机器翻译模型五CNN+seq2seq__Pytorch实现
目录
1.CNN应用于机器翻译
1.1Encoder模块
1.2Decoder模块
2.代码实现
2.1数据准备
2.2模型构建
2.3训练
1.CNN应用于机器翻译
在深度学习中,RNN擅长处理序列数据,而CNN擅长做特征提取。我们之前的机器翻译都是采用RNN结构来翻译句子,但《Convolutional Sequence to Sequence Learning》这篇文章将CNN应用Seq2Seq模型中,并不在使用传统的串行RNN模型来预测模型,而是构造CNN卷积网络并行计算并预测结构。其论文模型如下:
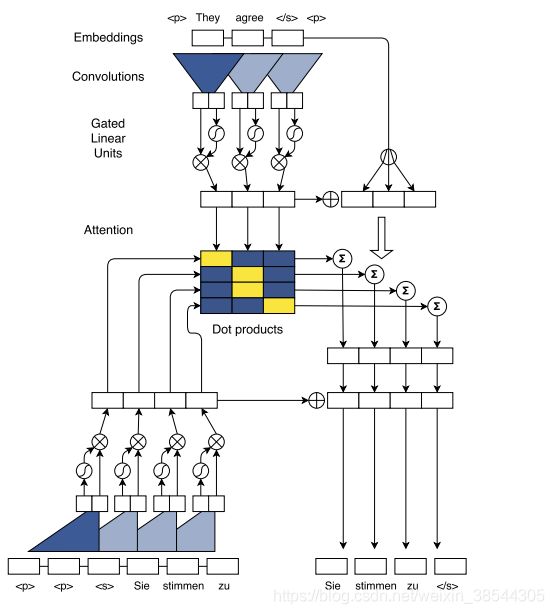
直观的看,模型十分复杂,其较之前的模型理解难度直接上升一个级别(后面难度一个比一个更难),不过其本质思想与之前的Attention+Seq2Seq是一样的,也是encoder,decoder模块以及attention模型。(上述模型是英翻得),以下我们将详细介绍各个模块。
1.1Encoder模块
Encoder模块主要对源句进行编码,使得不定⻓的输⼊序列变换成⼀个定⻓的上下文变量context,使得编码以后的源句(context向量)在特征上的表现更明显(语义,上下文),首先给出Encoder模型的模型:

以下逐层介绍:
嵌入层:在之前的RNN模型中,我们的可以直接输入一句话带入RNN模型中,不用担心其词序问题,这是因为RNN模型串行处理,其记忆单元天然具有时间序列信息。但是,在CNN卷积网络并行处理中,这种RNN具有的天然时序信息其并不具备。我们需要给每个词添加位置信息,引入我们的嵌入层包含两个,一个是词嵌入(token_embed),另外一个则是位置嵌入(pos_embed)。最后将两者求和得到带有位置编码的词嵌入(elementwis sum)。我们假设输入的src=[batch src_len emb_size]
线性层(emb_size->hid_size):在此模型中,所有线性层的功能都做维度转换的功能,在此处主要将词嵌入的维度转变为卷积层的输入维度,也可以说是隐藏层维度。即src=[batch src_len hid_size]
卷积层:卷积层是此模型的精髓,其主要承担着特征提取的功能,即提取词之间的语义,句法信息等。其一共有10层卷积块,其大致模型如下(前两层,后面类推):

(1)block块输入(输出)层:block模块的输入层为为上一层的输出,第一层则是线性层(emb_size->hid_size)的输出。即src=[batch src_len hid_size]
(2)block块padding层:在编码器中,paddding层主要是用来使得卷积以后输入输出大小相同,我们知道单纯的卷积操作会使得序列长度变小,因此在卷积操作前需要进行padding操作。如,在我们机器翻译中,总不能输入句长为4,编码以后句长为3这种情况发现。padding的大小为:(kernel_size-1)//2(在两端padding添加,所以整除2,表示每端添加的数量,进行NLP一般将kernel_size设为奇数)。 此时src=[batch src_len+kernel_size-1 hid_size]
切记:在编码器中,padding层的作用主要为控制输入输出的序列长度相同,而在解码器中,除此以外还另有他用!
