.4、批次标准化BN层&池化层&舍弃层
Ⅰ、批次标准化:
因为神经网络对0附近的数据更加的敏感,但是随着网络层数的增加,数据会偏离0点,因此需要对数据进行一定的标准化处理,批次标准化就是对一批数据进行标准化,批次标准化操作常用于卷积和激活之间来进行,使得进入激活函数的数据分布在0附近。
但是这样会一定程度丧失网络的非线性表达力,因为数据呈一种近似正态分布的趋势,因此增加了缩放因子和偏移因子,感兴趣的读者可以查阅他们是如何增加线性表达力的。
其实很简单,tensorflow有专门的函数来处理这件事:
tf.keras.layers.BatchNormalization()这句话加入到卷积层和激活函数之间就可以啦。
Ⅱ、池化:
池化用于减少图片的特征数量,maxpooling用于提取图片的纹理特征,meanpooling用于提取图片的背景特征,具体操作如下例子所示:

下面是两种池化函数:
max池化操作函数:tf.keras.layers.MaxPool2D(pool_size=池化层大小,如果不是方形池化参考卷积核写法就可以,strides=池化步长,也参考卷积核写法,padding=‘same’/padding=‘valid’)
mean池化操作函数:tf.keras.layers.MaxPool2D(pool_size=池化层大小,如果不是方形池化参考卷积核写法就可以,strides=池化步长,也参考卷积核写法,padding=‘same’/padding=‘valid’)
Ⅲ、舍弃:
舍弃用于缓解网络的过拟合,改进网络效果,经常将隐藏层的一些参数从模型中舍弃掉以此来进行缓解,也就是改变连接形式,某些神经元以一定概率不进行工作。这个操作在Tensorflow里面也十分简单,利用起来也十分简单,舍弃函数如下:
tf.keras.layers.Dropout(舍弃概率多大)
这样我们就完成了卷积的所有操作,这样提取的特征进入全连接就可以进行训练了,我们将之前的内容进行一下总结,例子如下:
example26(卷积网络model)(CBAPD原则):
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6,
kernel_size=(5,5,),
strides=1,
padding='same'),
#6个5*5卷积核,步长1,使用全零填充(C)
tf.keras.layers.BatchNormalization(),
#BN函数批次归一化(B)
tf.keras.layers.Activation('relu'),
#relu激活(A)
tf.keras.layers.MaxPool2D(pool_size=(2,2),
strides=2,
padding='same',
),
#max池化层(P)
tf.keras.layers.Dropout(0.2)
#舍弃层,概率为20%(D)
#CBAPD五步
])#网络架构
十三、卷积神经网络在cifar10上的应用
下面我们根据cifar10数据集对卷积网络进行应用和实现,感兴趣的读者可以自行增加数据增强,尝试其他网络优化办法。
example27(cifar10数据集两层卷积两层池化,两层全连接):
import tensorflow as tf
import os
data=tf.keras.datasets.cifar10#导入数据
(xtrain,ytrain),(xtest,ytest)=data.load_data()
lotypath='C:/Users/DELL/Desktop/lotydata/cifar.ckpt'#设置mnist的文件路径。
xtrain=xtrain/255#数据归一化
xtest=xtest/255#数据归一化
#读取cifar10数据集数据,每一张是32×32的RGB彩色图片。
#0-9标签代表的分别是飞机,汽车,鸟,猫,鹿,狗,青蛙,马,船,卡车。
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6,
kernel_size=(5,5,),
strides=1,
padding='same'),
#6个5*5卷积核,步长1,使用全零填充(C)
tf.keras.layers.BatchNormalization(),
#BN函数批次归一化(B)
tf.keras.layers.Activation('relu'),
#relu激活(A)
tf.keras.layers.MaxPool2D(pool_size=(2,2),
strides=2,
padding='same',
),
#max池化层(P)
tf.keras.layers.Dropout(0.2),
#舍弃层,概率为20%(D)
#在次卷积
tf.keras.layers.Conv2D(filters=6,
kernel_size=(3, 3,),
strides=1,
padding='same'),
# 8个3*3卷积核,步长1,使用全零填充(C)
tf.keras.layers.BatchNormalization(),
#BN函数批次归一化(B)
tf.keras.layers.Activation('relu'),
# relu激活(A)
tf.keras.layers.MaxPool2D(pool_size=(2, 2),
strides=2,
padding='same',
),
# max池化层(P)
tf.keras.layers.Dropout(0.2),
# 舍弃层,概率为20%(D)
# 接下来送给全连接网络
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(128,activation='relu'),#使用relu激活
tf.keras.layers.Dropout(0.2),# 舍弃层,概率为20%舍弃20%的网络参数
tf.keras.layers.Dense(10,activation='softmax')#使用softmax激活分类
])#网络架构
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
if os.path.exists(lotypath+'.index'):#如果路径文件存在着索引表
print("hello! I have finished!!!")
