tensorRT:入门
TensorRT简介
tensorRT的核心是c++运行库,这个运行库能大大提高网络在gpu上的推理(inference)速度。tensorflow、caffe、pytorch等训练框架更关注网络设计的灵活性,tensorRT能弥补其运行速度的缺陷。tensorRT专门关注对训练好的网络如何优化,以更快的生成结果。
一些训练框架,比如tensorflow,已经集成了tensorRT。另外,tensorRT可以作为运行库供用户调用。
TensorRT包含三部分:
- 模型解析器 parser
- c++ API
- Python API
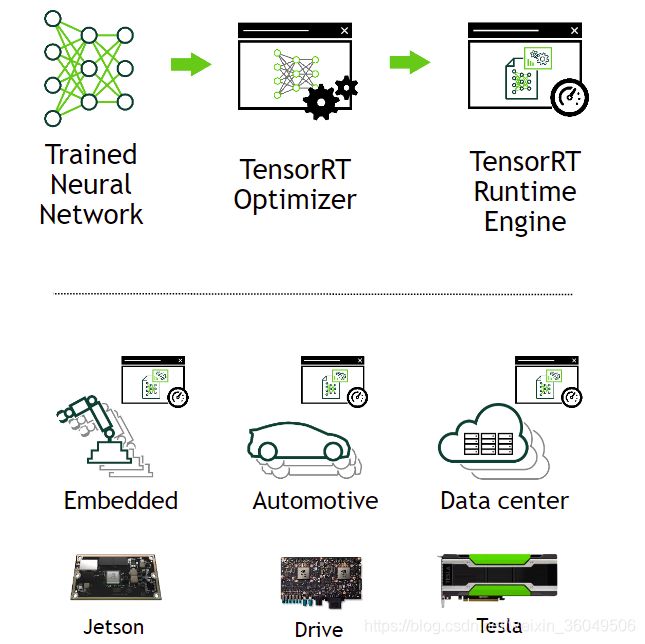
TensorRT通过组合多个层和优化内核的选择来优化网络,改善延迟(latency),吞吐量(throughput),能效(power efficiency)和内存消耗(memory consumption)。另外在程序中可以指定以半精度(fp16)或整数(int8)方式运行。
TensorRT API包括最常见的深度学习layers的实现。 有关layers的更多信息,请参见TensorRT Layers。 您还可以使用C ++ plugin API或Python plugin API为TensorRT不支持的不常用或更具创新性的layers提供实现。
基于tensorRT的深度学习模型系统开发和部署
一般来说,开发和部署一个深度学习模型需要三步:
- 训练
- 开发解决方案
- 部署解决方案
阶段一:训练
在训练阶段,首先明确要解决的问题,确定输入输出和损失函数,标注数据集。然后设计网络结构训练模型。训练时监视学习过程,根据网络表现修改损失函数、添加或修改数据集,验证模型性能并保存训练过的模型。训练和验证通常使用tensorflow、pytorch等框架,使用gpu进行。
阶段二:开发解决方案
1.这一阶段将利用训练好的模型,创建解决方案并验证。
考虑神经网络是在更大的系统中的哪一部分,并设计和实施适当的方案。包含模型的系统千差万别,可能是自动驾驶系统、视频安全系统、设备的语音接口、生产线的自动化质量保证系统、提供产品推荐的在线零售系统等等。
确定优先事项。在设计时需要考虑很多因素:
a. 网络模型的数量及结构(并行还是级联),或是根据终端用户的数据得到最终模型
b. 运行网络的设备
c. 数据如何到达模型,相机、传感器还是网络
d. 进行哪些预处理? 什么格式输入,图像是否需要裁剪、旋转;文本是哪一字符集
e. 对吞吐量和时延的需求
f. 是否可以多个请求并行处理
g. 是否需要多个网络的实例来一起批处理
h. 如何处理网络的输出
i. 需要哪些后续的步骤
2.定义解决方案的体系结构、确定了优先级之后,可以使用tensorRT从保存的网络模型中构建推理引擎(build inference engine)。根据训练框架和网络结构,可以有多种方式执行此操作。通常使用onnx解析器、uff解析器等。
3.解析网络之后,还需要考虑一些优化设置:
- batchsize大小
- 工作空间(workspace)大小
- 混合精度(mixed precision)
在tensorRT构建步骤中选择并指定了这些选项。
4.使用tensorRT创建inference engine后,需要验证它是否可以重现训练过程中测得的模型结果。如果选择了fp32或fp16,则它应与结果非常接近。如果选择了int8,则在训练过程中获得的准确度(accuracy)与推理准确度之间可能有一些差距。
5.序列化输出inference engine,也叫plan file。
阶段三:部署解决方案
tensorRT库将链接到部署应用程序中,部署应用程序将在需要推断结果时调用tensorRT库。要初始化engine,应用程序将首先将plan file中的模型反序列化为engine。
tensorRT通常异步(asynchronously)使用,因此,当输入数据到达时,程序将调用入队函数(enqueue function)写入输入缓冲区(input buffer)。同时,tensorRT会将推断结果放入输出缓冲区,像下面这样:
net.doInference(inputData.data(), outputData.get());
tensorRT如何工作
为了优化inference engine,tensorRT会采用对网络执行组合层的优化、针对平台特定优化等一系列优化,并生成inference engine。这一过程成为build phase,在这一过程中会花费大量的时间,尤其是在嵌入式平台。因此,typical 应用只会build engine once,结果保存为plan file供以后使用。
注意:生成的plan file不能跨平台或跨tensorRT版本移植。plan特定于其所构建的指定gpu模型。
build phase 对layer graph 执行以下优化:
Elimination of layers whose outputs are not used 消除输出没有被使用的层
Elimination of operations which are equivalent to no-op 消除对于输入输出无变化的运算
Fusion of convolution, bias and ReLU operations 融合卷积,偏置和relu层到一个层
Aggregation of operations with sufficiently similar parameters and the same source tensor (for example, the 1x1 convolutions in GoogleNet v5’s inception module) 聚合相似运算
Merging of concatenation layers by directing layer outputs to the correct eventual destination.
