【机器学习线性代数】02 初识矩阵:让向量动起来
1.矩阵?一排向量,一堆数
介绍完了向量,这一节我们开始介绍矩阵。对于矩阵而言,最直观的描述就是一个 m × n m\times n m×n大小的数字方阵,他可以看作是 n n n个 m m m维列向量从左到右并排摆放,也可以看成是 m m m个 n n n维行向量从上到下进行叠放。
我们举一个实际的例子:一个 2 × 3 2\times 3 2×3的矩阵 A = [ 1 2 3 0.4 − 4 2 ] A=\begin{bmatrix} 1 & 2 & 3 \\ 0.4 & -4 & 2 \end{bmatrix} A=[10.42−432]:
显而易见,他有 2 2 2行 3 3 3列,一共 6 6 6个元素,每一个元素都对应矩阵中的一个数据项,例如第一行第二列的项是 2 2 2,我们也可以表示为 A 12 = 2 A_{12} = 2 A12=2。
那如果我们想使用Python语言来表示上面这个矩阵,也是非常简单的。可以使用 N u m P y NumPy NumPy中的嵌套数组来完成,这个矩阵本质上被表示成了一个二维数组:
代码片段:
import numpy as np
A = np.array([[1, 2, 3],
[0.4, -4, 2]])
print(A)
print(A.shape)
运行结果:
[[ 1. 2. 3. ]
[ 0.4 -4. 2. ]]
(2, 3)
我们着重强调一下,在形容矩阵规模的时候,一般采用其行数和列数来进行描述,对应到代码中,我们通过矩阵 A A A的 s h a p e shape shape属性,就获取了一个表示规模的元组: 2 2 2行 3 3 3列。
2.一些重要的特殊矩阵
初步接触了上一小节里那个普普通通的 2 × 3 2\times 3 2×3矩阵后,这里我们再补充一些特殊形态的矩阵,这些矩阵的特殊性不光体现在外观形状上,更在后续的矩阵实际应用中发挥着重要的作用。
2.1.方阵:行数等于列数
行数和列数相等的这类矩阵,我们称之为方阵,其行数或列数称之为他的阶数,这里我们看到的就是一个 3 3 3阶方阵 [ 1 2 3 4 5 6 7 8 9 ] \begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \\ 7 & 8 & 9\end{bmatrix} ⎣⎡147258369⎦⎤,我们代码表示一下:
代码片段:
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6],
[7, 8, 9]])
print(A)
print(A.shape)
运行结果:
[[1 2 3]
[4 5 6]
[7 8 9]]
(3, 3)
2.2.矩阵转置与对称矩阵
在说到对称矩阵之前,我们先得说一下矩阵的转置。对于矩阵 A = [ 1 2 3 4 5 6 ] A=\begin{bmatrix} 1 & 2 & 3 \\ 4 & 5 & 6 \end{bmatrix} A=[142536],如果将其行列互换得到一个新矩阵 [ 1 4 2 5 3 6 ] \begin{bmatrix} 1 & 4 \\ 2 & 5 \\ 3 &6\end{bmatrix} ⎣⎡123456⎦⎤,我们将其称之为转置矩阵 A T A^{T} AT ,行列互换的矩阵操作我们称之为矩阵的转置。
代码片段:
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6]])
print(A)
print(A.T)
运行结果:
[[1 2 3]
[4 5 6]]
[[1 4]
[2 5]
[3 6]]
那么,如果原矩阵和转置后新得到的矩阵相等,那么这个矩阵我们就称其为对称矩阵。显然,矩阵对称的前提必须得是一个方阵,其次在方阵 S S S中的每一项元素,都必须满足 S i j = S j i S_{ij}=S_{ji} Sij=Sji。我们举一个实际例子看看。
代码片段:
import numpy as np
S = np.array([[1, 2, 3],
[2, 5, 6],
[3, 6, 9]])
print(S)
print(S.T)
运行结果:
[[1 2 3]
[2 5 6]
[3 6 9]]
[[1 2 3]
[2 5 6]
[3 6 9]]
在对阵矩阵中我们发现,沿着从左上到右下的对角线相互对称的元素都是彼此相等的。在后面的内容中你会不断发现:将对称矩阵称之为最重要的矩阵之一,丝毫不为过。他在矩阵的相关分析中会扮演极其重要的角色。
2.3.向量:特殊的一维矩阵
前面在介绍向量的时候,我们提到过这个概念。现在介绍了矩阵之后,我们再着重回顾一下: n n n维的行向量可以看做是 1 × n 1\times n 1×n的矩阵,同理, n n n维的列向量也同样可以看做是 n × 1 n\times 1 n×1的特殊矩阵。
那么这样做的目的是什么呢?一方面可以将矩阵和向量的 p y t h o n python python表示方法统一起来,另一方面,在马上要介绍的矩阵与向量的乘法运算中,也可以将其看作是矩阵与矩阵乘法的一种特殊形式,将计算方式统一起来。我们再次用这个视角重新生成一个新的行向量和列向量。