model.load_weights(lotypath)#读取网络参数
#在此之前需要先构建好model模型,然后再读取参数~
cp_callback=tf.keras.callbacks.ModelCheckpoint(filepath=lotypath,
save_weights_only=True,
save_best_only=True)
#save_weights_only为是否只保留模型参数
#save_best_only为是否只保留最优结果
history=model.fit(xtrain,
ytrain,
batch_size=32,
epochs=15,
validation_data=(xtest,ytest),
validation_freq=1,
callbacks=[cp_callback])#设置训练集和测试集数据
#加入了callbacks=[cp_callback]这一选项
model.summary()
十四、LeNet,AlexNet,VGGNet网络架构及其实现
我们已经学会了CNN的搭建框架结构,下面介绍几种经典的网络及其实现代码。
14.1、LeNet网络结构框架(1998)
下图是LeNet网络的结构框架,相信读者自己可以构建出来了。
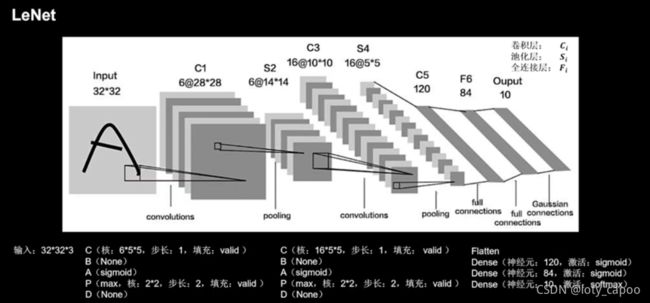
example28(LeNet):
将example27中的model替换成此结构即可。
model=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=6,
kernel_size=(5,5),
activation='sigmoid',
strides=1,
padding='valid'),
#6个5*5卷积核,步长1,不使用全零填充(C)
#无归一化
tf.keras.layers.MaxPool2D(pool_size=(2,2),
strides=2,
padding='valid',
),
#max池化层(P)
#无舍弃层,这个网络出现时代还没有Dropout层
#再次卷积
tf.keras.layers.Conv2D(filters=16,
kernel_size=(5, 5),
activation='sigmoid',
strides=1,
padding='valid'),
# 16个5*5卷积核,步长1,不使用全零填充(C)
#无BN函数批次归一化(B)
tf.keras.layers.MaxPool2D(pool_size=(2, 2),
strides=2,
padding='valid',
),
# max池化层(P)
# 无舍弃层,理由在上面
# 接下来送给全连接网络
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(120,activation='sigmoid'),#使用sigmoid激活
tf.keras.layers.Dense(84,activation='sigmoid'),#使用sigmoid激活
tf.keras.layers.Dense(10,activation='softmax')#使用softmax激活分类
])#Lenet的网络架构
14.2、AlexNet网络结构框架(2012)
下图是AlexNet网络的结构框架,他一共分为五个卷积层和三个全连接层,由于Alex原文用的为LRN局部响应归一化,这里我们用BN代替它。

example29(AlexNet):
将example27中的model替换成此结构即可。
model=tf.keras.models.Sequential([
#第一层卷积
tf.keras.layers.Conv2D(filters=96,
kernel_size=(3,3),
strides=1,
padding='valid'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=(3,3),
strides=2,
padding='valid',
),
#无舍弃层,第一层卷积结束
#第二层卷积
tf.keras.layers.Conv2D(filters=256,
kernel_size=(3, 3),
strides=1,
padding='valid'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=(3, 3),
strides=2,
padding='valid',
),
#无舍弃层,第二层卷积结束
#第三层卷积
tf.keras.layers.Conv2D(filters=384,
kernel_size=(3, 3),
strides=1,
padding='same',
activation='relu'
),
#第四层卷积
tf.keras.layers.Conv2D(filters=384,
kernel_size=(3, 3),
strides=1,
padding='same',
activation='relu'
),
# 第五层卷积
tf.keras.layers.Conv2D(filters=256,
kernel_size=(3, 3),
strides=1,
padding='same',
activation='relu'
),
tf.keras.layers.MaxPool2D(pool_size=(3, 3),
strides=2,
padding='valid',
),
# 接下来送给全连接网络
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(2048,activation='relu'),#使用'relu激活
tf.keras.layers.Dropout(0.5),# 舍弃层,概率为50%舍弃50%的网络参数
tf.keras.layers.Dense(2048,activation='relu'),#使用'relu激活
tf.keras.layers.Dropout(0.5), # 舍弃层,概率为50%舍弃50%的网络参数
tf.keras.layers.Dense(10,activation='softmax')#使用softmax激活分类
])#AlexNet的网络架构
14.3、VGGNet网络结构框架(2014)
下图是16层VGGNet网络的结构框架,根据以下我们可以写出16层VGG的代码,至于任意多少层的VGGNet大家可以仿照VGG原理进行继续编写。
这里是8层CBA,5层CBAPD,3层全连接构成了,结构如下:
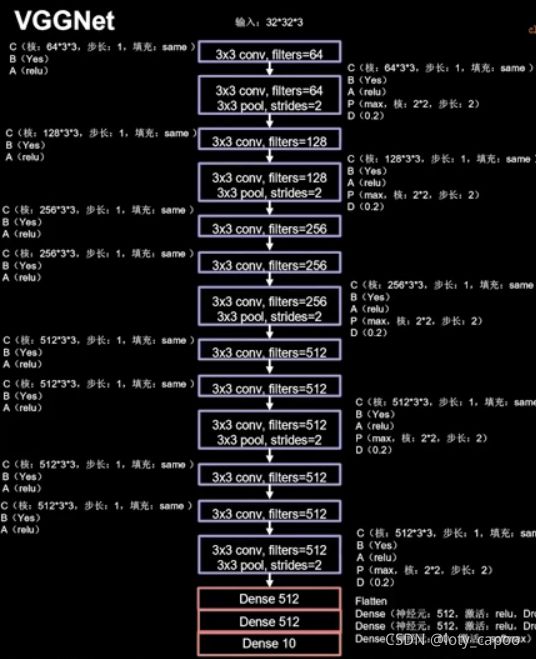
看起来很复杂,实际上我们已经很容易写出它的网络结构了
example30(16=13+3dense的VGGNet):
将example27中的model替换成此结构即可。
model=tf.keras.models.Sequential([
#第一层卷积
tf.keras.layers.Conv2D(filters=64,
kernel_size=(3,3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
#第一层卷积结束
#第二层卷积
tf.keras.layers.Conv2D(filters=64,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2),
strides=2,
padding='valid',
),
tf.keras.layers.Dropout(0.2),
#第二层卷积结束
#第三层卷积
tf.keras.layers.Conv2D(filters=128,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
#第三层卷积结束
#第四层卷积
tf.keras.layers.Conv2D(filters=128,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2),
strides=2,
padding='valid',
),
tf.keras.layers.Dropout(0.2),
#第四层卷积结束
# 第五层卷积
tf.keras.layers.Conv2D(filters=256,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
# 第五层卷积结束
# 第六层卷积
tf.keras.layers.Conv2D(filters=256,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
# 第六层卷积结束
# 第七层卷积
tf.keras.layers.Conv2D(filters=256,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2),
strides=2,
padding='valid',
),
tf.keras.layers.Dropout(0.2),
# 第七层卷积结束
# 第八层卷积
tf.keras.layers.Conv2D(filters=512,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
# 第八层卷积结束
# 第九层卷积
tf.keras.layers.Conv2D(filters=512,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
# 第九层卷积结束
# 第十层卷积
tf.keras.layers.Conv2D(filters=512,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2),
strides=2,
padding='valid',
),
tf.keras.layers.Dropout(0.2),
# 第十层卷积结束
# 第十一层卷积
tf.keras.layers.Conv2D(filters=512,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
# 第十一层卷积结束
# 第十二层卷积
tf.keras.layers.Conv2D(filters=512,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
# 第十二层卷积结束
# 第十三层卷积
tf.keras.layers.Conv2D(filters=512,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
tf.keras.layers.MaxPool2D(pool_size=(2, 2),
strides=2,
padding='valid',
),
tf.keras.layers.Dropout(0.2),
# 第十三层卷积结束
# 接下来送给三层全连接网络
tf.keras.layers.Flatten(),#将数据直接拉长为一维数组喂入神经网络
tf.keras.layers.Dense(512,activation='relu'),#使用relu激活
tf.keras.layers.Dropout(0.2),# 舍弃层,概率为50%舍弃50%的网络参数
tf.keras.layers.Dense(512,activation='relu'),#使用relu激活
tf.keras.layers.Dropout(0.2), # 舍弃层,概率为50%舍弃50%的网络参数
tf.keras.layers.Dense(10,activation='softmax')#使用softmax激活分类
])#16层VGGNet的网络架构
十五、ResNet,InceptionNet网络架构及其实现
不同于之前的网络架构,这两个网络架构需要自己单独的结构块来实现,而不是像之前三个网络的简单设计卷积。
15.1、InceptionNet网络结构框架(2014)
这是2014年的冠军网络,VGG是当年的亚军网络,这个网络特殊在它具有自己的结构块,我们称之为InceptionNet结构块,结构块的功能很重要,大家一定要记住!
