YOLOv3_目标检测
YOLOv3_目标检测
YOLOv1最初是由Joseph Redmon实现的,和大型NLP transformers不同,YOLOv1设计的很小,可为设备上的部署提供实时检测速度。
YOLO-9000是Joseph Redmon实现的第二个版本YOLOv2目标检测器,它对YOLOv1做了很多技巧上的改进,并强调该检测器能够推广到检测世界上的任何物体。
YOLOv3对YOLOv2做了进一步的改进,引入多尺度特征融合,针对不同网格尺寸并行处理,大大提升了不同尺寸目标的检测精度。
文章目录
- YOLOv3_目标检测
- 一、VOC2007数据集
- 二、先验框Anchors聚类
- 三、数据结构编码
- 四、Bounding Box变换
- 五、Loss损失函数
- 六、YOLOv3网络结构
- 七、训练过程
- 八、实验结果
- 九、深入思考
- 十、源码
- 十一、项目链接
一、VOC2007数据集
本次实验我采用的是VOC2007数据集。
我只选用了其中的JEPGImages、Annotations两个文件夹。JEPGImages文件夹含有9963张RGB图片,总共20个类别,Annotations文件夹含有9963个xml文件,分别记录了每张图片中目标物体的类别与信息。

class_dictionary = {'aeroplane': 0, 'bicycle': 1, 'bird': 2, 'boat': 3, 'bottle': 4, 'bus': 5,
'car': 6, 'cat': 7, 'chair': 8, 'cow': 9, 'diningtable': 10, 'dog': 11,
'horse': 12, 'motorbike': 13, 'person': 14, 'pottedplant': 15, 'sheep': 16,
'sofa': 17, 'train': 18, 'tvmonitor': 19}
二、先验框Anchors聚类
在基于anchor的目标检测网络中,一个至关重要的步骤就是科学的设置anchor,可以说anchor设置的合理与否,极大的影响着检测模型最终性能的好坏。
anchor到底是什么?如果用一句话概括,就是在图像上预设好的不同大小、不同长宽比的参照框。如果我们想要去检测某个目标物体,很容易可以想到,该目标物体的长宽比大致是固定的,比如说想要检测人脸,人脸的长宽比会近似在1:1.5。如果我们往模型里预先加入这个先验知识,网络就不必再大费力气重头学起,可以轻松舍弃掉一些不合理的学习结果,模型学习起来更加简单,检测效果自然会更好。
假设有一张416x416大小的图片,经过卷积上采样,得到13x13、26x26、52x52大小的特征图。我们在这三个特征图的每个点都设置三个不同大小的anchor。第一个13 x 13的特征图上设置了13 x 13 x 3 = 507个anchor,尺寸分别是:[179 265]、[303 170]、[371 318]。第二个26 x 26的特征图上设置了26 x 26 x 3 = 2028个anchor,尺寸分别是:[69 52]、[100 196]、[149 112]。第三个52 x 52的特征图上设置了52 x 52 x 3 = 8112个anchor,尺寸分别是:[25 35]、[34 77]、[64 112]。

这9个anchor尺寸是利用k_means算法聚类得到的。

从8000张训练数据集图片中取出所有bounding box,可以得到19670个box,其记录着每个目标物体的w和h。我们对这个二维数据集进行k_means聚类,得到9个聚类中心,并按w和h的大小依次排序,后续在YOLOv3模型中用来设置anchor。
三、数据结构编码
在read_data_path.py文件中,read_image_path()函数用来读取存储图片的绝对路径,read_coordinate_txt()函数用来读取目标物体的位置、种类,都以字符串的形式记录。整个数据集划分成三部分:8000个训练样本、1000个验证样本、963个测试样本。
train_x : (8000,),列表形式
train_y : (8000,),列表形式
val_x : (1000,),列表形式
val_y : (1000,),列表形式
test_x :(963,),列表形式
test_y :(963,),列表形式

在train.py文件中,data_encoding()函数对数据结构进行第一次编码。对于一个batch的train_x,先用opencv读取图片,再像素值除以255归一化,最后resize到(416, 416)尺寸。对于一个batch的train_y,首先将x1、y1、x2、y2转化为center_x、center_y、w、h,然后将center_x、center_y、w、h除以图片长和宽,转化成占整张图片的比例,最后针对每个目标物体的边框,根据IOU计算出最近似的那个anchor,将坐标值存储在那个位置,其他位置全部置0,得到(batch, 13, 13, 3, 25)、(batch, 26, 26, 3, 25)、(batch, 52, 52, 3, 25)的数据结构。
在这里,center_x_ratio、center_y_ratio记录的是占整张图片的比例,而不是针对于每个grid的比例。这一点还需要后续再处理,因为YOLOv3有三种不同尺寸的grid,不适合在这里立马就转换好,最好放在loss函数中用for循环分三种情况分别处理。


在yolov3_loss.py文件中,yolo_loss()函数对数据结构进行第二次编码。对(batch, 13, 13, 3, 25)、(batch, 26, 26, 3, 25)、(batch, 52, 52, 3, 25)的y_true再做处理。针对(13, 13)、(26, 26)、(52, 52)三种的网格,center_x_ratio、center_y_ratio转化成相对于不同小格子的偏移,w_ratio、h_ratio要转化为相对于anchor长宽的偏移。

四、Bounding Box变换
首先必须想明白一个问题:YOLOv3卷积网络最终输出的结果,到底是在拟合什么?
YOLOv1网络最终输出的结果,其实就是目标物体位置的直接刻画;VGG网络最终输出的结果,其实就是分类结果的直接刻画。但YOLOv3完全不同,它借助残差网络的思想,网络学习的不是目标物体位置的直接刻画,而是目标物体位置的残差,这一点可以在解码函数中完全体现出来。