(3)block块卷积:这一层的即为一维卷积操作,用于进行特征提取,提取源句中的语义信息,句法信息等。其输出的维度设置为输入的两倍(这是因为后面的激活函数为GLU),此时经过卷积以后的src=[batch src_len hid_size*2]
(4)block块GLU层:glu层是一个激活函数,其计算公式为: ![]() 。此时:src=[batch src_len hid_size]
。此时:src=[batch src_len hid_size]
(5)block块残差连接层:残差连接主要用于防止网络退化,即卷积层我们设置层10层,但是可能在4层网络就已经达到最优,即提取最佳的特征(后面继续做特征提取,粒度就过于粗糙了)。后面的6层只需要进行一个等值传递的功能即可,因此在此添加残差连接。即将GLU层的输出与输入层求和。此时得到的结果src=[batch src_len hid_size]。其为该层的输出或下一层的输出。
线性层(hid_size->emb_size):这一层的线程层主要将10层卷积块的输出进行维度转换,此时:conved=src=[batch src_len emb_size],其得到了我们的卷积向量(K)。
组合层(残差连接层):这一层的残差主要功能并非为了防止网络退化,按理说上一层的线性层(hid_size->emb_size)其已经得到了编码向量,其包含了重要的上下文信息(卷积),但是卷积以后其的原始特征就比较稀薄了,原始特征里面除了原始的词嵌入以外,还有一个特征重要的位置特征,因此将编码向量与带有位置编码的词嵌入组合(求和操作),得到组合向量(Q)。
编码器最终返回卷积向量(K)与组合向量(Q),其中卷积向量包含丰富的上下文信息,而组合向量具有更多关于特定标记的信息。若现在不理解其妙用,可继续看注意力机制层,加深对其理解。
1.2Decoder模块
Decoder模块主要对编码器输出的上下文向量进行解码,解码将其映射到新的样本空间中去,解码的长度不固定。解码的时候当然也可以有各种参考,以下给出解码器模型:
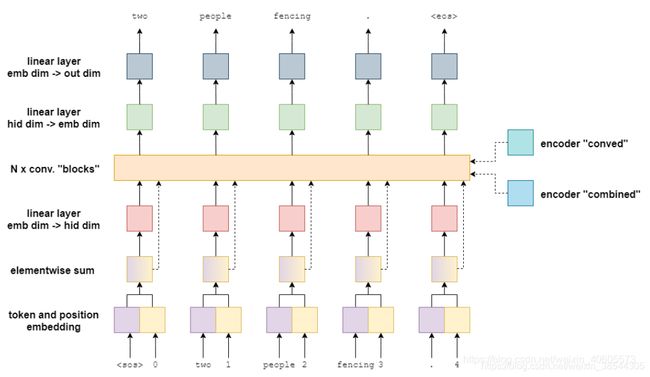
以下与编码器一样逐层介绍:
嵌入层:此层输入目标端的需要被翻译的句子,同编码中一样,也需要嵌入位置信息,最后将二者嵌入向量求和。得到trg=[batch trg_len emb_size]
线性层(emb_size->hid_size):此线性层作维度变化的功能,将嵌入维度转变为隐层维度。trg=[batch trg_len hid_size]
卷积层:此卷积层也是解码器的精髓支出所在,作用依然是特征提取,提取目标词之间语义,句法特征。其一共有10层卷积块,其大致模型如下(一层,后面类推):

(1)block块的输入层:block模块的输入层为为上一层的输出,第一层则是线性层(emb_size->hid_size)的输出,即trg=[batch trg_len hid_size]。后面则是dev_conved,维度同。
(2)block块的paddding层:在编码器中padding层的作用主要是维持输入输出的序列长度畅通,解码器中依旧有这样的功能,因此其padding的大小为(kernel_size-1)。但是不同于编码器的padding在两段操作,解码器的padding添加在句子前面,为什么需要这样呢?答案:错开正确答案,防止模型作弊。
假设我们和encoder层一样padding,如下:
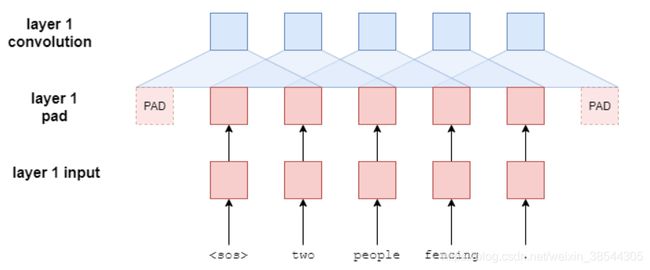
我们发现,在一个卷积视野中(假设kernel_size=3),当前词预测词的答案竟然也出现在卷积视野中,比如

经过padding以后,其trg=[batch trg_len+kernel_size-1 hid_size]。
(3)block块的卷积操作:同编码器,经过卷积操作以后使其输出维度是输入维度的两倍,此时trg=[batch trg_len 2*hid_size]
(4)block块的GLU层:同编码器,经过该激活函数以后,维度降低一半,此时trg=[batch trg_len hid_size]
(5)attention层:attention层的存在,使得卷积块不仅仅接收卷积操作经过激活函数的输出(dec_conved),还多3个变量。分别是en_conved(编码器的卷积向量),en_combined(编码器的组合向量)还有目标端带有位置信息的词嵌入信息(tokenPos_embed)。所以attention层一共接收4个变量。
我们知道attention机制的主要目的在于:够帮助decoder在生成词语时,有一个编码器上不同词语的权重参考。这其中涉及三个变量,分别是学习目标Query(查询向量),编码器中每个词经过特殊编码形成的value(值向量)以及查找每个此的key(键向量)。其计算过程如下:(其实也可以画一个类似block的图,github没找到图,自己随手画一个,很糙勿喷):
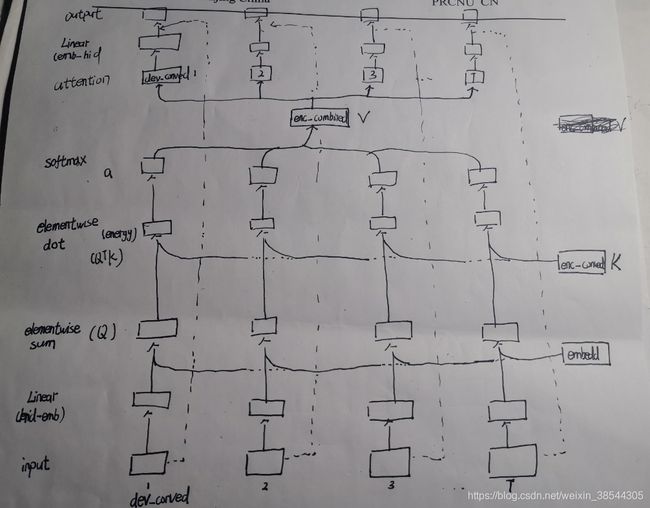
step1(Linear):接收GLU层的输出(batch trg_len hid_size),将其维度转变为嵌入维度,此时dev_conved=[batch trg_len embed_size]
