机器学习:决策树算法(ID3算法)的理解与实现
机器学习:决策树算法(ID3算法)的理解与实现
文章目录
- 机器学习:决策树算法(ID3算法)的理解与实现
-
- 1.对决策树算法的理解
-
- 1.概述
- 2.算法难点
-
- 选择最优划分属性
-
- 1.信息熵
- 2.信息增益
- 2.使用sklearn实现ID3算法构建西瓜分类决策树:
-
-
- 1.创建txt数据集
- 2.python实现
-
1.对决策树算法的理解
1.概述
1.分类决策树模型是一种描述对实例进行分类的树形结构。 决策树由结点和有向边组成。结点有两种类型:内部结点和叶 节点。内部结点表示一个特征或属性,叶节点表示一个类。决策树学习的目的是为了产生一个泛化能力强的决策树,用来预测未知事例。
2.经典的决策树算法有ID3、C4.5、CART、RF等,由于本人是初学者,所以以下示例由ID3展开
ID3作为一种经典的决策树算法,是基于信息熵来选择最佳的测试属性,其选择了当前样本集中具有最大信息增益值的属性作为测试属性。
样本集的划分则依据了测试属性的取值进行,测试属性有多少种取值就能划分出多少的子样本集;同时决策树上与该样本集相应的节点长出新的叶子节点。
ID3算法根据信息论理论,采用划分后样本集的不确定性作为衡量划分样本子集的好坏程度,用“信息增益值”度量不确定性——信息增益值越大,不确定性就更小,这就促使我们找到一个好的非叶子节点来进行划分。
2.算法难点
选择最优划分属性
由于样本通常都是具有多个属性的,要使构建出的决策树尽可能简洁,即使分支节点包含的类别尽量少,要选定其中的一个较能满足上述条件的属性来作为一个结点,然后再依次下分,所以优先选用哪个属性就是一个难点。
在ID3算法中,利用信息增益来选择属性的最优划分,某个属性的信息增益越大,意味着用这个属性进行划分所获得的分支节点更少。因此,优先选择信息增益最大的属性来划分。
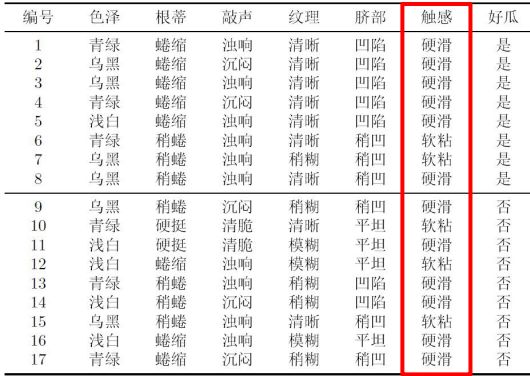
让我们用以下所示例的表格的为数据,来了解一下信息增益以及其相关概念及计算方法:
1.信息熵
“信息熵”是度量样本集合纯度最常用的一种指标,假定 当前样本集合D中第k类样本所占的比例为 pk (K=1, 2, …, |y|) ,则D的信息熵定义为
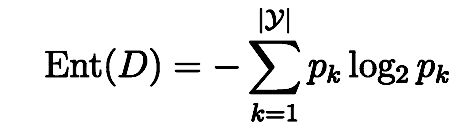
2.信息增益
使用属性a对样本集D进行划分所获得的“信息增益”的计算方法是,用样本集的总信息熵减去属性a的每个分支的信息熵与权重(该分支的样本数除以总样本数)的乘积
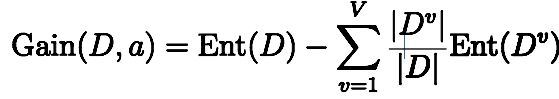
以上述数据的属性“色泽”为例,它有3个取值{青绿、乌黑、浅白}
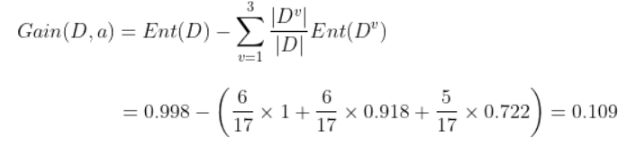
按此可计算出其他属性的信息增益,然后每个分支中再次计算剩下属性的信息增益,循环构建出决策树。
2.使用sklearn实现ID3算法构建西瓜分类决策树:
1.创建txt数据集
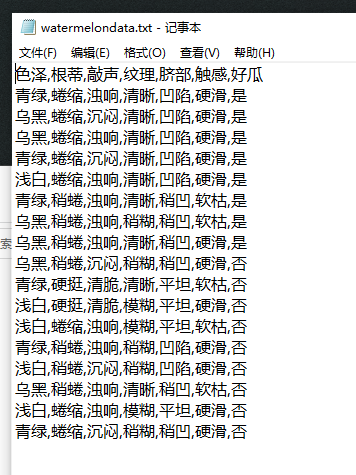
2.python实现
1.导包
import graphviz
import numpy as np
import pandas as pd
from sklearn import tree
2.读取数据集
data = pd.read_csv('F:\work\机器学习\code\watermelondata.txt')
data.head(10)
3.将特征值转化成整形
data['色泽']=data['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
data['根蒂']=data['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
data['敲声']=data['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
