【SLAM基础入门】贝叶斯滤波、卡尔曼滤波、粒子滤波笔记(4)
文章目录
-
-
- 第七部分:粒子滤波PF
-
第七部分:粒子滤波PF
-
应用:处理非线性函数f和h,用于电池电量估算,视频跟踪,封闭环境导航gmapping。
-
大数定律:设X为随机变量,E(X)存在,对X采样(做n次随机试验),试验结果记为 x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn,则有 lim n → ∞ P ( ∣ 1 n ∑ i x i − E ( X ) ∣ < ϵ ) = 1 \lim \limits_{n\to \infin} P(|\frac{1}{n}\sum \limits_i x_i-E(X)|<\epsilon)=1 n→∞limP(∣n1i∑xi−E(X)∣<ϵ)=1
当n足够大时,均值收敛于期望, 1 n ∑ i x i ≈ E ( X ) = ∫ − ∞ ∞ x f ( x ) d x \frac{1}{n}\sum \limits_i x_i \approx E(X)=\int _{-\infin}^\infin xf(x)dx n1i∑xi≈E(X)=∫−∞∞xf(x)dx。
狄拉克函数: ∫ c d f ( x ) δ ( x − a ) = f ( a ) , a ∈ [ c , d ] \int _c^df(x)\delta(x-a)=f(a), a\in [c,d] ∫cdf(x)δ(x−a)=f(a),a∈[c,d],将一个函数收缩成一个点。
1 n ∑ i x i = 1 n ( x 1 + x 2 + . . . + x n ) \frac{1}{n}\sum \limits_i x_i=\frac{1}{n}(x_1+x_2+...+x_n) n1i∑xi=n1(x1+x2+...+xn), x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn为数,是可以排序的。则设 − ∞ < x 1 < a 1 < x 2 < a 2 < x 3 < . . . < x n < + ∞ -\infin
即 x 1 = ∫ − ∞ a 1 x δ ( x − x 1 ) d x x_1=\int _{-\infin}^{a_1}x\delta(x-x_1)dx x1=∫−∞a1xδ(x−x1)dx, x n = ∫ a n − 1 + ∞ x δ ( x − x n ) d x x_n=\int ^{+\infin}_{a_{n-1}}x\delta(x-x_n)dx xn=∫an−1+∞xδ(x−xn)dx
⇒ 1 n ∑ i x i = 1 n ( ∫ − ∞ a 1 + ∫ a 1 a 2 + . . . + ∫ a 1 + ∞ ) = 1 n ∫ − ∞ + ∞ x [ ∑ i δ ( x − x i ) ] d x = ∫ − ∞ ∞ x f ( x ) d x \Rightarrow \frac{1}{n} \sum \limits_i x_i=\frac{1}{n} (\int_{-\infin}^{a_1}+\int_{a_1}^{a_2}+...+\int_{a_1}^{+\infin})=\frac{1}{n} \int_{-\infin}^{+\infin}x[\sum \limits_i \delta(x-x_i)]dx=\int_{-\infin}^\infin xf(x)dx ⇒n1i∑xi=n1(∫−∞a1+∫a1a2+...+∫a1+∞)=n1∫−∞+∞x[i∑δ(x−xi)]dx=∫−∞∞xf(x)dx,其中 f ( x ) f(x) f(x)是X的PDF。
由大数定律,当$n \to \infin , , ,f(x)\approx \frac{1}{n} \sum \limits_i \delta(x-x_i)$,狄拉克函数是非常容易积分的。即大数定律暗示了概率密度可以用一堆带权重的粒子来近似(采样)。

缺点:需要大量粒子。
如何用少量粒子表示pdf

-
在概率密度大的地方升高得快一点:引入权重,让少量粒子有较高的权重。权重 1 n → w i \frac{1}{n}\to w_i n1→wi
f ( x ) ≈ ∑ i 1 n δ ( x − x i ) ⇒ ∑ i w i δ ( x − x i ) f(x)\approx \sum \limits_i \frac{1}{n} \delta(x-x_i) \Rightarrow \sum \limits_i w_i \delta(x-x_i) f(x)≈i∑n1δ(x−xi)⇒i∑wiδ(x−xi), ∑ i w i = 1 \sum \limits_i w_i =1 i∑wi=1
