Java 8 主要新特性
JAVA 8 新特性
1. Lambda 表达式
1.1 简介
Lambda 是一个匿名函数,通过 lambda 操作符 -> 分成左右两部分:
- 左侧:lambda 表达式的参数列表;
- 右侧:lambda 表达式中所需要执行的功能,即 lambda 体。
Lambda 表达式需要函数式接口支持,接口中只有一个抽象方法的接口为函数式接口,可以使用注解 @FunctionInterface 修饰,通过该注解可检验是否为函数式接口,比如:
// 非函数式接口,因为不止一个抽象方法
public interface xxx<T> {
public boolean test(T t);
public boolean test1(T t);
}
// 函数式接口,使用此注解后,如果有多个方法,那么会报错
@FunctionInterface
public interface xxx<T> {
public boolean test(T t);
}
1.2 Lambda 表达式多种语法格式
-
格式一:无参数、无返回值。
() -> System.out.println("Hello Lambda");比如:
public class TestLambd1 { @Test public void test() { Runnable r = new Runnable() { @Override public void run() { System.out.println("Hello Lambda"); } }; r.run(); / lambda / Runnable r1 = () -> System.out.println("Hello Lambda"); r1.run(); } } -
格式二:有一个参数,并且无返回值。
(x) -> System.out.println(x);比如:
public class TestLambd1 { @Test public void test() { Consumer<String> con = (x) -> System.out.println(x); con.accept("Hello Lambda"); } } -
格式三:如果只有一个参数,那么小括号可以不写。
x -> System.out.println(x); -
格式四:多个参数,有返回值,且 lambda 体中有多条语句。
public class TestLambd1 { @Test public void test() { Comparator<Integer> com = (x, y) -> { System.out.println("Hello Lambda"); return Integer.compare(x, y); }; } } -
格式五:有返回值,若 lambda 体中只有一条语句,return 和 {} 可以省略。
public class TestLambd1 { @Test public void test() { Comparator<Integer> com = (x, y) -> Integer.compare(x, y); } } -
格式六:lambda 表达式的参数列表可以省略不写,因为 JVM 编译器通过上下文可以推断数据类型。
1.3 JAVA8 内置的四大核心函数式接口
除了此四大核心函数式接口外还有类似的子接口,这里就不过多赘述。
1.3.1 消费型接口 Consumer
void accept(T t);
public class TestLambd1 {
@Test
public void test() {
happy(100, (m) -> System.out.println("消费:" + x + "元"));
}
public void happy(double money, Consumer<Double> con) {
con.accept(money);
}
}
1.3.2 供给型接口Supplier
T get();
public class TestLambd1 {
@Test
public void test() {
// 通过随机数产生
List<Integer> res = getNumList(10, () -> (int)(Math.random() * 100));
for (Integer num : res) {
System.out.println(num);
}
}
// 需求:产生指定个数的整数,并放入集合中
public List<Integer> getNumList(int num, Supplier<Integer> sup) {
List<Integer> list = new ArrayList<>();
for (int i = 0; i < num; i++) {
Integer n = sup.get();
list.add(n);
}
return list;
}
}
1.3.3 函数型接口Function
R apply(T t);
public class TestLambd1 {
@Test
public void test() {
// 处理字符串的方法,去掉首位空格
String newStr = strHandler("\t\t\t haha", (str) -> str.trim());
System.out.println(newStr);
// 处理字符串的方法,数据截取
String subStr = strHandler("hahahaha", (str) -> str.substring(1,3));
System.out.println(subStr);
}
// 需求:用于处理字符串
public String strHandler(String str, Function<String, String> fun) {
return fun.apply(str);
}
}
1.3.4 断言型接口 Predicate
boolean test(T t);
public class TestLambd1 {
@Test
public void test() {
List<String> list = Arrays.aslist("Hello", "Lambda", "www");