step2(elementwise sum):卷积以后,其原始信息特征不在明显,将目标端原始的带位置编码的词嵌入(embedd=[batch trg_len emb_size])与dev_conved求和,强化此类特征在卷积上(我认为这样的操作使得解码器的卷积具有更多关于源端特定标记的信息,这些标记信息将更有助于与编码器的卷积向量进行匹配)。这也得到了我们的学习目标Q=[batch trg_len emb_size。
step3(elementwise dot):我们得到了学习目标以后Q,将与编码器的卷积向量enc_conved=[batch src_len emb_size](K)对应元素进行相乘(匹配),我们知道编码器的卷积向量包含许多编码器的上下文信息,这更有助于进行匹配,得到匹配能量:energy=[batch trg_len src_len]
step4(softmax):对匹配能量进行softamx,得到其编码器各个词的注意力权重a=[batch trg_len src_len]
step5(attention):有了各个词的注意力权重以后,我们通过编码器的组合向量enc_combined[batch src_len emb_size](V)进行加权求和得到最终的上下文向量context=[batch trg_len emb_size]。仔细想一个,我们在翻译的时候,是翻译词,更希望值向量包含多一点特定表征信息,因此这也是值向量选择组合向量而非卷积向量的原因,这也是组合词向量就是在原本卷积词向量基础上添加位置编码的词嵌入的原因。
step6(Liner):将其维度变为hid_size。context=[batch trg_len hid_size]
step7(输出层):与输入层初始的dev_conved=[batch trg_len hid_size]进行求和,使得context向量不仅包含解码器信息,也包含目标端翻译的前文信息。context=[batch trg_len hid_size]
所以经过attention层以后,有源端卷积激活得到的dev_conved变为context(包含源端和目标端翻译前文的信息)
(6)block块的残差连接:这一步作用其实和编码器的残差连接作用一样,防止网络退化。因此context加上block开始的输入,我们姑且称其为dev_conved,因为其也是下一层的输入。
以上block搭建10层,最后一层输出的dev_conved=[batch trg_len hid_size]
线性层(hid_size->emb_size):维度变化,将其转变为为emb_size维度,dev_conved_emb=[batch trg_len emb_size]
输出层(映射到目标端样本空间):即输出结果ouput=[batch trg_len trg_vocab_size]
至此,模型介绍完毕。其创新之处在于将CNN网络应用于Seq2Seq中,并取得的非常好的效果,下面我们将实现代码。
2.代码实现
工具:Jupyter
2.1数据准备
import torch
import spacy
from torchtext.data import Field,BucketIterator
from torchtext.datasets import Multi30kde_seq=spacy.load("de_core_news_sm")
en_seq=spacy.load("en_core_web_sm")
def de_tokenizer(text):
return [word.text for word in de_seq.tokenizer(text)]
def en_tokenizer(text):
return [word.text for word in en_seq.tokenizer(text)]SRC=Field(tokenize=de_tokenizer,
init_token="",
eos_token="",
lower=True,
batch_first=True)
TRG=Field(tokenize=en_tokenizer,
init_token="",
eos_token="",
lower=True,
batch_first=True) train_data,val_data,test_data=Multi30k.splits(exts=(".de",".en"),
fields=(SRC,TRG))
SRC.build_vocab(train_data,min_freq=2)
TRG.build_vocab(train_data,min_freq=2)batch=128
device=torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_iter,val_iter,test_iter=BucketIterator.splits(
(train_data,val_data,test_data),
device=device,
batch_size=batch
)测试:
for example in train_iter:
src=example.src