data['纹理']=data['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
data['脐部']=data['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
data['触感'] = np.where(data['触感']=="硬滑",1,2)
data['好瓜'] = np.where(data['好瓜']=="是",1,0)
4.读入特征与标签,开始训练
x_train=data[['色泽','根蒂','敲声','纹理','脐部','触感']]
y_train=data['好瓜']
print(data)
Tree=tree.DecisionTreeClassifier(criterion='entropy')
Tree=Tree.fit(x_train,y_train)
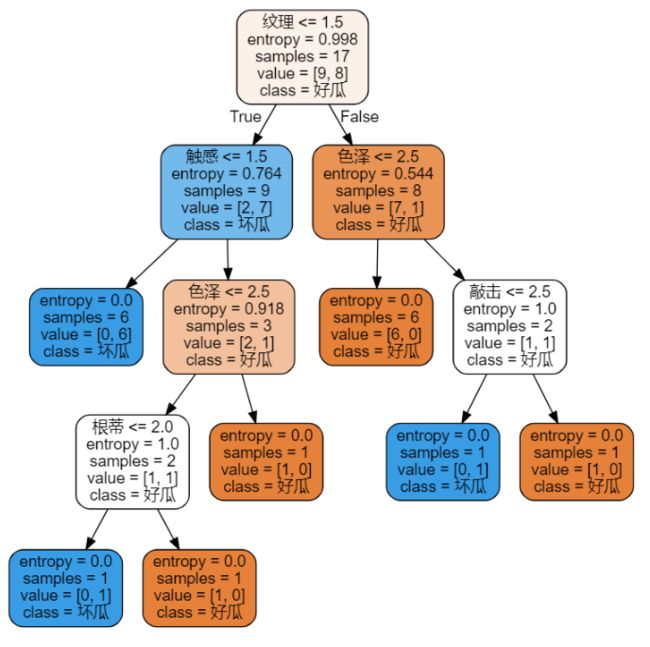
5.用graphviz绘制树的结构图
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
dot_data = tree.export_graphviz(Tree,feature_names=labels,class_names=["好瓜","坏瓜"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph.render('graph', view=True)
在此之前需要手动安装Graphviz,并将其添加到系统的PATH中,然后在python中pip 安装Graphviz的依赖包,才可以使用绘图功能
Graphviz下载地址:Download | Graphviz
安装教程:Graphviz安装及使用-决策树可视化 - 知乎 (zhihu.com)
同时有可能出现汉字显示乱码问题,解决教程:python graphviz中文乱码
6.完整代码
import graphviz
import numpy as np
import pandas as pd
from sklearn import tree
data = pd.read_csv('F:\work\机器学习\code\watermelondata.txt')
data.head(10)
data['色泽']=data['色泽'].map({'浅白':1,'青绿':2,'乌黑':3})
data['根蒂']=data['根蒂'].map({'稍蜷':1,'蜷缩':2,'硬挺':3})
data['敲声']=data['敲声'].map({'清脆':1,'浊响':2,'沉闷':3})
data['纹理']=data['纹理'].map({'清晰':1,'稍糊':2,'模糊':3})
data['脐部']=data['脐部'].map({'平坦':1,'稍凹':2,'凹陷':3})
data['触感'] = np.where(data['触感']=="硬滑",1,2)
data['好瓜'] = np.where(data['好瓜']=="是",1,0)
x_train=data[['色泽','根蒂','敲声','纹理','脐部','触感']]
y_train=data['好瓜']
print(data)
Tree=tree.DecisionTreeClassifier(criterion='entropy')
Tree=Tree.fit(x_train,y_train)
# print(Tree)
labels = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
dot_data = tree.export_graphviz(Tree,feature_names=labels,class_names=["好瓜","坏瓜"],filled=True,rounded=True)
graph = graphviz.Source(dot_data)
graph.render('graph', view=True)
7.运行结果及绘制的效果图: