【SLAM基础入门】贝叶斯滤波、卡尔曼滤波、粒子滤波笔记(1)
贝叶斯滤波、卡尔曼滤波、粒子滤波 (https://www.bilibili.com/video/BV1HT4y1577g?spm_id_from=333.999.header_right.history_list.click)
SLAM基础入门,滤波相关知识,基于b站老王视频的学习笔记
文章目录
-
-
- 第一部分:随机过程
- 第二部分:连续随机变量的贝叶斯公式
-
第一部分:随机过程
-
确定过程:如自由落体 v = g t v=gt v=gt, v 1 , v 2 v_1,v_2 v1,v2各个时刻的v都是确定的。
随机过程: x 1 , x 2 , x 3 . . . x_1,x_2,x_3... x1,x2,x3...都是随机变量,但是不独立的,都是有联系的。(无法做随机试验)
随机试验:在相同条件下,试验可重复进行(随机试验之间相互独立);一次试验结果不确定,所有可能的结果可知;试验之前,试验结果预先未知。给事件的概率赋值,如抛硬币。频率 → \to →大数定律,均值收敛到期望。
大数定律:在n次独立试验中,对于任意正数 ϵ \epsilon ϵ有 lim h → ∞ P ( ∣ μ n − P 1 ∣ < ϵ ) = 1 \lim \limits_{h\to \infin}P(|\frac{\mu}{n}-P_1|<\epsilon)=1 h→∞limP(∣nμ−P1∣<ϵ)=1 , 当 n → ∞ n \to \infin n→∞时, μ n \frac{\mu}{n} nμ依概率收敛于 P 1 P_1 P1
不独立的随机试验:如股市,想对股票做随机试验,必须做时光倒流。分子扩散、气温变化。时光一去不复返。
不独立随机变量之间的关系: x k = f ( x k − 1 ) , P ( x k ) = f ( P ( x k − 1 ) ) x_k=f(x_{k-1}),P(x_k)=f(P(x_{k-1})) xk=f(xk−1),P(xk)=f(P(xk−1)) 初值 P ( x 1 ) P(x_1) P(x1)的选取很重要。有的初值可以做随机试验,如随机游走 x k = x k − 1 + D x_k=x_{k-1}+D xk=xk−1+D,规定起点 P ( x 0 = 0 ) = 1 P(x_0=0)=1 P(x0=0)=1 。
利用主观概率获得初值:设有随机过程 x 1 , x 2 , . . x n x_1,x_2,..x_n x1,x2,..xn,有关系 x K = f ( x k − 1 ) x_K=f(x_{k-1}) xK=f(xk−1),不同的主观概率将导致不同的结果,因此引入外部观测(信息,证据)来对过程进行更新。如股票概率,有内部消息,减弱主观的影响。
主观概率(先验概率,先于实验之前,经验) → 外 部 观 测 \mathop{\to} \limits^{外部观测} →外部观测 相对客观的概率,即后验概率(后测概率)。
-
举例:温度
-
先验概率分布: P ( T = 10 ) = 0.8 P(T=10)=0.8 P(T=10)=0.8, P ( T = 11 ) = 0.2 P(T=11)=0.2 P(T=11)=0.2 —— 真实值可能是10,可能是11。
-
温度计读数 T m e a s u r e = 10. 3 o C T_{measure}=10.3^oC Tmeasure=10.3oC
-