代码片段:
import numpy as np
p = np.array([[1, 2, 3]])
print(p)
print(p.T)
运行结果:
[[1 2 3]]
[[1]
[2]
[3]]
我们用生成矩阵的方法生成了一个 1 × 3 1\times 3 1×3的矩阵,用他来表示一个 3 3 3维的行向量。随后将其转置(因为是矩阵形式,所以可以运用转置方法),就得到了 3 3 3维的列向量。
2.4.零矩阵:元素全 0 0 0
顾名思义,所有元素都是 0 0 0的矩阵称之为零矩阵,记作 O O O,像下面这个 3 × 5 3\times 5 3×5的零矩阵 [ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 ] \begin{bmatrix} 0 & 0 & 0 &0&0 \\ 0 & 0 & 0 &0&0 \\ 0 & 0 & 0 &0&0\end{bmatrix} ⎣⎡000000000000000⎦⎤,他可以记作是 O 3 , 5 O_{3,5} O3,5。
代码片段:
import numpy as np
A = np.zeros([3, 5])
print(A)
运行结果:
[[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]
[ 0. 0. 0. 0. 0.]]
2.5.对角矩阵
非对角元素位置上全部为 0 0 0的方阵,我们称之为对角矩阵,例如: [ 1 0 0 0 2 0 0 0 3 ] \begin{bmatrix} 1 & 0 & 0 \\ 0 & 2 & 0 \\ 0 & 0 & 3 \end{bmatrix} ⎣⎡100020003⎦⎤ , p y t h o n python python生成的方法如下:
代码片段:
import numpy as np
A = np.diag([1, 2, 3])
print(A)
运行结果:
[[1 0 0]
[0 2 0]
[0 0 3]]
2.6.单位矩阵:对角线为 1 1 1
注意:单位矩阵并不是所有元素都为 1 1 1的矩阵,而是对角元素均为 1 1 1,其余元素均为 0 0 0的特殊对角矩阵。 n n n阶单位矩阵记作 I n I_{n} In,下面我们用 p y t h o n python python生成一个 4 4 4阶单位矩阵 I 4 I_{4} I4: [ 1 0 0 0 0 1 0 0 0 0 1 0 0 0 0 1 ] \begin{bmatrix} 1 & 0 & 0 &0 \\ 0 & 1 & 0 &0 \\ 0 & 0 & 1 &0 \\ 0 & 0 & 0 &1\end{bmatrix} ⎣⎢⎢⎡1000010000100001⎦⎥⎥⎤ 。
代码片段:
import numpy as np
I = np.eye(4)
print(I)
运行结果:
[[ 1. 0. 0. 0.]
[ 0. 1. 0. 0.]
[ 0. 0. 1. 0.]
[ 0. 0. 0. 1.]]
3.矩阵的基本运算
3.1.矩阵的加法
矩阵之间的加法必须运用到相等规模的两个矩阵之间,即:行数和列数相等的两个矩阵之间才能做加法运算。这个非常容易理解,将对应位置上的元素相加即可得到结果矩阵:
[ a 11 a 12 a 13 a 21 a 22 a 23 ] + [ b 11 b 12 b 13 b 21 b 22 b 23 ] \begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \end{bmatrix} + \begin{bmatrix} b_{11} & b_{12} & b_{13} \\ b_{21} & b_{22} & b_{23} \end{bmatrix} [a11a21a12a22a13a23]+[b11b21b12b22b13b23] = [ a 11 + b 11 a 12 + b 12 a 13 + b 13 a 21 + b 21 a 22 + b 22 a 23 + b 23 ] =\begin{bmatrix} a_{11}+b_{11} & a_{12}+b_{12} & a_{13}+b_{13} \\ a_{21}+b_{21} & a_{22} +b_{22}& a_{23} +b_{23} \end{bmatrix} =[a11+b11a21+b21a12+b12a22+b22a13+b13a23+b23]
我们还是看看实际的代码:
代码片段:
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6]])
B = np.array([[10, 20, 30],
[40, 50, 60]])
print(A+B)
代码片段:
[[11 22 33]
[44 55 66]]
3.2.矩阵的数量乘法