15.1.1、InceptionNet结构块功能:
结构块功能:在同一层网络中使用不同的卷积核,提取出这一层多个特征,并按照深度排行这些特征而不是卷积加和。
换而言之,InceptionNet网络正因为具有InceptionNet结构块增加了网络的表达能力,下图是结构块的示意图
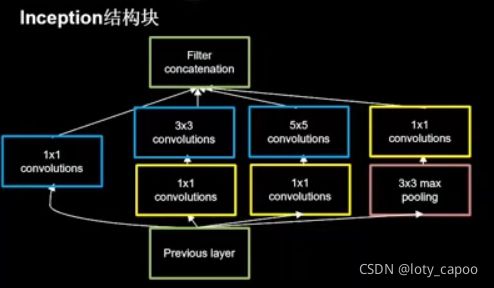
这是结构块的输出如下:

因此我们需要先定义结构块,再定义网络,转换成我们熟悉的图片,网络定义应该如下所示:
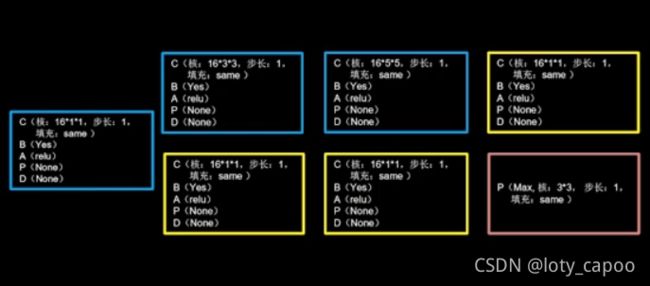 一个四层的网络结构如下所示:
一个四层的网络结构如下所示:
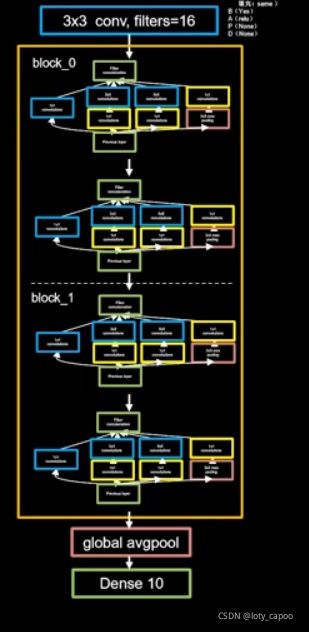
还记得类去定义model的写法吗?因为这里我们要在一层里面嵌套,因此我们不妨用类去写InceptionNet结构块!
example31(InceptionNet结构块定义)
class loty_InceptionNetModel(Model):
def __init__(self):
super(loty_InceptionNetModel, self).__init__()
self.channel1=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16,
kernel_size=(1, 1),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu')
])#左边第一个channel
self.channel2_1=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16,
kernel_size=(1, 1),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu')
])#左边第二个channel第一部分
self.channel2_2 = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16,
kernel_size=(3, 3),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu')
]) # 左边第二个channel第二部分
self.channel3_1=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16,
kernel_size=(1, 1),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu')
])#左边第三个channel第一部分
self.channel3_2 = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16,
kernel_size=(5, 5),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu')
]) # 左边第三个channel第二部分
self.channel4_1=tf.keras.layers.MaxPool2D(
pool_size=(3, 3),
strides=1,
padding='same',
)
# 左边第四个channel第一部分
self.channel4_2 = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=16,
kernel_size=(1, 1),
strides=1,
padding='same'),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu')
]) # 左边第四个channel第二部分
def call(self,x):
x_1=self.channel1(x)
x_21=self.channel2_1(x)
x_22=self.channel2_2(x_21)
x_31=self.channel3_1(x)
x_32=self.channel3_2(x_31)
x_41=self.channel4_1(x)
x_42=self.channel4_2(x_41)
x=tf.concat([x_1,x_22,x_32,x_42],axis=3)
#axis=3代表沿着深度方向排列。
return x
example32(InceptionNet网络):
将example27中的model替换成此结构即可。
在这里笔者和老师写法相似,都是用类来定义的结构块,方便大家运行和操作,InceptionNet网络最突出的优点就是网络框架特别的整洁。
大家对注释有问题的请给笔者留言笔者会一一解答疑惑地点
import tensorflow as tf
from tensorflow.keras import Model
class Robot(Model):
#封装一些操作,便于之后进行
def __init__(self,channel,kerenalsize,strides,padding='same'):
super(Robot,self).__init__()
self.robot=tf.keras.models.Sequential([
tf.keras.layers.Conv2D(filters=channel,
kernel_size=(kerenalsize, kerenalsize),
strides=strides,
padding=padding),
tf.keras.layers.BatchNormalization(),
tf.keras.layers.Activation('relu'),
])
def call(self, x):
y = self.robot(x)
return y
#InceptionNet结构块
class InceptionNetModel(Model):
def __init__(self, channel,strides):
super(InceptionNetModel, self).__init__()
self.channel=channel
self.strides=strides
#开始构建InceptionNet结构块
self.c1=Robot(channel,kerenalsize=1,strides=strides)
self.c2_1=Robot(channel, kerenalsize=1, strides=strides)
self.c2_2=Robot(channel,kerenalsize=3,strides=1)
self.c3_1=Robot(channel, kerenalsize=1, strides=strides)
self.c3_2=Robot(channel,kerenalsize=5,strides=1)
self.c4_1=tf.keras.layers.MaxPool2D(
pool_size=(3, 3),
strides=1,
padding='same',
),
self.c4_2=Robot(channel,kerenalsize=5,strides=strides)
def call(self, x):
x_1 = self.c1(x)
x_21 = self.c2_1(x)
x_22 = self.c2_2(x_21)
x_31 = self.c3_1(x)
x_32 = self.c3_2(x_31)
x_41 = self.c4_1(x)
x_42 = self.c4_2(x_41)
x = tf.concat([x_1, x_22, x_32, x_42], axis=3)
# axis=3代表沿着深度方向排列。
return x
#InceptionNet
class InceptionNet(Model):
def __init__(self, blocks_number,classes,**kwargs):