trg=example.trg
break
print(src.shape)结果:
torch.Size([128, 26])2.2模型构建
import torch.nn as nn
import torch.nn.functional as Fclass Encoder(nn.Module):
def __init__(self,src_vocab_size,emb_size,hid_size,kernel_size,n_layers,dropout=0.25,max_len=100):
#src_vocab_size 德语词库大小
#embe_size 嵌入维度
#hidden_size 卷积层的隐藏维度
#kernel_size 卷积核大小
#n_layers 卷积的block层数
super(Encoder,self).__init__()
self.token_emb=nn.Embedding(src_vocab_size,emb_size)
self.pos_emb=nn.Embedding(max_len,emb_size)
self.emb2hid=nn.Linear(emb_size,hid_size)
self.hid2emb=nn.Linear(hid_size,emb_size)
self.convs=nn.ModuleList([
nn.Conv1d(in_channels=hid_size,
out_channels=hid_size*2,
kernel_size=kernel_size,
padding=(kernel_size-1)//2)
for _ in range(n_layers)
])
self.dropout=nn.Dropout(dropout)
self.scale=torch.sqrt(torch.FloatTensor([0.5])).to(device)#其实是一个平均的过程
def forward(self, src):
#src[batch src_len]
#产生位置序列
batch_size=src.shape[0]
src_len=src.shape[1]
pos=torch.arange(0,src_len).to(device)
#pos[src_len]
pos=pos.unsqueeze(0).repeat(batch_size,1)
#pos[batch src_len]
#src[batch src_len]
src_embed=self.token_emb(src)
pos_embed=self.pos_emb(pos)
#src[batch src_len emb_size]
#pos[batch src_len emb_size]
#词嵌入添加位置编码
src_pos_embed=self.dropout(src_embed+pos_embed)
#src_pos_embed[batch src_len emb_size]
#转变维度使其进入卷积层
conv_input=self.emb2hid(src_pos_embed)
#conv_input[batch src_len hid_size]
#注:1D卷积的输入shape为:[batch input_channel seq_len],input_channel为输入维度,
# 输出shape为:[batch output_channel (seq_len+2*padding-kernel_size)/stride+1]
# 我们的padding=kernel_size-1//2(这样设计就是保住输入输出长度相同),stride=1,output_channel=2input_channel
# 因此输出:[batch 2*input_channel seq_len]
#所以首先先转变conv_input的shape
conv_input=conv_input.permute(0,2,1)
#conv_input[batch hid_size src_len]
#进入卷积层
for conv in self.convs:
conved=conv(self.dropout(conv_input))
#conved[batch hid_size*2 src_len]
#输出为2*hid_size 是为了glu激活函数,其输出的维度是输入的一半
conved=F.glu(conved,dim=1)
#conved[batch hid_size src_len]
#残差连接,防止网络退化
conved=(conved+conv_input)*self.scale
#conved[batch hid_size src_len]
#循环遍历,此卷积输出是下一次卷积的输入
conv_input=conved
#conv_input[batch hid_size src_len]
#卷积结束:
#conved[batch hid_size src_len]
#转变shape
conved=conved.permute(0,2,1)
#conved[batch src_len hid_size]
#转变维度,得到卷积向量,也是注意力机制的里面的k
conved=self.hid2emb(conved)