矩阵的数量乘法,描述起来也非常简单:
c [ a 11 a 12 a 13 a 21 a 22 a 23 ] = [ c a 11 c a 12 c a 13 c a 21 c a 22 c a 23 ] c\begin{bmatrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \end{bmatrix} =\begin{bmatrix} ca_{11} & ca_{12} & ca_{13} \\ ca_{21} & ca_{22} & ca_{23} \end{bmatrix} c[a11a21a12a22a13a23]=[ca11ca21ca12ca22ca13ca23]
同样,我们看一个代码的例子:
代码片段:
import numpy as np
A = np.array([[1, 2, 3],
[4, 5, 6]])
print(2*A)
运行结果:
[[ 2 4 6]
[ 8 10 12]]
4.矩阵与矩阵的乘法
矩阵与矩阵的相乘,过程要稍微复杂一点,因此我们拿出来单讲。例如下面举例的矩阵 A A A和矩阵 B B B的乘法运算,对两个矩阵的形态是有要求的。
[ a 11 a 12 a 21 a 22 a 31 a 32 ] × [ b 11 b 12 b 13 b 21 b 22 b 23 ] = [ a 11 b 11 + a 12 b 21 a 11 b 12 + a 12 b 22 a 11 b 13 + a 12 b 23 a 21 b 11 + a 22 b 21 a 21 b 12 + a 22 b 22 a 21 b 13 + a 22 b 23 a 31 b 11 + a 32 b 21 a 31 b 12 + a 32 b 22 a 31 b 13 + a 32 b 23 ] \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ a_{31} & a_{32} \end{bmatrix} ×\begin{bmatrix} b_{11}&b_{12}&b_{13} \\ b_{21} &b_{22}&b_{23} \end{bmatrix} =\begin{bmatrix} a_{11}b_{11} +a_{12}b_{21}&a_{11}b_{12} +a_{12}b_{22}&a_{11}b_{13} +a_{12}b_{23} \\ a_{21}b_{11} + a_{22} b_{21}& a_{21}b_{12} + a_{22} b_{22}& a_{21}b_{13} + a_{22} b_{23}\\ a_{31}b_{11} + a_{32} b_{21}&a_{31}b_{12} + a_{32} b_{22}&a_{31}b_{13} + a_{32} b_{23} \end{bmatrix} ⎣⎡a11a21a31a12a22a32⎦⎤×[b11b21b12b22b13b23]=⎣⎡a11b11+a12b21a21b11+a22b21a31b11+a32b21a11b12+a12b22a21b12+a22b22a31b12+a32b22a11b13+a12b23a21b13+a22b23a31b13+a32b23⎦⎤
仔细观察这个计算公式,我们总结出以下的一些要求和规律:
1 左边矩阵的列数要和右边矩阵的行数相等
2 左边矩阵的行数决定了结果矩阵的行数
3 右边矩阵的列数决定了结果矩阵的列数
同样,我们用 p y t h o n python python来演示下面这个例子:
[ 1 2 3 4 5 6 ] × [ 3 4 5 6 7 8 ] \begin{bmatrix} 1 & 2 \\ 3 &4 \\ 5& 6 \end{bmatrix} × \begin{bmatrix} 3&4&5 \\ 6 &7&8 \end{bmatrix} ⎣⎡135246⎦⎤×[364758]
代码片段:
import numpy as np
A = np.array([[1, 2],
[3, 4],
[5, 6]])
B = np.array([[3, 4, 5],
[6, 7, 8]])
print(np.dot(A, B))
运行结果:
[[15 18 21]
[33 40 47]
[51 62 73]]
5.改变空间位置:矩阵乘以向量的本质
矩阵与向量的乘法,一般而言写作矩阵 A A A在左,列向量 x x x在右的 A x Ax Ax 的形式。这种 A x Ax Ax的写法便于描述向量 x x x的位置在矩阵 A A A的作用下进行变换的过程(下面会详细介绍)。
矩阵与向量的乘法,其实可以看作是矩阵与矩阵乘法的一种特殊形式,只不过位于后面的矩阵列数为 1 1 1而已。
