Neural Collaborative Filtering(推荐系统)(二)
Neural Collaborative Filtering(推荐系统)(二)
本篇博客主要梳理了NCF中的2.背景知识和3.1NCF框架以及3.2GMF思路。
2. PRELIMINARIES(预备知识)
2.1 从隐式数据中学习
Learning from Implicit Data
定义用户-物品交互矩阵Y ∈ RM×N

其中,1是观测到的交互数据,0是其他的数据。
学习下面这个函数
![]()
其中yui^预测了用户u和物品i之间的交互得分。
theta是模型参数
f是交互函数,在给定theta和u、i下计算交互得分。
为了估计参数theta,一般的机器学习范式是优化一个目标函数。最常用的两种目标函数:pointwise loss & pairwise loss
For pointwise loss:
使用优化yui^和yui之间的平方误差的回归框架。
为了解决负样本缺失,pointwise使用两种方法。
1)将所有未观测到的数据全部当作负样本。
2)从未观测到的数据中采样负样本。
For pairwise loss:
使用三元组的形式。
将观测到的数据排名高于未观测到的数据,最大化观测到的数据yui^ 和未观测到的数据yuj^之间的距离。
NCF中使用神经网络建立交互函数f估计出yui^,同时支持pointwise loss和pairwise loss。
2.2 矩阵分解
Matrix Factorization
矩阵分解(MF)将用户和用品分别用一个有真实值的向量表示出来,向量表示了用户或者用品的潜在特征。矩阵内积可以表示用户u与物品i之间的交互yui^。

潜在向量空间的各维度相互独立,且各维度权重相同,MF可以看作是一个对于潜在特征的线性模型。
内积函数限制了MF的表现力。
1) 物品或者用户之间的相似度可以用内积来表示,或者可以用两个潜在向量之间角度的cos值表示。
2) 使用Jaccard coefficient3作为MF需要覆盖的基本用户相似性。
Figure 1a,1b 展示了使用简单固定的内积算法在低维空间估算复杂的交互会出现问题。
解决这个问题的方法之一是使用大的矩阵维数K,但是这样可能会伤害模型的一般性(比如说过拟合),尤其是数据是sparse的。
文章解决这个问题的方法是,使用DNN从数据中学习交互函数。
3. 神经协同过滤
NEURAL COLLABORATIVE FILTERING
先提出了一般的框架(3.1 General Framework),说明了使用隐式数据的二进制属性概率模型来学习NCF。然后,展示了MF在NCF下的表达(3.2 GMF)。接着,使用MLP(多层感知机)去学习用户和项目之间的交互函数,探索DNN在协同过滤中的应用(3.3 MLP)。最后,提出了神经矩阵分解模型,该模型在NCF框架下集合了MF和MLP(3.4 NeuMF)。该模型统一了MF的线性功能和MLP的非线性功能,该模型用于建模用户-物品之间的潜在结构。
3.1 NCF一般框架(General framework)
框架如图所示:

Input Layer:包括两个特征向量vu和vi,分别描述了用户u和物品i。用二进制稀疏向量编码。通过使用这种内容特征来表示用户和项目来解决冷启动问题。
Embedding Layer:一个全连接层,将稀疏表示转化为密集矢量(dense vector)。
Neural collaborative filtering layers:将latent vector 映射到预测分数yui^。每一层的神经网络都可以视作去发现特定的用户-物品之间交互的结构。
minimize pointwise loss:yui^与yui之间的平方损失函数。其他损失函数也可以,但是损失函数不是我们要讨论的重点。所以,本文使用pointwise loss。
最后,NCF可以表示为如下预测模型:

或者,
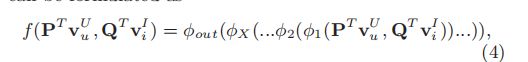
3.1.1 学习NCF
Learning NCF
损失函数定义为:
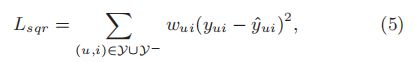
我们可以将yui视作一个标签,1代表 i 是和 u 相关的,0代表不相关。预测值yui^ 我们可以看作 i 和 u 的相关程度。为了给yui^ 一个概率解释,我们需要将yui^ 限制在 [ 0 , 1 ] 之间,这个可以通过概率函数很简单的实现。
损失函数变为了交叉熵损失:

这个就是NCF需要最小化的损失函数,可以使用随机梯度下降SGD实现最小化。负样本在每次迭代中从未观测到的数据中进行采样,并控制采样比例。
3.2 GMF
Generalized Matrix Factorization 一般矩阵分解
MF在推荐系统中很常用,如果NCF能实现MF则能实现一大部分的推荐模型。
在NCF中输入的是稀疏向量vu和vi通过embedding转化为了pu和qi,如下:
![]()
和
![]()
将第一层的神经协同过滤层定义为
pu和qi之间的运算符表示向量的内积,输出层表示为:
![]()
aout是输出层的激活函数,h是输出层的权重。如果将aout设置为恒等函数,将h设置为全为一的向量,那么NCF就可以实现MF了。
在NCF框架下,MF很容易被推广和扩展。h也是可以从数据中学习的,不同的权重可以使神经网络不同维度有不同的重要性。
GMF:
MF是线性函数。在文章中,在NCF框架下,使用sigmoid激活函数作为aout,使用log loss来从数据中学习h,将这种结构称为GMF(Generalized Matrix Factorization)。
总结
本篇文章将NCF这篇文章知识背景梳理了一下,整理了GMF。下篇文章要碰GMF的代码了。
恐惧。。。对代码总是心生恐惧。。。。
2021.03.31 补充
哈哈哈哈,原来代码如此简单
本来这个系列(三)想写我运行代码过程中遇到的问题,没想到啊,没想到,这个代码实在简单。算了,这个系列不记录运行代码的过程了,就只梳理论文思路好了。