List<String> res = filterStr(list, (str) -> s.length > 3);
for (String s ; res) {
System.out.println(s);
}
}
// 需求:将满足条件的字符串放入集合
public List<String> filterStr(List<String> list, Predicate<String> pre) {
List<String> strList = new ArrayList<>();
for (String str:list) {
if(pre.test(pre)) {
strList.add(str);
}
}
return strList;
}
}
1.4 方法引用
如果 lambda 体中的内容已有方法实现了,我们可以使用方法引用。方法引用可以理解为 lambda 表达式的另外一种表现形式。
注意事项:
- lambda 体中调用方法的参数列表与返回值类型,要与函数式接口中抽象方法的函数列表和返回值类型保持一致。
- 如果 lambda 参数列表中的第一个参数是 实例方法的调用者,而第二个参数是实例方法的参数时,可以使用
ClassName::MethodName。
方法引用主要有以下三种格式:对象::实例方法名;类::静态方法名;类::实例方法名。
对象::实例方法名;
public class TestLambd1 {
@Test
public void test() {
Consumer<String> con = (x) -> System.out.println(x);
con.accept("abc");
// 进入 println 之后,其内容如下,println 为实例方法,属于PrintStream类
/*
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}
*/
// 所以上面的 con 对应的代码行也可以写成
PrintStream ps = System.out;
Consumer<String> con1 = ps::println;
con1.accept("abc");
// 或者
Consumer<String> con2 = System.out::println;
con2.accept("abc");
}
}
类::静态方法名;
public class TestLambd1 {
@Test
public void test() {
Comparator<Integer> com = (x, y) -> Integer.compare(x, y);
// 进入 Integer.compare 之后,其内容如下,compare 为静态方法,属于Integer类
/*
public static int compare(int x, int y) {
return (x < y) ? -1 : ((x == y) ? 0 : 1);
}
*/
// 或者
Comparator<Integer> com1 = Integer::compare;
}
}
类::实例方法名。
public class TestLambd1 {
@Test
public void test() {
BiPredicate<String, String> bp = (x, y) -> x.equals(y);
BiPredicate<String, String> bp2 = String::equals;
}
}
1.5 构成器引用
注意:
- 需要调用的构造器的参数列表要与函数式接口中抽象方法的参数列表保持一致。
格式 ClassName::new。
public class TestLambd1 {
@Test
public void test() {
/* 无参构造器 public Employee() {} */
Supplier<Employee> sup = () -> new Employee();
// 构造器引用
Supplier<Employee> sup2 = Employee::new;
Employee emp = sup2.get();
/* 带参构造器 public Employee(int id) {this.id = id;} */
Function<Integer, Employee> fun = (x) -> new Employee(x);
Function<Integer, Employee> fun1 = Employee::new;
Employee emp1 = fun1.apply(101);
/* 带参构造器 public Employee(int id, int age) {this.id = id; this.age = age} */
BiFunction<Integer, Integer, Employee> bf = Employee::new;
}
}
1.6 数组引用
格式:Type::new。
public class TestLambd1 {
@Test
public void test() {
Function<Integer, String[]> fun = (x) -> new String[x];
String[] strs = fun.apply(10); // 得到长度为10的string数组
//或者
Function<Integer, String[]> fun1 = (x) -> String[]::new;
String[] strs1 = fun1.apply(10); // 得到长度为10的string数组
}
}
2. Stream API
2.1 简介
JAVA 8 有两大重要改变,一个是是 lambda 表达式,另一个是 Stream API(java.util.stream.*)。Stream 是 JAVA 8 中处理集合的关键抽象概念,可以指定希望对集合进行的操作,执行非常复杂的查找、过滤和映射数据等操作。
Stream 是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。集合讲的是数据,流讲的是计算。
注意:
- Stream 自己不会存储元素;
- Stream 不会改变源对象,而是返回一个持有结果的新 Stream;