[ a 11 a 12 a 21 a 22 a 31 a 32 ] [ x 11 x 21 ] = [ a 11 x 11 + a 12 x 21 a 21 x 11 + a 22 x 21 a 31 x 11 + a 32 x 21 ] \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \\ a_{31} & a_{32} \end{bmatrix} \begin{bmatrix} x_{11} \\ x_{21} \end{bmatrix} =\begin{bmatrix} a_{11}x_{11} +a_{12}x_{21} \\ a_{21}x_{11} + a_{22} x_{21}\\ a_{31}x_{11} + a_{32} x_{21} \end{bmatrix} ⎣⎡a11a21a31a12a22a32⎦⎤[x11x21]=⎣⎡a11x11+a12x21a21x11+a22x21a31x11+a32x21⎦⎤
我们对照前面讲过的矩阵与矩阵的乘法,来对比一下矩阵与向量的乘法规则,我们把列向量看作是列数为 1 1 1的特殊矩阵,那么就会非常明确:
1、矩阵在左,列向量在右,矩阵的列数和列向量的维数必须相等
2、矩阵和向量相乘的结果也是一个向量
3、矩阵的行数就是最终结果输出的列向量的维数
4、乘法的规则如上所示,就是矩阵的每行和列向量进行对应元素分别相乘后相加
我们来看一个矩阵与列向量相乘的例子:
[ 1 2 3 4 5 6 ] [ 4 5 ] = [ 1 × 4 + 2 × 5 3 × 4 + 4 × 5 5 × 4 + 6 × 5 ] = [ 14 32 50 ] \begin{bmatrix} 1 & 2 \\ 3 &4 \\ 5 &6 \end{bmatrix} \begin{bmatrix} 4 \\ 5 \end{bmatrix} =\begin{bmatrix} 1×4 +2×5 \\ 3×4 + 4× 5\\ 5×4 +6×5 \end{bmatrix} = \begin{bmatrix} 14 \\ 32\\50 \end{bmatrix} ⎣⎡135246⎦⎤[45]=⎣⎡1×4+2×53×4+4×55×4+6×5⎦⎤=⎣⎡143250⎦⎤
代码片段:
import numpy as np
A = np.array([[1, 2],
[3, 4],
[5, 6]])
x = np.array([[4, 5]]).T
print(np.dot(A, x))
运行结果:
[[14]
[32]
[50]]
从结果看,原始向量表示二维空间中的一个点,坐标为 ( 4 , 5 ) (4,5) (4,5),经过矩阵 [ 1 2 3 4 5 6 ] \begin{bmatrix} 1 & 2 \\ 3 &4 \\ 5 &6 \end{bmatrix} ⎣⎡135246⎦⎤乘法的作用,转化为三维空间中坐标为 ( 14 , 32 , 50 ) (14,32,50) (14,32,50)的点。
因此从这个例子中我们可以总结一下矩阵的作用:在特定矩阵的乘法作用下,原空间中的向量坐标,被映射到了目标空间中的新坐标,向量的空间位置(甚至是所在空间维数)由此发生了转化。
6.从行的角度思考
学习了矩阵、向量的表示方法以及运算规则之后,我们回过头来静静的思考一个问题:矩阵 A A A和列向量 x x x的乘法 A x Ax Ax到底意味着什么?下面,我们就来挖掘一下这里面的内涵。
在二阶方阵 A A A与二维列向量 x x x相乘的例子中, A x = [ a b c d ] [ x 1 x 2 ] Ax=\begin{bmatrix} a & b \\ c &d \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} Ax=[acbd][x1x2] = [ a x 1 + b x 2 c x 1 + d x 2 ] =\begin{bmatrix} ax_1 +bx_2 \\ cx_1+dx_2 \end{bmatrix} =[ax1+bx2cx1+dx2] 。
刚才说了,位于矩阵 A A A第 i i i行的行向量的各成分和列向量 x x x各成分分别相乘后相加,得到的就是结果向量的第 i i i个成分。这个计算方法有没有感觉很熟悉?没错,这不就是向量点乘的定义式么?
即: A x = [ r o w 1 r o w 2 ] x = [ r o w 1 ⋅ x r o w 2 ⋅ x ] Ax=\begin{bmatrix} row_1 \\ row_2 \end{bmatrix} x=\begin{bmatrix} row_1 \cdot x\\ row_2 \cdot x\end{bmatrix} Ax=[row1row2]x=[row1⋅xrow2⋅x]。
矩阵与向量的乘法如果从行的角度来看,就是如此。常规的计算操作就是这么执行的,但是似乎也没有更多可以挖掘的,那我们试试继续从列的角度再来看看。
7.列的角度:重新组合矩阵的列向量
如果从列的角度来计算矩阵与向量的乘积,会有另一套计算的方法,可能大家对这种方法要相对陌生一些。但是实质上,这种方法从线性代数的角度来看,还要更为重要一些,我们还是用二阶方阵进行举例。