-
粒子的数量、位置和权重完全决定了 pdf, x 1 , . . . , x n x_1,...,x_n x1,...,xn是样本,权重 w i = 1 / n w_i=1/n wi=1/n
- 位置影响
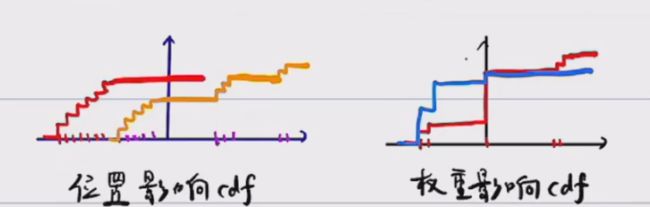
+ 权重影响:原则——pdf大的, w i w_i wi高
-
处理方法
- 比例分配权重: w i = f ( x i ) f ( x 1 ) + f ( x 2 ) + f ( x 3 ) w_i=\frac{f(x_i)}{f(x_1)+f(x_2)+f(x_3)} wi=f(x1)+f(x2)+f(x3)f(xi),满足归一化 ∑ w i = 1 \sum w_i=1 ∑wi=1
- 大粒子数:也可以 w i = 1 / n w_i=1/n wi=1/n,但是n要足够大(50个以上)
- 综合:大粒子数,且 w i = f ( x i ) ∑ i f ( x i ) w_i=\frac{f(x_i)}{\sum \limits_i f(x_i)} wi=i∑f(xi)f(xi)
-
贝叶斯滤波中的粒子滤波:
设 x 0 x_0 x0的pdf为 f 0 ( x ) f_0(x) f0(x),在 f 0 ( x ) f_0(x) f0(x)中采了n个样本。
如何采样:假设 X 0 X_0 X0是一个正态分布,采集到样本 x 0 ( 1 ) , x 0 ( 2 ) , . . . , x 0 ( n ) x_0^{(1)},x_0^{(2)},...,x_0^{(n)} x0(1),x0(2),...,x0(n),设 f 0 ( x ) = ∑ i w 0 ( i ) δ [ x − x 0 ( i ) ] f_0(x)=\sum \limits_i w_0^{(i)} \delta[x-x_0^{(i)}] f0(x)=i∑w0(i)δ[x−x0(i)], w 0 ( i ) w_0^{(i)} w0(i)可以为 1 / n 1/n 1/n也可以按比例分配。
贝叶斯滤波:
-
f 0 ( x ) = ∑ i w i δ [ x − x 0 ( i ) ] f_0(x)=\sum \limits_i w_i \delta[x-x_0^{(i)}] f0(x)=i∑wiδ[x−x0(i)]
-
f 1 − ( x ) = ∫ − ∞ + ∞ f Q [ x − f ( v ) ] f 0 ( v ) d v = ∑ i w i f Q [ x − f ( x 0 ( i ) ) ] f_1^-(x)=\int _{-\infin}^{+\infin}f_Q[x-f(v)]f_0(v)dv=\sum \limits_i w_if_Q [x-f(x_0^{(i)})] f1−(x)=∫−∞+∞fQ[x−f(v)]f0(v)dv=i∑wifQ[x−f(x0(i))],概率分布由一堆粒子近似,多个正态分布按照权重进行叠加。
-
f 1 + ( x ) = η f R [ y − h ( x ) ] f 1 − ( x ) f^+_1(x)=\eta f_R[y-h(x)]f^-_1(x) f1+(x)=ηfR[y−h(x)]f1−(x)
到这一步已无狄拉克函数无法无穷积分,且很难采样
解决办法:
-
通过 f 1 − ( x ) f^-_1(x) f1−(x)生成一堆粒子,理论上 f 1 − ( x ) = ∑ i w i f Q [ x − f ( x 0 ( i ) ) ] f^-_1(x)= \sum \limits_i w_if_Q [x-f(x_0^{(i)})] f1−(x)=i∑wifQ[x−f(x0(i))]也可以采样,也可以计算出新的权重w。
-
假设 Q ∼ N ( 0 , Q ) Q\sim N(0,Q) Q∼N(0,Q)则, f Q [ x − f ( x 0 ( i ) ) ] ∼ N ( f ( x 0 ( i ) ) , Q ) f_Q[x-f(x_0^{(i)})]\sim N(f(x_0^{(i)}),Q) fQ[x−f(x0(i))]∼N(f(x0(i)),Q) ,则下面要对这一堆概率密度进行采样(找到独立事件)
-