- Stream 操作是延迟执行的,意味着要等到需要结果的时候才执行。
Stream 操作的三个步骤:
-
创建Stream
一个数据源(如集合数组等),获取一个流。
-
中间操作
中间操作链,对数据源的数据进行处理。
-
终止操作(终端操作)
执行中间操作链,并产生结果。
2.2 创建 Stream
四种创建 Stream 的方法。
-
通过
Collection提供的stream()方法或者parallelStream();public class TestLambd1 { @Test public void test() { List<String> list = new ArrayList<>(); Stream<String> stream = list.stream(); } } -
通过
Arrays中的静态方法stream()获取数组流;String[] strs = new String[10]; Stream<String> stream = Arrays.stream(strs); -
通过
Stream类中的静态方法of();Stream<String> stream = Stream.of("a","b","c"); -
创建无限流
迭代:
// Stream.iterate(seed, function) // seed the initial element
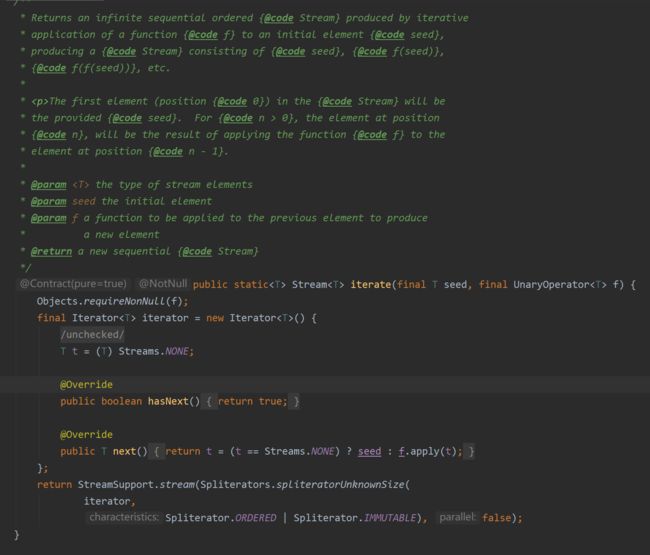
Stream<Integer> stream = Stream.iterate(0, (x) -> x + 2);
生成:
// @param s the {@code Supplier} of generated elements
Stream.generate(s)
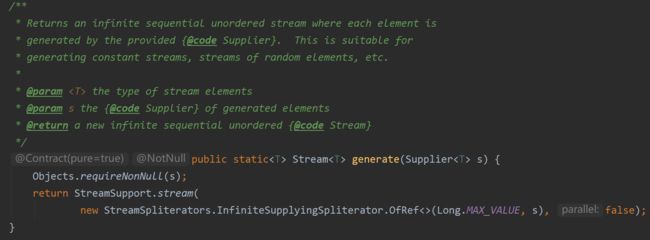
Stream.generate(() -> Math.random());
2.3 中间操作
多个中间操作可以连接起来形成一个流水线,除非流水线上触发终止操作,否则中间操作不会执行任何处理,而终止操作时一次性全部处理,称为惰性求值。
2.3.1 筛选与切片
| 方法 | 描述 |
|---|---|
| filter(Predicate p) | 接收 lambda,从流中排除某些元素。 |
| distinct() | 筛选,通过流所生成元素的 hashCode() 和 equals() 去除重复元素。 |
| limit(long maxSize) | 截断流,使其元素不超过给定数量。 |
| skip(long n) | 跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流,与 limit(n) 互补。 |
- filter 代码:
@SpringBootTest
class DemoApplicationTests {
List<Employee> employees = Arrays.asList(
new Employee("张三", 18, 9999.99),
new Employee("李四", 58, 5555.55),
new Employee("王五", 26, 3333.33),
new Employee("赵六", 36, 6666.66),
new Employee("田七", 12, 8888.88),
new Employee("田七", 12, 8888.88)
);
@Test
void test() {
// 中间操作
Stream<Employee> s = employees.stream()
.filter((e) -> e.getAge() > 35);
// 终止操作
s.forEach(System.out::println);
}
}
====
Employee{name='李四', age=58, salary=5555.55}
Employee{name='赵六', age=36, salary=6666.66}
- limit 代码
@Test
void test() {
employees.stream()
.filter((e) -> {
System.out.println("get..");
return e.getSalary() > 5000;
})
.limit(2)
.forEach(System.out::println);
}
====
// 没有sort,所以按数组索引得到的前两个,得到两个之后就不在继续了。可以简单理解成 a==1 && b==3
// 如果 a 不是 1,那么 b==3 不会执行。
get..
Employee{name='张三', age=18, salary=9999.99}
get..
Employee{name='李四', age=58, salary=5555.55}
- skip 代码:
@Test
void test() {
employees.stream()
.filter((e) -> {
System.out.println("get..");
return e.getSalary() > 5000;
})
.skip(2)
.forEach(System.out::println);
}
====
get..
get..
get..
get..
Employee{name='赵六', age=36, salary=6666.66}
get..
Employee{name='田七', age=12, salary=8888.88}
get..
Employee{name='田七', age=12, salary=8888.88}
- distinct 代码
@Test
void test() {
employees.stream()
.filter((e) -> {
System.out.println("get..");
return e.getSalary() > 5000;
})
.skip(2)
.distinct() // 必须重写 Employee 类的 hashcode 和 equals 方法,因为是通过流所生成元素的 hashCode() 和 equals() 去除重复元素。
.forEach(System.out::println);
}
====
get..
get..
get..
get..