YOLOv3借用了bounding box回归的思想。对真实数据y进行bounding box变换后,拟合起来会更简单,网络学习效果更好。
对于真实y_true:xy要转化成相对于每个小格子的比例,wh要除以最接近的anchor的长宽再取ln,confidence、class不做处理。
对于网络最终输出结果y_pre:xy、confidence、class进行sigmid变换,wh不做处理,此时它们就可以作为真实数据bounding box变换后的数值拟合。
五、Loss损失函数
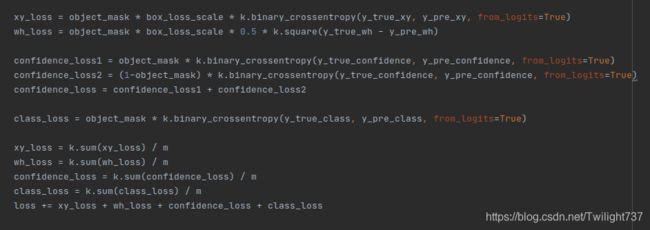
进行bounding box变换后的y_true,与进行sigmoid变换后的y_pre计算损失。代码中y_pre的xy、confidence、class的sigmoid变换,隐藏在k.binary_crossentropy函数的from_logits=True中。
xy、confidence、class采用二项交叉熵损失,wh采用均方误差损失。
六、YOLOv3网络结构
YOLOv3网络主要由两部分构成:第一部分是Darknet_53特征提取网络,第二部分是FPN多尺度特征融合网络。


Darknet_53特征提取网络:由DBL、res1、…、res8构成。DBL可作为YOLOv3网络的最小组建,由一个卷积层一个BN层一个LeakyReLu层组成。整个Darknet_53网络没有池化层和全连接层,所有下采样过程通过卷积stride = 2实现。
FPN多尺度特征融合网络:输出三个尺度的预测结果。对于Darknet_53提取到的特征,先经过一系列的卷积变换,第一个分支输出(13, 13, 75)的预测结果。然后对特征图进行上采样,与之前提取到的特征进行融合,经过一系列的卷积变换,第二个分支输出(26, 26, 75)的预测结果。最后再对特征图进行上采样,与更之前提取到的特征进行融合,经过一系列的卷积变换,第三个分支输出(52, 52, 75)的预测结果。
七、训练过程
网上下载得到yolo_weights.h5网络权重,原模型总共有252层,载入权重后将前249层网络参数冰冻起来,针对特定的数据集,只训练最后3层的网络权重。

总共训练了三天时间,每个epoch花费1.5个小时。
第一轮训练:Adam(lr=1e-3),epoch = 10。train loss从15844.1下降到31.6,val loss从95.7下降到33.5,此时目标检测效果已经不错。

第二轮训练:sgd = optimizers.SGD(lr=1e-4, momentum=0.9),epoch=15。
train loss从32.40下降到26.35,val loss从31.03下降到28.37,此时训练已经达到瓶颈,损失函数很难再降下去。

第三轮训练:sgd = optimizers.SGD(lr=1e-8, momentum=0.9),epoch = 10。
我将学习率调整到一个非常低的水平,期望损失函数能缓慢下降,但结果不尽如人意,train loss和val loss均达到瓶颈,无法再进一步降低了。

八、实验结果
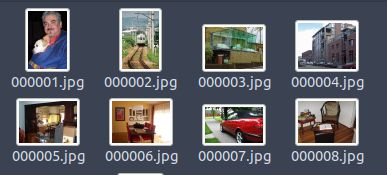
从测试集中随意选取10张图片,检测结果如下:










可以看出,YOLOv3的目标检测效果的确比YOLOv1好太多,在引入anchor机制之后,网络学习出来的边框长宽更加精确,检测效果更好。
九、深入思考
Ques1:YOLOv2对YOLOv1做了哪些改进?
YOLOv2的论文全名为YOLO9000: Better, Faster, Stronger,它斩获了CVPR 2017 Best Paper Honorable Mention。这篇文章包含了两个模型:YOLOv2和YOLO9000,二者的主体结构是一致的,只是YOLO9000采用了一种混合训练的方式,号称能实现9000个类别的目标检测,所以作者给它取名为YOLO9000。
YOLOv2是在YOLOv1的基础上改进得来的,模型主体思路没什么变化,主要是引入了很多cv领域的trick,这些trick大幅提高了目标检测精度。
(1)引入BN层。Batch Normalization可以提升模型收敛速度,而且可以起到一定的正则化效果,降低模型的过拟合。YOLOv2的每个卷积层后面都添加了BN层,使用BN层后,YOLOv2的mAP提升了2.4%。
(2)Anchor Boxes。YOLOv1采用全连接层直接对边框进行预测,边框的宽与高是相对整张图片大小的,由于各个图片中存在不同尺度的物体,训练过程中学习不同物体的形状非常困难,这也导致了YOLOv1在精确定位方面表现较差。YOLOv2借鉴了RPN网络的先验框策略,使得模型更容易学习。使用Anchor boxes之后,YOLOv2的召回率由原来的81%提升至88%。
(3)Dimension Clusters。在Faster RCNN、SSD中,先验框的长宽都是手动设定的,带有一定的主观性,而如果选取的先验框长宽比较合适,模型会更容易学习。YOLOv2利用k-means算法对训练集的边界框做了聚类分析。
(4)Darknet-19特征提取器。YOLOv2采用了一个新的特征提取器Darknet-19,包括19个卷积层和5个maxpooling层,而之前一直都是使用VGG16进行特征提取。
Ques2:YOLOv3对YOLOv2做了哪些改进?
YOLOv3:An Incremental Improvement,按照原文说法,这仅是他们近一年的一个工作报告,并不算一个完整的paper,只是把其它论文的一些工作在YOLO上尝试了一下。相比于YOLOv2,YOLOv3最大的改进包括两点:使用残差模型和采用FPN架构。
YOLOv3的特征提取器是一个包含53个卷积层的残差模型,称为Darknet-53。相比于Darknet-19特征提取器,Darknet-53采用了残差单元所以可以构建得更深。YOLOv3采用FPN实现多尺度检测,通过金字塔特征融合策略,提取得到更好的图像特征。
Ques3:深度学习网络层数构建太深会出现什么问题?
VGG卷积网络达到了19层,GoogleNet卷积网络达到了22层,但实际上算法精度并不会随着网络层数的增多而提高,网络层数过多反而会出现以下问题: 计算资源的消耗、模型容易过拟合、梯度消失、梯度爆炸。
但更重要的是,随着网络层数的增加,网络会发生退化(degradation)现象:
随着网络层数的增多,训练集loss逐渐下降,然后趋于饱和,但如果再增加网络深度的话,训练集loss反而会增大。注意这并不是过拟合,因为过拟合中训练loss是一直减小的,这里训练loss莫名其妙反而变大了。
Ques4:残差网络的思想是什么,为什么能提取得到更好的特征?
当网络发生退化时,浅层网络能够达到比深层网络更好的特征提取效果,这时如果我们把浅层的特征也传递到深层,那么最终效果至少不会比浅层网络差。如果在VGG的第98层和VGG的第14层之间添加一条直接映射,网络的特征提取效果会更佳。
从信息论的角度理解,前向传输过程中随着层数的加深,Feature Map包含的图像信息会逐层减少,而残差网络直接映射的加入,保证了第l+1层的网络一定比第l层包含更多的图像信息。基于这种直接映射跨层连接的思想,残差网络应运而生。
Ques5:YOLOv3为什么能解决同一位置检测多个重叠的目标?
YOLOv1算法中图片被划分为(7, 7)的网格,每个grid只能检测该网格内一个目标物体。
YOLOv3算法引入了多尺度检测,图片具有(13, 13)、(26, 26)、(52, 52)三种网格划分。目标物体重叠情况下,虽然目标物体的位置相同,但它们的长宽尺寸往往不同。尽管此时每个grid还是只负责一个目标物体的检测,但借助三种不同尺度,YOLOv3可以实现同一位置多个重叠目标的检测。
Ques6:YOLOv3是如何融入Anchors思想的?
关于如何将Anchors思想融入模型算法中,YOLOv3和Faster RCNN处理方法完全不同。
Faster RCNN类似于RCNN的思路,先在原图上生成许许多多的anchors,把它们作为候选区域,一个一个的进行分类和回归调整。而YOLOv3完全不同,它直接在输出数据结构上融入anchors,网络最终输出的结果,就代表着针对不同anchors的位置调整情况。
Ques7:总结一下自己复现YOLOv3时代码出的BUG。
(1)训练数据y结构出错,代码无法运行。最后找到错误原因,针对训练数据y我之前设置的是(batch, 3)的结构,其中每个代表的含义是zeros(13, 13, 3, 25), zeros(26, 26, 3, 25), zeros(52, 52, 3, 25)。实际上要改成[zeros(batch, 13, 13, 3, 25), zeros(batch, 13, 13, 3, 25), zeros(batch, 13, 13, 3, 25)]的结构。
(2)训练起始阶段损失函数值巨大,50万的loss。查找后发现,训练数据结构转换中出了问题,写成了center_x / w, center_y / h,改成center_x / size[1], center_y / size[2]后训练就正常了,起始阶段loss在15000左右。
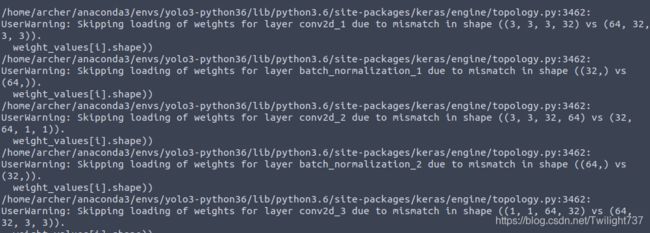
(3)训练过程中,train loss能不断减小到几十,但val loss依然是上千之巨降低不了。之前在YOLOv1训练过程中也遇到这个问题,最后发现是权重文件加载不匹配,特征提取层未能读取到正确权重就被冰冻起来了。

我重新运行convert.py文件,转化生成yolo_weights.h5,权重文件被成功加载。
之前权重文件加载失败:
之后权重文件加载成功:

(4)最后我还发现源码逻辑上的一个BUG。
源码在生成Anchors时,是直接对图片数据集中目标物体的边框进行聚类。但在实际网络拟合中,图片被resize到(416, 416)大小,我由原边框长宽设计出来的先验信息,并没起到想要的效果。因此在生成Anchors时,应该先把图片数据集中目标物体边框长宽先缩放,让它与网络实际处理过程所拟合的数值相匹配。
十、源码
数据集读取:
import os
import xml.etree.ElementTree as ET
class_dictionary = {'aeroplane': 0, 'bicycle': 1, 'bird': 2, 'boat': 3, 'bottle': 4, 'bus': 5,
'car': 6, 'cat': 7, 'chair': 8, 'cow': 9, 'diningtable': 10, 'dog': 11,
'horse': 12, 'motorbike': 13, 'person': 14, 'pottedplant': 15, 'sheep': 16,
'sofa': 17, 'train': 18, 'tvmonitor': 19}
class_list = list(class_dictionary.keys())
def read_image_path():
data_x = []
filename = os.listdir('/home/archer/CODE/YOLOv3/JPEGImages')
filename.sort()
for name in filename:
path = '/home/archer/CODE/YOLOv3/JPEGImages/' + name
data_x.append(path)
print('JPEGImages has been download ! ')
return data_x
def read_coordinate_txt():
data_y = []
filename = os.listdir('/home/archer/CODE/YOLOv3/Annotations')
filename.sort()
for name in filename:
tree = ET.parse('/home/archer/CODE/YOLOv3/Annotations/' + name)
root = tree.getroot()
coordinate = ''
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in class_list or int(difficult) == 1:
continue
cls_id = class_list.index(cls)
xml_box = obj.find('bndbox')
x_min = int(xml_box.find('xmin').text)
y_min = int(xml_box.find('ymin').text)
x_max = int(xml_box.find('xmax').text)
y_max = int(xml_box.find('ymax').text)
loc = (str(x_min) + ',' + str(y_min) + ',' + str(x_max) + ',' + str(y_max) + ',' + str(cls_id) + ' ')
coordinate = coordinate + loc
data_y.append(coordinate)
print('Object Coordinate has been download ! ')
return data_y
def make_data():
data_x = read_image_path()
data_y = read_coordinate_txt()
n = len(data_x)
train_x = data_x[0:8000]
train_y = data_y[0:8000]
val_x = data_x[8000:9000]
val_y = data_y[8000:9000]
test_x = data_x[9000:n]
test_y = data_y[9000:n]
return train_x, train_y, val_x, val_y, test_x, test_y
Anchors生成:
import numpy as np
import cv2
# the anchor_iou between 19670 box and 9 clusters
def anchor_iou(boxes, clusters):
n = boxes.shape[0] # 19670
k = clusters.shape[0] # 9
box_area = boxes[:, 0] * boxes[:, 1] # 19670
# repeat function : [1 1 1 2 2 2 3 3 3]
box_area = box_area.repeat(k) # 19670 * 9 = 177030
box_area = np.reshape(box_area, (n, k)) # (19670, 9), every column is the box_area vector
cluster_area = clusters[:, 0] * clusters[:, 1] # 9
# tile function : [1 2 3 1 2 3 1 2 3]
cluster_area = np.tile(cluster_area, [1, n]) # 9 * 19670 = 177030
cluster_area = np.reshape(cluster_area, (n, k)) # (19670, 9), every row is the cluster_area vector
box_w_matrix = np.reshape(boxes[:, 0].repeat(k), (n, k)) # (19670, 9)
cluster_w_matrix = np.reshape(np.tile(clusters[:, 0], (1, n)), (n, k)) # (19670, 9)
min_w_matrix = np.minimum(cluster_w_matrix, box_w_matrix) # (19670, 9)
box_h_matrix = np.reshape(boxes[:, 1].repeat(k), (n, k)) # (19670, 9)
cluster_h_matrix = np.reshape(np.tile(clusters[:, 1], (1, n)), (n, k)) # (19670, 9)
min_h_matrix = np.minimum(cluster_h_matrix, box_h_matrix) # (19670, 9)
inter_area = np.multiply(min_w_matrix, min_h_matrix) # (19670, 9)
iou = inter_area / (box_area + cluster_area - inter_area) # (19670, 9)
return iou
def k_means(box, k):
box_number = len(box) # 19670
last_nearest = np.zeros(box_number)
# init k clusters
np.random.seed(1)
clusters = box[np.random.choice(box_number, k, replace=False)]
# (9, 2)
while True:
# calculate the iou_distance between 19670 boxes and 9 clusters
# distance : (19670, 9)
distances = 1 - anchor_iou(box, clusters)
# calculate the mum anchor index for 19670 boxes
# current_nearest : (19670, 1)
current_nearest = np.argmin(distances, axis=1)
if (last_nearest == current_nearest).all():
break
for num in range(k):
clusters[num] = np.median(box[current_nearest == num], axis=0)
last_nearest = current_nearest
return clusters
def calculate_anchor(train_x, train_y):
box = []
# len(train_y) : 19670
for i in range(len(train_y)):
img = cv2.imread(train_x[i])
size = img.shape
obj_all = train_y[i].strip().split()
for j in range(len(obj_all)):
obj = obj_all[j].split(',')
x1, y1, x2, y2 = [int(obj[0]), int(obj[1]), int(obj[2]), int(obj[3])]
w = x2 - x1
h = y2 - y1
w = int(w / size[1] * 416)
h = int(h / size[0] * 416)
box.append([w, h])
box = np.array(box)
# box : (19670, 2)
anchors = k_means(box, 9)
# anchors : (9, 2)
index = np.argsort(anchors[:, 0])
# [0 5 6 8 2 7 4 3 1]
anchors = anchors[index]
# [[22 37]
# [26 82]
# [49 132]
# [56 57]
# [89 211]
# [113 108]
# [162 298]
# [238 177]
# [341 340]]
return anchors
YOLOv3模型结构:
from functools import reduce
from keras.layers import Conv2D, Add, ZeroPadding2D, UpSampling2D, Concatenate, Input
from keras.layers.advanced_activations import LeakyReLU
from keras.layers.normalization import BatchNormalization