对预测 f 1 − ( x ) f_1^-(x) f1−(x)做傅里叶变换, N ( f ( x o ( i ) ) , Q ) → F . T e i f ( x 0 ( i ) ) t − Q t 2 / 2 = e i f ( x 0 ( i ) ) t e − Q t 2 / 2 N(f(x_o^{(i)}),Q)\mathop{\to} \limits^{F.T} e^{if(x_0^{(i)})t-Qt^2/2}=e^{if(x_0^{(i)})t}e^{-Qt^2/2} N(f(xo(i)),Q)→F.Teif(x0(i))t−Qt2/2=eif(x0(i))te−Qt2/2
-
对两个拆分出来的独立事件做傅里叶逆变换
- e i f ( x 0 ( i ) ) t → I . F . T δ ( x − f ( x 0 ( i ) ) ) e^{if(x_0^{(i)})t}\mathop{\to } \limits^{I.F.T} \delta(x-f(x_0^{(i)})) eif(x0(i))t→I.F.Tδ(x−f(x0(i))),是必然事件 X = f ( x 0 ( i ) ) X=f(x_0^{(i)}) X=f(x0(i))时的概率密度
- e − Q t 2 / 2 → I . F . T N ( 0 , Q ) e^{-Qt^2/2} \mathop{\to } \limits^{I.F.T} N(0,Q) e−Qt2/2→I.F.TN(0,Q),是Q的概率密度
-
定理:若X的pdf为f,Y的pdf为g,X,Y独立,则 Z = X + Y Z=X+Y Z=X+Y的 p d f = f ∗ g pdf = f*g pdf=f∗g,设Z的概率密度为h,则 h = f ∗ g h=f*g h=f∗g(卷积),设 G G G为FT,则 G ( h ) = G ( f ) G ( g ) G(h)=G(f)G(g) G(h)=G(f)G(g)
-
设事件X的pdf为 f X = δ ( x − f ( x 0 ( i ) ) ) f_X=\delta(x-f(x_0^{(i)})) fX=δ(x−f(x0(i))),Y的pdf为 f Y = N ( 0 , Q ) f_Y =N(0,Q) fY=N(0,Q),X,Y独立, G ( f A ) = G ( f X ) G ( f Y ) ⇒ A = X + Y G(f_A)=G(f_X)G(f_Y) \Rightarrow A=X+Y G(fA)=G(fX)G(fY)⇒A=X+Y。想对事件A做随机试验,则只需要对事件X和事件Y分别做随机试验然后把它们加起来。
分析两个拆分出来的事件, X X X为必然事件, Y ∼ N ( 0 , Q ) Y\sim N(0,Q) Y∼N(0,Q),且X,Y独立
-
对 f 1 − ( x ) f_1^-(x) f1−(x)生成粒子: f 1 − ( x ) = ∑ i w i f Q [ x − f ( x 0 ( i ) ) ] f^-_1(x)= \sum \limits_i w_if_Q [x-f(x_0^{(i)})] f1−(x)=i∑wifQ[x−f(x0(i))],对每一个 f Q [ x − f ( x 0 ( i ) ) ] f_Q [x-f(x_0^{(i)})] fQ[x−f(x0(i))]可以看做是一个必然事件 X = f ( x 0 ( i ) ) X=f(x_0^{(i)}) X=f(x0(i))与一个随机数 Y ∼ N ( 0 , Q ) Y\sim N(0,Q) Y∼N(0,Q)的叠加。
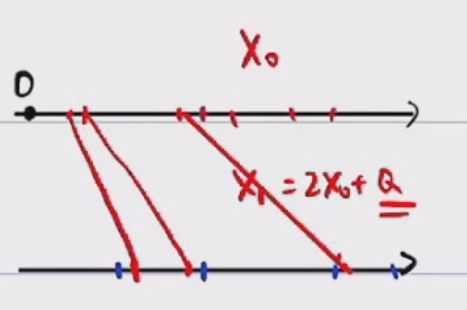
则可生成粒子 X 1 − ( 1 ) , X 1 − ( 2 ) , . . . , X 1 − ( n ) X_1^{-(1)},X_1^{-(2)},...,X_1^{-(n)} X1−(1),X1−(2),...,X1−(n), X 1 − ( i ) = f ( x 0 ( i ) ) + v X_1^{-(i)}=f(x_0^{(i)})+v X1−(i)=f(x0(i))+v,其中 v ∼ N ( 0 , Q ) v\sim N(0,Q) v∼N(0,Q)的一个随机数。
例子: X 1 = 2 X 0 + Q , Q ∼ N ( 0 , 1 ) X_1=2X_0+Q,Q\sim N(0,1) X1=2X0+Q,Q∼N(0,1),设 X 0 ∼ N ( 0 , 1 ) X_0\sim N(0,1) X0∼N(0,1),样本 x 0 − ( 1 ) = 0 , x 0 − ( 2 ) = 0.1 , x 0 − ( 3 ) = − 0.1 x_0^{-(1)}=0,x_0^{-(2)}=0.1,x_0^{-(3)}=-0.1 x0−(1)=0,x0−(2)=0.1,x0−(3)=−0.1