Employee{name='赵六', age=36, salary=6666.66}
get..
Employee{name='田七', age=12, salary=8888.88}
get..
2.3.2 映射
| 方法 | 描述 |
|---|---|
| map(Function f) | 接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成为一个新的元素。 |
| mapToDouble(ToDoubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的 LongStream。 |
| flagMap(Function f) | 接收一个函数作为参数,将流中的每个值都替换成另一个流,然后把所有流连接成一个流。 |
- map 代码
@Test
void test() {
List<String> list = Arrays.asList("aa", "bb", "cc");
list.stream()
.map((str) -> str.toUpperCase()) // 将list所有元素中的小写变成大写
.forEach(System.out::println);
}
===
AA
BB
CC
@Test
void test() {
employees.stream()
.map(Employee::getName) // 提取所有员工名字
.forEach(System.out::println);
}
===
张三
李四
王五
赵六
田七
田七
- flagMap 代码
传统方式把字符串里的字符提取出来并转化成流。
@Test
void test() {
List<String> list = Arrays.asList("aa", "bb", "cc");
// 因为 map 返回的是流,而流中的数据又是流,所以返回值是 Stream>
Stream<Stream<Character>> stream = list.stream()
.map(DemoApplicationTests::filterCharacter);
// 最外层 forEach 遍历的结果是流,需要再遍历一次得到流里流的数据
stream.forEach((sm) -> {
sm.forEach(System.out::println);
});
}
// 将字符串转化成流
public static Stream<Character> filterCharacter(String str) {
List<Character> list = new ArrayList<>();
for (Character ch : str.toCharArray()) {
list.add(ch);
}
return list.stream();
}
===
a
a
b
b
c
c
如果使用 flatmap 也可以得到同样结果:
@Test
void test() {
List<String> list = Arrays.asList("aa", "bb", "cc");
Stream<Character> sm = list.stream()
.flatMap(DemoApplicationTests::filterCharacter);
sm.forEach(System.out::println);
}
public static Stream<Character> filterCharacter(String str) {
List<Character> list = new ArrayList<>();
for (Character ch : str.toCharArray()) {
list.add(ch);
}
return list.stream();
}
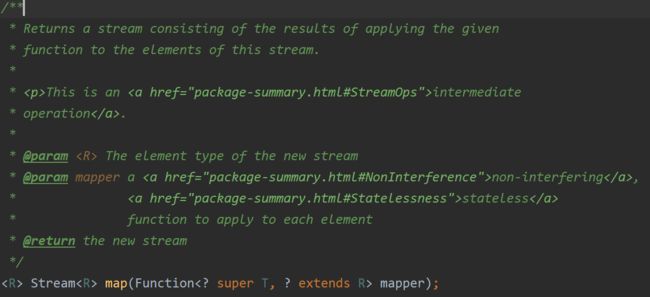
其中 map 的入参和返回值如下,返回值类型是函数式接口返回值的 Stream 类型。即对 Function 而言,T 是入参类型,R 是返回值类型,而所以 map 的返回值是类型是 Stream,所以当传入的函数式接口的返回值是 Stream (R)时,那么 map 得到的值是 Stream (Stream)。
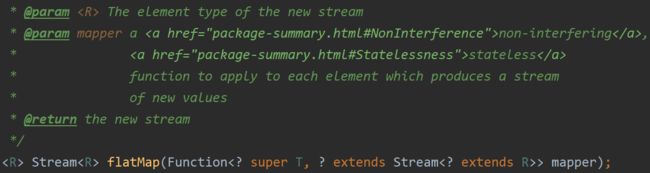
而 flatmap 如下,返回值类型与入参的函数式接口的返回值类型一直,即函数式接口得到的是 Stream 那么 flatmap 得到也是 Stream 。
有点类似 add(Object obj) 和 addAll(Collection coll) 的区别:
List<Object> list = Arrays.asList();
List<Object> list1 = Arrays.asList();
List arrList = new ArrayList(list);
List arrList1 = new ArrayList(list1);
// 得到 {{1, 2}, {3,4}}
// 如果处理的对象是流数据,相当于 map,map 会把多个流放到一个流里
arrList.add(Arrays.asList(1, 2));
arrList.add(Arrays.asList(3, 4));
// 得到 {1, 2, 3, 4}
// 如果处理的对象是流数据,相当于 flatmap,会把多个流对应的元素放到一个流里
arrList1.addAll(Arrays.asList(1, 2));
arrList1.addAll(Arrays.asList(3, 4));
注:由
Arrays.asList()返回的是Arrays的内部类ArrayList,而不是java.util.ArrayList。Arrays的内部类ArrayList和java.util.ArrayList都是继承AbstractList,java.util.ArrayList重写了remove、add等方法,而Arrays的内部类ArrayList没有重写,需要做List arrList = new ArrayList(list);类型转换,否则会抛出UnsupportedOperationException异常。
2.3.3 排序
| 方法 | 描述 |
|---|---|
