(5)机器学习--分类模型之决策树算法
回归:目标变量是数值型,得到方程式
分类:目标变量是分类值,可能是一个数,贝叶斯网络概率,神经网络,超平面函数
1理解模型
测量精度
基尼系数
1.1衡量指标
1.1.1熵
混杂样本中,熵是混乱程度的量度,样本集合纯度

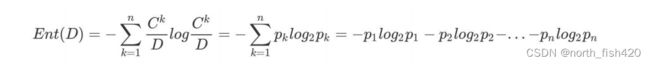
当数据量⼀致时,系统越有序,熵值越低;系统越混乱或者分散,熵值越⾼。

决策树目的:找到一个特征值,对其进行分类,然后使得纯度更高
1.1.2信息增益
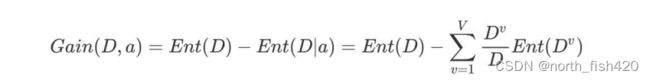

2模型训练
2.1数据集划分
三个方法:留出法、交叉验证法、自助法

2.2代码实现

3模型评估
【补充】
实证研究,一般用回归,追求影响因素,以及影响程度,只需要知道是否影响,影响程度
机器学习,判定预测的好,分为训练集和测试集,用训练集评估好,用测试集测精度
机器学习重点是评估、提高精度
经验误差:在训练集中模型的误差
泛化误差:在测试集中模型的误差
3.1过拟合与欠拟合
3.1.1定义
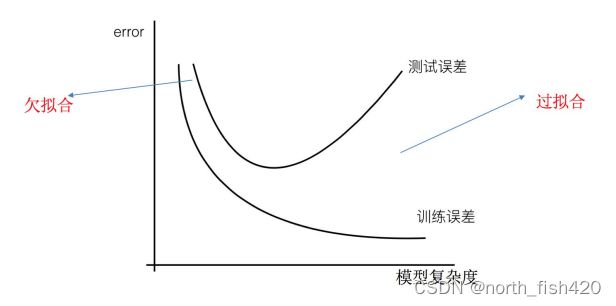
3.1.2原因及解决方法
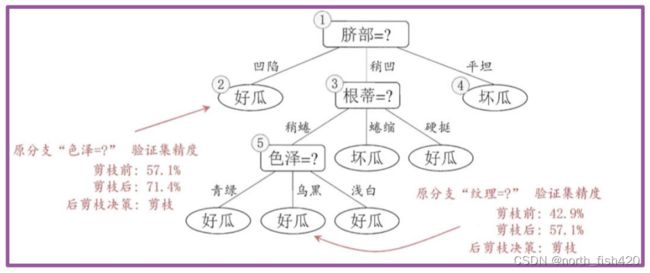
5)剪枝策略
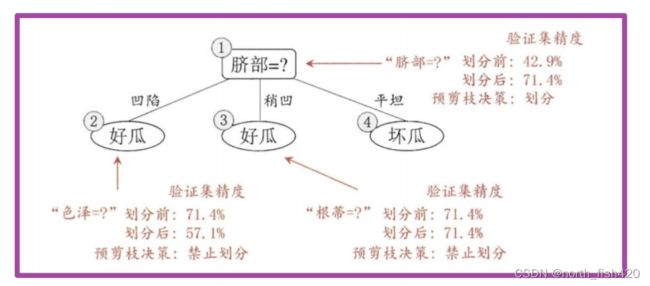
后剪枝:通过加入惩罚,叶子节点越多,损失越大
3.2精度与召回率
3.2.1混淆矩阵
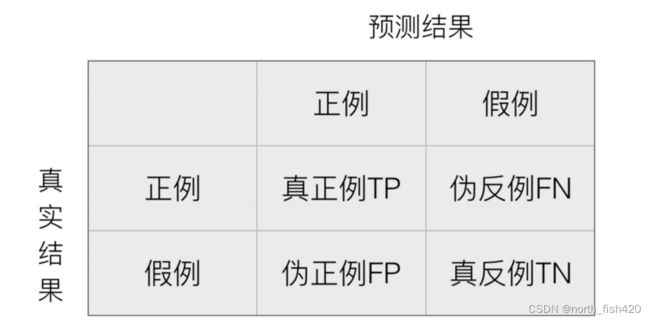
精确率:预测结果为正例样本中真实为正例的⽐例(了解)

召回率:真实为正例的样本中预测结果为正例的⽐例(查得全,对正样本的区分能⼒)

计算举例: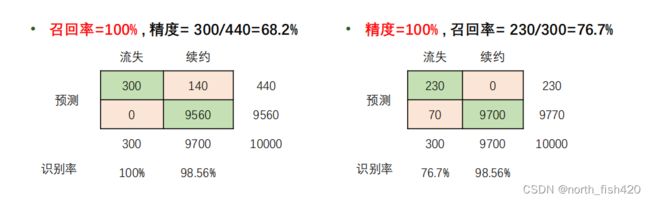
性能指标如下:


3.3ROC与AUC曲线
(32条消息) 5分钟带你学懂ROC曲线_最强理发师托尼的博客-CSDN博客_roc图
ROC曲线是TPR与FPR的函数曲线
首先,对于一个特定的学习器(模型)和一个样本,在坐标上有且仅对应一个点(一组结果),那么我们怎样得到一系列结果从而生成一个“平滑”的ROC曲线呢?
我们测试集有n个样本就可以说生成对应的点(n组结果),从而生成一个“平滑”的ROC曲线。
学习器(分类器)可以帮助我们生成预测该样本是正样本的概率,有n个样本就生成n个score值,放入列表中,将其从大到小排序,依次将各score值从大到小顺序设置为阈值(threshold),只要样本score值大于等于当前阈值则认为是正样本、否则认为是负样本。即每个阈值对应一个混淆矩阵,得到一组结果。以此类推,我们可以得到n组结果,并将其连成平滑曲线。

AUC表示ROC曲线下面积
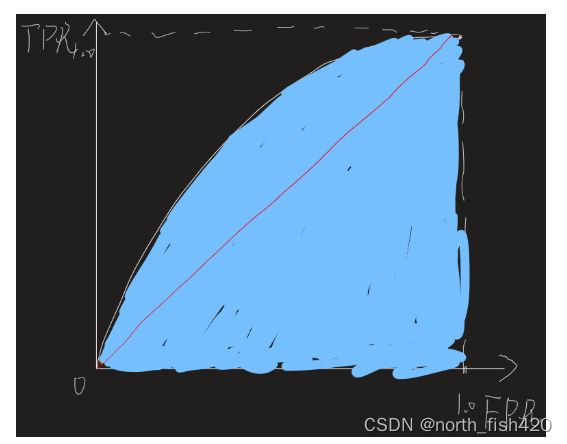

ROC曲线有一个很好的特点:在总样本中正负样本比例变化的情况下,ROC曲线能够保持很小的变化/甚至不变(证明思路是会用所有样本的threshold生成结果,样本数目足够大时,最终生成稳定曲线,笔者这里没有详细证明)。这在很多工程问题上有较好的体现,例如在新冠疫情病毒检测中,正样本数目一定远远大于负样本数目,这就体现了ROC与AUC模型泛化性能评价体系的优势。