# **kwargs代表转递可变长列表参数的意思。
#blocks_number代表几个Inception块,两个块一个blocks
#classes代表待分类问题结果是几类
super(InceptionNet, self).__init__(**kwargs)
self.outchannel=16
self.blocks_number=blocks_number
self.classes=classes
self.c1=Robot(channel=16,kerenalsize=3,strides=1)#第一层网络为3*3*16的卷积核
self.blocks=tf.keras.models.Sequential()
for range1 in range(blocks_number):
for range2 in range(2):
if(range2==0):#每个blocks的第一个连接步长为2的结构块如图所示
block=InceptionNetModel(self.outchannel,strides=2)
else:#每个blocks的第二个连接步长为1的结构块如图所示
block = InceptionNetModel(self.outchannel, strides=1)
self.blocks.add(block)
self.outchannel=self.outchannel*2#扩大网络通道数×2
self.p1=tf.keras.layers.GlobalAveragePooling2D()
#全局平均池化
self.f1=tf.keras.layers.Dense(classes,activation='softmax')
#最后的全连接要以输出特征数为神经元个数,softmax输出概率分布
def call(self, x):
x=self.c1(x)#调用第一个卷积核
x=self.blocks(x)#调用blocks进行blocks连接
x=self.p1(x)#调用全局平均池化
y=self.f1(x)#最后的全连接连接网络并进行输出
return y
model=InceptionNet(blocks_number=2,classes=10)
#block数量为2个,四个结构块,分类数量为10个。
15.2、ResNet网络结构框架(2015)
之前的网络我们发现,都是深度不断地增加以增加网络的表达能力和准确率,但是ResNet的作者何恺明发现并不是网络越深越好,他做的实验发现56层的网络效果还不如20层的网络好一些,也就是说,太深的网络特征有了损失,模型出现了退化,也就是说,网络的深度堆叠导致网络出现了退化。为了缓解这种退化现象,衍生出了ResNet网络,ResNet网络也是由ResNet块构成的,下例是ResNet块的定义:
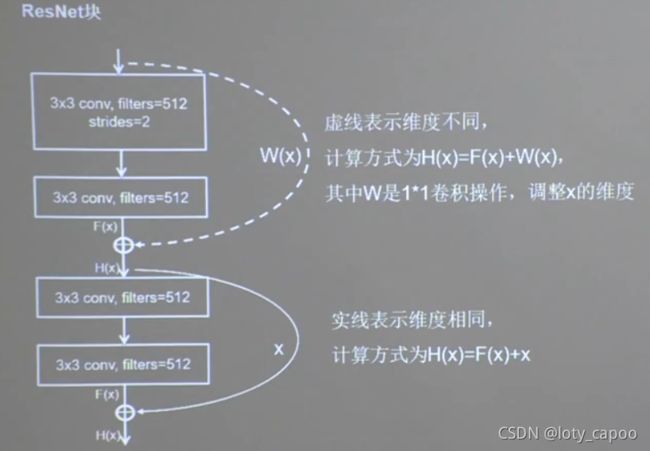
如果输入和输出维度相同,则执行实线部分计算H(x)真实输出,否则先通过一个1*1的卷积调整维度和F(x)一样,然后再执行计算H(x)操作。
15.2.1、ResNet结构块功能:
上面的结构称为一个ResNet块,ResNet是由千千万万个这样的ResNet块构成的!下面我们分析并进行ResNet块的定义和编写。
example33(ResNet结构块定义):
class loty_resnet(Model):
def __init__(self,filters_number,strides,res_ornot,padding='same'):
super(loty_resnet, self).__init__()
self.filters_number=filters_number
self.strides=strides
self.res_ornot=res_ornot
#他们分别定义的是卷积核个数,步长,是虚线还是实线连接
if(res_ornot):#如果实行虚线连接,也就是通过一层1*1的卷积核
self.c1=tf.keras.layers.Conv2D(
filters=filters_number,
kernel_size=(1,1),#1*1卷积
strides=strides,
padding='same',
use_bias=False#不使用偏置
)
self.c2=tf.keras.layers.BatchNormalization()
#下面是正常的卷积操作,和是否实虚线连接无关。
self.d1=tf.keras.layers.Conv2D(
filters=filters_number,
kernel_size=(3,3),#1*1卷积
strides=strides,
padding='same',
use_bias=False#不使用偏置
)
self.d2=tf.keras.layers.BatchNormalization()
self.d3=tf.keras.layers.Activation('relu')
self.d4=tf.keras.layers.Conv2D(
filters=filters_number,
kernel_size=(3,3),#1*1卷积
strides=1,#步长为1
padding='same',
use_bias=False#不使用偏置
)
self.d5=tf.keras.layers.BatchNormalization()
self.d6=tf.keras.layers.Activation('relu')#使用relu进行激活
def call(self, x):
residual=x
#如果不进行虚线操作,那么这个时候residual就是输入直接相加
#进行卷积
result=self.d1(x)
result=self.d2(result)
result=self.d3(result)
result=self.d4(result)
y=self.d5(result)
#卷积结束得到输出结果y
if(self.res_ornot):#如果是虚线连接执行虚线部分的1*1卷积
residual=self.c1(x)
residual=self.c2(residual)
finally_result=self.d6(y+residual)
#最后通过一次relu激活
return finally_result
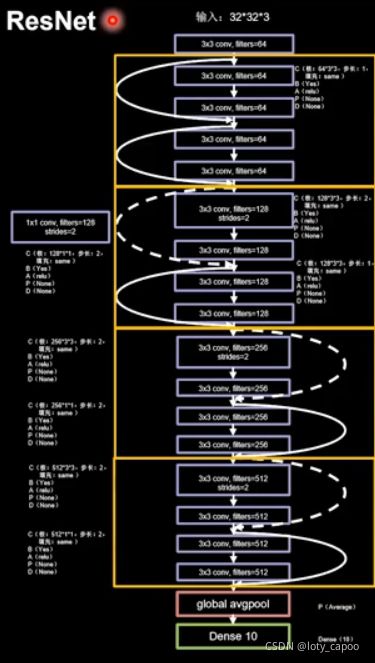
非常好,你已经坚持到这里了,下面距离构建ResNet仅差一步了!下图是ResNet的示例构建图,我们发现ResNet除了第一个ResNet块是纯实线之外,后面都是虚线!这一点一定要注意!对于网络的构建,相信大家看完前面这么多了,也应该对构建这个网络不陌生了吧~大家自己完成一下,然后可以和我的对照一下。
example34(ResNet):
将example27中的model替换成此结构即可
class loty_resnet(Model):
def __init__(self,filters_number,strides,res_ornot):
super(loty_resnet, self).__init__()
self.filters_number=filters_number
self.strides=strides
self.res_ornot=res_ornot
#他们分别定义的是卷积核个数,步长,是虚线还是实线连接
if(res_ornot):#如果实行虚线连接,也就是通过一层1*1的卷积核
self.c1=tf.keras.layers.Conv2D(
filters=filters_number,
kernel_size=(1,1),#1*1卷积
strides=strides,
padding='same',
use_bias=False#不使用偏置
)
self.c2=tf.keras.layers.BatchNormalization()
#下面是正常的卷积操作,和是否实虚线连接无关。
self.d1=tf.keras.layers.Conv2D(
filters=filters_number,