from keras.models import Model
from keras.regularizers import l2
from functools import wraps
def compose(*funcs):
# Compose arbitrarily many functions, evaluated left to right.
# Reference: https://mathieularose.com/function-composition-in-python/
# return lambda x: reduce(lambda v, f: f(v), funcs, x)
if funcs:
return reduce(lambda f, g: lambda *a, **kw: g(f(*a, **kw)), funcs)
else:
raise ValueError('Composition of empty sequence not supported.')
@wraps(Conv2D)
def DarknetConv2D(*args, **kwargs):
darknet_conv_kwargs = {'kernel_regularizer': l2(5e-4)}
darknet_conv_kwargs['padding'] = 'valid' if kwargs.get('strides') == (2, 2) else 'same'
darknet_conv_kwargs.update(kwargs)
return Conv2D(*args, **darknet_conv_kwargs)
def DarknetConv2D_BN_Leaky(*args, **kwargs):
no_bias_kwargs = {'use_bias': False}
no_bias_kwargs.update(kwargs)
return compose(
DarknetConv2D(*args, **no_bias_kwargs),
BatchNormalization(),
LeakyReLU(alpha=0.1))
def resblock_body(x, num_filters, num_blocks):
# Darknet uses left and top padding instead of 'same' mode
x = ZeroPadding2D(((1, 0), (1, 0)))(x)
x = DarknetConv2D_BN_Leaky(num_filters, (3, 3), strides=(2, 2))(x)
for i in range(num_blocks):
y = compose(
DarknetConv2D_BN_Leaky(num_filters//2, (1, 1)),
DarknetConv2D_BN_Leaky(num_filters, (3, 3)))(x)
x = Add()([x, y])
return x
def darknet_body(x):
x = DarknetConv2D_BN_Leaky(32, (3, 3))(x)
x = resblock_body(x, 64, 1)
x = resblock_body(x, 128, 2)
x = resblock_body(x, 256, 8)
x = resblock_body(x, 512, 8)
x = resblock_body(x, 1024, 4)
return x
def make_last_layers(x, num_filters, out_filters):
x = compose(
DarknetConv2D_BN_Leaky(num_filters, (1, 1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3, 3)),
DarknetConv2D_BN_Leaky(num_filters, (1, 1)),
DarknetConv2D_BN_Leaky(num_filters*2, (3, 3)),
DarknetConv2D_BN_Leaky(num_filters, (1, 1)))(x)
y = compose(
DarknetConv2D_BN_Leaky(num_filters*2, (3, 3)),
DarknetConv2D(out_filters, (1, 1)))(x)
return x, y
def create_yolo_model():
# Create YOLO_V3 model CNN body in Keras
inputs = Input((416, 416, 3))
darknet = Model(inputs, darknet_body(inputs))
# darknet.summary()
x, y1 = make_last_layers(darknet.output, 512, 75)
x = compose(DarknetConv2D_BN_Leaky(256, (1, 1)), UpSampling2D(2))(x)
x = Concatenate()([x, darknet.layers[152].output])
x, y2 = make_last_layers(x, 256, 75)
x = compose(DarknetConv2D_BN_Leaky(128, (1, 1)), UpSampling2D(2))(x)
x = Concatenate()([x, darknet.layers[92].output])
x, y3 = make_last_layers(x, 128, 75)
yolo3_model = Model(inputs, [y1, y2, y3])
yolo3_model.summary()
return yolo3_model
损失函数:
from keras import backend as k
import numpy as np
with open("yolo_anchors.txt", "r") as f:
string = f.read().strip().split(',')
anchors = [int(s) for s in string]
anchors = np.reshape(anchors, (9, 2))
def yolo_head(y_pre_part):
# y_pre_part : Tensor, shape=(batch, 13, 13, 75), float32
grid_shape = k.shape(y_pre_part)[1:3]
# Tensor, shape=(2, ), [13 13]
grid_y = k.tile(k.reshape(k.arange(0, stop=grid_shape[0]), [-1, 1, 1, 1]), [1, grid_shape[1], 1, 1])
# Tensor, shape=(13, 13, 1, 1), int32
grid_x = k.tile(k.reshape(k.arange(0, stop=grid_shape[1]), [1, -1, 1, 1]), [grid_shape[0], 1, 1, 1])
# Tensor, shape=(13, 13, 1, 1), int32
grid = k.concatenate([grid_x, grid_y])
# Tensor, shape=(13, 13, 1, 2), int32
grid = k.cast(grid, k.dtype(y_pre_part))
# Tensor, shape=(13, 13, 1, 2), float32
return grid
def yolo_loss(args):
y_pre = args[:3]
y_true = args[3:]
# y_pre : [ Tensor (batch, 13, 13, 75) , Tensor (batch, 26, 26, 75) , Tensor (batch, 52, 52, 75) ]
# y_true : [ Tensor (batch, 13, 13, 3, 25) , Tensor (batch, 26, 26, 3, 25) , Tensor (batch, 52, 52, 3, 25) ]
# little grid predict large bounding box and
# large grid predict little bounding box
anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
input_shape = k.shape(y_pre[0])[1:3] * 32
input_shape = k.cast(input_shape, k.dtype(y_true[0]))
# [13, 13] * 32 = [416, 416] - tensor, float
grid_shapes = [k.cast(k.shape(y_pre[l])[1:3], k.dtype(y_true[0])) for l in range(3)]
# [[13, 13]-tensor, [26, 26]-tensor, [52, 52]-tensor]
loss = 0
m = k.cast(k.shape(y_pre[0])[0], k.dtype(y_pre[0])) # batch size, tensor-32, float
for l in range(3):
# y_pre[l] : shape=(batch, ?, ?, 75), float32
# single_y_pre : shape=(batch, ?, ?, 3, 25), float32
# grid : shape=(?, ?, 1, 2), float32
grid_shape = k.shape(y_pre[l])[1:3] # Tensor, shape=(2, ), [13, 13] or [26, 26] or [52, 52]
single_y_pre = k.reshape(y_pre[l], [-1, grid_shape[0], grid_shape[1], 3, 25])
# Tensor, shape=(batch, ?, ?, 3, 25), float32
grid = yolo_head(y_pre[l])
# Tensor, shape=(?, ?, 1, 2), float32
# calculate the y_true_confidence, y_true_class, y_true_xy, y_true_wh---------------------------------------
y_true_confidence = y_true[l][..., 4:5] # Tensor, (batch, 13, 13, 3, 1), float32