#conved[batch src_len emb_size]
#残差连接,得到联合向量,也是注意力机制里面的v
combined=(conved+src_pos_embed)*self.scale
#返回卷积向量和联合向量
return conved,combined测试:
src_vocab_size=len(SRC.vocab)
trg_vocab_size=len(TRG.vocab)
emb_size=256
hid_size=512
kernel_size=3
n_layers=10enModel=Encoder(src_vocab_size,emb_size,hid_size,kernel_size,n_layers).to(device)
conved,combined=enModel(src)
print(conved.shape,combined.shape)结果:
torch.Size([128, 26, 256]) torch.Size([128, 26, 256])class Attention(nn.Module):
def __init__(self,emb_size,hid_size):
#这里我默认了encoder与decoder的嵌入维度和隐层维度相同
super(Attention,self).__init__()
self.emb2hid=nn.Linear(emb_size,hid_size)
self.hid2emb=nn.Linear(hid_size,emb_size)
self.scale=torch.sqrt(torch.FloatTensor([0.5])).to(device)
def forward(self,dec_conved,embedd,en_conved,en_combined):
"""
注意力计算首先使用一个线性层改变Decoder传入的conved的隐藏维数为相同的嵌入维数。
然后,再与嵌入(embedded)通过一个残差连接求和。然后,通过发现它与编码的卷积(conved)有多少“匹配”,然后再通过对编码的组合(combined)进行加权和,
这样应用标准注意力计算。然后将其投影回隐藏的维度大小,并应用与注意力层初始输入(conved)的残差连接。
"""
#embedd[batch trg_len emb_size]
#dec_conved[batch hid_size trg_len] Q(要加上词嵌入才算真正的Q)
#en_conved[batch src_len emb_size] K
#en_combined[batch src_len emb_size] V
#转变Q的shape,使其为[batch trg_len hid_size]
dec_conved=dec_conved.permute(0,2,1)
#dec_conved[batch trg_len hid_size]
#改变其维度,使其与嵌入维度相同
dec_conved_emb=self.hid2emb(dec_conved)
#dec_conved_emb[batch trg_len emb_size]
#与embedded嵌入求和
Q=(dec_conved_emb+embedd)*self.scale
#Q[batch trg_len emb_size]
#en_conved[batch src_len emb_size] K
#计算与每个k的匹配程度
energy=torch.matmul(Q,en_conved.permute(0,2,1))
#energy[batch trg_len src_len]
a=F.softmax(energy,dim=2)
#a[batch trg_len src_len]
#en_combined[batch src_len emb_size] V
#得到权重以后计算其最终的向量
context=torch.matmul(a,en_combined)
#context[batch trg_len emb_size]
#转变维度并加上卷积初始残差
#context[batch trg_len emb_size]
#dec_conved[batch trg_len hid_size]
context=self.emb2hid(context)
#context[batch trg_len hid_size]
conved=(context+dec_conved)*self.scale
#conved[batch trg_len hid_size]
return conved.permute(0,2,1),a测试:
attModel=Attention(emb_size,hid_size).to(device)
#自己造一个dec的卷积向量
dec_conved=torch.randn(128,hid_size,26).to(device)
#自己构造一个词嵌入(带有位置信息)--trg
embedded=torch.randn(128,26,emb_size).to(device)
dec_conved,a=attModel(dec_conved,embedded,conved,combined)
print(dec_conved.shape,a.shape)结果:
torch.Size([128, 512, 26]) torch.Size([128, 26, 26])class Decoder(nn.Module):
def __init__(self,trg_vocab_size,emb_size,hid_size,kernel_size,n_layers,attnModel,dropout=0.25,max_len=50):
#trg_vocab_size 英语的词库大小
#emb_size 嵌入维度
#hid_size 隐层维度
#kernel_size 卷积核大小
#n_layers 卷积网络的层数
#attnModel 注意力机制层
super(Decoder,self).__init__()
self.attnModel=attnModel
self.kernel_size=kernel_size#要根据其在前面创建kernel-1个pad
self.token_embed=nn.Embedding(trg_vocab_size,emb_size)
self.pos_embed=nn.Embedding(max_len,emb_size)
self.emb2hid=nn.Linear(emb_size,hid_size)
self.hid2emb=nn.Linear(hid_size,emb_size)
self.fc=nn.Linear(emb_size,trg_vocab_size)
self.scale=torch.sqrt(torch.FloatTensor([0.5])).to(device)
self.convs=nn.ModuleList([
nn.Conv1d(in_channels=hid_size,
out_channels=2*hid_size,
kernel_size=kernel_size)
for _ in range(n_layers)])
self.dropout=nn.Dropout(dropout)
def forward(self,trg,en_conved,en_combined):
#trg[batch trg_len]
#en_conved[batch src_len emb_size]
#en_combined[batch src_len emb_size]
batch_size=trg.shape[0]
trg_len=trg.shape[1]
#位置编码
pos=torch.arange(0,trg_len).to(device)
#pos[trg_len]
pos=pos.unsqueeze(0).repeat(batch_size,1)
#pos[batch trg_len]
#嵌入并求和
token_embed=self.token_embed(trg)
pos_embed=self.pos_embed(pos)
#token_embed[batch trg_len emb_size]
#pos_embed[batch trg_len emb_size]
embedd=self.dropout(token_embed+pos_embed)
#pos_embed[batch trg_len emb_size]
#将embedd有emb_size维度转变为hid_size维度代入卷积层
input_conv=self.emb2hid(embedd).permute(0,2,1)
#input_conv[batch hid_size trg_len]
hid_size=input_conv.shape[1]
for _,conv in enumerate(self.convs):
input_conv=self.dropout(input_conv)
#对输入序列添加kernel_size的pad,防止翻译答案泄露
padding=torch.ones(batch_size,hid_size,self.kernel_size-1).to(device)
#padding[batch hid_size kernel_size-1]
#input_conv[batch hid_size trg_len]
pad_input_conv=torch.cat((padding,input_conv),dim=2)
#pad_input_conv[batch hid_size trg_len+kernel_size-1]
conved=conv(pad_input_conv)
#conved[batch 2*hid_size trg_len]
conved=F.glu(conved,dim=1)
#conved[batch hid_size trg_len]
conved,a=self.attnModel(conved,embedd,en_conved,en_combined)
#conved[batch hid_size trg_len],a[batch trg_len src_len]
#input_conv[batch hid_size trg_len]
#残差连接
conved=(conved+input_conv)*self.scale
#conved[batch hid_size trg_len]