| sorted() | 产生一个新流,其中按自然顺序排序。 |
| sorted(Comparator comp) | 产生一个新流,其中按比较器顺序排序。 |
-
sorted()代码:void test() { List<String> list = Arrays.asList("b", "a", "c"); list.stream() .sorted() .forEach(System.out::println); } === // 类似 Comparable,String 已经实现了 Comparable,所以得到是字典序排序。 a b c -
sorted(Comparator comp)代码:void test() { employees.stream() .sorted((e1, e2) -> { // 如果年龄相同就按姓名增序排,否则按年龄增序排 if (e1.getAge().equals(e2.getAge())) { return e1.getName().compareTo(e2.getName()); } else { // 如果想倒叙,返回的结果可以直接加负号 return e1.getAge().compareTo(e2.getAge()); } }) .forEach(System.out::println); } === Employee{name='田七', age=12, salary=8888.88} Employee{name='田七', age=12, salary=8888.88} Employee{name='张三', age=18, salary=9999.99} Employee{name='王五', age=26, salary=3333.33} Employee{name='赵六', age=36, salary=6666.66} Employee{name='李四', age=58, salary=5555.55}
2.4 终止操作
2.4.1 查找与匹配
| 方法 | 描述 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素。 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素。 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素。 |
| findFirst() | 返回第一个元素。 |
| findAny() | 返回当前流中的任意元素。 |
| count() | 返回流中元素的总个数。 |
| max(Comparator c) | 返回流中最大值。 |
| min(Comparator c) | 返回流中最小值。 |
| forEach(Comsumer c) | 内部迭代(使用 Collection 接口需要用户去做迭代,称为外部迭代) |
-
前五个方法代码:
@SpringBootTest class DemoApplicationTests { List<Employee> employees = Arrays.asList( new Employee("张三", 18, 9999.99, Status.FREE), new Employee("李四", 58, 5555.55, Status.BUSY), new Employee("王五", 26, 3333.33, Status.VOCATION), new Employee("赵六", 36, 6666.66, Status.FREE), new Employee("田七", 12, 8888.88, Status.BUSY) ); @Test void test() { // 判断所有元素的状态是否都为 BUSY boolean b = employees.stream() .allMatch((e) -> e.getStatus().equals(Status.BUSY)); System.out.println(b); // false // 判断是否有元素的状态为 BUSY boolean b1 = employees.stream() .anyMatch((e) -> e.getStatus().equals(Status.BUSY)); System.out.println(b1); // true // 判断是否所有元素的状态都不为 BUSY boolean b2 = employees.stream() .noneMatch((e) -> e.getStatus().equals(Status.BUSY)); System.out.println(b2); // false // 获取最低工资的信息 // 返回值 Optional 是容器类,把对象放入容器里 // 通过 orElse 方法避免 op 对应的值为空,即解决了空指针异常 // 如果得到的结果有可能为空时,java8 会返回 Optional 类型。 Optional<Employee> op = employees.stream() .sorted((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())) .findFirst(); System.out.println(op.get()); // Employee{name='王五', age=26, salary=3333.33, Status=VOCATION} // 从中找到空闲状态的 employee // 找到一个就取出 Optional<Employee> op1 = employees.stream() .filter((e) -> e.getStatus().equals(Status.FREE)) .findAny(); System.out.println(op1.get()); // Employee{name='张三', age=18, salary=9999.99, Status=FREE} } } -
后三个方法代码:
@Test void test() { // 获取信息总数 Long cnt = employees.stream() .count(); System.out.println(cnt); // 获取最大工资对应的信息 Optional<Employee> op1 = employees.stream() .max((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary())); System.out.println(op1.get()); // 获取最小的工资 Optional<Double> op2 = employees.stream() .map(Employee::getSalary) .min(Double::compare); System.out.println(op2.get()); } === 5 Employee{name='张三', age=18, salary=9999.99, Status=FREE} 3333.33
2.5 归约与收集
2.5.1 归约
| 方法 | 描述 |
|---|---|
| reduce(T identify, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值,返回 T。 |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值,返回 Optional。 |
- reduce(T identify, BinaryOperator b) 代码
@Test
void test() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
Integer sum = list.stream()
.reduce(0, (x, y) -> x + y);
System.out.println(sum);
}
===
15

其中 identity 是计算的初始值,BinaryOperator 是函数式接口,用于两个值计算。在执行第 5 行语句时,首先将 0 作为 x,然后把 1 作为 y,得到的 0+1=1 作为下次的 x,而 2 作为下次的 y,以此类推。
- reduce(BinaryOperator b) 代码
@Test
void test() {
// 计算所有人工资的总和
Optional<Double> op = employees.stream()
.map(Employee::getSalary)
.reduce(Double::sum);
System.out.println(op.get());
}
===
34444.41
2.5.2 收集
| 方法 | 描述 |
|---|---|
| collect(Collector c) | 将流转化为其他形式,接收一个 Collector 接口的实现,用于给 Stream 中元素汇总的方法。 |
Collector 接口中方法的实现决定了如何对流执行收集操作(如收集到 List、Set、Map),但是 Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例。
-
代码一(数据存储)
// 将所有人的名字放到集合中 void test() { List<String> list = employees.stream() .map(Employee::getName) .collect(Collectors.toList()); list.forEach(System.out::println); } === 张三 李四 王五 赵六 田七 -
代码二(数据存储)
// 如果有特殊需求,也可以通过 Collectors.toCollection() 传入其他方法 // 下面是将名字存到 HashSet 中。 void test() { HashSet<String> hashSet = employees.stream() .map(Employee::getName) .collect(Collectors.toCollection(HashSet::new)); hashSet.forEach(System.out::println); } === 李四 张三 王五 赵六 田七 -
代码三(计算)
void test() { // 人员总数 Long count = employees.stream() .collect(Collectors.counting()); System.out.println(count); // 5 // 平均工资 Double avg = employees.stream() .collect(Collectors.averagingDouble(Employee::getSalary)); System.out.println(avg); // 6888.8820000000005 // 工资最大值对应的员工 Optional<Employee> op = employees.stream() .collect(Collectors.maxBy((e1, e2) -> Double.compare(e1.getSalary(), e2.getSalary()))); System.out.println(op.get()); // Employee{name='张三', age=18, salary=9999.99, Status=FREE} // 最小工资 Optional<Double> min = employees.stream() .map(Employee::getSalary) .collect(Collectors.minBy(Double::compare)); System.out.println(min.get()); // 3333.33 } -
代码四(普通分组)
void test() { // 按员工状态分组 Map<Status, List<Employee>> map = employees.stream() .collect(Collectors.groupingBy(Employee::getStatus)); System.out.println(map); } === {VOCATION=[Employee{name='王五', age=26, salary=3333.33, Status=VOCATION}], BUSY=[Employee{name='李四', age=58, salary=5555.55, Status=BUSY}, Employee{name='田七', age=12, salary=8888.88, Status=BUSY}], FREE=[Employee{name='张三', age=18, salary=9999.99, Status=FREE}, Employee{name='赵六', age=36, salary=6666.66, Status=FREE}]} -