A x = [ a b c d ] [ x 1 x 2 ] Ax=\begin{bmatrix} a & b \\ c &d \end{bmatrix} \begin{bmatrix} x_1 \\ x_2 \end{bmatrix} Ax=[acbd][x1x2] = x 1 [ a c ] + x 2 [ b d ] =x_1\begin{bmatrix} a\\ c\end{bmatrix} +x_2\begin{bmatrix} b\\ d\end{bmatrix} =x1[ac]+x2[bd] = [ a x 1 + b x 2 c x 1 + d x 2 ] =\begin{bmatrix} ax_1 +bx_2 \\ cx_1+dx_2 \end{bmatrix} =[ax1+bx2cx1+dx2]
发现了规律没有?我们通过这种形式的拆解,也能得到最终的正确结果,这就是从列的角度进行的分析。从前面的知识我们可以这样描述:从列的角度来看,矩阵 A A A与向量 x x x的乘法是对矩阵 A A A的各列向量进行线性组合的过程,每个列向量的组合系数就是向量 x x x的各对应成分。
这么理解似乎有点新意,我们按照列的思想重新把矩阵 A A A写成一组列向量的形式:
A x = [ c o l 1 c o l 2 . . . c o l n ] [ x 1 x 2 . . . x n ] Ax=\begin{bmatrix}col_1 & col_2 &...&col_n\end{bmatrix} \begin{bmatrix}x_1\\x_2\\...\\x_n\end{bmatrix} Ax=[col1col2...coln]⎣⎢⎢⎡x1x2...xn⎦⎥⎥⎤ = x 1 c o l 1 + x 2 c o l 2 + . . . + x n c o l n =x_1col_1+x_2col_2+...+x_ncol_n =x1col1+x2col2+...+xncoln
依照上述公式,我们举一个实际的例子,就更清楚了。
A x = [ 1 2 3 4 ] [ 3 5 ] Ax=\begin{bmatrix} 1 & 2 \\ 3 &4 \end{bmatrix} \begin{bmatrix} 3 \\ 5 \end{bmatrix} Ax=[1324][35] = 3 [ 1 3 ] + 5 [ 2 4 ] =3\begin{bmatrix} 1\\ 3\end{bmatrix} +5\begin{bmatrix} 2\\ 4\end{bmatrix} =3[13]+5[24]
所得到的结果就是矩阵第一列的列向量 [ 1 3 ] \begin{bmatrix} 1\\ 3\end{bmatrix} [13]的 3 3 3倍加上第二列列向量 [ 2 4 ] \begin{bmatrix} 2\\ 4\end{bmatrix} [24]的 5 5 5倍。
因此,一个矩阵和一个向量相乘的过程,就是对位于原矩阵各列的列向量重新进行线性组合的过程,而线性组合的各系数就是向量的对应各成分。
8.进一步引申:变换向量的基底
8.1.二阶方阵与二维列向量乘法举例
为了方便说明原理,我们依旧用二阶方阵 [ a b c d ] \begin{bmatrix} a & b \\ c &d \end{bmatrix} [acbd]与二维列向量 [ x y ] \begin{bmatrix} x \\ y \end{bmatrix} [xy]的乘法进行举例:
二维列向量 [ x y ] \begin{bmatrix} x \\ y \end{bmatrix} [xy]的坐标是 x x x和 y y y,还记得之前我们介绍过的向量坐标的概念么?向量的坐标依托于基底的选取,向量坐标在基底明确的前提下才有实际意义,而这个二维列向量,我们说他的坐标是 x x x和 y y y,基于的就是默认基底: ( [ 1 0 ] (\begin{bmatrix} 1 \\0 \end{bmatrix} ([10]和 [ 0 1 ] ) \begin{bmatrix} 0 \\1 \end{bmatrix}) [01])。那么二维列向量的完整表达式就是:
[ x y ] = x [ 1 0 ] + y [ 0 1 ] \begin{bmatrix} x \\y\end{bmatrix}=x\begin{bmatrix} 1 \\0 \end{bmatrix} +y\begin{bmatrix} 0 \\1 \end{bmatrix} [xy]=x[10]+y[01]。
好,回顾了这些基础,我们就利用他将矩阵与向量的乘法表达式做进一步的展开:
[ a b c d ] [ x y ] \begin{bmatrix} a & b \\ c &d \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} [acbd][xy] = [ a b c d ] ( x [ 1 0 ] + y [ 0 1 ] ) =\begin{bmatrix} a & b \\ c &d \end{bmatrix} (x\begin{bmatrix} 1 \\ 0 \end{bmatrix} +y\begin{bmatrix} 0 \\ 1 \end{bmatrix}) =[acbd](x[10]+y[01]) = x [ a b c d ] [ 1 0 ] + y [ a b c d ] [ 0 1 ] =x\begin{bmatrix} a & b \\ c &d \end{bmatrix} \begin{bmatrix} 1 \\ 0 \end{bmatrix} +y\begin{bmatrix} a & b \\ c &d \end{bmatrix} \begin{bmatrix} 0 \\ 1 \end{bmatrix} =x[acbd][10]+y[acbd][01] = x [ a c ] + y [ b d ] =x\begin{bmatrix} a \\ c \end{bmatrix} +y\begin{bmatrix} b \\ d \end{bmatrix} =x[ac]+y[bd]
是不是已经初见端倪了?我们再直观的展示一下式子首尾的结果,在矩阵 [ a b c d ] \begin{bmatrix} a & b \\ c &d \end{bmatrix} [acbd]的乘法作用下,向量完成了下面的转换: x [ 1 0 ] + y [ 0 1 ] ⇒ x [ a c ] + y [ b d ] x\begin{bmatrix} 1 \\ 0 \end{bmatrix} +y\begin{bmatrix} 0 \\ 1 \end{bmatrix}\Rightarrow x\begin{bmatrix} a \\ c \end{bmatrix} +y\begin{bmatrix} b \\ d \end{bmatrix} x[10]+y[01]⇒x[ac]+y[bd]
挑明了说,就是矩阵把向量的基底进行了变换,把旧的基底 ( [ 1 0 ] , [ 0 1 ] ) (\begin{bmatrix} 1 \\ 0 \end{bmatrix} ,\begin{bmatrix} 0 \\ 1 \end{bmatrix}) ([10],[01])变换成了新的基底 ( [ a c ] , [ b d ] ) (\begin{bmatrix} a \\ c \end{bmatrix} ,\begin{bmatrix} b \\ d \end{bmatrix}) ([ac],[bd])。
映射前由旧的基底分别乘以对应的坐标 ( x , y ) (x,y) (x,y)来表示其位置,而映射后,由于旧的基底映射到新的基底,那向量自然而然应该用新的基底来分别乘以对应坐标 ( x , y ) (x,y) (x,y)来描述改变后的空间位置, x [ 1 0 ] + y [ 0 1 ] ⇒ x [ a c ] + y [ b d ] x\begin{bmatrix} 1 \\ 0 \end{bmatrix} +y\begin{bmatrix} 0 \\ 1 \end{bmatrix}\Rightarrow x\begin{bmatrix} a \\ c \end{bmatrix} +y\begin{bmatrix} b \\ d \end{bmatrix} x[10]+y[01]⇒x[ac]+y[bd] = [ a x + b y c x + d y ] =\begin{bmatrix} ax +by \\ cx+dy \end{bmatrix} =[ax+bycx+dy] ,如图1所示。
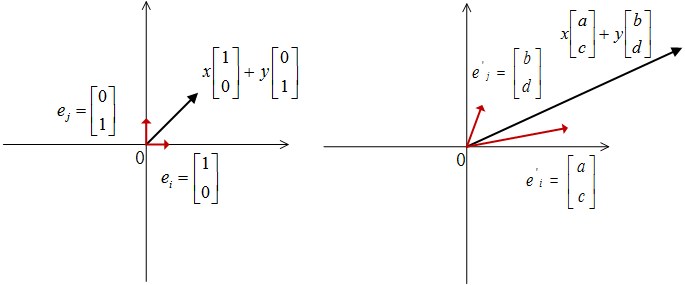
8.2.矩阵的各列就是映射后的新基底
结合矩阵的式子我们不难发现:矩阵 A A A的第一列 [ a c ] \begin{bmatrix}a \\ c \end{bmatrix} [ac]就是原始的默认基向量 [ 1 0 ] \begin{bmatrix} 1 \\ 0 \end{bmatrix} [10]变换后的目标位置(新的基向量),而第二列 [ b d ] \begin{bmatrix} b \\ d \end{bmatrix} [bd]就是另一个基向量 [ 0 1 ] \begin{bmatrix} 0 \\ 1 \end{bmatrix} [01]映射后的目标位置(新的基向量)。
基底的变换明确了,那向量的坐标呢?映射后得到的新向量,如果以 ( [ a c ] , [ b d ] ) (\begin{bmatrix} a \\ c \end{bmatrix} ,\begin{bmatrix} b \\ d \end{bmatrix}) ([ac],[bd])为基底,他的坐标仍是 ( x , y ) (x,y) (x,y),如果以默认的 ( [ 1 0 ] , [ 0 1 ] ) (\begin{bmatrix} 1 \\ 0 \end{bmatrix} ,\begin{bmatrix} 0 \\ 1 \end{bmatrix}) ([10],[01])为基底,那么其坐标就是 ( a x + b y , c x + d y ) (ax +by,cx+dy) (ax+by,cx+dy) 。
8.3.扩展到三阶方阵
