用Python对淘宝用户行为数据的分析
目录
项目前言
一、分析目的
二、数据获取与理解
1.数据来源
2.理解数据
三、具体做法
1.导入并清洗数据
3.1.1.把时间戳改为datetime类型
3.1.2.查看是否存在重复的行数据
3.1.3.查看列中是否存在缺失数据
2.用户维度
3.2.1.一个月内每天pv、uv的变化
3.2.2.日ARPPU,日ARPU
3.2.3.付费率
3.2.4.复购率
3.2.5.用户行为转化漏斗图
3.2.6.用户价值RFM模型分析(RF)
3.产品维度
3.3.1.点击量top10的商品
3.3.2.购买量top10的商品
3.3.3.点击量前十的商品的购买量
3.3.4.购买量前十的点击量
4.行为维度
3.4.1.对所有用户的购买行为进行数据统计
3.4.2.每个用户对商品的不同行为的汇总
3.4.3.由不同行为导致的转化率
3.4.4.由不同行为导致的流失率
3.4.5.不同行为Top10的商品
四、总结
五、参考文献
项目前言
数据分析是要依靠使用者的具体需求从而进行进一步的分析。由于没有具体的使用者,所以该数据用作训练项目进行数据处理。本文使用anaconda中的jupyter notebook完成
一、分析目的
通过挖掘用户行为的数据价值,从而进行深度分析,最后通过可视化的方式展现出来。用来处理运营过程中所需要解决的用户需求,产品需求等。有利于优化运营策略,提升运营效率。
二、数据获取与理解
1.数据来源
阿里天池:https://tianchi.aliyun.com/dataset/dataDetail?dataId=649
2.理解数据
本数据集包含了2017年11月25日至2017年12月3日之间,有行为的约一百万随机用户的所有行为(行为包括点击、购买、加购、喜欢)。数据集的组织形式和MovieLens-20M类似,即数据集的每一行表示一条用户行为,由用户ID、商品ID、商品类目ID、行为类型和时间戳组成,并以逗号分隔。关于数据集中每一列的详细描述如下:
| 列名称 | 说明 |
|---|---|
| 用户ID | 整数类型,序列化后的用户ID |
| 商品ID | 整数类型,序列化后的商品ID |
| 商品类目ID | 整数类型,序列化后的商品所属类目ID |
| 行为类型 | 字符串,枚举类型,包括('pv', 'buy', 'cart', 'fav') |
| 时间戳 | 行为发生的时间戳 |
用户行为类型共有四种,它们分别是
| 行为类型 | 说明 |
|---|---|
| pv | 商品详情页pv,等价于点击 |
| buy | 商品购买 |
| cart | 将商品加入购物车 |
| fav | 收藏商品 |
用户行为分析思维导图:
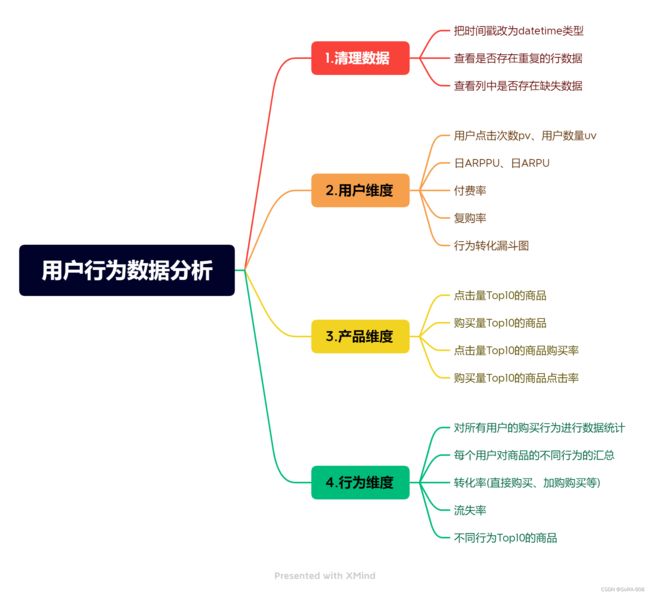
三、具体做法
1.导入并清洗数据
import numpy as np
import pandas as pd
import matplotlib as mpl
from matplotlib import pyplot as plt
import seaborn as sns
import warnings
import matplotlib.dates as mdates
from datetime import timedelta
# 有时候运行代码时会有很多warning输出,像提醒新版本之类的,如果不想这些乱糟糟的输出,可以使用如下代码
warnings.filterwarnings('ignore')
# 用来显示中文标签
mpl.rcParams["font.family"] = "SimHei"
# 用来显示负号
mpl.rcParams["axes.unicode_minus"] = False由于该数据集有上亿条数据,怕提取时内存爆炸,我在这里只提取了100w条数据
# 写入数据
df = pd.read_csv(r"D:\Desktop\淘宝用户行为数据\UserBehavior_new.csv",header=None,names=['用户id','商品ID','商品类目ID','行为类型','时间戳'])