kernel_size=(3,3),#3*3卷积
strides=strides,
padding='same',
use_bias=False#不使用偏置
)
self.d2=tf.keras.layers.BatchNormalization()
self.d3=tf.keras.layers.Activation('relu')
self.d4=tf.keras.layers.Conv2D(
filters=filters_number,
kernel_size=(3,3),#3*3卷积
strides=1,#步长为1
padding='same',
use_bias=False#不使用偏置
)
self.d5=tf.keras.layers.BatchNormalization()
self.d6=tf.keras.layers.Activation('relu')#使用relu进行激活
def call(self, x):
residual=x
#如果不进行虚线操作,那么这个时候residual就是输入直接相加
#进行卷积
result=self.d1(x)
result=self.d2(result)
result=self.d3(result)
result=self.d4(result)
y=self.d5(result)
#卷积结束得到输出结果y
if(self.res_ornot):#如果是虚线连接执行虚线部分的1*1卷积
residual=self.c1(x)
residual=self.c2(residual)
finally_result=self.d6(y+residual)
#最后通过一次relu激活
return finally_result
class resnet(Model):
def __init__(self, blocklist,classes,filters=64):
super(resnet, self).__init__()
self.length=len(blocklist)
self.blocklist=blocklist
self.filters=filters
#先进入一个前置卷积层
self.c1=tf.keras.layers.Conv2D(
filters=filters,
kernel_size=(3,3),
strides=1,
padding='same',
kernel_initializer='he_normal',
use_bias=False#不使用偏置
)
self.c2=tf.keras.layers.BatchNormalization()
self.c3=tf.keras.layers.Activation('relu')#使用relu进行激活
self.blocks=tf.keras.models.Sequential()
for range1 in range(len(blocklist)):
for range2 in range(blocklist[range1]):#进行每一个块内的卷积层循环
# 只要不是第一层,而且是每一个块的第一个卷积层就执行虚线部分的卷积计算
if((range1!=0)and(range2==0)):
block=loty_resnet(self.filters,strides=2,res_ornot=True)
else:
block = loty_resnet(self.filters, strides=1,res_ornot=False)
self.blocks.add(block)
self.filters=self.filters*2
#类似于Inceptionnet一样的操作
#最后的两层,一层全连接,一层全局平均池化
self.p1=tf.keras.layers.GlobalAveragePooling2D()
self.f1=tf.keras.layers.Dense(classes,activation='softmax')
def call(self, x):
x=self.c1(x)
x=self.c2(x)
x=self.c3(x)
x=self.blocks(x)
x=self.p1(x)
y=self.f1(x)
return y
model=resnet(blocklist=[2,2,2,2],classes=10)
这就是以上几大网络的代码,下面两个框架结构代码根据自己电脑配置运行,比如笔者电脑比较垃圾,在没GPU加速条件下运行一个epoch时间超过了1个小时而且网络太深CPU要爆炸了…这里建议大家GPU加速后再去运行,这个Resnet准确率还是很高的!相比之前的准确率有本质的提升,并且它可以继续推广下去,使网络加深得到了可能。
总结:以上我们介绍了五种经典神经网络和两种网络块,后两种大家一定要掌握,因为很多图像处理网络是在他们的基础上进行改进的,如想看懂类似的代码和论文学会他们是必不可少的,大家可以重新进行自我编写
十六、循环神经网络
循环神经网络可以做时间序列的预测,文章预测等等,它的关键地方就是它可以像人脑一样存储记忆并提取时间信息。
16.1、循环核
循环核和卷积核很类似,但是循环核具有不同于卷积核的性质:
①网络参数时间共享
②循环层提取时间信息
下面就是一个循环核的示例图:

在这里,输入为xt,经过三个矩阵,矩阵的头和尾的维度取决于输入和输出的大小,中间是隐藏层,一个循环核就是由三个这样的矩阵所构成的。
循环核存在一个记忆体ht,记忆体里面存储了当前的记忆信息,记忆体存储的信息ht又称为当前时刻的状态信息它的更新公式和输出yt分别是这样计算的:
y t = s o f t m a x ( h t W h y + b y ) b y 是 偏 置 y_t=softmax(h_tW_{hy}+by)by是偏置 yt=softmax(htWhy+by)by是偏置
h t = t a n h ( x t W x h + h t − 1 W h h + b h ) b h 是 偏 置 h_t=tanh(x_tW_{xh}+h_{t-1}W_{hh}+bh)bh是偏置 ht=tanh(xtWxh+ht−1Whh+bh)bh是偏置
在循环神经网络中,他们是共用一个循环核的,这就是和CNN不同的地方了:下图是我们按照时间线展开后的循环神经网络:
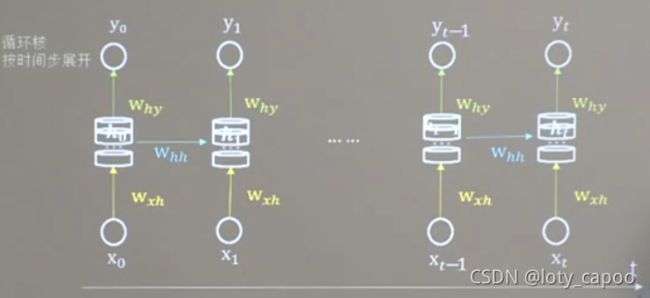
会发现他们其实都共用了一个循环核
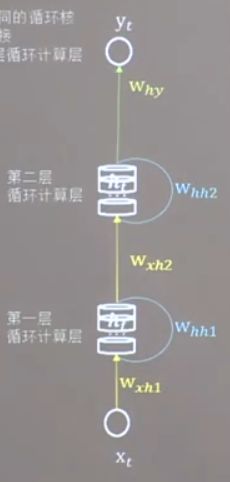
当然了,你也可以不只定义一个循环核,我还可以像下图这样定义两层,三层,四层···等等。
16.2、Tensorflow的tf.keras.layers.SimpleRNN()
循环网络循环核
tf.keras.layers.SimpleRNN(记忆体要多少个,activation=‘激活函数’,return_sequences=是否每个时刻输出ht到下一层)
16.2.1、函数详解
return_sequences=True代表各个时间都输入到下一层
return_sequences=False代表仅最后时间输出ht(一般最后一个循环核不要)
activation默认是tanh函数
16.2.2、API维数要求
RNN对输入的训练集要求非常的严格,要求输入格式如下:
xtrain=[送入样本总数,循环核按时间展开的步长,每个时间步长输入的特征数量]
16.3、独热编码——字母预测
下面我们考虑这样一个问题,输入a要输出它下一个字母b,输入b要输出它下一个字母c,输入c要预测它下一个字母d,以此类推,假设输入f我们要预测它的输出是a,这样一个循环我们如何利用循环神经网络来进行构建呢?
16.3.1、特征转独热编码:
我们都知道abcdef这些是字母,而不是网络习惯用的数量阵,因此对于这些字母,我们首先需要利用独热编码将他们转化为6类,之后进行编写,这六类独热编码如下:
xtrain=[[1.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 1.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 1.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0]]