为了让结果更让人信服,我们再看看三阶方阵和三维列向量相乘的例子,同理也满足这个过程:
[ a b c d e f g h i ] [ x y z ] \begin{bmatrix} a & b& c\\ d & e& f\\ g & h&i \end{bmatrix} \begin{bmatrix} x \\ y\\ z \end{bmatrix} ⎣⎡adgbehcfi⎦⎤⎣⎡xyz⎦⎤ = [ a b c d e f g h i ] ( x [ 1 0 0 ] + y [ 0 1 0 ] + z [ 0 0 1 ] ) =\begin{bmatrix} a & b& c\\ d & e& f\\ g & h&i \end{bmatrix} (x\begin{bmatrix} 1 \\ 0\\ 0 \end{bmatrix} +y\begin{bmatrix} 0 \\ 1\\ 0 \end{bmatrix}+z\begin{bmatrix} 0 \\ 0\\ 1 \end{bmatrix}) =⎣⎡adgbehcfi⎦⎤(x⎣⎡100⎦⎤+y⎣⎡010⎦⎤+z⎣⎡001⎦⎤) = x [ a d g ] + y [ b e h ] + z [ c f c ] = x\begin{bmatrix} a \\ d\\ g \end{bmatrix} +y\begin{bmatrix} b \\ e\\ h \end{bmatrix}+z\begin{bmatrix} c \\ f\\ c \end{bmatrix} =x⎣⎡adg⎦⎤+y⎣⎡beh⎦⎤+z⎣⎡cfc⎦⎤
是不是和二阶矩阵的情况是一模一样呢?三阶方阵将三维列向量的基底做了映射转换,方阵的第一列 [ a d g ] \begin{bmatrix} a \\ d\\ g \end{bmatrix} ⎣⎡adg⎦⎤是原始基向量 [ 1 0 0 ] \begin{bmatrix} 1 \\ 0\\ 0 \end{bmatrix} ⎣⎡100⎦⎤映射后的目标位置(新的基向量),方阵的第二列 [ b e h ] \begin{bmatrix} b \\ e\\ h \end{bmatrix} ⎣⎡beh⎦⎤是原始基向量 [ 0 1 0 ] \begin{bmatrix} 0 \\ 1\\ 0 \end{bmatrix} ⎣⎡010⎦⎤映射后的目标位置(新的基向量),方阵的第三列 [ c f i ] \begin{bmatrix} c \\ f\\ i \end{bmatrix} ⎣⎡cfi⎦⎤是原始基向量 [ 0 0 1 ] \begin{bmatrix} 0\\ 0\\ 1 \end{bmatrix} ⎣⎡001⎦⎤映射后的目标位置(新的基向量)。
因此同样的,映射后的目标向量如果在新的基底 ( [ a d g ] , [ b e h ] , [ c f c ] ) (\begin{bmatrix} a \\ d\\ g \end{bmatrix} ,\begin{bmatrix} b \\ e\\ h \end{bmatrix},\begin{bmatrix} c \\ f\\ c \end{bmatrix}) (⎣⎡adg⎦⎤,⎣⎡beh⎦⎤,⎣⎡cfc⎦⎤)下看,其坐标仍然是 ( x , y , z ) (x,y,z) (x,y,z)。如果放回到原始基底 ( [ 1 0 0 ] , [ 0 1 0 ] , [ 0 0 1 ] ) (\begin{bmatrix} 1 \\ 0\\ 0 \end{bmatrix} ,\begin{bmatrix} 0 \\ 1\\ 0 \end{bmatrix},\begin{bmatrix} 0 \\ 0\\ 1 \end{bmatrix}) (⎣⎡100⎦⎤,⎣⎡010⎦⎤,⎣⎡001⎦⎤)下看,将新的基底 ( [ a d g ] , [ b e h ] , [ c f c ] ) (\begin{bmatrix} a \\ d\\ g \end{bmatrix} ,\begin{bmatrix} b \\ e\\ h \end{bmatrix},\begin{bmatrix} c \\ f\\ c \end{bmatrix}) (⎣⎡adg⎦⎤,⎣⎡beh⎦⎤,⎣⎡cfc⎦⎤)和他对应的坐标 ( x , y , z ) (x,y,z) (x,y,z)相结合,就能得到默认原始基底下的坐标: [ a x + b y + c z d x + e y + f z g x + h y + i z ] \begin{bmatrix} ax+by+cz \\ dx+ey+fz\\ gx+hy+iz \end{bmatrix} ⎣⎡ax+by+czdx+ey+fzgx+hy+iz⎦⎤ 。
8.4.一般化的: m × n m×n m×n矩阵乘以 n n n维列向量