data=df.take(indices=np.random.permutation(df.shape[0]),axis=0)[0:1000000]
data.to_csv(r"D:\Desktop\淘宝用户行为数据\UserBehavior_new01.csv")
data100w条数据中随机抽取,乱序排列

3.1.1.把时间戳改为datetime类型
把时间戳改为datetime类型会更方便后续的数据提取与分析(这边注意转化的时候很容易出错,建议先用data.head().info()检查数据类型,确保时间戳为datetime型)
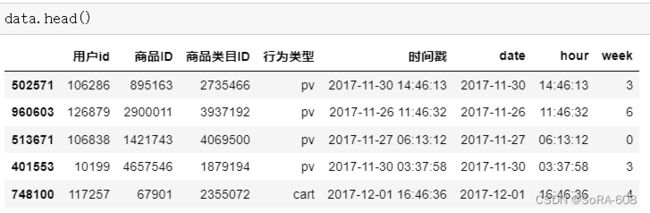
data['时间戳']=pd.to_datetime(data['时间戳'],unit='s')之后把时间戳分别调整为date(日期)、hour(时间)、week(星期)
data.时间戳=pd.to_datetime(data['时间戳'])
data['date']=data['时间戳'].dt.date
data['hour']=data['时间戳'].dt.time
data['week']=data['时间戳'].dt.weekday提取效果如下所示:
3.1.2.查看是否存在重复的行数据
(data.duplicated()).sum()3.1.3.查看列中是否存在缺失数据
data.isnull().any(axis=0)#返回true证明有缺失数据,false:没有缺失数据2.用户维度
3.2.1.一个月内每天pv、uv的变化
Q1:什么是pv、什么是uv?
pv反映的是浏览某网站的页面数,所以每刷新一次也算一次。就是说pv与来访者的数量成正比,但pv并不是页面的来访者数量,而是网站被访问的页面数量
uv反映的是实际使用者的数量,每个uv相对于每个ip更准确地对应一个实际的浏览者
d_pv=data.groupby('date').用户id.count()#groupby 里面不能用时间戳
d_uv=data.groupby('date').用户id.nunique()#date默认为字符串类型
plt.style.use('ggplot')
plt.figure(figsize=(20,18),dpi=80)
plt.subplot(611)
plt.plot(d_pv.index,d_pv.values,'bo-')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
plt.gca().xaxis.set_major_locator(mdates.DayLocator())
plt.gcf().autofmt_xdate()#自动旋转日期标记
plt.xlabel('2017-xx-xx')
plt.title('一个月内pv的变化')
plt.show()
发现大多数时间pv没有变化,于是决定缩小范围
#发现空白值过多
ex=(data['时间戳']>='2017-11-07')&(data['时间戳']<='2017-12-07')
data_new=data.loc[ex]
data_new['时间戳'].max(),data_new['时间戳'].min()(Timestamp('2017-12-03 16:00:06'), Timestamp('2017-11-10 13:33:35'))
调整过后

接下来求uv
plt.figure(figsize=(20,18),dpi=80)
plt.subplot(611)
plt.plot(d_uv.index,d_uv.values,'ro-')
plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%m/%d'))
plt.gca().xaxis.set_major_locator(mdates.DayLocator())
plt.gcf().autofmt_xdate()#自动旋转日期标记
plt.xlabel('2017-xx-xx')
plt.title('一个月内uv的变化')
plt.show() 3.2.2.日ARPPU,日ARPU
3.2.2.日ARPPU,日ARPU
Q2:什么是日ARPPU、什么是日ARPU ?