接下来我们分成两个来进行预测,一个是给一个字母就预测下一个字母的,还有给多个字母来预测下一个字母的,这两个分别对应了是否按照时间展开的情况。
example35(字母预测abcdef-不按照时间展开):
import tensorflow as tf
import numpy as np
xtrain=[[1.0, 0.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 1.0, 0.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 1.0, 0.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 1.0, 0.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 1.0, 0.0],
[0.0, 0.0, 0.0, 0.0, 0.0, 1.0]]
ytrain=[1, 2, 3, 4, 5, 0]
#0-5分别代表abcdef
np.random.seed(10)
np.random.shuffle(xtrain)
np.random.seed(10)
np.random.shuffle(ytrain)
tf.random.set_seed(10)
xtrain=np.reshape(xtrain, (len(xtrain), 1, 6))
#转换成RNN支持的类型
ytrain=np.array(ytrain)
model=tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(5),#设置记忆元
tf.keras.layers.Dense(6,activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
model.fit(xtrain,
ytrain,
batch_size=32,
epochs=100
)#设置训练集和测试集数据
model.summary()
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4,'f':5} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.,0.], 1: [0., 1., 0., 0., 0.,0.], 2: [0., 0., 1., 0., 0.,0.], 3: [0., 0., 0., 1., 0.,0.],
4: [0., 0., 0., 0., 1.,0.],5: [0., 0., 0., 0., 0.,1.]} # id编码为one-hot
list1=input("请输入您要预测的字母。")
kkk=[id_to_onehot[w_to_id[list1]]]
list2=np.reshape(kkk, (1, 1, 6))#转成RNN的输入形式
print(model.predict([list2]))
测试输入a输出b,输入b输出c···
example36(字母预测abcdef-按照时间展开):
import tensorflow as tf
import numpy as np
xtrain=[[[1.0, 0.0, 0.0, 0.0, 0.0, 0.0],[0.0, 1.0, 0.0, 0.0, 0.0, 0.0],[0.0, 0.0, 1.0, 0.0, 0.0, 0.0],[0.0, 0.0, 0.0, 1.0, 0.0, 0.0]],
[[0.0, 1.0, 0.0, 0.0, 0.0, 0.0],[0.0, 0.0, 1.0, 0.0, 0.0, 0.0],[0.0, 0.0, 0.0, 1.0, 0.0, 0.0],[0.0, 0.0, 0.0, 0.0, 1.0, 0.0]],
[[0.0, 0.0, 1.0, 0.0, 0.0, 0.0],[0.0, 0.0, 0.0, 1.0, 0.0, 0.0],[0.0, 0.0, 0.0, 0.0, 1.0, 0.0],[0.0, 0.0, 0.0, 0.0, 0.0, 1.0]]]
#输入abcd输出e,输入bcde输出f,输入cdef输出a
ytrain=[4, 5, 0]
#0-5分别代表abcdef
np.random.seed(10)
np.random.shuffle(xtrain)
np.random.seed(10)
np.random.shuffle(ytrain)
tf.random.set_seed(10)
xtrain=np.reshape(xtrain, (len(xtrain), 4, 6))
#转换成RNN支持的类型
ytrain=np.array(ytrain)
model=tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(5),#设置记忆元
tf.keras.layers.Dense(6,activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
model.fit(xtrain,
ytrain,
batch_size=32,
epochs=100
)#设置训练集和测试集数据
model.summary()
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4,'f':5} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.,0.], 1: [0., 1., 0., 0., 0.,0.], 2: [0., 0., 1., 0., 0.,0.], 3: [0., 0., 0., 1., 0.,0.],
4: [0., 0., 0., 0., 1.,0.],5: [0., 0., 0., 0., 0.,1.]} # id编码为one-hot
list1=input("请输入您要预测的字母。")
list2=input("请输入您要预测的字母。")
list3=input("请输入您要预测的字母。")
list4=input("请输入您要预测的字母。")
kkk1=[id_to_onehot[w_to_id[list1]]]
kkk2=[id_to_onehot[w_to_id[list2]]]
kkk3=[id_to_onehot[w_to_id[list3]]]
kkk4=[id_to_onehot[w_to_id[list4]]]
list5=np.reshape([kkk1,kkk2,kkk3,kkk4], (1, 4, 6))#转成RNN的输入形式
print(model.predict([list5]))
测试输入abcd输出e,输入bcde输出f···
16.4、Embedding编码
独热编码编码单词很浪费资源,矩阵过于稀疏,并且独热编码比适用于大规模单词编码,因为那样会使得矩阵维数极其的大,并且单词与单词之间的相关性在独热编码中没办法展现出来,很不方便定义,Tensorflow给出了一种可以专门单词定义的编码——Embedding编码
16.4.1、Embedding编码函数:
tf.keras.layers.Embedding(词汇表大小,编码维度)
例如以下的例子所示:
tf.keras.layers.Embedding(1000,3)
#将1000个数编码到三维空间,每个数都有一个自己的编码
16.4.2、Embedding编码维度要求:
要求如下所示:
xtrain=[送入样本总数,循环核按时间展开的步长]
下面改写原来的独热编码代码,替换部分就可以了,这里笔者只更新了不展开时间步长的代码,展开的留个读者自行完成吧。
example37(改example35成Embedding编码):
import tensorflow as tf
import numpy as np