object_mask = y_true_confidence
y_true_class = y_true[l][..., 5:] # Tensor, (batch, 13, 13, 3, 20), float32
y_true_xy = y_true[l][..., :2]*grid_shapes[l][::-1] - grid # Tensor, shape=(batch, 13, 13, 3, 2), float32
y_true_wh = k.log(y_true[l][..., 2:4] / anchors[anchor_mask[l]] * input_shape[::-1])
y_true_wh = k.switch(object_mask, y_true_wh, k.zeros_like(y_true_wh))
# avoid log(0)=-inf
# Tensor, shape=(batch, 13, 13, 3, 2), float32
box_loss_scale = 2 - y_true[l][..., 2:3] * y_true[l][..., 3:4]
# Tensor, shape=(batch, 13, 13, 3, 1), float32
# calculate the y_pre_confidence, y_pre_class, y_pre_xy, y_pre_wh-----------------------------------------
y_pre_confidence = single_y_pre[..., 4:5]
# Tensor, shape=(batch, 13, 13, 3, 1), float32
y_pre_class = single_y_pre[..., 5:]
# Tensor, shape=(batch, 13, 13, 3, 20), float32
y_pre_xy = single_y_pre[..., 0:2]
# Tensor, shape=(batch, 13, 13, 3, 2), float32
y_pre_wh = single_y_pre[..., 2:4]
# Tensor, shape=(batch, 13, 13, 3, 2), float32
# calculate the sum loss ---------------------------------------------------------------------------------
xy_loss = object_mask * box_loss_scale * k.binary_crossentropy(y_true_xy, y_pre_xy, from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * k.square(y_true_wh - y_pre_wh)
confidence_loss1 = object_mask * k.binary_crossentropy(y_true_confidence, y_pre_confidence, from_logits=True)
confidence_loss2 = (1-object_mask) * k.binary_crossentropy(y_true_confidence, y_pre_confidence, from_logits=True)
confidence_loss = confidence_loss1 + confidence_loss2
class_loss = object_mask * k.binary_crossentropy(y_true_class, y_pre_class, from_logits=True)
xy_loss = k.sum(xy_loss) / m
wh_loss = k.sum(wh_loss) / m
confidence_loss = k.sum(confidence_loss) / m
class_loss = k.sum(class_loss) / m
loss += xy_loss + wh_loss + confidence_loss + class_loss
return loss
训练函数:
import numpy as np
from keras.models import load_model
import cv2
import yolov3_model
from yolov3_loss import yolo_loss
from keras.utils import Sequence
import math
from keras.callbacks import ModelCheckpoint
from keras import optimizers
from keras.models import Model
from keras.layers import Input, Lambda
from keras.optimizers import Adam
with open("yolo_anchors.txt", "r") as f:
string = f.read().strip().split(',')
anchors = [int(s) for s in string]
anchors = np.reshape(anchors, (9, 2))
# [[22 37]
# [26 82]
# [49 132]
# [56 57]
# [89 211]
# [113 108]
# [162 298]
# [238 177]
# [341 340]]
def max_iou_index(w, h):
# (w, h) : 253 177
box_area = np.array([w * h]).repeat(9)
# box_area : [44781 44781 44781 44781 44781 44781 44781 44781 44781]
anchor_area = anchors[:, 0] * anchors[:, 1]
# anchor_area : [875 2618 7168 3588 19600 16688 47435 51510 117978]
anchor_w_matrix = anchors[:, 0]
# anchor_w_matrix : [25 34 64 69 100 149 179 303 371]
min_w_matrix = np.minimum(anchor_w_matrix, w)
# min_w_matrix : [25 34 64 69 100 149 179 253 253]
anchor_h_matrix = anchors[:, 1]
# anchor_h_matrix : [35 77 112 52 196 112 265 170 318]
min_h_matrix = np.minimum(anchor_h_matrix, h)
# min_h_matrix : [35 77 112 52 177 112 177 170 177]
inter_area = np.multiply(min_w_matrix, min_h_matrix)
# inter_area : [875 2618 7168 3588 17700 16688 31683 43010 44781]
iou = inter_area / (box_area + anchor_area - inter_area)
# iou : [0.01953954 0.05846229 0.16006789 0.08012327 0.37916926 0.37265805 0.52340046 0.80722959 0.37957077]
index = np.argmax(iou)
return index
def data_encoding(batch_image_path, batch_true_boxes):
# batch_image_path : (32, str), str recorded the image path
# batch_true_boxes : (32, str), str has absolute x_min, y_min, x_max, y_max, class_id
# encoding_y : x、y、w、h are relative value
anchor_mask = [[6, 7, 8], [3, 4, 5], [0, 1, 2]]
grid_shapes = [[13, 13], [26, 26], [52, 52]]
batch_encoding_y = [np.zeros((32, 13, 13, 3, 25)), np.zeros((32, 26, 26, 3, 25)), np.zeros((32, 52, 52, 3, 25))]
batch_images = []
for i in range(len(batch_true_boxes)):
img = cv2.imread(batch_image_path[i])
size = img.shape
img1 = img / 255
resize_img = cv2.resize(img1, (416, 416), interpolation=cv2.INTER_AREA)
batch_images.append(resize_img)
obj_all = batch_true_boxes[i].strip().split()
for j in range(len(obj_all)):
obj = obj_all[j].split(',')
x1, y1, x2, y2 = [int(obj[0]), int(obj[1]), int(obj[2]), int(obj[3])]
category = int(obj[4]) # 0 - 19
center_x = (x1 + x2) / 2
center_y = (y1 + y2) / 2
w = x2 - x1
h = y2 - y1
center_x_ratio = center_x / size[1]
center_y_ratio = center_y / size[0]
w_ratio = w / size[1]
h_ratio = h / size[0]
anchor_index = max_iou_index(w, h)
for num in range(3):
if anchor_index in anchor_mask[num]:
# anchor_mask[0] : [6, 7, 8]
# anchor_mask[1] : [3, 4, 5]
# anchor_mask[0] : [0, 1, 2]
inner_index = anchor_mask[num].index(anchor_index) # 0 or 1 or 2