日ARPPU(Average Revenue Per Paying User),每付费用户平均收益。一天内,付费用户对产品产生的平均收入。ARPPU(每付费用户收益)=付费总额/付费用户数。通过计算公式了解到,若想提升ARPPU值,可以通过提升付费总额或者是降低付费用户数。
日ARPU (Average Revenue Per User)即每用户平均收入,衡量的是一天内运营商从每个用户所得到的收入。
日ARPPU每付费平均费用=总收入/活跃付费用户数(由于没有具体金额,所以使用消费总数代替总金额)
#每天每人消费总次数
one_user_buy1=data_new[data_new['行为类型']=='buy'].groupby(['date','用户id']).size().reset_index().rename(columns={0:'total'})
#one_user_buy1.head()
one_user_buy2=one_user_buy1.groupby('date')['total'].sum()/one_user_buy1.groupby('date')['total'].count()
plt.figure(figsize=(18,5), dpi=80)
plt.subplot(121)
one_user_buy2.plot()
plt.ylabel('平均次数')
plt.title('日ARPPU')
plt.show()#日ARPU平均每活跃用户消费次数
data_new['operation']=1
#每天不同用户不同行为类型次数
data_new_user_active1=data_new.groupby(['date','用户id','行为类型'])['operation'].count().reset_index().rename(columns={'operation':'total'})
#data_user_active.head()
plt.figure(figsize=(18,5), dpi=80)
plt.subplot(122)
data_user_active2=data_new_user_active1.groupby('date').apply(lambda x: x[x.行为类型 =='buy'].total.sum()/len(x.用户id.unique()))
data_user_active2.plot()
plt.ylabel('平均次数')
plt.title('日ARPU')
plt.show()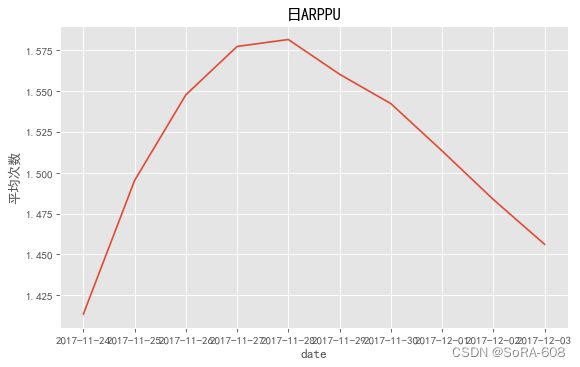
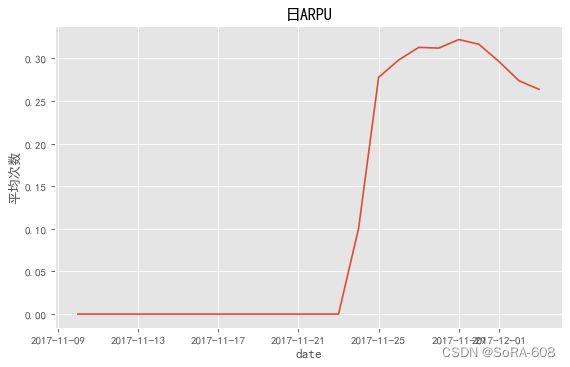
发现从2017-11-24开始至2017-12-03日,日ARPPU与日ARPU都呈现先升高后降低的趋势。可预测是12月份有促销活动,吸引大批用户来购买商品。
3.2.3.付费率
#付费率
buy_rate=data_new_user_active1.groupby('date').apply(lambda x:x[x.行为类型=='buy'].total.count()/len(x.用户id.unique()))
buy_rate.plot()
plt.ylabel('付费率')
plt.title('付费率')
plt.show()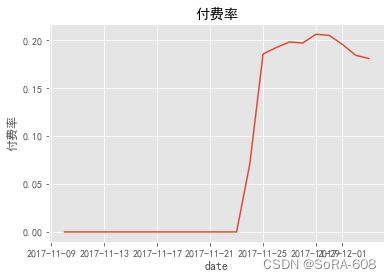
3.2.4.复购率
re_buy1=data_new[data_new.行为类型=='buy'].groupby('用户id')['date'].apply(lambda x:len(x.unique()))
re_buy2=re_buy1[re_buy1>=2].count()/re_buy1.count()
re_buy2所得结果为:
0.5528479593362237
用户会有一半的几率再次购买
1)复购时间消费间隔
re_day_buy=data_new[data_new.行为类型=='buy'].groupby('用户id').date.apply(lambda x: x.sort_values()).diff(1).dropna()
re_day_buy=re_day_buy.map(lambda x: abs(x.days))
df1= re_day_buy.value_counts()
plt.figure(figsize=(15,5))
X=df1.index
Y=df1.values
plt.bar(range(len(X)),Y,tick_label=X,color='g',width=0.5)
font={'size':18,}
plt.ylabel('数量',font)
plt.xlabel('复购间隔时间(天)',font)
plt.xticks(fontsize=10)
plt.yticks(fontsize=15)
plt.legend()
plt.title('复购时间间隔分布',fontsize=18)
plt.show()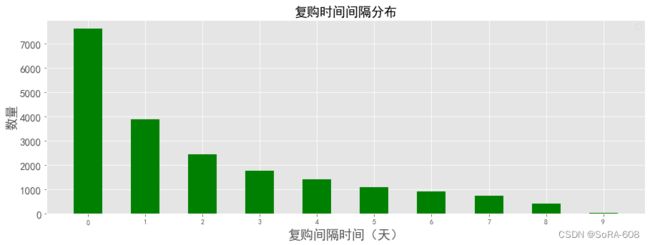
大部分人的复购时间间隔都是在7天内,随着消费时间间隔的增大,消费人数也在随之减少,因此可以考虑把营销重点放在复购率在7天内的客户