则 x 1 − ( 1 ) = 2 ⋅ 0 + 0.12 , x 1 − ( 2 ) = 2 ⋅ 0.1 + 0.08 , x 1 − ( 2 ) = 2 ⋅ ( − 0.1 ) + 0.3 x_1^{-(1)}=2\cdot 0+0.12,x_1^{-(2)}=2\cdot 0.1+0.08,x_1^{-(2)}=2\cdot (-0.1)+0.3 x1−(1)=2⋅0+0.12,x1−(2)=2⋅0.1+0.08,x1−(2)=2⋅(−0.1)+0.3
-
综上 f 1 − ( x ) = ∑ i w i f Q [ x − f ( x 0 ( i ) ) ] f_1^-(x)=\sum \limits_i w_if_Q [x-f(x_0^{(i)})] f1−(x)=i∑wifQ[x−f(x0(i))],对每一个 f Q [ x − f ( x 0 ( i ) ) ] f_Q [x-f(x_0^{(i)})] fQ[x−f(x0(i))]生成一个粒子即可。此时 x 1 − ( i ) = f ( x 0 ( i ) ) + Q x_1^{-(i)}=f(x_0^{(i)})+Q x1−(i)=f(x0(i))+Q,本质是改变了粒子的位置,并未改变粒子的权重。
-
-
-
粒子滤波算法推导
-
设置初值 X ∼ N ( μ , σ 2 ) X \sim N(\mu,\sigma^2) X∼N(μ,σ2)
-
生成 X 0 X_0 X0的采样样本 x 0 ( 1 ) , . . . . , x 0 ( n ) x_0^{(1)},....,x_0^{(n)} x0(1),....,x0(n),生成 X 0 X_0 X0的样本对应权重 w 0 ( i ) w_0^{(i)} w0(i),可以1/n,也可以按比例分配 f ( x i ) ∑ i f ( x i ) \frac{f(x_i)}{\sum \limits_i f(x_i)} i∑f(xi)f(xi),其中 f ( x ) f(x) f(x)为 X 0 X_0 X0的pdf
-
预测步:生成 X 1 − X_1^- X1−的样本, x 1 ( i ) = f ( x 0 ( i ) ) + v x_1^{(i)}=f(x_0^{(i)})+v x1(i)=f(x0(i))+v, v v v为一个服从 N ( 0 , Q ) N(0,Q) N(0,Q)的正态分布的随机数。
f − ( x ) = ∑ i w 0 ( i ) δ ( x − x 1 − ( i ) ) f^-(x)=\sum \limits_i w_0^{(i)}\delta (x-x_1^{-(i)}) f−(x)=i∑w0(i)δ(x−x1−(i)),预测步改变了粒子的位置,并未改变粒子的权重
-
更新步: f 1 + ( x ) = η f R [ y − h ( x ) ] f 1 − ( x ) = ∑ i = 1 n η f R [ y − h ( x ) ] w 0 ( i ) δ ( x − x 1 − ( i ) ) f^+_1(x)=\eta f_R[y-h(x)]f^-_1(x)=\sum \limits_{i=1}^n \eta f_R[y-h(x)] w_0^{(i)}\delta (x-x_1^{-(i)}) f1+(x)=ηfR[y−h(x)]f1−(x)=i=1∑nηfR[y−h(x)]w0(i)δ(x−x1−(i))

⇒ f 1 + ( x ) = ∑ i = 1 n η f R [ y − h ( x 1 − ( i ) ) ] w 0 ( i ) δ ( x − x 1 − ( i ) ) \Rightarrow f_1^+(x)=\sum \limits_{i=1}^n \eta f_R[y-h(x_1^{-(i)})] w_0^{(i)}\delta (x-x_1^{-(i)}) ⇒f1+(x)=i=1∑nηfR[y−h(x1−(i))]w0(i)δ(x−x1−(i))
设 w 1 ( i ) = f R [ y − h ( x 1 − ( i ) ) ] w 0 ( i ) w_1^{(i)}= f_R [y-h(x_1^{-(i)})] w_0^{(i)} w1(i)=fR[y−h(x1−(i))]w0(i),则
⇒ f 1 + ( x ) = η ∑ i = 1 n w 1 ( i ) δ ( x − x 1 − ( i ) ) \Rightarrow f_1^+(x)=\eta \sum \limits_{i=1}^n w_1^{(i)} \delta (x-x_1^{-(i)}) ⇒f1+(x)=ηi=1∑nw1(i)δ(x−x1−(i)) ,其中 η = ( ∑ i w 1 ( i ) ) − 1 \eta =(\sum \limits_i w_1^{(i)})^{-1} η=(i∑w1(i))−1起到归一化作用