xtrain=[0,1,2,3,4,5]
#输入abcd输出e,输入bcde输出f,输入cdef输出a
ytrain=[2,3,4,5,1,0]
#0-5分别代表abcdef
np.random.seed(10)
np.random.shuffle(xtrain)
np.random.seed(10)
np.random.shuffle(ytrain)
tf.random.set_seed(10)
xtrain=np.reshape(xtrain, (len(xtrain), 1))
#转换成Embedding支持的类型
ytrain=np.array(ytrain)
model=tf.keras.models.Sequential([
tf.keras.layers.Embedding(6,2),#六行两列的编码数据可训练
tf.keras.layers.SimpleRNN(5),#设置记忆元
tf.keras.layers.Dense(6,activation='softmax')
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.01),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
#因为我们用softmax输出的因此这里已经满足概率分布了所以是False
metrics=['sparse_categorical_accuracy']
#因为输出是概率分布,而我们的y是标签值,因此用第三种情况
)#网络优化和损失
model.fit(xtrain,
ytrain,
batch_size=32,
epochs=100
)#设置训练集和测试集数据
model.summary()
w_to_id = {'a': 0, 'b': 1, 'c': 2, 'd': 3, 'e': 4,'f':5} # 单词映射到数值id的词典
id_to_onehot = {0: [1., 0., 0., 0., 0.,0.], 1: [0., 1., 0., 0., 0.,0.], 2: [0., 0., 1., 0., 0.,0.], 3: [0., 0., 0., 1., 0.,0.],
4: [0., 0., 0., 0., 1.,0.],5: [0., 0., 0., 0., 0.,1.]} # id编码为one-hot
list1=input("请输入您要预测的字母。")
kkk1=[id_to_onehot[w_to_id[list1]]]
list5=np.reshape([kkk1], (1,1))#转成Embedding的输入形式
print(model.predict([list5]))
16.5、RNN股票预测
本文中使用老师提供的数据集,大家可以自行搜索数据集,
我们利用RNN来预测一下股票的开盘价格,预测代码如下所示供大家学习和参考,详细的地方我都给予了注释,大家可以参考一下里面的写法来进行
example38(RNN股票预测):
import tensorflow as tf
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
import matplotlib.pyplot as plt
file=pd.read_csv("C:/Users/DELL/Desktop/SH600519.csv")
#读取CSV文件,我们只要开盘open价格
training_set = file.iloc[0:2426 - 300, 2:3].values
test_set = file.iloc[2426 - 300:, 2:3].values
#后三百个作为网络测试集
sc=MinMaxScaler(feature_range=(0, 1))
#归一化到零一区间中
training_set_scaled=sc.fit_transform(training_set)
#求训练集的最大和最小值并归一化它
test_set=sc.transform(test_set)
#利用训练集的最大和最小值并归一化测试集
xtrain=[]
ytrain=[]
xtest=[]
ytest=[]
#每30天一个周期,预测第60天的内容,将前59天作为xtrain
#第31天作为ytrain,同理后面也是这样的
for range1 in range(60,len(training_set_scaled)):
xtrain.append(training_set_scaled[range1-60:range1,0])
ytrain.append(training_set_scaled[range1,0])
#设置随机种子
np.random.seed(9)
np.random.shuffle(xtrain)
np.random.seed(9)
np.random.shuffle(ytrain)
tf.random.set_seed(9)
xtrain,ytrain=np.array(xtrain),np.array(ytrain)
xtrain=np.reshape(xtrain,(xtrain.shape[0],60,1))
for range2 in range(60,len(test_set)):
xtest.append(test_set[range2-60:range2,0])
ytest.append(test_set[range2,0])
#加到列表中去
xtest,ytest=np.array(xtest),np.array(ytest)
xtest=np.reshape(xtest,(xtest.shape[0],60,1))
model=tf.keras.models.Sequential([
tf.keras.layers.SimpleRNN(80,return_sequences=True),#设置记忆元
tf.keras.layers.Dropout(0.2),
tf.keras.layers.SimpleRNN(100),#设置记忆元
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1)
])
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error'
#我们是预测,没有准确率
)#网络优化和损失
history=model.fit(xtrain,
ytrain,
batch_size=64,
epochs=50,
validation_data=(xtest,ytest),
validation_freq=1
)#设置训练集和测试集数据
model.summary()
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.legend()
plt.show()
# 测试集输入模型进行预测
predicted_price = model.predict(xtest)
# 对预测数据还原---从(0,1)反归一化到原始范围
predicted_stock_price=sc.inverse_transform(predicted_price)
# 对真实数据还原---从(0,1)反归一化到原始范围
real_price = sc.inverse_transform(test_set[60:])
# 画出真实数据和预测数据的对比曲线
plt.plot(real_price, color='red', label='real-value')
plt.plot(predicted_stock_price, color='blue', label='Predicted value')
plt.legend()
plt.show()
16.5.1、RNN-预测效果
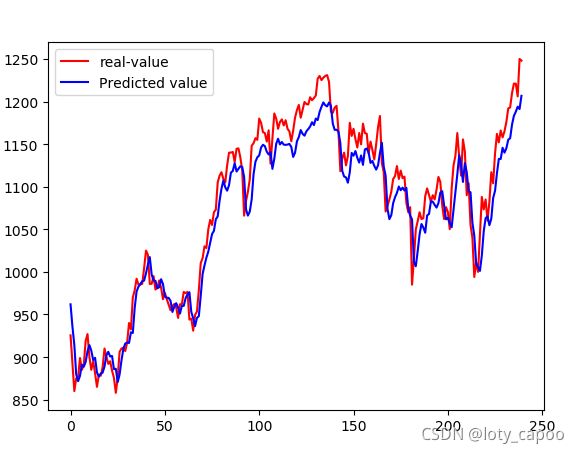
16.5.2、预测说明
实际上,改动一点点RNN的参数或者层数都会导致股票预测结果发生很大变化,网络的调整和dropout是关键所在,切记,并不是网络越深越好!