2)同一时间段用户消费的分布
samedt_user_buy=data_new[data_new['行为类型']=='buy'].groupby(['用户id','date','hour'])['operation'].sum()
df2= samedt_user_buy.value_counts()
plt.figure(figsize=(15,5))
X=df2.index
Y=df2.values
plt.bar(range(len(X)),Y,tick_label=X,color='g',width=0.5)
font={'size':18,}
plt.ylabel('数量',font)
plt.xlabel('复购次数',font)
plt.xticks(fontsize=10)
plt.yticks(fontsize=15)
plt.legend()
plt.title('复购频率分布',fontsize=18)
plt.show()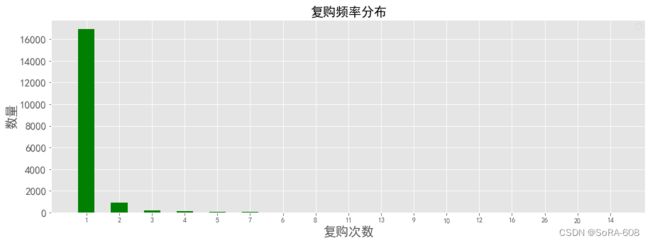 由图可得,大部分的人的消费次数都在4次以内,因此可以重点关注大于4次消费的客户。
由图可得,大部分的人的消费次数都在4次以内,因此可以重点关注大于4次消费的客户。
3.2.5.用户行为转化漏斗图
from pyecharts import options as opts
from pyecharts.charts import Funnel
from pyecharts.faker import Faker
pv_users = data[data.行为类型 == 'pv']['用户id'].count()
fav_users = data[data.行为类型== 'cart']['用户id'].count()
cart_users = data[data.行为类型== 'fav']['用户id'].count()
buy_users = data[data.行为类型 == 'buy']['用户id'].count()
attr = ['pv', 'cart', 'fav', 'buy']
values = [np.around((pv_users / pv_users * 100), 2),
np.around((cart_users / pv_users * 100), 2),
np.around((fav_users / pv_users * 100), 2),
np.around((buy_users / pv_users * 100), 2)]
c = (
Funnel()
.add(
series_name="环节",
data_pair=[list(z) for z in zip(attr,values)],
sort_="descending", # 数据排序显示顺序,降序
label_opts=opts.LabelOpts(font_size=13,position="right",formatter="{b}"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="用户行为转化漏斗",subtitle="图中的比例表示该行为下的总行为次数占浏览行为总次数的比例"))
.render("用户行为转化漏斗.html")
)
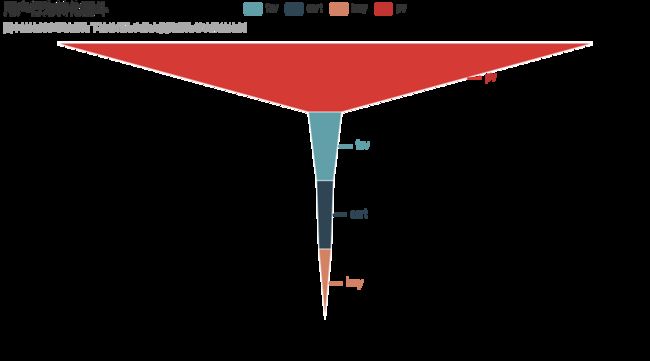 从pv-cart/fav-buy的转化率为:2.27%。可以看出浏览到加入购物车或收藏这一环节的用户流失率较大。
从pv-cart/fav-buy的转化率为:2.27%。可以看出浏览到加入购物车或收藏这一环节的用户流失率较大。
3.2.6.用户价值RFM模型分析(RF)
用户分群方法一:RFM
RFM是依据R(Recency,最近一次消费时间间隔)、F(Frequency,一段时间内的消费频次)、M(Monetary,一段时间内的消费金额)三个用户行为指标的数据组合,实现用户分层的一种工具方法,应用于对用户进行精准化/差异化营销。
RFM指标的用户分类规则:
运营以钱为中心,所以针对RFM的三个指标表现出来的“高”和“低”,通过两大维度来给用户分层:
(1)重要性维度:我们可以根据用户的消费金额区分其价值重要性,消费金额高则是我们需要优先花费人力物力去维护的“重要”客户;而消费低的客户则归为“一般”客户。
(2)策略维度:剩余两个R和F行为指标,我们可以归纳出四个类型
- RF均高(最近消费,且消费频次高),则为价值用户,需提供VIP
- R高,F低(最近有消费,但消费频次低),则为深耕用户,需刺激消费频次
- R低,F高(最近无消费,但频次高),则为召回用户,说明潜在流失,需要刺激消费
- RF均低(最近无消费,且频次低),则为挽留用户,实际为流失客户
| R-最近消费 | F-消费频次 | M-消费金额 | 用户分类 | 运营策略 |
| 高 | 高 | 高 | 1-重要价值用户 | 保持好现状 |
| 高 | 低 | 高 | 2-重要深耕用户 | 刺激其消费频率 |
| 低 | 高 | 高 | 3-重要召回用户 | 留住此客户 |
| 低 | 低 | 高 | 4-重要挽留用户 | 留住并刺激消费 |
| 高 | 高 | 低 | 5-一般价值用户 | 刺激消费力度 |
| 高 | 低 | 低 | 6-一般深耕用户 | 刺激消费力度和频率 |
| 低 | 高 | 低 | 7-一般召回用户 | 留住并刺激消费力度 |
| 低 | 低 | 低 | 8-一般挽留用户 | 各方面进行刺激 |
#RFM分析(假设现在是2017,12,1)
from datetime import datetime
#最近一次购买距离现在的天数
data['date']=pd.to_datetime(data['date'])
recent_buy=data[data.行为类型=='buy'].groupby('用户id')['date'].apply(lambda x: datetime(2017,12,1)-x.sort_values().iloc[-1]).reset_index().rename(columns={'date':'recent'})
recent_buy.recent=recent_buy.recent.map(lambda x: x.days)
#购买频率(购买次数)
fred_buy=data[data.行为类型=='buy'].groupby('用户id').date.count().reset_index().rename(columns={'date':'fred'})
#rfm
recent_fred=pd.merge(recent_buy,fred_buy,on='用户id')
#为实现自动细分,将使用R和F变量的80%分位数
quantiles=recent_fred.quantile(q=[0.8])
recent_fred['R']=np.where(recent_fred['recent']<=int(quantiles.recent.values),2,1)#R(Recency,最近一次消费时间间隔):指用户上一次消费距今多长时间
recent_fred['F']=np.where(recent_fred['fred']<=int(quantiles.fred.values),1,2)#F(Frequency,消费频率):指用户在一段时间内消费的次数
recent_fred['rfm']=recent_fred.R.map(str)+recent_fred.F.map(str) #M(Monetary,消费金额):指用户一段时间内的消费金额
#打标签,时间越近次数越多越重要
labels = {'12':'流失客户','22': '明星客户','11':'次要客户','21':'新客户'}
recent_fred['labels']= recent_fred['rfm'].apply(lambda x: labels[x])
rfm=pd.DataFrame(recent_fred['labels'].value_counts())
plt.figure(figsize=(10,7))
#print(rfm._values) 发现是个二维数组
#rfm._values=sum(rfm._values,[])
print(rfm.values) #报错:can't set attribute
plt.pie([4488,1164,1000,37],autopct='%1.1f%%',labels=rfm.index,explode=[0.05,0,0,0],colors=['red','yellowgreen','gold','orange'])
plt.legend()
plt.axis('equal')
plt.title('客户类群占比',fontsize=18)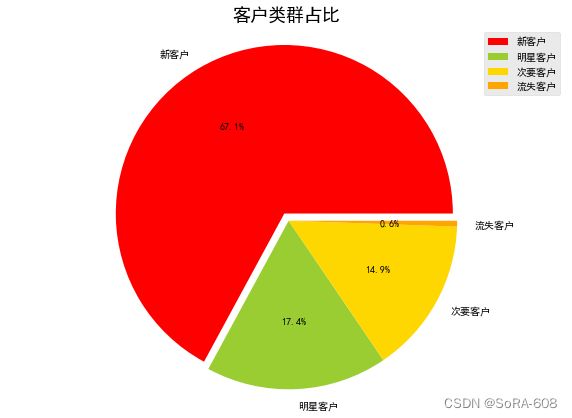
由图中可见,流失客户量较少,说明大部分用户会在期间定期购物,新客户占67.15%的大部分,
用户分群方法二:
基于RFM模型的K-Means算法(由于缺少金额数据,这里用RF分析聚类)
用轮廓系数和肘方法找出最优K值
# 用户质量RFM聚类分析(基于消费行为特征聚类分析)
from sklearn.cluster import KMeans
from sklearn import metrics
import matplotlib.pyplot as plt
from sklearn import preprocessing
#准备数据
recent_fred.用户id = recent_fred.用户id.astype('str')
X = recent_fred.values[:,1:3]
# 数据标准化(z_score)
Model = preprocessing.StandardScaler()
X = Model.fit_transform(X)
ss_score = []
inertia = []
for k in range(2,10):
clf = KMeans(n_clusters=k,max_iter=1000)
pred = clf.fit_predict(X)
ss = metrics.silhouette_score(X,pred)
ss_score.append(ss)
inertia.append(clf.inertia_)
# 做图对比
fig = plt.figure()
ax1 = fig.add_subplot(121)
plt.plot(list(range(2,10)),ss_score,c='b')
plt.title('轮廓系数')