更新步并未改变粒子位置,但是改变了粒子权重
-
对后验概率分布 f 1 + ( x ) = ∑ i = 1 n w 1 ( i ) δ ( x − x i ) f^+_1(x)=\sum \limits_{i=1}^n w_1^{(i)}\delta(x-x_i) f1+(x)=i=1∑nw1(i)δ(x−xi)估计期望: X ^ k + = E ( X 1 + ) = ∫ − ∞ ∞ x ∑ i = 1 n w 1 ( i ) δ ( x − x i ) d x = ∑ i = 1 n w 1 ( i ) x i \hat X_k^+ =E(X_1^+)=\int_{-\infin}^\infin x\sum \limits_{i=1}^n w_1^{(i)}\delta(x-x_i)dx=\sum \limits_{i=1}^n w_1^{(i)}x_i X^k+=E(X1+)=∫−∞∞xi=1∑nw1(i)δ(x−xi)dx=i=1∑nw1(i)xi
方差 D ( X 1 + ) = E ( X 1 2 + ) − [ E ( X 1 + ) ] 2 = ∑ i = 1 n ( w 1 ( i ) x i 2 ) − ( X ^ k + ) 2 D(X_1^+)=E(X_1^{2+})-[E(X_1^+)]^2=\sum \limits_{i=1}^n(w_1^{(i)}x_i^2)-(\hat X_k^+)^2 D(X1+)=E(X12+)−[E(X1+)]2=i=1∑n(w1(i)xi2)−(X^k+)2
-
-
粒子滤波算法流程
- 设置初值 X ∼ N ( μ , σ 2 ) X \sim N(\mu,\sigma^2) X∼N(μ,σ2)
- 生成 X 0 X_0 X0的采样样本 x 0 ( 1 ) , . . . . , x 0 ( n ) x_0^{(1)},....,x_0^{(n)} x0(1),....,x0(n),生成 X 0 X_0 X0的样本对应权重 w 0 ( i ) w_0^{(i)} w0(i),可以1/n,也可以按比例分配 f ( x i ) ∑ i f ( x i ) \frac{f(x_i)}{\sum \limits_i f(x_i)} i∑f(xi)f(xi),其中 f ( x ) f(x) f(x)为 X 0 X_0 X0的pdf
- 预测步:生成 X 1 − X_1^- X1−的样本, x 1 ( i ) = f ( x 0 ( i ) ) + v x_1^{(i)}=f(x_0^{(i)})+v x1(i)=f(x0(i))+v, v v v为一个服从 N ( 0 , Q ) N(0,Q) N(0,Q)的正态分布的随机数。更新粒子位置。
- 更新步:设观测值 y 1 y_1 y1,生成 w 1 ( i ) = f R [ y 1 − h ( x 1 − ( i ) ) ] w 0 ( i ) w_1^{(i)}=f_R[y_1-h(x_1^{-(i)})]w_0^{(i)} w1(i)=fR[y1−h(x1−(i))]w0(i)。更新粒子权重。
- 将 w 1 ( i ) w_1^{(i)} w1(i)归一化, w 1 ( i ) = w 1 ( i ) ∑ i w 1 ( i ) w_1^{(i)}=\frac{w_1^{(i)}}{\sum \limits_i w_1^{(i)}} w1(i)=i∑w1(i)w1(i)
- 此时有新的粒子 X 1 ( i ) X_1^{(i)} X1(i)和新的权重 w 1 ( i ) w_1^{(i)} w1(i)
- 再由预测步生成 X 2 ( i ) = f ( x 1 ( i ) ) + v X_2^{(i)}=f(x_1^{(i)})+v X2(i)=f(x1(i))+v
- 再由更新步生成 w 2 ( i ) = f R [ y 2 − h ( x 2 − ( i ) ) ] w 0 ( i ) w_2^{(i)}=f_R[y_2-h(x_2^{-(i)})]w_0^{(i)} w2(i)=fR[y2−h(x2−(i))]w0(i),归一化 w 2 ( i ) = w 2 ( i ) ∑ i w 2 ( i ) w_2^{(i)}=\frac{w_2^{(i)}}{\sum \limits_i w_2^{(i)}} w2(i)=i∑w2(i)w2(i)
- . . . . . ..... .....
-
重采样:为了解决粒子退化问题,针对下一步更新失效的问题,但必然导致粒子多样性丧失,且减慢粒子滤波的速度。重采样判据 N = 1 ∑ w i 2 N=\frac{1}{\sum w_i^2} N=∑wi21。
-
粒子退化问题:只有少数粒子具有较高的权重,大量粒子权重极低。 → \to →下一步更新失效
-
原因1:粒子数太多
-
原因2: w k ( i ) = f R [ y k − h ( x k − ( i ) ) ] w k − 1 ( i ) w_k^{(i)}=f_R[y_k-h(x_k^{-(i)})]w_{k-1}^{(i)} wk(i)=fR[yk−h(xk−(i))]wk−1(i), f R [ y k − h ( x k ( i ) ) ] = ( 2 π R ) − 1 / 2 e − [ y k − h ( x k ( i ) ) ] 2 2 R f_R[y_k-h(x_k^{(i)})]=(2\pi R)^{-1/2}e^{-\frac{[y_k-h(x_k^{(i)})]^2}{2R}} fR[yk−h(xk(i))]=(2πR)−1/2e−2R[yk−h(xk(i))]2是 e − α x 2 e^{-\alpha x^2} e−αx2型

-
-
例子退化的坏处: f k + = δ ( x − x 2 ) f_k^+=\delta(x-x_2) fk+=δ(x−x2),除了 w k ( 2 ) = 1 w_k^{(2)}=1 wk(2)=1,其余权重都是0。进行预测步 x k + 1 ( i ) = f ( x k ( i ) ) + v k √ x_{k+1}^{(i)}=f(x_k^{(i)})+v_k \surd xk+1(i)=f(xk(i))+vk√;进行更新步 w k ( 2 ) = f R [ y k − h ( x k − ( 2 ) ) ] w k − 1 ( 2 ) w_k^{(2)}=f_R[y_k-h(x_k^{-(2)})]w_{k-1}^{(2)} wk(2)=fR[yk−h(xk−(2))]wk−1(2)其余权重都还是0;归一化 w k + 1 ( 2 ) = w k + 1 ( 2 ) ∑ i w k + 1 ( i ) = 1 w_{k+1}^{(2)}=\frac{w_{k+1}^{(2)}}{\sum \limits_i w_{k+1}^{(i)}} =1 wk+1(2)=i∑wk+1(i)wk+1(2)=1,权重没有更新,失去了权重更新的作用。
-

-
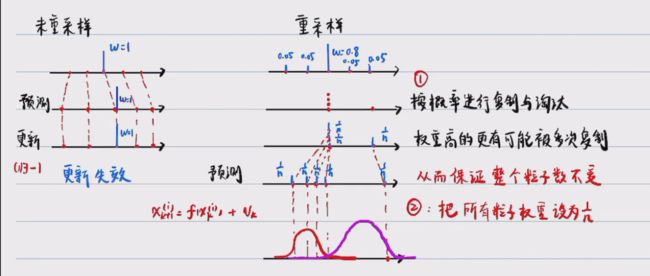
重采样的流程:
-
按概率进行复制和淘汰,权重高的粒子更有可能被多次复制,从而保证整个粒子数不变。
-
复制后把所有粒子的权重设为 1 n \frac{1}{n} n1
-
-
例子:
-
x 1 : w 1 = 0.1 , x 2 : w 2 = 0.1 , x 3 : w 3 = 0.7 , x 4 : w 4 = 0.1 x_1:w_1=0.1,x_2:w_2=0.1,x_3:w_3=0.7,x_4:w_4=0.1 x1:w1=0.1,x2:w2=0.1,x3:w3=0.7,x4:w4=0.1,在[0,1]上按 w i w_i wi的大小生成区间,权重越大区间越长

每个区间为 ( 0 , w 1 ) ( w 1 , w 1 + w 2 ) , . . . , ( ∑ i − 1 w i − 1 , ∑ i w i ) (0,w_1)(w_1,w_1+w_2),...,(\sum \limits_{i-1} w_{i-1},\sum \limits_{i} w_i) (0,w1)(w1,w1+w2),...,(i−1∑wi−1,i∑wi),即 ( 0 , 0.1 ) ( 0.1 , 0.2 ) ( 0.2 , 0.9 ) ( 0.9 , 1 ) (0,0.1)(0.1,0.2)(0.2,0.9)(0.9,1) (0,0.1)(0.1,0.2)(0.2,0.9)(0.9,1)
-
随机生成随机数a, a ∼ U ( 0 , 1 ) a\sim U(0,1) a∼U(0,1)
-
看a落在哪个区间,就把该区间对应粒子进行复制。若a取4次, x 1 x_1 x1复制一次, x 3 x_3 x3复制三次,则重采样结果是 x 1 , x 3 , x 3 , x 3 x_1,x_3,x_3,x_3 x1,x3,x3,x3,即按概率进行复制。
-
所有粒子权重设为 1 n \frac{1}{n} n1
-
重采样代码:
Xold=[x1 x2 x3 x4]; Wold=[w1 w2 w3 w4]; for i=1:4 a = unifrnd(0,1); C[4] = (w1,w1+w2,w1+w2+w3,1); for j = 1:4 if(a
-
-
[粒子滤波算法代码实现](
注意:滤波之前一定要写成状态方程与观测方程的形式 x k = f ( x k − 1 ) x_k=f(x_{k-1}) xk=f(xk−1),大多数情况下不能直接得到 x k x_k xk和 x k − 1 x_{k-1} xk−1的关系,而是 x = f ( t ) x=f(t) x=f(t),要用各种模型(改进欧拉、龙格库塔、泰勒展开等)将 x = f ( t ) x=f(t) x=f(t)转化为** x k = f ( x k − 1 ) x_k=f(x_{k-1}) xk=f(xk−1)**。
-
如何在复杂pdf上采样
采样粒子的特点:概率密度大的地方粒子密度大,概率密度小的地方粒子密度小。
采样方法:高pdf 的地方粒子有更大的概率被保留,低pdf的地方粒子有更大的概率被去掉。做减法,结果粒子数不可控。

均匀分布 → \to →任意分布
-
均匀分布生成粒子
-
取直线M,使 M ≥ f ( x ) M\geq f(x) M≥f(x)
-
对每一个粒子 x 1 , , . . . , x n x_1,,...,x_n x1,,...,xn做判断:生成随机数 a ∼ U ( 0 , M ) a\sim U(0,M) a∼U(0,M),看a落在哪个区间,若 a ∈ ( 0 , f ( x i ) ) a\in (0,f(x_i)) a∈(0,f(xi))则 x i x_i xi保留,否则去掉。

任意分布 → \to →均匀分布
-
设 g ( x ) g(x) g(x)为正态分布
-
在g(x)采样
-
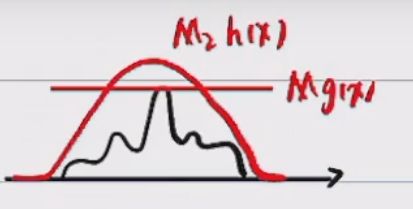
找到一个常数M,使得 M g ( x ) ≥ f ( x ) Mg(x)\geq f(x) Mg(x)≥f(x)
-
对于每一个 x i x_i xi,生成一个随机数 a ∼ U ( 0 , M g ( x i ) ) a\sim U(0,Mg(x_i)) a∼U(0,Mg(xi)),看a落在哪个区间,若 a ∈ ( 0 , f ( x i ) ) a\in (0,f(x_i)) a∈(0,f(xi))保留,反之拒绝。
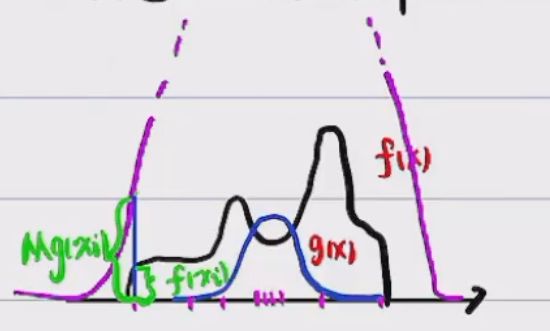
接受-拒绝采样法:设待采样分布 f ( x ) f(x) f(x),容易采样分布 g ( x ) g(x) g(x)(提议分布proposal distribute)。做加法,结果粒子数可控。
- 找到M,使得 M g ( x ) ≥ f ( x ) Mg(x)\geq f(x) Mg(x)≥f(x)
- 在 g ( x ) g(x) g(x)采样一个粒子 x 1 x_1 x1
- 对于每一个 x i x_i xi,生成一个随机数 a ∼ U ( 0 , M g ( x 1 ) ) a\sim U(0,Mg(x_1)) a∼U(0,Mg(x1)),看a落在哪个区间,若 a ∈ ( 0 , f ( x 1 ) ) a\in (0,f(x_1)) a∈(0,f(x1))保留,反之拒绝。
- 在 g ( x ) g(x) g(x)采样一个粒子 x 2 x_2 x2
- . . . . .... ....

提议分布尽可能要与 f ( x ) f(x) f(x)位置、形状贴近,形状越相似,拒绝率越低。

-
改写预测方程:已知 X = f ( t ) X= f(t) X=f(t),如何得到高精度的 X k = F ( X k − 1 ) X_k=F(X_{k-1}) Xk=F(Xk−1)
核心方程: { x k = f ( x k − 1 ) + Q k 预 测 难 写 z k , j = h ( x k ) + R k 观 测 好 写 \left\{\begin{array}{l} \begin{aligned} x_k &= f(x_{k-1})+Q_k 预测 难写\\ z_{k,j} &= h(x_k)+R_{k}观测 好写 \end{aligned} \end{array}\right. {xkzk,j=f(xk−1)+Qk预测难写=h(xk)+Rk观测好写
解决方式: x = f ( t ) → d i s c r e t e x k = f ( t k ) ⇒ x k = F ( x k − 1 , t ) x=f(t) \mathop{\to} \limits^{discrete} x_k=f(t_k)\Rightarrow x_k = F(x_{k-1},t) x=f(t)→discretexk=f(tk)⇒xk=F(xk−1,t),如
[ X k X ˙ k X ¨ k ] = [ 1 d t d t 2 / 2 0 1 d t 0 0 1 ] [ X k − 1 X ˙ k − 1 X ¨ k − 1 ] + [ Q k 11 Q k 2 Q k 3 X k ] \begin{bmatrix} X_k\\[4pt] \dot X_k\\[4pt] \ddot X_k \end{bmatrix}= \begin{bmatrix} 1&dt&dt^2/2\\[4pt] 0&1&dt\\[4pt] 0&0&1 \end{bmatrix} \begin{bmatrix} X_{k-1}\\[4pt] \dot X_{k-1}\\[4pt] \ddot X_{k-1} \end{bmatrix}+\begin{bmatrix} Q_{k11}\\[4pt] Q_{k2}\\[4pt] Q_{k3} X_k \end{bmatrix} ⎣⎢⎡XkX˙kX¨k⎦⎥⎤=⎣⎢⎡100dt10dt2/2dt1⎦⎥⎤⎣⎢⎡Xk−1X˙k−1X¨k−1⎦⎥⎤+⎣⎢⎡Qk11Qk2Qk3Xk⎦⎥⎤ ,但是改变了维数,计算了许多不必要的量,计算缓慢。思路:转换为常微分方程数值解法 x = f ( t ) ⇒ x ˙ = F ( x , t ) x=f(t)\Rightarrow \dot x=F(x,t) x=f(t)⇒x˙=F(x,t),使用欧拉法、龙格库塔法,在不改变维数的前提下提高精度。
- 已知 d x d t + p ( t ) x = 0 ⇒ x = e − ∫ p ( t ) d t + l n C \frac{dx}{dt}+p(t)x=0 \Rightarrow x= e^{-\int p(t)dt +lnC} dtdx+p(t)x=0⇒x=e−∫p(t)dt+lnC,想用 d x d t + p ( t ) x = 0 ⇐ x = e − ∫ p ( t ) d t + l n C \frac{dx}{dt}+p(t)x=0 \Leftarrow x= e^{-\int p(t)dt +lnC} dtdx+p(t)x=0⇐x=e−∫p(t)dt+lnC,来得到 x ˙ = F ( x , t ) \dot x=F(x,t) x˙=F(x,t)
- x = f ( t ) = e ∣ l n f ( t ) ∣ x=f(t)=e^{|lnf(t)|} x=f(t)=e∣lnf(t)∣
- 对比得到 p ( t ) = − f ′ ( t ) f ( t ) p(t)=-\frac{f'(t)}{f(t)} p(t)=−f(t)f′(t)
- 即得到 x = f ( t ) ⇒ x ˙ − f ′ ( t ) f ( t ) x = 0 ⇒ x ˙ = F ( x , t ) = f ′ ( t ) f ( t ) x x=f(t) \Rightarrow \dot x -\frac{f'(t)}{f(t)}x=0 \Rightarrow \dot x=F(x,t)=\frac{f'(t)}{f(t)}x x=f(t)⇒x˙−f(t)f′(t)x=0⇒x˙=F(x,t)=f(t)f′(t)x
举例:设 x = f ( t ) = e t 2 x=f(t)=e^{t^2} x=f(t)=et2,则 f ′ ( t ) = 2 t e t 2 f'(t)=2te^{t^2} f′(t)=2tet2,因此 F ( x , t ) = 2 t e t 2 e t 2 x = 2 t x ⇒ x ˙ = 2 t x F(x,t) = \frac{2te^{t^2}}{e^{t^2}}x=2tx \Rightarrow \dot x=2tx F(x,t)=et22tet2x=2tx⇒x˙=2tx。
- 欧拉法 x k = x k − 1 + 2 t k − 1 x k − 1 d t x_k = x_{k-1}+2t_{k-1}x_{k-1}dt xk=xk−1+2tk−1xk−1dt
- 改进欧拉法 x k = x k − 1 + d t [ 2 t k − 1 x k − 1 + t t k ( x k − 1 + 2 t k − 1 x k − 1 d t ) ] / 2 x_k = x_{k-1}+dt[2t_{k-1}x_{k-1}+tt_k( x_{k-1}+2t_{k-1}x_{k-1}dt)]/2 xk=xk−1+dt[2tk−1xk−1+ttk(xk−1+2tk−1xk−1dt)]/2
- 龙格库塔法