代码五(多级分组)
// 先按状态分组,再按年龄分组 void test() { // 按员工状态分组 Map<Status, Map<String, List<Employee>>> map = employees.stream() .collect(Collectors.groupingBy(Employee::getStatus, Collectors.groupingBy((e) -> { if (((Employee) e).getAge() <= 35) { return "青年"; } else if (((Employee) e).getAge() <= 50) { return "中年"; } else { return "老年"; } }))); System.out.println(map); } === {VOCATION={青年=[Employee{name='王五', age=26, salary=3333.33, Status=VOCATION}]}, BUSY={青年=[Employee{name='田七', age=12, salary=8888.88, Status=BUSY}], 老年=[Employee{name='李四', age=58, salary=5555.55, Status=BUSY}]}, FREE={青年=[Employee{name='张三', age=18, salary=9999.99, Status=FREE}], 中年=[Employee{name='赵六', age=36, salary=6666.66, Status=FREE}]}} -
代码六(分区)
// 按照 true false 分,满足条件的一个区,不满足的一个 void test() { Map<Boolean, List<Employee>> map = employees.stream() .collect(Collectors.partitioningBy((e) -> e.getSalary() > 8000)); System.out.println(map); } === {false=[Employee{name='李四', age=58, salary=5555.55, Status=BUSY}, Employee{name='王五', age=26, salary=3333.33, Status=VOCATION}, Employee{name='赵六', age=36, salary=6666.66, Status=FREE}], true=[Employee{name='张三', age=18, salary=9999.99, Status=FREE}, Employee{name='田七', age=12, salary=8888.88, Status=BUSY}]} -
代码七(summary statistics)
// 统计值 void test() { DoubleSummaryStatistics dss = employees.stream() .collect(Collectors.summarizingDouble(Employee::getSalary)); System.out.println(dss.getMax()); System.out.println(dss.getAverage()); System.out.println(dss.getCount()); System.out.println(dss.getMin()); System.out.println(dss.getSum()); } === 9999.99 6888.8820000000005 5 3333.33 34444.41 -
代码八(join)
// 获取所有名字,名字之间逗号分隔 void test() { String str = employees.stream() .map(Employee::getName) .collect(Collectors.joining(",")); System.out.println(str); } === 张三,李四,王五,赵六,田七 // 收尾加字符 void test() { String str = employees.stream() .map(Employee::getName) .collect(Collectors.joining(",", "---", "+++")); System.out.println(str); } === ---张三,李四,王五,赵六,田七+++
3. 并行流与串行流
3.1 简介
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。Stream API 可以声明性的通过 parallel() 与 sequential() 在并行与串行流之间进行切换。
代码:
void test() {
int reduce = IntStream.range(0, 10)
.parallel()
.reduce(0, Integer::sum);
System.out.println(reduce);
}
parallel 主要基于 fork/join 框架,采用 “工作窃取” 模式,当执行新的任务时它可以将其拆分分成更小的任务执行,并将小任务加到线程队列中,然后再从一个随机线程的队列中拿取一个任务并放入自己的队列中。
3.2 Fork/Join 框架
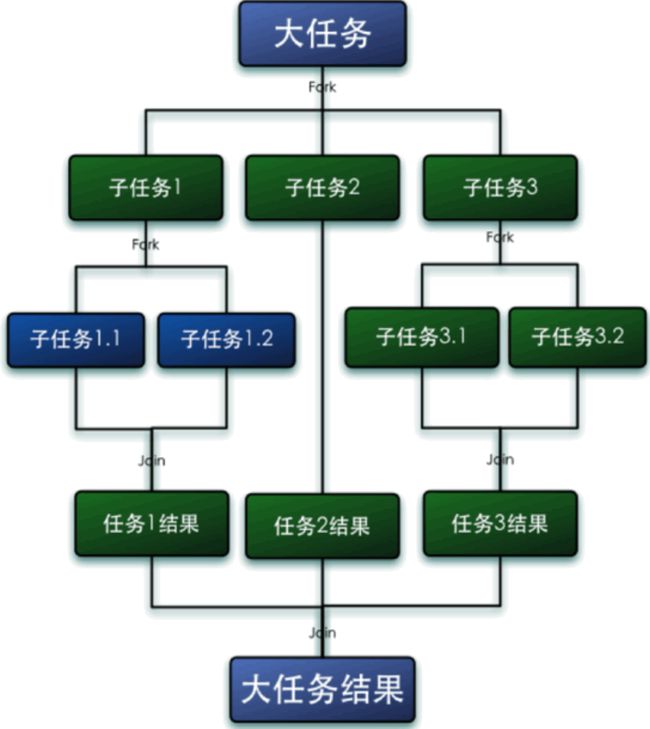
相对于一般的线程池实现,fork/join 框架的优势体现在对其中包含的任务的处理方式上。在一般线程池中,如果一个线程正在执行的任务由于某些原因无法继续执行,那么该线程会处于等待状态。而 fork/join 框架实现中,假设线程 2 优先把分配到自己队列里的任务执行完毕,此时如果线程 1 对应的队列里还有任务等待执行,空闲的线程 2 会窃取线程 1 队列里任务执行,并且为了减少窃取任务时线程 2 和被窃取任务线程 1 之间的发生竞争,队列采用双向队列,窃取任务的线程 2 会从队列的尾部获取任务执行,被窃取任务线程 1 会从队列的头部获取任务执行。