融合cancatenation层
builder还可以修改权重的精度。 当生成8位整数精度的网络时,它使用称为calibration的过程来确定中间激活层的动态范围,从而确定用于量化的适当缩放因子。
此外,build phase还会在虚拟数据(dummy data )上运行各层,以从其内核目录中选择最快的文件,并在适当的情况下执行权重预格式化(pre-formatting)和内存优化。
查看更多Working With Mixed Precision
tensorRT提供了什么能力
TensorRT使开发人员能够导入,校准,生成和部署优化的网络。 网络可以直接从Caffe导入,也可以通过UFF或ONNX格式从其他框架导入。 也可以通过实例化各个layer并直接设置参数和权重以编程方式创建它们。
用户还可以使用Plugin interface通过TensorRT运行自定义layer。 GraphSurgeon utility提供了将TensorFlow节点映射到TensorRT中的自定义layer的功能,从而可以使用TensorRT对许多TensorFlow网络进行推理。
TensorRT在所有支持的平台上提供C ++实现,并在x86,aarch64和ppc64le上提供Python实现。
TensorRT provides a C++ implementation on all supported platforms, and a Python implementation on x86, aarch64, and ppc64le.
TensorRT核心库中的关键接口是:
- Network Definition 网络定义
The Network Definition interface provides methods for the application to specify the definition of a network. Input and output tensors can be specified, layers can be added, and there is an interface for configuring each supported layer type. As well as layer types, such as convolutional and recurrent layers, and a Plugin layer type allows the application to implement functionality not natively supported by TensorRT. For more information about the Network Definition, see Network Definition API.
网络定义接口为应用程序提供了指定网络定义的方法。 可以指定输入和输出张量,可以添加层,并且有一个用于配置每种支持的层类型的接口。 和layer types一样,像卷积层和循环层等层,以及Plugin层类型都允许应用程序实现TensorRT本身不支持的功能。
有关网络定义的更多信息,请参见网络定义API。 - Builder 构建器
The Builder interface allows creation of an optimized engine from a network definition. It allows the application to specify the maximum batch and workspace size, the minimum acceptable level of precision, timing iteration counts for autotuning, and an interface for quantizing networks to run in 8-bit precision. For more information about the Builder, see Builder API.
Builder界面允许根据网络定义创建优化的引擎。 它允许应用程序指定最大批处理和工作空间大小,最小可接受的精度级别,用于自动调整的定时迭代计数以及用于量化网络以8位精度运行的接口。 有关Builder的更多信息,请参见Builder API。 - Engine 引擎
The Engine interface allows the application to execute inference. It supports synchronous and asynchronous execution, profiling, and enumeration and querying of the bindings for the engine inputs and outputs. A single engine can have multiple execution contexts, allowing a single set of trained parameters to be used for the simultaneous execution of multiple batches. For more information about the Engine, see Execution API.
Engine接口允许应用程序执行推理。 它支持同步和异步执行,性能分析(profiling)以及枚举和查询引擎输入和输出的绑定。 单个引擎可以具有多个执行上下文,从而允许将一组训练好的参数用于同时执行多个批次。 有关引擎的更多信息,请参见Execution API。
TensorRT provides parsers for importing trained networks to create network definitions:
TensorRT提供了解析器,用于导入经过训练的网络以创建网络定义:
- Caffe Parser
This parser can be used to parse a Caffe network created in BVLC Caffe or NVCaffe 0.16. It also provides the ability to register a plugin factory for custom layers. For more details on the C++ Caffe Parser, see NvCaffeParser or the Python Caffe Parser.
该解析器可用于解析在BVLC Caffe或NVCaffe 0.16中创建的Caffe网络。 它还提供了为自定义layer 注册到plugin factory的功能。 有关C ++ Caffe解析器的更多详细信息,请参见NvCaffeParser或Python Caffe解析器。 - UFF Parser
This parser can be used to parse a network in UFF format. It also provides the ability to register a plugin factory and pass field attributes for custom layers. For more details on the C++ UFF Parser, see NvUffParser or the Python UFF Parser.
该解析器可用于解析UFF格式的网络。 它还提供了注册插件工厂并为自定义层传递字段属性的功能。 有关C ++ UFF解析器的更多详细信息,请参见NvUffParser或Python UFF解析器。 - ONNX Parser
This parser can be used to parse an ONNX model. For more details on the C++ ONNX Parser, see NvONNXParser or the Python ONNX Parser.
该解析器可用于解析ONNX模型。 有关C ++ ONNX解析器的更多详细信息,请参见NvONNXParser或Python ONNX解析器。
Restriction: Since the ONNX format is quickly developing, you may encounter a version mismatch between the model version and the parser version. The ONNX Parser shipped with TensorRT 5.1.x supports ONNX IR (Intermediate Representation) version 0.0.3, opset version 9.
Note: Additionally, some TensorRT Caffe and ONNX parsers and plugins can be found on GitHub.
限制:由于ONNX格式正在快速开发中,因此您可能会遇到模型版本与解析器版本之间的版本不匹配的情况。 TensorRT 5.1.x随附的ONNX解析器支持ONNX IR(中间表示)版本0.0.3,操作集版本9。
注意:此外,可以在GitHub上找到一些TensorRT Caffe和ONNX解析器和插件。