yolov5数据集_如何使用Yolov5创建端到端对象检测器?
作者 | Rahul Agarwal
来源 | Medium
编辑 | 代码医生团队
Ultralytics最近在围绕其名称的争议中推出了YOLOv5。就上下文而言,约瑟夫·雷德蒙(Joseph Redmon)创建了YOLO(您只看一次)的前三个版本。此后,Alexey Bochkovskiy在Darknet上创建了YOLOv4,与以前的迭代相比,它拥有更高的平均精度(AP)和更快的结果。
现在,Ultralytics已发布YOLOv5,具有可比的AP和比YOLOv4更快的推理时间。这引起了很多人的疑问:是否应授予与YOLOv4相似的准确性的新版本?无论答案是什么,这绝对是检测社区发展速度的标志。
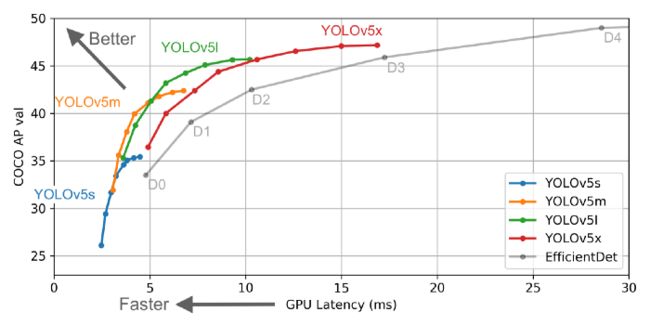
资料来源:Ultralytics Yolov5
自从首次移植YOLOv3以来,Ultralytics就使使用Pytorch创建和部署模型非常简单,所以很想尝试YOLOv5。事实证明,Ultralytics进一步简化了流程,其结果不言而喻。
在本文中,将使用YOLOv5创建检测模型,从创建数据集并对其进行注释到使用其卓越的库进行训练和推理。这篇文章重点介绍YOLOv5的实现,包括:
创建玩具数据集
注释图像数据
创建项目结构
训练YOLOv5
创建自定义数据集
如果有图像数据集,则可以放弃第一步。由于没有图像,因此正在从开放图像数据集(OID)下载数据,这是获取可用于分类和检测的带注释图像数据的绝佳资源。注意,不会使用OID提供的注释,而是为了学习而创建自己的注释。
1. OIDv4下载图片:
要从Open Image数据集下载图像,首先克隆OIDv4_ToolKit并安装所有要求。
git clone https://github.com/EscVM/OIDv4_ToolKit
cd OIDv4_ToolKit
pip install -r requirements.txt
现在可以使用main.py此文件夹中的脚本来下载图像以及多个类的标签。
下面正在下载棒球和足球的数据以创建自定义数据集。也就是说将创建一个包含足球和棒球的数据集,学习任务是检测这些球。
python3 main.py downloader --classes Cricket_ball Football --type_csv all -y --limit 500
以下命令使用以下结构创建一个名为“ OID”的目录:
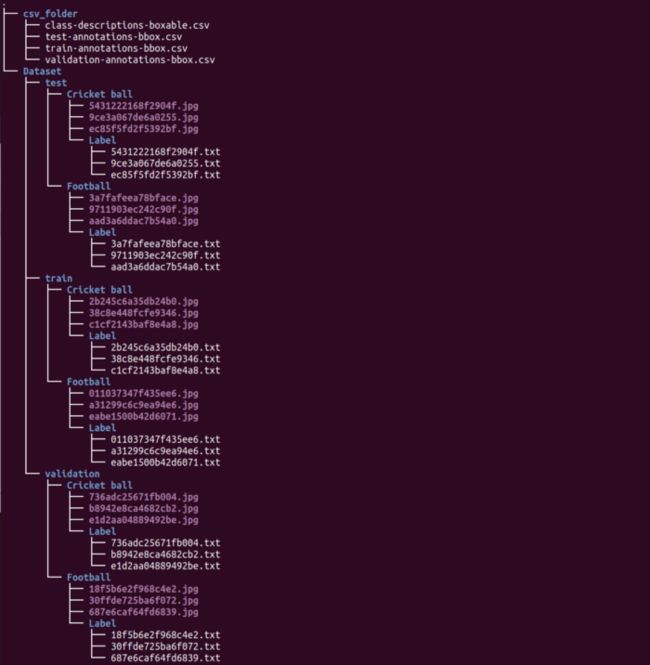
OID目录结构。将仅从此处获取图像文件(.jpgs),而不从标签中获取标签,因为将手动添加注释以创建“自定义数据集”,尽管如果不同项目需要,也可以使用它们。
在继续之前,需要复制同一文件夹中的所有图像以从头开始标签练习。可以选择手动执行此操作,但是也可以使用递归glob函数以编程方式快速完成此操作:
import os
from glob import glob
os.system("mkdir Images")
images = glob(r'OID/**/*.jpg', recursive=True)
for img in images:
os.system(f"cp {img} Images/")
2.使用HyperLabel标记图像
将使用称为Hyperlabel的工具来标记图像。过去曾使用过许多工具来创建诸如labelimg,labelbox等的批注,但从未遇到过如此简单易用且过于开源的工具。唯一的缺点是无法在Linux,Mac和Windows上使用此工具,但是想这对大多数人都很好。
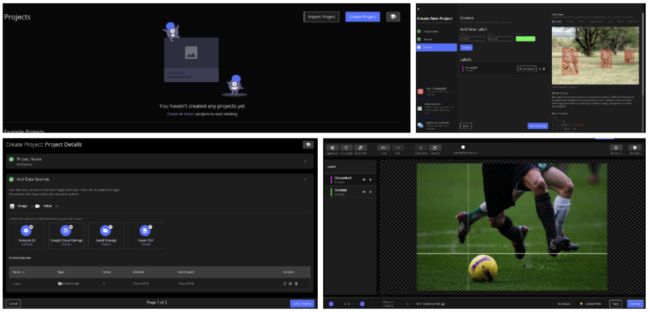
1.创建项目,2,设置标签,3.添加本地图像数据源,4.注释
该工具最好的部分是它提供的各种输出格式。由于要获取Yolo的数据,因此将关闭Yolo格式并在完成注释后将其导出。但是如果也想以JSON格式(COCO)或XML格式(Pascal VOC)获得注释,则可以选择使用此工具。

以Yolo格式导出实际上会为每个图像创建一个.txt文件,其中包含class_id,x_center,y_center,图像的宽度和高度。它还创建一个名为的文件obj.names,该文件有助于将class_id映射到该类名。例如:

图像,其注释和obj.names文件
请注意,注释文件中的坐标从0缩放到1。另外请注意,对于每个obj.names 文件,棒球的class_id为0,橄榄球为1,从0开始。使用此文件创建了一些其他文件,但在本示例中将不再使用它们。
完成此操作后,大多数情况下都将使用自定义数据集进行设置,并且在训练模型时,只需要重新排列其中一些文件即可进行后续的训练和验证拆分。当前的数据集将是一个单独的文件夹,如下所示,其中既包含图像又包含注释:
dataset
- 0027773a6d54b960.jpg
- 0027773a6d54b960.txt
- 2bded1f9cb587843.jpg
- 2bded1f9cb587843.txt
--
--
设置项目
为了训练自定义对象检测器,将使用Ultralytics的Yolov5。首先克隆存储库并安装依赖项:
git clone https://github.com/ultralytics/yolov5 # clone repo
cd yolov5
pip install -U -r requirements.txt
然后从创建自己的名为training的文件夹开始,在其中保留自定义数据集。
!mkdir training
首先将自定义数据集文件夹复制到该文件夹中,然后使用简单的train_val_folder_split.ipynb笔记本创建训练验证文件夹。下面的代码仅创建了一些train和validation文件夹,并在其中填充了图像。
import glob, os
import random
# put your own path here
dataset_path = 'dataset'
# Percentage of images to be used for the validation set
percentage_test = 20
!mkdir data
!mkdir data/images
!mkdir data/labels
!mkdir data/images/train
!mkdir data/images/valid
!mkdir data/labels/train
!mkdir data/labels/valid
# Populate the folders
p = percentage_test/100
for pathAndFilename in glob.iglob(os.path.join(dataset_path, "*.jpg")):
title, ext = os.path.splitext(os.path.basename(pathAndFilename))
if random.random() <=p :
os.system(f"cp {dataset_path}/{title}.jpg data/images/valid")
os.system(f"cp {dataset_path}/{title}.txt data/labels/valid")
else:
os.system(f"cp {dataset_path}/{title}.jpg data/images/train")
os.system(f"cp {dataset_path}/{title}.txt data/labels/train")
运行此命令后,data文件夹结构应如下所示。它应该有两个目录images和labels。

现在,必须向文件training夹添加两个配置文件:
1. Dataset.yaml:创建一个文件“ dataset.yaml”,其中包含训练和验证图像的路径以及类。
# train and val datasets (image directory or *.txt file with image paths)
train: training/data/images/train/
val: training/data/images/valid/
# number of classes
nc: 2
# class names
names: ['Cricketball', 'Football']
2. Model.yaml:创建网络时,可以使用从小到大的多种模型。例如,yolov5s.yaml目录中的yolov5/models 文件是具有7M参数的小型Yolo模型,而yolov5x.yaml具有96M Params的最大Yolo模型。对于此项目,将使用yolov5l.yaml具有50M参数的。首先将文件从复制yolov5/models/yolov5l.yaml到training文件夹,然后将更改nc,这是根据项目要求将类数更改为2的方法。
# parameters
nc: 2 # change number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
训练
此时训练文件夹如下所示:

完成上述步骤后,就可以开始训练模型了。这就像运行以下命令一样简单,在其中提供配置文件和各种其他参数的位置。可以检查train.py文件中的其他不同选项,但是这些是发现值得注意的选项。
# Train yolov5l on custom dataset for 300 epochs
$ python train.py --img 640 --batch 16 --epochs 300--data training/dataset.yaml --cfg training/yolov5l.yaml --weights ''
在那种情况下,使用以下命令在单个GPU上运行的PyTorch 1.5版可能会出错:
# Train yolov5l on custom dataset for 300 epochs
$ python train.py --img 640 --batch 16 --epochs 300--data training/dataset.yaml --cfg training/yolov5l.yaml --weights '' --device 0
开始训练后,可以通过检查自动创建的文件来检查训练是否已设置train_batch0.jpg,该文件包含第一批的训练标签,并且test_batch0_gt.jpg包括测试图像的基本情况。

左:train_batch0.jpg,右:test_batch0_gt.jpg
结果
要localhost:6006使用tensorboard在浏览器中查看训练的结果,请在另一个终端选项卡中运行此命令
tensorboard --logdir=runs
以下是各种验证指标。results.png在训练运行结束时,这些指标也会保存在文件中。

预测
Ultralytics Yolov5提供了许多不同的方法来检查新数据的结果。
要检测一些图像,可以将它们简单地放在名为文件夹中,inference/images并根据验证AP使用最佳权重来运行推理:
python detect.py --weights weights/best.pt

结果
还可以使用detect.py文件在视频中进行检测:
python detect.py --weights weights/best.pt --source inference/videos/messi.mp4 --view-img --output inference/output
在这里,指定使用— view-img标志查看输出,并将输出存储在位置推断/输出中。这将.mp4在此位置创建一个文件。令人印象深刻的是,网络可以看到球,在这里进行推理的速度以及从未观察到的数据的惊人准确性。
这是梅西
也可以通过将其指定--source为0,将网络摄像头用作来源。可以在detect.py文件中签出其他各种选项。
结论
在本文中,讨论了如何使用“自定义数据集”创建Yolov5对象检测模型。喜欢Ultralytics轻松创建对象检测模型的方式。
如果想自己尝试使用自定义数据集,则可以在Kaggle上下载带注释的数据,并在Github上下载代码。
https://www.kaggle.com/mlwhiz/detection-footballvscricketball
https://github.com/MLWhiz/data_science_blogs/tree/master/yolov5CustomData

推荐阅读
YOLOv5来了!基于PyTorch,体积比YOLOv4小巧90%,速度却超2倍