#带入下一层循环
input_conv=conved
#卷积层出来后
#conved[batch hid_size trg_len]
#转变维度为emb_size
output=self.hid2emb(conved.permute(0,2,1))
#output[batch trg_len emb_size]
#映射到英语字典空间上
output=self.fc(self.dropout(output))
return output,aclass Seq2Seq(nn.Module):
def __init__(self,encoder,decoder):
super(Seq2Seq,self).__init__()
self.encoder=encoder
self.decoder=decoder
def forward(self,src,trg):
en_coved,en_combined=self.encoder(src)
output,attn=self.decoder(trg,en_coved,en_combined)
return output,attn测试:
model=Seq2Seq(enModel,deModel).to(device)
output,a=model(src,trg)
print(output.shape)结果:
torch.Size([128, 31, 5893])2.3训练
import math,time
from torch.optim import Adamdef epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secsepochs=10
clip=0.1
criterion=nn.CrossEntropyLoss(ignore_index=1)
optim=Adam(model.parameters())def train(model,data_iter,criterion,optim,clip):
model.train()
lossAll=0
for example in data_iter:
src=example.src
trg=example.trg
optim.zero_grad()
output,_=model(src,trg[:,:-1])
#output[batch trg_len-1 trg_vocab_size]
output=output.reshape(-1,trg_vocab_size)
trg=trg[:,1:].reshape(-1)
#output[batch*(trg_len-1),trg_vocab_size]
#trg[batch*(trg_ken-1)]
loss=criterion(output,trg)
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(),clip)
optim.step()
lossAll+=loss.item()
return lossAll/len(data_iter)def evaluate(model,data_iter,criterion):
model.eval()
lossAll=0
with torch.no_grad():
for example in data_iter:
src=example.src
trg=example.trg
output,_=model(src,trg[:,:-1])
#output[batch trg_len-1 trg_vocab_size]
output=output.reshape(-1,trg_vocab_size)
trg=trg[:,1:].reshape(-1)
#output[batch*(trg_len-1),trg_vocab_size]
#trg[batch*(trg_ken-1)]
loss=criterion(output,trg)
lossAll+=loss.item()
return lossAll/len(data_iter)for epoch in range(epochs):
start_time = time.time()
train_loss = train(model,train_iter,criterion,optim,clip)
valid_loss = evaluate(model,val_iter,criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')
print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')过程展示:
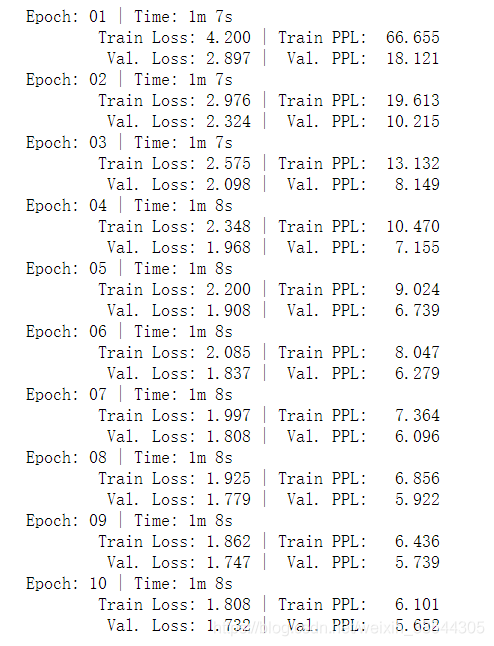
测试集评估:
test_loss = evaluate(model,test_iter,criterion)
print(f'\t Test. Loss: {test_loss:.3f} | Val. PPL: {math.exp(test_loss):7.3f}')结果:
Test. Loss: 1.811 | Val. PPL: 6.119