后验概率分布:用贝叶斯公式, P ( T = 10 ∣ T m e a s u r e = 10.3 ) = P ( T m e a s u r e = 10.3 ∣ T = 10 ) P ( T = 10 ) P ( T m e a s u r e = 10.3 ) P(T=10|T_{measure}=10.3)=\frac{P(T_{measure}=10.3|T=10)P(T=10)}{P(T_{measure}=10.3)} P(T=10∣Tmeasure=10.3)=P(Tmeasure=10.3)P(Tmeasure=10.3∣T=10)P(T=10)表示测量值为10.3的情况下,真实值为10的概率
-
似然概率 P ( T m e a s u r e = 10.3 ∣ T = 10 ) P(T_{measure}=10.3|T=10) P(Tmeasure=10.3∣T=10)代表观测的准确度,当真实温度为10时,温度计测得温度为10.3的概率。定义为似然,即传感器精度(客观存在),表示哪个原因最有可能导致了结果。
例子:A班99男1女,B班1男99女,随机抽一个班,再抽一个人进行观测,结果是女。此女最有可能是从B班抽出来的。
-
P ( T m e a s u r e = 10.3 ) P(T_{measure}=10.3) P(Tmeasure=10.3)表示测量值是10.3的概率。全概率公式展开 P ( T m = 10.3 ) = P ( T m = 10.3 ∣ T = 10 ) + P ( T m = 10.3 ∣ T = 11 ) P ( T = 11 ) P(T_m=10.3)=P(T_m=10.3|T=10)+P(T_m=10.3|T=11)P(T=11) P(Tm=10.3)=P(Tm=10.3∣T=10)+P(Tm=10.3∣T=11)P(T=11)
** ⋆ \star ⋆ P ( T m = 10.3 ) P(T_m=10.3) P(Tm=10.3)与T的取值无关,与T的分布律(先验概率)有关,而先验概率已经给定,因此其与真实值T无关,所以将其倒数视作常数 η \eta η。**简化贝叶斯公式 P ( T = 10 ∣ T m e a s u r e = 10.3 ) = P ( T m e a s u r e = 10.3 ∣ T = 10 ) P ( T = 10 ) P ( T m e a s u r e = 10.3 ) = η P ( T m e a s u r e = 10.3 ∣ T = 10 ) P ( T = 10 ) P(T=10|T_{measure}=10.3)=\frac{P(T_{measure}=10.3|T=10)P(T=10)}{P(T_{measure}=10.3)}=\eta P(T_{measure}=10.3|T=10)P(T=10) P(T=10∣Tmeasure=10.3)=P(Tmeasure=10.3)P(Tmeasure=10.3∣T=10)P(T=10)=ηP(Tmeasure=10.3∣T=10)P(T=10) 即
后 验 = η 似 然 × 先 验 ⟺ P ( 状 态 ∣ 观 测 ) = η P ( 观 测 ∣ 状 态 ) P ( 状 态 ) 后验=\eta 似然\times先验 \iff P(状态|观测)=\eta P(观测|状态)P(状态) 后验=η似然×先验⟺P(状态∣观测)=ηP(观测∣状态)P(状态),状态是因,观测是果。
-
第二部分:连续随机变量的贝叶斯公式
-
离散随机变量贝叶斯公式: P ( X = x ∣ Y = y ) = P ( Y = y ∣ X = x ) P ( X = x ) P ( Y = y ) P(X=x|Y=y)=\frac{P(Y=y|X=x)P(X=x)}{P(Y=y)} P(X=x∣Y=y)=P(Y=y)P(Y=y∣X=x)P(X=x)
连续随机变量贝叶斯公式:
P ( X < x ∣ Y = y ) = ∫ − ∞ x f X ∣ Y ( x ∣ y ) d x = ∫ − ∞ x f Y ∣ X ( y ∣ x ) f X ( x ) f Y ( y ) d x ⇒ f X ∣ Y ( x ∣ y ) = f Y ∣ X ( y ∣ x ) f X ( x ) f Y ( y ) P(X
其中 f Y ( y ) = ∫ − ∞ ∞ f ( y , x ) d x f_Y(y)=\int_{-\infin}^\infin f(y,x)dx fY(y)=∫−∞∞f(y,x)dx 即联合概率密度与边缘概率密度的关系,求边缘。
用 条 件 概 率 ⇒ f Y ( y ) = ∫ − ∞ ∞ f ( y , x ) d x = ∫ − ∞ ∞ f Y ∣ X ( y ∣ x ) f X ( x ) d x = C η = ∫ − ∞ ∞ 1 f Y ∣ X ( y ∣ x ) f X ( x ) d x d x 归 一 化 得 到 ⇒ f X ∣ Y ( x ∣ y ) = f Y ∣ X ( y ∣ x ) f X ( x ) f Y ( y ) = η f Y ∣ X ( y ∣ x ) f X ( x ) 用条件概率\Rightarrow f_Y(y)=\int_{-\infin}^\infin f(y,x)dx=\int_{-\infin}^\infin f_{Y|X}(y|x)f_X(x)dx=C \\ \eta =\int_{-\infin}^\infin \frac{1}{f_{Y|X}(y|x)f_X(x)dx}dx 归一化 得到 \Rightarrow f_{X|Y}(x|y)=\frac{f_{Y|X}(y|x)f_X(x)}{f_Y(y)}=\eta f_{Y|X}(y|x)f_X(x) 用条件概率⇒fY(y)=∫−∞∞f(y,x)dx=∫−∞∞fY∣X(y∣x)fX(x)dx=Cη=∫−∞∞fY∣X(y∣x)fX(x)dx1dx归一化得到⇒fX∣Y(x∣y)=fY(y)fY∣X(y∣x)fX(x)=ηfY∣X(y∣x)fX(x) -
例子:测温
-
猜一下多少度,即给定先验概率密度: f X ( x ) = 1 2 π e − ( x − 10 ) 2 2 f_X(x)=\frac{1}{\sqrt{2\pi}}e^{-\frac{(x-10)^2}{2}} fX(x)=2π1e−2(x−10)2,倾向于认为 X = 10 X=10 X=10是最有可能的温度,自信程度为方差。
-
温度计测一下,观测: y = 9 y=9 y=9
-
想求后验概率密度 f X ∣ Y ( x ∣ 9 ) f_{X|Y}(x|9) fX∣Y(x∣9),想用贝叶斯公式那么要知道似然概率 f Y ∣ X ( y ∣ x ) f_{Y|X}(y|x) fY∣X(y∣x)。
f Y ∣ X ( y ∣ x ) ⋅ ϵ = P ( y < Y < y + ϵ ∣ X = x ) ⇒ f Y ∣ X ( y ∣ x ) = lim ϵ → 0 P ( y < Y < y + ϵ ∣ X = x ) ϵ f_{Y|X}(y|x)\cdot\epsilon = P(y
即传感器的精度。温度计精度 ± 0.2 \pm 0.2 ±0.2,真实值为x,则 y = x ± 0.2 y=x\pm 0.2 y=x±0.2。用概率描述,即 P ( x − 0.2 < Y < x + 0.2 ∣ X = x ) = ∫ y = x − 0.2 y = x + 0.2 f Y ∣ X ( y ∣ x ) d y P(x-0.2 -
