Kaggle入门第二天之tensorflow解决MNIST手写数字识别问题
目录
- 前言
- 数据集描述
- 方法
- 结论
前言
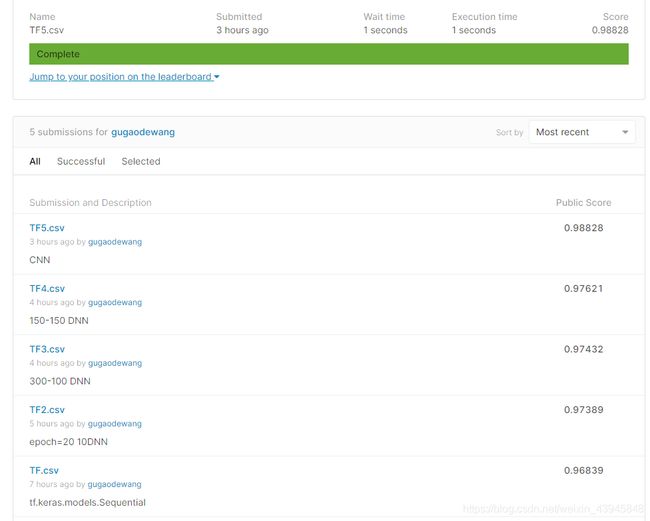
先不说别的,把今天参加digit-recognizer练习比赛的五次成绩放在这里留个纪念。第一次用tensorflow,很多基础概念也不是很了解,纯粹靠keras的API接口做出了神经网络并进行了一系列调整,还是学到了不少,写在这里并且分享给和我一样的真萌新一些经验吧。
数据集描述
作为计算机视觉机器学习领域的"Hello world",MNIST手写数字识别数据集想必大家都听说过。每个手写数字图片具有28像素的宽度和28像素的高度,总共有784个像素,每个像素都由一个在[0,255]内的数字来表示明亮程度,数字越高表示它越暗。

比如上图是一个9,你看出来了吗?
Kaggle的digit-recognizer竞赛提供给我们的Train.csv包含了其中42000条标注数据,Test.csv里面存的是不带标签的28000条数据要求我们预测标签值,即通过像素来预测是哪个数字。
Train.csv中每一条数据包含785列,其中第一列为标签列,告诉你这个数字是什么,比如第一个就是1,第二列开始到最后一列的数据为784个特征,存储了784个像素的数值(0-255)。

可能有人会想为什么都是0呢?是因为旁边都是空白,数字在图片的中央,所以非零值也集中在中间的像素列里面了,这里省略看不到。
方法
首先,如果你和我一样从来没有接触过tensorflow,虽然安装了它但是从来没有用过,我们如何来快速解决这个问题呢?有一个办法,就是看官方的示例。
在tensorflow的官网教程中有以下这么一块代码:
import tensorflow as tf
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=5)
model.evaluate(x_test, y_test, verbose=2)
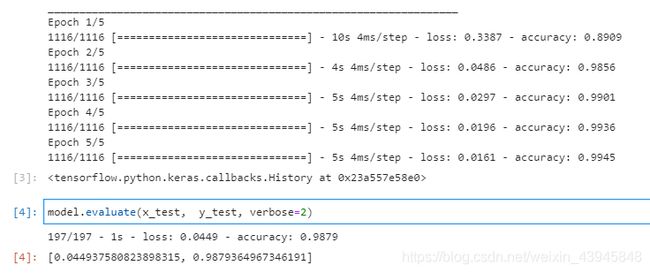
先不管它是什么,运行看看得到以下结果:
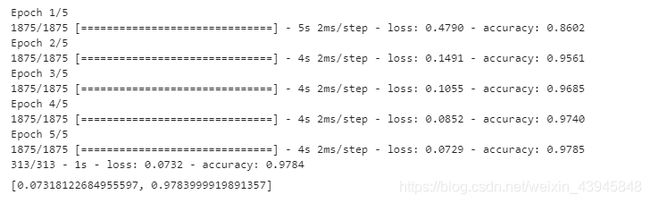
进行了五次迭代,在测试集上的准确率达到了97.8%。
效果还可以,仔细看下它的输入,其中训练集和测试集用的是mnist.load_data()自动下载的数据,那么我们只要把输入换成我们自己的Kaggle数据集,问题不就解决了吗?简单地说就是它造了一辆车,只要把车上的乘客换成我们自己的,就到达了目的地。
如何更换
首先我们来看看它的x_train是什么样子:

可以看到是一个array,具体的维度调用.shape方法可以得知:
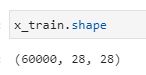
60000条28x28的数据,也就是说我们只要把读进来的数据改造成一个28x28的array就可以实现我们的需求,同理y_train的维度为(60000,),代码如下:
import pandas as pd
import numpy as np
train = pd.read_csv("/newstart/code/minist/train.csv") #读取你的文件路径得到完整的dataframe
x = train.iloc[:, 1:785].values.reshape(42000,28,28) #取除第一列外的所有像素列的值并reshape为28x28
y = train.iloc[:, 0].values.reshape(42000,) #取标签列
别忘了划分训练集和测试集,这里我们参考官方示例中6:1的比例划分:
x_train = x[0:35700]
x_test = x[35700:42000]
y_train = y[0:35700]
y_test = y[35700:42000]
x_train, x_test = x_train / 255.0, x_test / 255.0
另外为了更快速地收敛算法,我们对数据除以了255进行归一化,还记得之前我们说过像素值的范围在0到255之间吗?
接下来再把models开始的代码组装上,同时我们来看下它的具体意义:
import tensorflow as tf
#模型构建
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), #拉直层
tf.keras.layers.Dense(128, activation='relu'), #128个神经元的全连接层,激活函数选择relu
tf.keras.layers.Dropout(0.2), #正则化去除失活神经元
tf.keras.layers.Dense(10, activation='softmax') #10个神经元的输出层,激活函数选择softmax回归
])
#模型组装
model.compile(optimizer='adam', #优化层
loss='sparse_categorical_crossentropy', #损失函数选择
metrics=['accuracy']) #度量标准选择准确率
#拟合训练集
model.fit(x_train, y_train, epochs=5) #迭代次数5次,该问题上可以调至20次
#评估测试集
model.evaluate(x_test, y_test, verbose=2) #训练集上准确率到达0.99测试集也到不了0.98
总之,通过tf.keras.models.Sequential这个工具我们可以方便的构建神经网络,在其中添加各种各样的layer层,同时为了防止过拟合,我们需要在测试集上评分。
提交成绩
现在我们构建了一个神经网络,那么怎么提交我们的成绩呢?稍等,我们还没有在Kaggle给的测试集上生成结果,通过以下代码可以解决:
#读取测试集
test = pd.read_csv("/newstart/code/minist/test.csv")
#对测试集进行和之前一样的变换
X = test.values.reshape(28000,28,28)
X = X / 255
#预测
predictions = model.predict(X) #在这步之后你会得到一个28000x10的矩阵,其中一行如0,0,1,0,0,0,0,0,0,0
pre = np.argmax(predictions,axis=1) #选取其中=1的位置,1在第几个位置表示它是什么数字
#结果导出
output = pd.DataFrame({'Label': pre}) #生成标签列
output.index+=1 #将索引列+1,原来是0,1,2,3,...现在是1,2,3,4,...
output.to_csv('TF.csv', index=1,index_label='ImageId') #将索引列和标签列一起导出
最后得到了我们要提交的CSV文件:
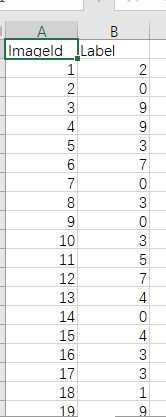
格式和下载下来的sample_submission.csv格式是一致的,上传到https://www.kaggle.com/c/digit-recognizer/就可以得到分数。
改进结果
第一次提交的分数只有0.968,很低,那么我们如何改进呢?这里有两个简单的思路,第一个,增加迭代次数,可能你的模型还可以进一步提升,毕竟我们只迭代了五次。第二个,改变你的模型,我们目前的模型的中间层只有一层128神经元的全连接层,根据书本上所说经典的mnist操作,我们可以再增加一层。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(150, activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(150, activation='relu'), #多增加了一个150神经元的中间层
tf.keras.layers.Dropout(0.2), #正则化里面的数字也是可以自己调的,本例中不宜太高
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(x_train, y_train, epochs=30) #将迭代次数设成了30,实际上在20的时候已经到达了极限
model.evaluate(x_test, y_test, verbose=2)
经过这样的调整之后,我们在Kaggle上的准确率从0.968来到了0.972,可以看到这样简单的DNN模型是有极限的,如果我们想要更进一步,最好更换模型。
在经过一番搜索之后,我们发现CNN在这个任务上的表现很不错,于是参考知乎上的一个方法搭建了以下的网络:
#使数据符合输入的要求
x_train = x_train.reshape(x_train.shape[0],28,28,1).astype('float32') #Shape为60000,28,28,1
x_test = x_test.reshape(x_test.shape[0],28,28,1).astype('float32') #Shape为10000,28,28,1
x_train = x_train / 255
x_test = x_test / 255
import tensorflow as tf
#防止爆显存停止运行,我的显卡是1660ti,在拟合CNN时,tf使用GPU加速一下子占了5个G的显存还停止了运行
config = tf.compat.v1.ConfigProto()
config.gpu_options.allow_growth = True
session = tf.compat.v1.InteractiveSession(config=config)
#模型构建
model = tf.keras.models.Sequential()
#.add方法可以用另一种形式把层添加到Sequential中
model.add(tf.keras.layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(tf.keras.layers.MaxPooling2D((2, 2)))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.Conv2D(64, (3, 3), activation='relu'))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(64, activation='relu'))
model.add(tf.keras.layers.Dense(10, activation='softmax'))
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
#输出模型报告
model.summary()
model.fit(x_train, y_train, epochs=5)
可以看到CNN的效果是强大的,最终它使我们Kaggle上的分数一下子来到了0.98828,wow!
结论
今天我们用tensorflow的kerasAPI成功解决了一个实际问题,学到了DNN和CNN的相关知识和一些基础数据处理方法以及模型的基础调整方法。
虽然我们在之前什么也不懂,但也能做出一番成果,机器学习注定是一条艰辛和孤独的路,不要害怕未知,勇敢前进,相信大家都能够成就自己的梦想。
[1]: https://www.kaggle.com/c/digit-recognizer/data
[2]: https://www.zhihu.com/question/52893753