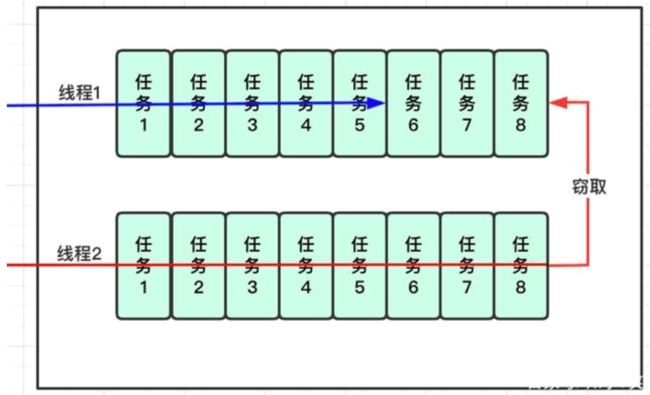
工作窃取算法的优点:线程间的竞争很少,充分利用线程进行并行计算,但是在任务队列里只有一个任务时,也可能会存在竞争情况。
4. Optional 类
4.1 简介
Optional 类(java.util.Optional)是一个容器类,代表一个值存在或不存在,原来用 null 表示一个值不存在,现在 Optional 可以更好的表达这个概念,并且可以避免空指针异常。
常用方法:
Optional.of(T t):创建一个 Optional 实例;Optional.empty():创建一个空的 Optional 实例;Optional.ofNullable(T t):若 t 不为 null,创建 Optional 实例,否则创建空实例;isPresent():判断是否包含值;orElse(T t):如果调用对象包含值,返回该值,否则返回 t;orElseGet(Supplier s):如果调用对象包含值,返回该值,否则返回 s 获取的值;map(Function f):如果有值对其处理,并返回处理后的 Optional,否则返回Optional.empty();flatMap(Function mapper):与 map 类似,要求返回值必须是 Optional。
4.2 相关用法
4.2.1 of 实例创建
void test() {
// 实例创建
Optional<Employee> op = Optional.of(new Employee());
Employee emp = op.get();
System.out.println(emp);
}
===
Employee{name='null', age=0, salary=0.0, Status=null}
4.2.2 相关空实例对比
// Optional.of(null)
Optional<Employee> op = Optional.of(null); // 这里会报错, NullPointerException
// Optional.empty()
Optional<Employee> op2 = Optional.empty();
System.out.println(op2.get()); // java.util.NoSuchElementException: No value present
// Optional.ofNullable(null)
Optional<Employee> op4 = Optional.ofNullable(null);
System.out.println(op4.get()); // java.util.NoSuchElementException: No value present
// Optional.ofNullable
Optional<Employee> op3 = Optional.ofNullable(new Employee());
System.out.println(op3.get()); // Employee{name='null', age=0, salary=0.0, Status=null}
ofNullable() 源码如下:

value 为 null 会创建 empty,所以 Optional.ofNullable(null) 也是在 get 的时候报错,直接打印 op3 结果是:Optional.empty。
4.2.3 避免空值的方法
可以通过 isPresent() 方法或 orElse 等对 Optional 对象进行判断,如果避免报错 java.util.NoSuchElementException: No value present。
// isPresent
void test() {
Optional<Employee> op4 = Optional.ofNullable(null);
if (op4.isPresent()) {
System.out.println(op4);
}
}
===
无打印
// orElse
void test() {
Optional<Employee> op = Optional.ofNullable(null);
// 如果没有值就创建
Employee emp = op.orElse(new Employee("zz", 1, 1, Status.BUSY));
System.out.println(emp);
}
===
Employee{name='zz', age=1, salary=1.0, Status=BUSY}
// orElseGet
void test() {
Optional<Employee> op = Optional.ofNullable(null);
// 可以传入函数式接口
Employee emp = op.orElseGet(() -> new Employee("zz", 1, 1, Status.BUSY));
System.out.println(emp);
}
===
Employee{name='zz', age=1, salary=1.0, Status=BUSY}
4.2.4 map 与 flatMap
-
map 代码
void test() { Optional<Employee> op = Optional.ofNullable(new Employee("zz", 1, 1, Status.BUSY)); Optional<String> str = op.map((e) -> e.getName()); System.out.println(str.get()); } === zz -
flatMap 代码
void test() { Optional<Employee> op = Optional.ofNullable(new Employee("zz", 1, 1, Status.BUSY)); // 要求返回值必须是 Optional,所以加了 Optional.of Optional<String> str = op.flatMap((e) -> Optional.of(e.getName())); System.out.println(str.get()); } === zz