此处,我们看到的就是最一般的情况了,矩阵 A = [ a 11 a 12 . . . a 1 n a 21 a 22 . . . a 2 n . . . . . . a m 1 a m 2 . . . a m n ] A=\begin{bmatrix} a_{11}&a_{12}&...&a_{1n} \\ a_{21}&a_{22}&...&a_{2n}\\ ...&&...\\ a_{m1}&a_{m2}&...&a_{mn} \end{bmatrix} A=⎣⎢⎢⎡a11a21...am1a12a22am2............a1na2namn⎦⎥⎥⎤和向量 x = [ x 1 x 2 . . . x n ] x= \begin{bmatrix} x_1 \\ x_2\\ ...\\ x_n \end{bmatrix} x=⎣⎢⎢⎡x1x2...xn⎦⎥⎥⎤进行相乘。
A x = [ a 11 a 12 . . . a 1 n a 21 a 22 . . . a 2 n . . . . . . a m 1 a m 2 . . . a m n ] [ x 1 x 2 . . . x n ] Ax = \begin{bmatrix} a_{11}&a_{12}&...&a_{1n} \\ a_{21}&a_{22}&...&a_{2n}\\ ...&&...\\ a_{m1}&a_{m2}&...&a_{mn} \end{bmatrix}\begin{bmatrix} x_1 \\ x_2\\ ...\\ x_n \end{bmatrix} Ax=⎣⎢⎢⎡a11a21...am1a12a22am2............a1na2namn⎦⎥⎥⎤⎣⎢⎢⎡x1x2...xn⎦⎥⎥⎤ = x 1 [ a 11 a 21 . . . a m 1 ] + x 2 [ a 12 a 22 . . . a m 2 ] + . . . + x n [ a 1 n a 2 n . . . a m n ] =x_1 \begin{bmatrix} a_{11} \\ a_{21}\\ ...\\ a_{m1} \end{bmatrix}+x_2 \begin{bmatrix} a_{12} \\ a_{22}\\ ...\\ a_{m2} \end{bmatrix}+...+x_n \begin{bmatrix} a_{1n} \\ a_{2n}\\ ...\\ a_{mn} \end{bmatrix} =x1⎣⎢⎢⎡a11a21...am1⎦⎥⎥⎤+x2⎣⎢⎢⎡a12a22...am2⎦⎥⎥⎤+...+xn⎣⎢⎢⎡a1na2n...amn⎦⎥⎥⎤
在 m × n m×n m×n矩阵 A A A的作用下,原始的 n n n维基向量 [ 1 0 . . . 0 ] \begin{bmatrix} 1 \\ 0\\ ...\\ 0 \end{bmatrix} ⎣⎢⎢⎡10...0⎦⎥⎥⎤映射成了新的基向量: [ a 11 a 21 . . . a m 1 ] \begin{bmatrix} a_{11} \\ a_{21}\\ ...\\ a_{m1} \end{bmatrix} ⎣⎢⎢⎡a11a21...am1⎦⎥⎥⎤ , n n n维基向量 [ 0 0 . . . 1 ] \begin{bmatrix} 0 \\ 0\\ ...\\ 1 \end{bmatrix} ⎣⎢⎢⎡00...1⎦⎥⎥⎤映射成了 [ a 1 n a 2 n . . . a m n ] \begin{bmatrix} a_{1n} \\ a_{2n}\\ ...\\ a_{mn} \end{bmatrix} ⎣⎢⎢⎡a1na2n...amn⎦⎥⎥⎤ ,我们发现,在这种一般性的情况下,如果 m ≠ n m \neq n m=n,那么映射前后,基向量的维数甚至都可能发生变化, n n n维列向量 x x x变换成了 n n n个 m m m维列向量线性组合的形式,其最终结果是一个 m m m 维的列向量。
由此看出,映射后的向量维数和原始向量维数的关系取决于 m m m和 n n n的关系,如果 m > n m>n m>n,那么目标向量的维数就大于原始向量的维数,如果 m < n m
9.基变换的意外情况
实质上,如果仅仅停留在上面的讨论结果,那可能会显示出我们思考问题不够全面、准确。首先,“经过矩阵变换,会将原始的基底变换成为一组新的基底”这句话的表述就并不准确,之前这么说只是为了方便大家理解并建立概念。
为什么这么说呢?对于一个 m × n m×n m×n的矩阵 A A A和 n n n维列向量 x x x,经过 A x Ax Ax的乘法作用, x x x的 n n n个 n n n维默认基向量构成的基底被转换成了 n n n个 m m m维的目标向量。
当 n > m n>m n>m的时候,这 n n n个向量线性相关,因此不构成基底;
当 n < m n
当且仅当 n = m n=m n=m,且这 n n n个向量线性无关的时候,他们才能称之为一组新的基底。
不过即便有这些意外情况,我们这一讲里讨论的内容仍然具有重要意义,矩阵 A A A的各列向量是 x x x默认基底经过转换后的目标向量,正因为其在维度和线性相关性方面存在各种不同情况,因此这组目标向量的张成空间和原始向量所在的空间之间,就会存在多种不同的对应关系,这便是我们后续将要重点讨论的空间映射相关内容。