grid_x = int(center_x / size[1] * grid_shapes[num][1])
grid_y = int(center_y / size[0] * grid_shapes[num][0])
batch_encoding_y[num][i, grid_y, grid_x, inner_index, 0:4] = np.array([center_x_ratio,
center_y_ratio,
w_ratio, h_ratio])
batch_encoding_y[num][i, grid_y, grid_x, inner_index, 4] = 1
batch_encoding_y[num][i, grid_y, grid_x, inner_index, 5 + category] = 1
return batch_images, batch_encoding_y
class SequenceData(Sequence):
def __init__(self, data_x, data_y, batch_size):
self.batch_size = batch_size
self.data_x = data_x
self.data_y = data_y
self.indexes = np.arange(len(self.data_x))
def __len__(self):
return math.floor(len(self.data_x) / float(self.batch_size))
def on_epoch_end(self):
np.random.shuffle(self.indexes)
def __getitem__(self, idx):
batch_index = self.indexes[idx * self.batch_size:(idx + 1) * self.batch_size]
batch_x = [self.data_x[k] for k in batch_index]
batch_y = [self.data_y[k] for k in batch_index]
x, y = data_encoding(batch_x, batch_y)
x = np.array(x)
return [x, *y], np.zeros(32)
# create model and train and save
def train_network(train_generator, validation_generator, epoch):
model_body = yolov3_model.create_yolo_model()
model_body.load_weights('/home/archer/CODE/YOLOv3/yolo_weights.h5', by_name=True, skip_mismatch=True)
print('model_body layers : ', len(model_body.layers))
for i in range(249):
model_body.layers[i].trainable = False
print('249 Layers has been frozen ! ')
grid_shape = np.array([[13, 13], [26, 26], [52, 52]])
y_true = [Input(shape=(grid_shape[l, 0], grid_shape[l, 1], 3, 25)) for l in range(3)]
# [Tensor-(?, 13, 13, 3, 25), Tensor-(?, 26, 26, 3, 25), Tensor-(?, 52, 52, 3, 25)]
model_loss = Lambda(yolo_loss, output_shape=(1, ), name='yolo_loss')([*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
# model_body.input : Tensor, shape=(?, 416, 416, 3), float32
model.compile(optimizer=Adam(lr=1e-3), loss={'yolo_loss': lambda y_true, y_pre: y_pre})
checkpoint = ModelCheckpoint('/home/archer/CODE/YOLOv3/best_weights.hdf5', monitor='val_loss',
save_weights_only=True, save_best_only=True)
model.fit_generator(
train_generator,
steps_per_epoch=len(train_generator),
epochs=epoch,
validation_data=validation_generator,
validation_steps=len(validation_generator),
callbacks=[checkpoint]
)
model_body.save_weights('first_weights.hdf5')
def load_network_then_train(train_generator, validation_generator, epoch, input_name, output_name):
model_body = yolov3_model.create_yolo_model()
model_body.load_weights(input_name, by_name=True, skip_mismatch=True)
for i in range(249):
model_body.layers[i].trainable = False
grid_shape = np.array([[13, 13], [26, 26], [52, 52]])
y_true = [Input(shape=(grid_shape[l, 0], grid_shape[l, 1], 3, 25)) for l in range(3)]
model_loss = Lambda(yolo_loss, output_shape=(1,), name='yolo_loss')([*model_body.output, *y_true])
model = Model([model_body.input, *y_true], model_loss)
sgd = optimizers.SGD(lr=1e-8, momentum=0.9)
model.compile(optimizer=sgd, loss={'yolo_loss': lambda y_true, y_pre: y_pre})
checkpoint = ModelCheckpoint('/home/archer/CODE/YOLOv3/best_weights.hdf5', monitor='val_loss',
save_weights_only=True, save_best_only=True)
model.fit_generator(
train_generator,
steps_per_epoch=len(train_generator),
epochs=epoch,
validation_data=validation_generator,
validation_steps=len(validation_generator),
callbacks=[checkpoint]
)
model.save_weights(output_name)
main函数调用:
import numpy as np
import cv2
import read_data_path as rp
import get_anchors as ga
import yolov3_model as ym
import train as tr
class_dictionary = {'aeroplane': 0, 'bicycle': 1, 'bird': 2, 'boat': 3, 'bottle': 4, 'bus': 5,
'car': 6, 'cat': 7, 'chair': 8, 'cow': 9, 'diningtable': 10, 'dog': 11,
'horse': 12, 'motorbike': 13, 'person': 14, 'pottedplant': 15, 'sheep': 16,
'sofa': 17, 'train': 18, 'tvmonitor': 19}
class_list = list(class_dictionary.keys())
def txt_document(matrix):
f = open("yolo_anchors.txt", 'w')
row = np.shape(matrix)[0]
for i in range(row):
if i == 0:
x_y = "%d,%d" % (matrix[i][0], matrix[i][1])
else:
x_y = ", %d,%d" % (matrix[i][0], matrix[i][1])
f.write(x_y)
f.close()
def sigmoid(x):
return 1/(1 + np.exp(-x))
if __name__ == "__main__":
train_x, train_y, val_x, val_y, test_x, test_y = rp.make_data()
anchors = ga.calculate_anchor(train_x, train_y)
# [[22 37]
# [26 82]
# [49 132]
# [56 57]
# [89 211]
# [113 108]
# [162 298]
# [238 177]
# [341 340]]
txt_document(anchors)
print('The anchors have been documented ! ')
train_generator = tr.SequenceData(train_x, train_y, 32)
validation_generator = tr.SequenceData(val_x, val_y, 32)
# tr.train_network(train_generator, validation_generator, epoch=10)
# tr.load_network_then_train(train_generator, validation_generator, epoch=15,
# input_name='first_weights.hdf5', output_name='second_weights.hdf5')
yolo3_model = ym.create_yolo_model()
yolo3_model.load_weights('second_weights.hdf5')
for i in range(len(train_x) - 1010, len(train_x) - 999):
img1 = cv2.imread(train_x[i])
size = img1.shape
img2 = img1 / 255
img3 = cv2.resize(img2, (416, 416), interpolation=cv2.INTER_AREA)
img4 = img3[np.newaxis, :, :, :]
pre = yolo3_model.predict(img4)
pre_13 = np.reshape(pre[0][0], [13, 13, 3, 25])
pre_26 = np.reshape(pre[1][0], [26, 26, 3, 25])
pre_52 = np.reshape(pre[2][0], [52, 52, 3, 25])
grid_y_13 = np.tile(np.reshape(np.arange(0, 13), [-1, 1]), [1, 13]) * size[0] / 13
# 0 0 0 ...
# 32 32 32 ...
# ... ... ...
# 384 384 384 ...
grid_x_13 = np.tile(np.reshape(np.arange(0, 13), [1, -1]), [13, 1]) * size[1] / 13
# 0 32 64 ...
# 0 32 64 ...
# ... ... ...
# 0 32 64 ...
grid_y_26 = np.tile(np.reshape(np.arange(0, 26), [-1, 1]), [1, 26]) * size[0] / 26 # (26, 26)
grid_x_26 = np.tile(np.reshape(np.arange(0, 26), [1, -1]), [26, 1]) * size[1] / 26 # (26, 26)
grid_y_52 = np.tile(np.reshape(np.arange(0, 52), [-1, 1]), [1, 52]) * size[0] / 52 # (52, 52)
grid_x_52 = np.tile(np.reshape(np.arange(0, 52), [1, -1]), [52, 1]) * size[1] / 52 # (52, 52)
for j in range(3):
pre_13[:, :, j, 0] = sigmoid(pre_13[:, :, j, 0]) * size[1] / 13 + grid_x_13
pre_13[:, :, j, 1] = sigmoid(pre_13[:, :, j, 1]) * size[0] / 13 + grid_y_13
pre_13[:, :, j, 2] = np.exp(pre_13[:, :, j, 2]) * anchors[j + 6, 0]
pre_13[:, :, j, 3] = np.exp(pre_13[:, :, j, 3]) * anchors[j + 6, 1]
pre_13[:, :, j, 4] = sigmoid(pre_13[:, :, j, 4])
pre_13[:, :, j, 5:] = sigmoid(pre_13[:, :, j, 5:])
pre_26[:, :, j, 0] = sigmoid(pre_26[:, :, j, 0]) * size[1] / 26 + grid_x_26
pre_26[:, :, j, 1] = sigmoid(pre_26[:, :, j, 1]) * size[0] / 26 + grid_y_26
pre_26[:, :, j, 2] = np.exp(pre_26[:, :, j, 2]) * anchors[j + 3, 0]
pre_26[:, :, j, 3] = np.exp(pre_26[:, :, j, 3]) * anchors[j + 3, 1]
pre_26[:, :, j, 4] = sigmoid(pre_26[:, :, j, 4])
pre_26[:, :, j, 5:] = sigmoid(pre_26[:, :, j, 5:])
pre_52[:, :, j, 0] = sigmoid(pre_52[:, :, j, 0]) * size[1] / 52 + grid_x_52
pre_52[:, :, j, 1] = sigmoid(pre_52[:, :, j, 1]) * size[0] / 52 + grid_y_52
pre_52[:, :, j, 2] = np.exp(pre_52[:, :, j, 2]) * anchors[j, 0]
pre_52[:, :, j, 3] = np.exp(pre_52[:, :, j, 3]) * anchors[j, 1]
pre_52[:, :, j, 4] = sigmoid(pre_52[:, :, j, 4])
pre_52[:, :, j, 5:] = sigmoid(pre_52[:, :, j, 5:])
candidate_box = []
for k1 in range(13):
for k2 in range(13):
for k3 in range(3):
if pre_13[k1, k2, k3, 4] > 0.1:
center_x = pre_13[k1, k2, k3, 0]
center_y = pre_13[k1, k2, k3, 1]
w = pre_13[k1, k2, k3, 2]
h = pre_13[k1, k2, k3, 3]
confidence = pre_13[k1, k2, k3, 4]
category = np.argmax(pre_13[k1, k2, k3, 5:])
x1 = center_x - w/2
y1 = center_y - h/2
x2 = center_x + w/2
y2 = center_y + h/2
category = int(category)
candidate_box.append([x1, y1, x2, y2, confidence, category])
print('Grid 13 * 13 :', x1, y1, x2, y2, confidence, category)
for k1 in range(26):
for k2 in range(26):
for k3 in range(3):
if pre_26[k1, k2, k3, 4] > 0.1:
center_x = pre_26[k1, k2, k3, 0]
center_y = pre_26[k1, k2, k3, 1]
w = pre_26[k1, k2, k3, 2]
h = pre_26[k1, k2, k3, 3]
confidence = pre_26[k1, k2, k3, 4]
category = np.argmax(pre_26[k1, k2, k3, 5:])
x1 = center_x - w / 2
y1 = center_y - h / 2
x2 = center_x + w / 2
y2 = center_y + h / 2
category = int(category)
candidate_box.append([x1, y1, x2, y2, confidence, category])
print('Grid 26 * 26 :', x1, y1, x2, y2, confidence, category)
for k1 in range(52):
for k2 in range(52):
for k3 in range(3):
if pre_52[k1, k2, k3, 4] > 0.1:
center_x = pre_52[k1, k2, k3, 0]
center_y = pre_52[k1, k2, k3, 1]
w = pre_52[k1, k2, k3, 2]
h = pre_52[k1, k2, k3, 3]
confidence = pre_52[k1, k2, k3, 4]
category = np.argmax(pre_52[k1, k2, k3, 5:])
x1 = center_x - w / 2
y1 = center_y - h / 2
x2 = center_x + w / 2
y2 = center_y + h / 2
category = int(category)
candidate_box.append([x1, y1, x2, y2, confidence, category])
print('Grid 52 * 52 :', x1, y1, x2, y2, confidence, category)
candidate_box = np.array(candidate_box)
for num in range(len(candidate_box)):
a1 = int(candidate_box[num, 0])
b1 = int(candidate_box[num, 1])
a2 = int(candidate_box[num, 2])
b2 = int(candidate_box[num, 3])
confidence = str(candidate_box[num, 4])
index = int(candidate_box[num, 5])
pre_class = class_list[index]
cv2.rectangle(img1, (a1, b1), (a2, b2), (0, 0, 255), 2)
cv2.putText(img1, pre_class, (a1, int((b1+b2)/2)), 1, 1, (0, 0, 255))
cv2.putText(img1, confidence, (a2, int((b1+b2)/2)), 1, 1, (0, 0, 255))
cv2.namedWindow("Final_Image")
cv2.imshow("Final_Image", img1)
cv2.waitKey(0)
cv2.imwrite("/home/archer/CODE/YOLOv3/demo/" + str(i) + '.jpg', img1)
十一、项目链接
如果代码跑不通,或者想直接使用训练好的模型,可以去下载项目链接:
https://blog.csdn.net/Twilight737