讲解变分自编码器-VAE(附代码)
学习了网上好多教程,感觉对这块理解得差不多了,干脆自己写一写,也方便以后复习回顾。
目录
1.从AE谈起
2.VAE基础知识
2.1 VAE基本介绍
2.2 VAE推导
2.2.1 KL散度
2.2.2 变分推断
2.2.3 推导过程
2.2.4 推导结果
3.代码实现
3.1.1 VAE.py
3.1.2 main.py
4.参考资料
1.从AE谈起
说到编码器这块,不可避免地要讲起AE(AutoEncoder)自编码器。它的结构下图所示:
 图1 AE基本结构
图1 AE基本结构
据图可知,AE通过自监督的训练方式,能够将输入的原始特征 通过编码encoder后得到潜在的特征编码
通过编码encoder后得到潜在的特征编码 ,实现了自动化的特征工程,并且达到了降维和泛化的目的。而后通过对进行decoder后,我们可以重构输出
,实现了自动化的特征工程,并且达到了降维和泛化的目的。而后通过对进行decoder后,我们可以重构输出 。一个良好的AE最好的状态就是解码器的输出能够完美地或者近似恢复出原来的输入, 即
。一个良好的AE最好的状态就是解码器的输出能够完美地或者近似恢复出原来的输入, 即![]() 。
。
为此,训练AE所需要的损失函数是:
![]()
AE的重点在于编码,而解码的结果,基于训练目标,如果损失足够小的话,将会与输入相同。从这一点上看解码的值没有任何实际意义,除了通过增加误差来补充平滑一些初始的零值或有些许用处。
易知,从输入到输出的整个过程,AE都是基于已有的训练数据的映射,尽管隐藏层的维度通常比输入层小很多,但隐藏层的概率分布依然只取决于训练数据的分布,这就导致隐藏状态空间的分布并不是连续的,它只是稀疏地记录下来你的输入样本和生成图像的一一对应关系。 因此如果我们随机生成隐藏层的状态,那么它经过解码将很可能不再具备输入特征的特点,因此想通过解码器来生成数据就有点强模型所难了。
如下图所示,仅通过AE,我们在码空间里随机采样的点并不能生成我们所希望的相应图像。
 图2 为什么需要VAE的直接原因
图2 为什么需要VAE的直接原因
据此,我们对AE的隐藏层作出改动,得到了VAE。
2.VAE基础知识
2.1 VAE基本介绍
VAE全称是Variational AutoEncoder,即变分自编码器。它不再是对一个样本直接生成一个码空间上的点,而是将经过神经网络编码后的隐藏层假设为一个标准的高斯分布,然后从这个分布中采样一个特征,再用这个特征进行解码,期望得到与原始输入相同的结果。
 图3 VAE基本结构
图3 VAE基本结构
VAE在AE的损失之外增加了编码推断分布与标准高斯分布的KL散度的正则项。增加这个正则项的目的是防止模型退化成普通的AE。因为网络训练时为了尽量减小重构误差,必然使得方差逐渐被降到0,这样便不再会有随机采样噪声,VAE也就逐渐变成了普通的AE。
因此,训练VAE所需要的损失函数是:
![]()
总的来说,VAE为输入, 生成了一个潜在概率分布![]() ,然后再从分布中进行随机采样,从而得到了连续完整的潜在空间,解决了AE中无法用于生成的问题。
,然后再从分布中进行随机采样,从而得到了连续完整的潜在空间,解决了AE中无法用于生成的问题。
2.2 VAE推导
2.2.1 KL散度
KL 散度(Kullback-Leibler divergence)是一个用来衡量两个概率分布的相似性的一个度量指标,又称相对熵。在信息论中,相对熵等价于两个概率分布的信息熵(Shannon entropy)的差值。
尽管现实世界里的任何观察都可以看成表示成信息和数据,但一般来说,我们只能拿到数据的部分样本而非总体,进而根据数据的部分样本对数据的整体做一个近似的估计。至于数据整体本身有的真实分布,我们可能永远也无法知道。而近似估计的概率分布和数据整体真实的概率分布的相似度,或者说差异程度,可以用 KL 散度来表示。
假设![]() 是随机变量
是随机变量 上的两个概率分布,则在离散和连续随机变量的情形下,KL散度的定义分别为:
上的两个概率分布,则在离散和连续随机变量的情形下,KL散度的定义分别为:
![]()
![]()
2.2.2 变分推断
变分推断是MCMC搞不定场景的一种替代算法,它考虑一个贝叶斯推断问题,给定观测变量![]() 和潜变量
和潜变量 ![]() 其联合概率分布为
其联合概率分布为![]() , 目标是计算后验分布
, 目标是计算后验分布![]() 。然后我们可以假设一个变分分布
。然后我们可以假设一个变分分布 ![]() 来自分布族
来自分布族![]() ,通过最小化KL散度来近似后验分布
,通过最小化KL散度来近似后验分布 ![]() :
:
![]()
从而成功地将一个贝叶斯推断问题转化为了一个优化问题。
2.2.3 推导过程
而VAE就是将AE的编码和解码过程转化为了一个贝叶斯概率模型: 输入的训练数据即为观测变量 , 假设它由不能直接观测到的潜变量
, 假设它由不能直接观测到的潜变量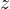 生成。 于是,生成观测变量过程便是似然分布:
生成。 于是,生成观测变量过程便是似然分布:![]() 也就是解码器,因而编码器自然就是后验分布:
也就是解码器,因而编码器自然就是后验分布:![]() 。
。
![]()
而基于变分推断的思想,我们假设变分分布![]() , 通过最小化KL散度来近似模拟后验分布
, 通过最小化KL散度来近似模拟后验分布![]() ,于是,最佳的
,于是,最佳的![]() 便是:
便是:
![]()
又因为训练数据是确定的,因此![]() 是一个常数,于是上面的优化问题等价于:
是一个常数,于是上面的优化问题等价于:
而这个式子,正是我们所找寻的VAE损失函数。
2.2.4 推导结果
·编码部分 encoder
我们希望拟合一个分布![]() 尽可能接近
尽可能接近![]() , 关键在于基于输入直接计算
, 关键在于基于输入直接计算![]() 和
和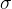 有点困难,于是就使用两个神经网络
有点困难,于是就使用两个神经网络![]() 和
和 ![]() 来拟合
来拟合![]() 和。
和。
· 解码部分 Decoder
即从潜变量生成数据的过程,在于最大化似然![]() ,通常我们假设它是一个伯努利分布或是高斯分布。 知道分布类型后我们计算
,通常我们假设它是一个伯努利分布或是高斯分布。 知道分布类型后我们计算![]() 只需要带入分布公式即可。
只需要带入分布公式即可。
是高斯分布:
和预期一样,公式变换为了均方误差。
是伯努利分布:
![]()