设似然概率为均值为y(观测值),方差为0.2(置信程度)的正态分布,即 f Y ∣ X ( y = 9 ∣ x ) = 1 2 π ⋅ 0.2 e − ( 9 − x ) 2 2 ⋅ 0. 2 2 f_{Y|X}(y=9|x)=\frac{1}{\sqrt{2\pi}\cdot 0.2}e^{-\frac{(9-x)^2}{2\cdot 0.2^2}} fY∣X(y=9∣x)=2π⋅0.21e−2⋅0.22(9−x)2
-
因此可计算得到后验概率 f X ∣ Y ( x ∣ 9 ) = η 1 2 π ⋅ 0.2 e − 1 2 [ ( x − 10 ) 2 + ( 9 − x ) 2 0. 2 2 ] ∼ N ( 9.0385 , 0.03 8 2 ) f_{X|Y}(x|9)=\eta \frac{1}{2\pi\cdot 0.2}e^{-\frac{1}{2}[(x-10)^2+\frac{(9-x)^2}{0.2^2}]} \sim N(9.0385,0.038^2) fX∣Y(x∣9)=η2π⋅0.21e−21[(x−10)2+0.22(9−x)2]∼N(9.0385,0.0382),其中 η = ( ∫ − ∞ ∞ 1 2 π ⋅ 0.2 e − 1 2 [ ( x − 10 ) 2 + ( 9 − x ) 2 0. 2 2 ] ) − 1 \eta = ( \int_{-\infin} ^\infin \frac{1}{2\pi\cdot 0.2}e^{-\frac{1}{2}[(x-10)^2+\frac{(9-x)^2}{0.2^2}]} )^{-1} η=(∫−∞∞2π⋅0.21e−21[(x−10)2+0.22(9−x)2])−1。
-
综上,先验概率 ∼ N ( 10 , 1 ) \sim N(10,1) ∼N(10,1),似然概率 ∼ N ( 9 , 0. 2 2 ) \sim N(9,0.2^2) ∼N(9,0.22),后验概率 ∼ N ( 9.0385 , 0.03 8 2 ) \sim N(9.0385,0.038^2) ∼N(9.0385,0.0382),方差显著降低,不确定度减小,即滤波。
-
似然模型:
(1)等可能型 f Y ∣ X ( y ∣ x ) = C f_{Y|X}(y|x)=C fY∣X(y∣x)=C

(2)阶梯型 推广:直方图滤波(非线性卡尔曼滤波)
-
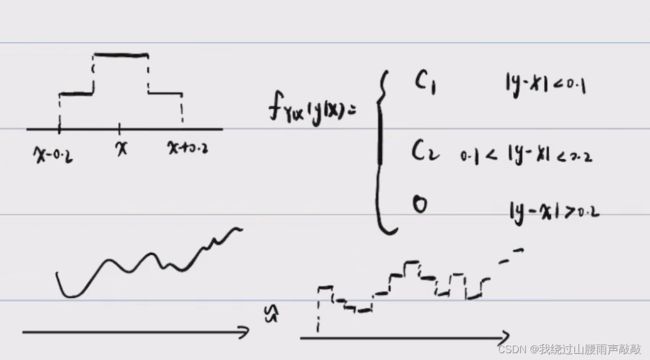
(3)正态分布型 √ \surd √:方差取传感器精度即0.2。
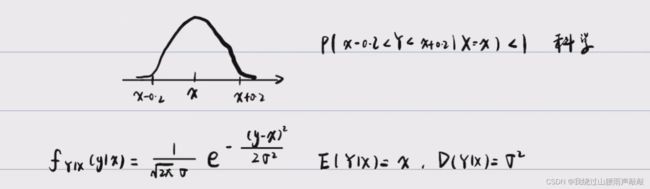
-
定理:若先验概率 f X ( x ) ∼ N ( μ 1 , σ 1 2 ) f_X(x)\sim N(\mu_1,\sigma^2_1) fX(x)∼N(μ1,σ12),似然概率 f Y ∣ X ( y ∣ x ) ∼ N ( μ 2 , σ 2 2 ) f_{Y|X}(y|x)\sim N(\mu_2,\sigma^2_2) fY∣X(y∣x)∼N(μ2,σ22),则后验概率 f X ∣ Y ( x ∣ y ) ∼ N ( σ 1 2 σ 1 2 + σ 2 2 μ 2 + σ 2 2 σ 1 2 + σ 2 2 μ 1 , σ 1 2 σ 2 2 σ 1 2 + σ 2 2 ) f_{X|Y}(x|y)\sim N(\frac{\sigma_1^2}{\sigma^2_1+\sigma^2_2}\mu_2+\frac{\sigma_2^2}{\sigma^2_1+\sigma^2_2}\mu_1,\frac{\sigma_1^2\sigma_2^2}{\sigma^2_1+\sigma^2_2}) fX∣Y(x∣y)∼N(σ12+σ22σ12μ2+σ12+σ22σ22μ1,σ12+σ22σ12σ22),理解为权重。方差大权重小。
