TF-IDF词频逆文档频率算法
一.原理分析
词频逆文档频率(TF-IDF) 是一种特征向量化方法,广泛用于文本挖掘中,以反映术语对语料库中文档的重要性。用t表示术语,用d表示文档,用D表示语料库。TF(t,d) 表示术语频率是术语在文档中出现的次数,而DF(t,D)文档频率是包含术语的文档在语料库中出现的次数。如果我们仅使用术语频率来衡量重要性,那么很容易过分强调那些经常出现但几乎不包含有关文档信息的术语,例如“a”,“the”和“of”。如果术语经常出现在整个语料库中,则表示该术语不包含有关特定文档的特殊信息。逆文档频率度量的是一个术语提供了多少信息。
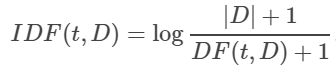
|D|表示所述语料库中的文件总数。由于使用对数,因此如果一个术语出现在所有文档中,则其IDF值将变为0。请注意,应用了平滑术语以避免对主体外的术语除以零。TF-IDF度量只是TF和IDF的乘积:
![]()
术语频率和文档频率的定义有多种变体。在MLlib中,我们将TF和IDF分开以使其具有灵活性。
TF:HashingTF和CountVectorizer均可用于生成项频率向量。
HashingTF是一个Transformer它接受一组术语并将其转换为固定长度的特征向量。在文本处理中,“一组术语”可能是一袋单词。 HashingTF利用哈希技巧。通过应用哈希函数将原始特征映射到索引(项)。这里使用的哈希函数是MurmurHash 3。然后根据映射的索引计算词频。这种方法避免了需要计算全局项到索引图的情况,这对于大型语料库可能是昂贵的,但是它会遭受潜在的哈希冲突,即哈希后不同的原始特征可能变成同一术语。为了减少冲突的机会,我们可以增加目标特征的维数,即哈希表的存储桶数。由于使用散列值的简单模来确定向量索引,因此建议使用2的幂作为特征维,否则特征将不会均匀地映射到向量索引。默认特征尺寸为2的18次方=262,144。可选的二进制切换参数控制项频率计数。当设置为true时,所有非零频率计数都设置为1。这对于模拟二进制而不是整数计数的离散概率模型特别有用。
CountVectorizer将文本文档转换为术语计数向量。
IDF是Estimator训练数据集并产生的IDFModel。所述 IDFModel需要的特征向量(通常从创建HashingTF或CountVectorizer)和缩放每个特征。从直觉上讲,它降低了经常出现在语料库中的特征的权重。
注意: spark.ml不提供文本分割工具。推荐使用斯坦福 NLP Group和 scalanlp / chalk。
二.代码案例
在下面的代码段中,从一组句子开始。使用将每个句子分成单词Tokenizer。对于每个句子(单词袋),用HashingTF将句子散列为特征向量。用IDF重新缩放特征向量;使用文本作为特征时,通常可以提高性能。然后,把特征向量传递给学习算法。
package spark2.ml
import org.apache.log4j.{Level, Logger}
import org.apache.spark.ml.feature.{IDF, Tokenizer, HashingTF}
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2020/9/18.
*/
object TF_IDF {
Logger.getLogger("org").setLevel(Level.WARN)
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder
.appName(s"${this.getClass.getSimpleName}")
.master("local[2]")
.getOrCreate()
val sentenceData = spark.createDataFrame(Seq(
(0.0, "Java Scala Spark"),
(0.0, "Scala Spark Scala Flink"),
(1.0, "Solr ES Lucene")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
wordsData.show(false)
val hashingTF = new HashingTF()
.setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
val featurizedData = hashingTF.transform(wordsData)
featurizedData.show(false)
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.show(false)
spark.stop()
}
}
三.执行结果
1.Tokenizer分词
±----±---------------------------+
|label|words |
±----±---------------------------+
|0.0 |[java, scala, spark] |
|0.0 |[scala, spark, scala, flink]|
|1.0 |[solr, es, lucene] |
±----±---------------------------+
2.TF
±----±---------------------------+
|label|rawFeatures |
±----±---------------------------+
|0.0 |(20,[5,7,10],[1.0,1.0,1.0]) |
|0.0 |(20,[5,10,17],[1.0,2.0,1.0])|
|1.0 |(20,[1,6,14],[1.0,1.0,1.0]) |
±----±---------------------------+
3.IDF
±----±-------------------------------------------------------------------------+
|label|features |
±----±-------------------------------------------------------------------------+
|0.0 |(20,[5,7,10],[0.28768207245178085,0.6931471805599453,0.28768207245178085])|
|0.0 |(20,[5,10,17],[0.28768207245178085,0.5753641449035617,0.6931471805599453])|
|1.0 |(20,[1,6,14],[0.6931471805599453,0.6931471805599453,0.6931471805599453]) |
±----±-------------------------------------------------------------------------+