假设伯努利的二元分布是![]() 和
和 ![]() ,那么所得到的正好就是交叉熵的损失。
,那么所得到的正好就是交叉熵的损失。
·重参数技巧
然而argmin在实际运算中是不可导的,所以从高斯分布![]() 中采样的操作被巧妙转换为了从
中采样的操作被巧妙转换为了从![]() 中采样得到
中采样得到![]() 后,再通过
后,再通过![]() 变换得到。
变换得到。
 图4 重参数技巧
图4 重参数技巧
而在重参数后,我们计算反向传播的过程 如下图所示:
 图5 重参数后反向传播过程
图5 重参数后反向传播过程
3.代码实现
3.1.1 VAE.py
import torch
from torch import nn
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
# [b, 784] =>[b,20]
# u: [b, 10]
# sigma: [b, 10]
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 64),
nn.ReLU(),
nn.Linear(64, 20),
nn.ReLU()
)
# [b,10] => [b, 784]
# sigmoid函数把结果压缩到0~1
self.decoder = nn.Sequential(
nn.Linear(10, 64),
nn.ReLU(),
nn.Linear(64, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
"""
:param x:
:return:
"""
batchsz = x.size(0)
# flatten
x = x.view(batchsz, 784)
# encoder
# [b, 20], including mean and sigma
h_ = self.encoder(x)
# chunk 在第二维上拆分成两部分
# [b, 20] => [b,10] and [b, 10]
mu, sigma = h_.chunk(2, dim=1)
# reparametrize tirchk, epison~N(0, 1)
# torch.randn_like(sigma)表示正态分布
h = mu + sigma * torch.randn_like(sigma)
# decoder
x_hat = self.decoder(h)
# reshape
x_hat = x_hat.view(batchsz, 1, 28, 28)
# KL
# 1e-8是防止σ^2接近于零时该项负无穷大
# (batchsz*28*28)是让kld变小
kld = 0.5 * torch.sum(
torch.pow(mu, 2) +
torch.pow(sigma, 2) -
torch.log(1e-8 + torch.pow(sigma, 2)) - 1
) / (batchsz*28*28)
return x, kld3.1.2 main.py
import torch
from torch.utils.data import DataLoader
from torch import nn, optim
from torchvision import transforms, datasets
from ae_1 import AE
from vae import VAE
from vq-vae import VQVAE
import visdom
def main():
mnist_train = datasets.MNIST('mnist', True, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_train = DataLoader(mnist_train, batch_size=32, shuffle=True)
mnist_test = datasets.MNIST('mnist', False, transform=transforms.Compose([
transforms.ToTensor()
]), download=True)
mnist_test = DataLoader(mnist_test, batch_size=32, shuffle=True)
#无监督学习,不能使用label
x, _ = iter(mnist_train).next()
print('x:', x.shape)
device = torch.device('cuda')
#model = AE().to(device)
model = VAE().to(device)
criteon = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=1e-3)
print(model)
viz = visdom.Visdom()
for epoch in range(1000):
for batchidx, (x, _) in enumerate(mnist_train):
# [b, 1, 28, 28]
x = x.to(device)
x_hat, kld = model(x)
loss = criteon(x_hat, x)
if kld is not None:
elbo = - loss - 1.0 * kld
loss = - elbo
# backprop
optimizer.zero_grad()
loss.backward()
optimizer.step()
print(epoch, 'loss', loss.item(), kld.item())
x, _ = iter(mnist_test).next()
x = x.to(device)
with torch.no_grad():
x_hat = model(x)
# nrow表示一行的图片
viz.images(x, nrow=8, win='x', optis=dic(title='x'))
iz.images(x_hat, nrow=8, win='x_hat', optis=dic(title='x_hat'))
if __name__ == '__main__':
main()4.参考资料
1.解析Variational AutoEncoder(VAE)
2.进来学VAE,VAE都不懂还想懂扩散模型? | Variational Auto-Encoder
3.苏剑林:变分自编码器(一):原来是这么一回事
4.b站 人工智能-小甲鱼 【深度学习Pytprch入门】 P116