-
若 σ 1 2 ≫ σ 2 2 \sigma_1^2 \gg \sigma^2_2 σ12≫σ22,即传感器精度极高或瞎猜,后验 ∼ N ( μ 2 , σ 2 2 ) \sim N(\mu_2,\sigma^2_2) ∼N(μ2,σ22)倾向于观测值。
-
若 σ 1 2 ≪ σ 2 2 \sigma_1^2 \ll \sigma^2_2 σ12≪σ22,即猜的贼准或者传感器精度极低,后验 ∼ N ( μ 1 , σ 1 2 ) \sim N(\mu_1,\sigma^2_1) ∼N(μ1,σ12)倾向于预测值(先验)。
后验方差 σ 1 2 σ 2 2 σ 1 2 + σ 2 2 = σ 1 2 1 1 + σ 1 2 / σ 2 2 = σ 2 2 1 1 + σ 2 2 / σ 1 2 \frac{\sigma_1^2\sigma_2^2}{\sigma^2_1+\sigma^2_2}=\sigma^2_1 \frac{1}{1+\sigma_1^2/\sigma^2_2}=\sigma^2_2 \frac{1}{1+\sigma_2^2/\sigma^2_1} σ12+σ22σ12σ22=σ121+σ12/σ221=σ221+σ22/σ121,即滤波后方差比之前任何一个都小,观测准确将削弱先验的影响。传感器融合的原理。
-
-
狄拉克函数 δ ( x ) \delta(x) δ(x):处理传感器无限精度,即方差 δ → 0 \delta \to 0 δ→0的问题。实质上是离散的必然事件的概率密度。
似然概率 f Y ∣ X ( y ∣ x ) = 1 2 π ⋅ σ e − ( y − x ) 2 2 ⋅ σ 2 f_{Y|X}(y|x)=\frac{1}{\sqrt{2\pi}\cdot \sigma}e^{-\frac{(y-x)^2}{2\cdot \sigma^2}} fY∣X(y∣x)=2π⋅σ1e−2⋅σ2(y−x)2,当 σ → 0 \sigma \to 0 σ→0时, f Y ∣ X ( y ∣ x ) = δ ( x ) f_{Y|X}(y|x)=\delta(x) fY∣X(y∣x)=δ(x),收缩成尖峰。将一个函数收缩成一个点
狄拉克函数的选择性: ∫ − ∞ + ∞ f ( x ) σ ( x − a ) = f ( a ) \int _{-\infin} ^{+\infin} f(x)\sigma(x-a)=f(a) ∫−∞+∞f(x)σ(x−a)=f(a)

例子:设先验 ∼ N ( μ , σ 2 ) \sim N(\mu,\sigma^2) ∼N(μ,σ2),观测 y = 10 y=10 y=10,似然 ∼ δ ( 10 − x ) \sim \delta(10-x) ∼δ(10−x)无限精度。则后验 f X ∣ Y ( x ∣ y ) = η δ ( 10 − x ) 1 2 π σ e − ( x − μ ) 2 2 σ 2 = δ ( 10 − x ) ⋅ e − ( x − μ ) 2 2 σ 2 + ( 10 − μ ) 2 2 σ 2 f_{X|Y}(x|y)=\eta \delta(10-x)\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}}=\delta(10-x) \cdot e^{-\frac{(x-\mu)^2}{2\sigma^2}+\frac{(10-\mu)^2}{2\sigma^2}} fX∣Y(x∣y)=ηδ(10−x)2πσ1e−2σ2(x−μ)2=δ(10−x)⋅e−2σ2(x−μ)2+2σ2(10−μ)2。测到10,实际为10的概率为1。