ax1 = fig.add_subplot(122)
plt.plot(range(2,10),inertia,marker='o')
plt.xlabel('number of clusters')
plt.ylabel('distortions')
plt.title('inertia')
plt.show() 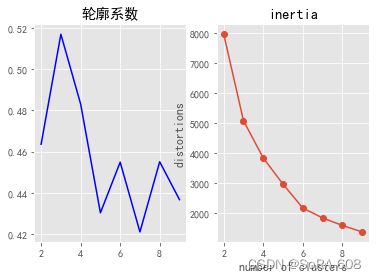
轮廓系数越接近于1越好,肘方法inertia出现明显拐点。
# 根据最佳的K值,聚类得到结果
model = KMeans(n_clusters=4,max_iter=1000)
model.fit_predict(X)
recent_fred['type']=model.labels_
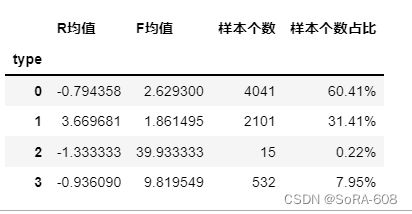
rf_type=recent_fred.drop(['R','F','rfm','labels'],axis=1,inplace=False)
r=rf_type.groupby('type').mean()
r['样本个数']=rf_type['type'].value_counts()
r['样本个数占比']=r['样本个数']/rf_type['type'].count()
r['样本个数占比']=r['样本个数占比'].map(lambda x: '%.2f%%'%(x*100))
r.columns=[['R均值','F均值','样本个数','样本个数占比']]
r
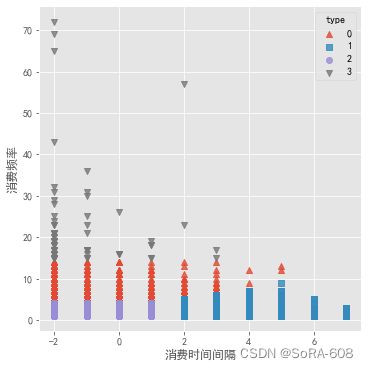
#可视化聚类结果
plt.style.use('ggplot')
# 四个簇的簇中心
#centers = model.cluster_centers_
# 绘制聚类效果的散点图
sns.lmplot(x = 'recent', y = 'fred', hue = 'type', markers = ['^','s','o','v'],data =rf_type, fit_reg = False, scatter_kws = {'alpha':0.8}, legend_out = False)
#plt.scatter(centers[:,0],centers[:,1], marker = '*', color = 'black', s = 130)
plt.xlabel('消费时间间隔')
plt.ylabel('消费频率')
# 图形显示
plt.show()
3.产品维度
3.3.1.点击量top10的商品
#分析出每个用户对商品的不同行为
one_hot_df=pd.get_dummies(df['行为类型'])
user_item_behavior_df=pd.concat((df[['用户id','商品ID']],one_hot_df),axis=1)#对两张表进行横向拼接
pv_sum_item_10_s=user_item_behavior_data.groupby(by='商品ID')['pv'].sum().sort_values().tail(10)
pv_sum_item_10_s
3.3.2.购买量top10的商品
#购买量前十的商品
buy_sum_item_10_s=user_item_behavior_df.groupby(by='商品ID')['buy'].sum().sort_values().tail(10)
buy_sum_item_10_s
3.3.3.点击量前十的商品的购买量
#计算点击量前十的商品的购买量
pv_10_buy=[]
for index in pv_sum_item_10_s.index:
buy_count=user_item_behavior_df.loc[user_item_behavior_df['商品ID']==index]['buy'].sum()
dic={
'商品ID':index,
'购买量':buy_count
}
pv_10_buy.append(dic)
pv_10_buy
3.3.4.购买量前十的点击量
#购买量前十的点击量
buy_10_pv=[]
for index in buy_sum_item_10_s.index:
pv_sum=user_item_behavior_df.loc[user_item_behavior_df['商品ID']==index]['pv'].sum()
dic={
'商品ID':index,
'点击量':pv_sum
}
buy_10_pv.append(dic)
buy_10_pv 
4.行为维度
3.4.1.对所有用户的购买行为进行数据统计
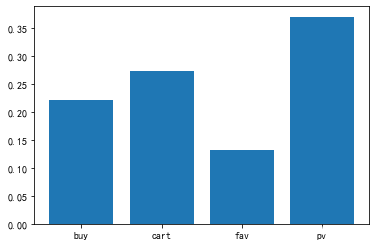
#对所有用户的购买行为进行数据统计,求得不同购买行为的百分比柱状图
s_percent=df.groupby(by='行为类型')['用户id'].nunique()/df.groupby(by='行为类型')['用户id'].nunique().sum()
plt.bar(s_percent.index,s_percent.values)结果以柱状图的形式展现
3.4.2.每个用户对商品的不同行为的汇总
#对用户分组(考虑用户的重复情况)
