sklearn(一)计算auc:使用sklearn.metrics.roc_auc_score()计算二分类的auc
1.auc的计算原理
从常用评价指标文章中摘出来:
ROC(Receiver Operating Characteristic)曲线是以假正率(FPR)和真正率(TPR)为轴的曲线,ROC曲线下面的面积我们叫做AUC,如下图所示:
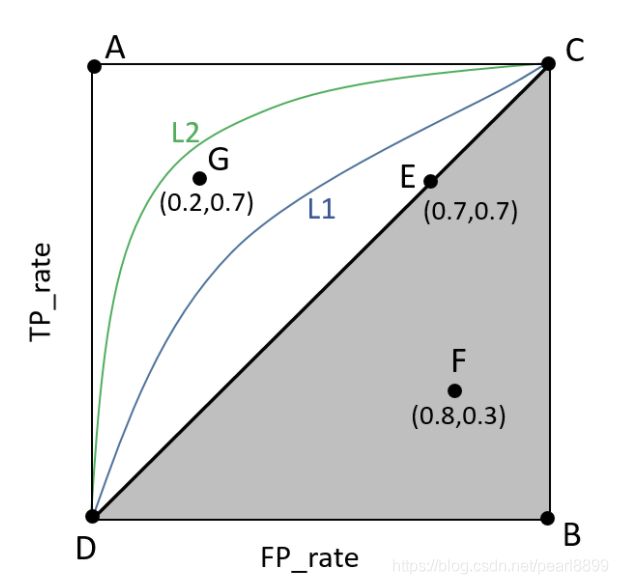
(2)A点是最完美的performance点,B处是性能最差点。
(3)位于C-D线上的点说明算法性能和random猜测是一样的–如C、D、E点。位于C-D之上(即曲线位于白色的三角形内)说明算法性能优于随机猜测–如G点,位于C-D之下(即曲线位于灰色的三角形内)说明算法性能差于随机猜测–如F点。
(4)虽然ROC曲线相比较于Precision和Recall等衡量指标更加合理,但是其在高不平衡数据条件下的的表现仍然过于理想,不能够很好的展示实际情况。
2.sklearn.metrics.roc_auc_score()的使用方法
用法:计算auc
sklearn.metrics.roc_auc_score(y_true, y_score, *, average='macro', sample_weight=None, max_fpr=None, multi_class='raise', labels=None)[source])输入参数:
y_true:真实的标签。形状(n_samples,)或(n_samples, n_classes)。二分类的形状(n_samples,1),而多标签情况的形状(n_samples, n_classes)。
y_score:目标分数。形状(n_samples,)或(n_samples, n_classes)。二分类情况形状(n_samples,1),“分数必须是具有较大标签的类的分数”,通俗点理解:模型打分的第二列。举个例子:模型输入的得分是一个数组[0.98361117 0.01638886],索引是其类别,这里“较大标签类的分数”,指的是索引为1的分数:0.01638886,也就是正例的预测得分。
average='macro':二分类时,该参数可以忽略。用于多分类,' micro ':将标签指标矩阵的每个元素看作一个标签,计算全局的指标。' macro ':计算每个标签的指标,并找到它们的未加权平均值。这并没有考虑标签的不平衡。' weighted ':计算每个标签的指标,并找到它们的平均值,根据支持度(每个标签的真实实例的数量)进行加权。(多分类的问题在下一篇文章中解释)
sample_weight=None:样本权重。形状(n_samples,),默认=无。
max_fpr=None:
multi_class='raise':(多分类的问题在下一篇文章中解释)
labels=None:
输出:
auc:是一个float的值。
3.举个例子
3.1数据格式:
| id | label | pred_label | pred_score | model_predict_scores |
| 1537 | 0 | 0 | 0.98361117 | [0.98361117 0.01638886] |
| 1548 | 0 | 0 | 0.9303047 | [0.9303047 0.06969527] |
| 1540 | 0 | 0 | 0.978964 | [0.978964 0.02103605] |
| 15525 | 1 | 1 | 0.9876039 | [0.01239602 0.9876039 ] |
3.2代码:
先将模型预测的结果保存到excel中,将预测结果保存为了string,导致了下面的处理稍微麻烦了一点:
# -*- encoding:utf-8 -*-
import requests, xlrd, re, xlwt, json
from collections import defaultdict
from sklearn import metrics
def calculate_auc(read_path):
workbook = xlrd.open_workbook(read_path) # 打开工作簿
sheets = workbook.sheet_names() # 获取工作簿中的所有表格
worksheet = workbook.sheet_by_name(sheets[0]) # 获取工作簿中所有表格中的的第一个表格
label = [] # 真实标签
pred = [] # 预测标签
score = [] #跟预测标签对应的模型打分
first = [] # 模型打分结果中类别0的概率,是一个n行 ,1列的数组
preds = [] # 模型的打分结果中类别1的概率,是一个n行 ,1列的数组
for i in range(0, 100):
value = worksheet.cell_value(i, 1)
value1 = worksheet.cell_value(i, 2)
label.append(int(value))
pred.append(int(value1))
score.append(float(worksheet.cell_value(i, 3)))
a = worksheet.cell_value(i, 4)
d = a.replace('[', '')
d = d.replace(']', '')
d = d.strip()
d = d.split(" ")
l = len(d)
print(' len ', l)
g = []
h = []
h.append(float(d[0]))
g.append(float(d[l - 1]))
preds.append(g)
first.append(h)
rocauc = metrics.roc_auc_score(label, score)
print('--rocauc:', rocauc)
rocauc1 = metrics.roc_auc_score(label, preds)
print('--rocauc1:', rocauc1)
rocauc0 = metrics.roc_auc_score(label, first)
print('--rocauc0:', rocauc0)
if __name__ == '__main__':
read_path = './new_two.xlsx'
calculate_auc(read_path)输出结果:
--rocauc: 0.3817052512704686
--rocauc1: 0.9390175042348956
--rocauc0: 0.06098249576510448分析:
第一个结果,是错误 的结果,这么计算没有意义,解释不通,用错了预测值 。
第二个结果是label为1的auc,这个值是大家平时说的 auc。
第三个结果是label为0的auc,平时不用,这里打印出来主要是 想验证一下,正负样本的auc和是不是1。经过验证,二者和为1。
参考:
0.官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html?highlight=roc_auc_score
1.https://blog.csdn.net/ODIMAYA/article/details/103138388