16.6、长短时记忆神经网络LSTM
RNN只适合于短期的网络预测,对于长期的网络预测效果,RNN并不能很好的描述甚至它的预测会出现极大的失真,由于网络过大,反向传播梯度相乘及其容易梯度消失,因此出现了LSTM长短时记忆网络LSTM通过门控网络控制三个们的输入输出来决定信息的遗忘和索取,下面是它的三个门控和一些状态:

16.6.1、原理说明:
σ代表的为sigmoid函数,他控制三个门控输出为0-1之间的数值,bi,bf,bo为三个偏置项,其余的和RNN的原理是类似的,LSTM有点像人脑的记忆过长,细胞态的长期记忆是由上一时刻的新知识和当前时刻的新知识构成的,由于我们学习中,上一时刻的新知识不能完全的记忆,所以要乘以遗忘门代表我们遗忘后剩余的知识,再加上我们新学的知识构成了现在的我们细胞态,当你把这一部分细胞态变为记忆再去输出时,你也不是完全的都能输出出去,类似于我们将知识传授给他人,是达不到100%的效果的,所以要乘以输出门来代替。这就是LSTM的工作原理,和我们的大脑很类似。
16.6.2、Tensorflow LSTM函数
Tensorflow给出了一个LSTM的函数也就是LSTM层如下所示:
tf.keras.layers.LSTM(记忆体个数,return_sequences=是否返回输出)
16.6.3、LSTM改进股票预测
这里非常简单啦,我们只需要把我们的model进行更改就好了!
example39(LSTM改进股票预测):
只需要替换model如下即可:
model=tf.keras.models.Sequential([
tf.keras.layers.LSTM(80,return_sequences=True),#设置记忆元
tf.keras.layers.Dropout(0.2),
tf.keras.layers.LSTM(100),#设置记忆元
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1)
])
16.6.4、LSTM-预测效果
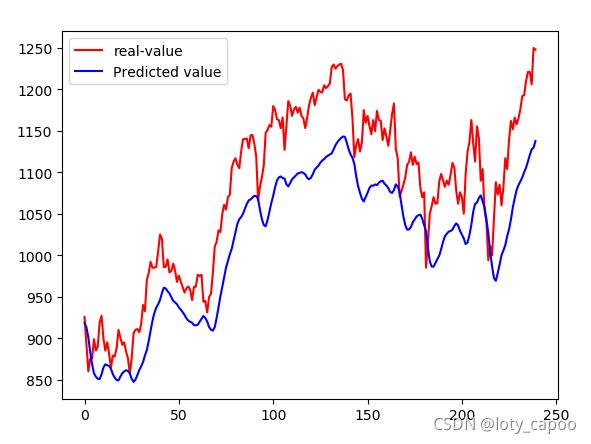
16.7、GRU网络
GRU网络的结构示意图在LSTM的基础上增加了下面几个点:

16.7.1、Tensorflow GRU函数
Tensorflow给出了一个LSTM的函数也就是LSTM层如下所示:
tf.keras.layers.GRU(记忆体个数,return_sequences=是否返回输出)
16.7.2、GRU改进股票预测
我们只需要类似一样把我们的model进行更改就好了!
example40(GRU改进股票预测):
只需要替换model如下即可:
model=tf.keras.models.Sequential([
tf.keras.layers.GRU(80,return_sequences=True),#设置记忆元
tf.keras.layers.Dropout(0.2),
tf.keras.layersGRU(100),#设置记忆元
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(1)
])
16.7.3、GRU-预测效果
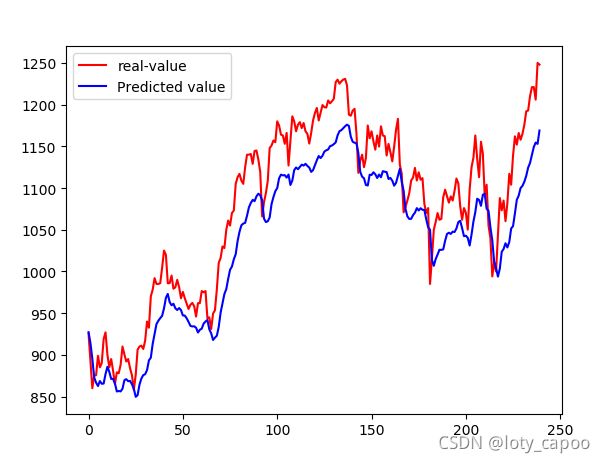
十七、本文总结
本文针对Tensorflow和keras及其部分numpy进行了一些简要的介绍和总结,供给大家进行学习和参考,本文特别感谢北京大学曹健老师的课,给我的启发很大,大家在用网络时候一定要学会不断地改进和调整网络参数,不要盲目的套用模板,要冷静分析后自我设计网络模型,这样才能够达到最优的效果,希望各位看完本文后能够有所收获。
最后希望各位支持笔者,笔者会今后更新其他的学习笔记并总结上来。笔者有幸与各位进行分享。与各位一起努力进步!