pv_sum=user_item_behavior_df.groupby(by='用户id')['pv'].sum()
buy_sum=user_item_behavior_df.groupby(by='用户id')['buy'].sum()
cart_sum=user_item_behavior_df.groupby(by='用户id')['cart'].sum()
fav_sum=user_item_behavior_df.groupby(by='用户id')['fav'].sum()
user_behavior_total_df=pd.DataFrame(data=[pv_sum,buy_sum,cart_sum,fav_sum]).T#.T为转置
user_behavior_total_df.head()| 用户id | pv | buy | cart | fav |
|---|---|---|---|---|
| 1 | 55.0 | 0.0 | 0.0 | 0.0 |
| 100 | 84.0 | 8.0 | 0.0 | 6.0 |
| 1000 | 67.0 | 0.0 | 2.0 | 12.0 |
| 10001 | 21.0 | 0.0 | 0.0 | 0.0 |
| 100002 | 84.0 | 1.0 | 0.0 | 7.0 |
3.4.3.由不同行为导致的转化率
1)直接购买转化率:点击——购买/点击量
首先求#所有用户的总点击量
user_behavior_total_df['pv'].sum()再求出#点击——购买行为统计
user_behavior_total_df.query('pv>0 & cart==0 & fav==0 & buy>0').shape[0]可得直接购买转化率:
buyvert=user_behavior_total_df.query('pv>0 & cart==0 & fav==0 & buy>0').shape[0]/user_behavior_total_df['pv'].sum()0.0004451368795904741
依次类推
2)加购购买转化率:点击——加购+购买/点击——加购
#点击——加购行为统计
user_behavior_total_df.query('pv>0 & cart>0 & fav==0 & buy==0').shape[0]
#点击——加购——购买
user_behavior_total_df.query('pv>0 & cart>0 & fav==0 & buy>0').shape[0]
cartvert=user_behavior_total_df.query('pv>0 & cart>0 & fav==0 & buy>0').shape[0]/user_behavior_total_df.query('pv>0 & cart>0 & fav==0 & buy==0').shape[0]2.133
3)收藏购买转化率:点击——收藏——购买/点击——收藏
#点击——收藏
user_behavior_total_df.query('pv>0 & cart==0 & fav>0 & buy==0').shape[0]
#点击——收藏——购买
user_behavior_total_df.query('pv>0 & cart==0 & fav>0 & buy>0').shape[0]
favvert=user_behavior_total_df.query('pv>0 & cart==0 & fav>0 & buy>0').shape[0]/user_behavior_total_df.query('pv>0 & cart==0 & fav>0 & buy==0').shape[0]1.0
4)加购收藏购买转化率:点击——收藏+加购——购买/点击——收藏+加购
#点击——收藏+加购
user_behavior_total_df.query('pv>0 & cart>0 & fav>0').shape[0]
#点击——收藏+加购——购买
user_behavior_total_df.query('pv>0 & cart>0 & fav>0 & buy>0').shape[0]
cartfavbuyvert=user_behavior_total_df.query('pv>0 & cart>0 & fav>0 & buy>0').shape[0]/user_behavior_total_df.query('pv>0 & cart>0 & fav>0').shape[0]0.6190476190476191
3.4.4.由不同行为导致的流失率
流失率:点击——流失/点击量
#点击——流失
user_behavior_total_df.query('pv>0 & cart==0 & fav==0 & buy==0').shape[0]
#所有用户的总点击量
user_behavior_total_df['pv'].sum()
lose=user_behavior_total_df.query('pv>0 & cart==0 & fav==0 & buy==0').shape[0]/user_behavior_total_df['pv'].sum()0.0008902737591809482
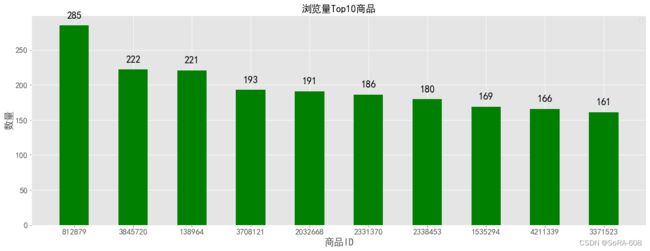
3.4.5.不同行为Top10的商品
#不同行为top10的商品
plt.figure(figsize=(20,7))
product_1= data[data.行为类型 == 'pv']['商品ID'].value_counts().head(10) # 商品统计
X=product_1.index
Y=product_1.values
plt.bar(range(len(X)),Y,tick_label=X,color='g',width=0.5)
for x,y in enumerate(Y):
plt.text(x,y+10,y,ha='center',fontsize=18)
font={'size':18,}
plt.ylabel('数量',font)
plt.xlabel('商品ID',font)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.legend()
plt.title('浏览量Top10商品',fontsize=18)
plt.show()
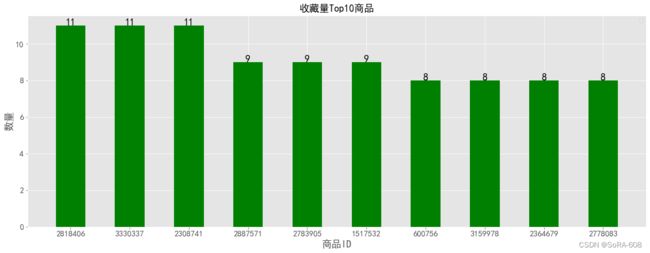
plt.figure(figsize=(20,7))
product_3= data[data.行为类型 == 'fav']['商品ID'].value_counts().head(10)
X=product_3.index
Y=product_3.values
plt.bar(range(len(X)),Y,tick_label=X,color='g',width=0.5)
for x,y in enumerate(Y):
plt.text(x,y,y,ha='center',fontsize=18)
font={'size':18,}
plt.ylabel('数量',font)
plt.xlabel('商品ID',font)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.legend()
plt.title('收藏量Top10商品',fontsize=18)
plt.show()
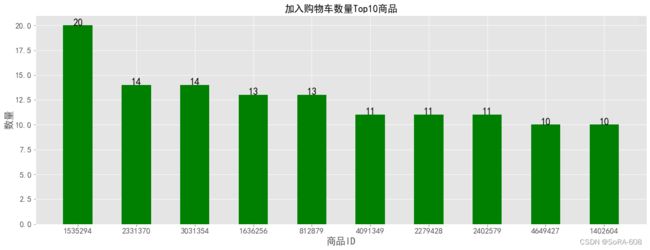
plt.figure(figsize=(20,7))
product_2= data[data.行为类型 == 'cart']['商品ID'].value_counts().head(10)
X=product_2.index
Y=product_2.values
plt.bar(range(len(X)),Y,tick_label=X,color='g',width=0.5)
for x,y in enumerate(Y):
plt.text(x,y,y,ha='center',fontsize=18)
font={'size':18,}
plt.ylabel('数量',font)
plt.xlabel('商品ID',font)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.legend()
plt.title('加入购物车数量Top10商品',fontsize=18)
plt.show()
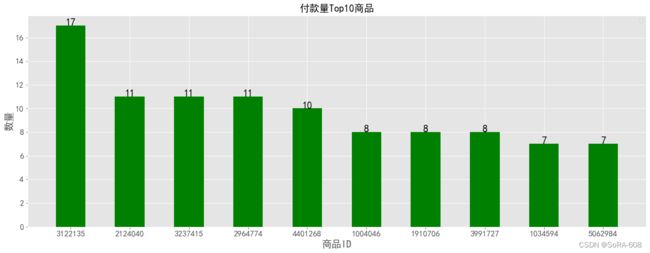
plt.figure(figsize=(20,7))
product_4= data[data.行为类型 == 'buy']['商品ID'].value_counts().head(10)
X=product_4.index
Y=product_4.values
plt.bar(range(len(X)),Y,tick_label=X,color='g',width=0.5)
for x,y in enumerate(Y):
plt.text(x,y,y,ha='center',fontsize=18)
font={'size':18,}
plt.ylabel('数量',font)
plt.xlabel('商品ID',font)
plt.xticks(fontsize=15)
plt.yticks(fontsize=15)
plt.legend()
plt.title('付款量Top10商品',fontsize=18)
plt.show()结果以柱状图的形式体现
 四、总结
四、总结
1.对热销和爆款的产品和商品类目可以通过公众号、抖音等新媒体进行引流展示。
2.十一月底至十二月初商品销量呈现快速增长状态,商家可以好好利用该时间段考虑增加优惠活动、,提高买家购买的积极性。
3.大部分人的复购时间间隔在7天以下,消费频次在4天以下。可重点关注复购时间间隔在七天以内,消费频率不低于4次的客户。
4.从pv-cart/fav-buy的转化率为:2.27%。可以看出浏览到加入购物车或收藏这一环节的用户流失率较大,考虑是否有产品不符合消费者需求或详情界面没有消费者想要了解的情况信息,需要对其中的原因进行进一步的挖掘。
5.对各TOP10产品进行对比分析,可用预测模型推测用户较为喜欢的商品。
五、参考文献
http://t.csdn.cn/hSXao
https://www.zhihu.com/question/49439948/answer/2597495757