densenet
DenseNet:比ResNet更优的CNN模型 - 知乎码字不易,欢迎给个赞! 欢迎交流与转载,文章会同步发布在公众号:机器学习算法全栈工程师(Jeemy110) 历史文章:小白将:你必须要知道CNN模型:ResNet前言在计算机视觉领域,卷积神经网络(CNN)已经成为最主流的… https://zhuanlan.zhihu.com/p/37189203Deep Networks with Stochastic Depth - 纯洁的小兄弟 - 博客园随机深度文章是发表于ECCV2016,这篇文章早于DenseNet.,DenseNet也是因为随机深度网络受到启发,才提出来。Deep Network with Stochastic depth,在训https://www.cnblogs.com/ziwh666/p/12482583.htmlDenseNet能不能像ResNet一样深? - 知乎DenseNet提出的出发点之一就是通过多尺度特征复用来降低参数量和复杂度的吧,直观上是需求每一层最高效的…https://www.zhihu.com/question/324527598/answer/684439450
https://zhuanlan.zhihu.com/p/37189203Deep Networks with Stochastic Depth - 纯洁的小兄弟 - 博客园随机深度文章是发表于ECCV2016,这篇文章早于DenseNet.,DenseNet也是因为随机深度网络受到启发,才提出来。Deep Network with Stochastic depth,在训https://www.cnblogs.com/ziwh666/p/12482583.htmlDenseNet能不能像ResNet一样深? - 知乎DenseNet提出的出发点之一就是通过多尺度特征复用来降低参数量和复杂度的吧,直观上是需求每一层最高效的…https://www.zhihu.com/question/324527598/answer/684439450
densenet是2017年的cvpr的best paper,文章质量相比resnet差点意思,resnet非常值得读,深度模型->BN解决梯度消失爆炸->退化->学习恒等映射或是残差->残差模型架构->缓解退化->恒等映射高响应->网络的灵活调控,resnet更本质像一个微分方程(残差函数),统一的模块构成差分块,通过调整步长来更好的拟合问题,使得映射空间的曲率更加平滑。densenet基本是模仿resnet,但是理论高度并没有那么高。实际工程中也不推荐用densenet,吃显存,效果也不是太多,加了浅层训练也不一定更好训了。
1.Abstract
Densenet的几个优点:they alleviate the vanishing-gradient problem, strengthen feature propagation, encourage feature reuse, and substantially reduce the number of parameters.(减轻了梯度消失,加强特征传播,鼓励特征复用,并大大减轻参数量)
2.Introduction
抛出了随着网络变深,会面临梯度消失问题,认为类似残差等跨层连接的方式有助于缓解梯度消失。
densenet提议了一种方式,to ensure maximum information flow between layers in the network, we connect all layers (with matching feature-map sizes) directly with each other. To preserve the feed-forward nature, each layer obtains additional inputs from all preceding layers and passes on its own feature-maps to all subsequent layers.Crucially,in contrast to ResNets, we never combine features through summation before they are passed into a layer; instead, we combine features by concatenating them. 为了确保网络中各层之间的信息流最大化,我们将所有层(具有匹配的特征图大小)直接相互连接。 为了保持前馈性质,每一层从所有前面的层获得额外的输入,并将它自己的特征图传递给所有后续层。不在通过add的方式来加和特征,而是将特征进行concat。
这种密集连接模式的一个可能违反直觉的影响是它需要比传统卷积网络更少的参数,因为不需要重新学习冗余特征图。 传统的前馈架构可以被视为具有状态的算法,该状态在层与层之间传递。 每一层从其前一层读取状态并将其写入后续层。它会改变状态,但也会传递需要保留的信息。resnet通过额外的identity transformation来确保这种信息保存,Deep networks with stochastic depth表明resnet中的一些层贡献很小,实际上可以在训练期间随机丢弃,这使得 ResNets 的状态类似于(展开的)循环神经网络 [21],但 ResNets 的参数数量要大得多,因为每一层都有自己的权重。
这里解释一下Deep networks with stochastic depth这篇文章的实验,也是densenet作者的文章,上面的材料也有,在训练resnet的过程中,随机去掉了很多层,在训练中,如果一个特定的残差块被启用了,那么它的输入就会同时流经恒等表换shortcut(identity shortcut)和权重层;否则输入就只会流经恒等变换shortcut。在训练的过程中,每一个层都有一个“生存概率”,并且都会被任意丢弃。在测试过程中,所有的block都将保持被激活状态,而且block都将根据其在训练中的生存概率进行调整,resnet自己对数据是有调整能力,这里相当于认为的引入了一个随机dropout,其结果是最终提升了模型的泛化能力。这种引入随机变量的设计有效的克服了过拟合使模型有了更好的泛化能力。作者的解释是,不激活一部分block事实上实现了一种隐性的模型融合(Implicit model ensemble),由于训练时模型的深度随机,预测时模型的深度确定,事实上是在测试时把不同深度的模型融合了起来。在深度确定时,信息随着网络一层层被提取被过滤,当信息到达网络的高层时已经不是非常informative了,高层网络面对这样的信息难以得到有效的训练。不激活一部分block,使得高层的block能接收到更多来自底层的信息,能得到更加充分的训练,因而模型有了更好的表达能力。在预测时,深度确定并且给各个block加权,也事实上是一种模型融合。
densenet的提出基于上面的实验,部分残差块其实本身并没有信息流经过,因此网络虽然很少,但并不是所有的都是深度信息起了作用,有些是浅层的信息,有些是深层的信息,于是为何不把浅层信息保存下来直接传下去呢? Our proposed DenseNet architecture explicitly differentiates between information that is added to the network and information that is preserved.densenet把要保存的信息并没有简单add,而是都concat起来,一部分是浅层的信息,一部分是经过了特征映射的信息。这样改善了整个网络的信息流和梯度,易于训练,Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision [20]. This helps training of deeper network architectures. Further, we also observe that dense connections have a regularizing effect, which reduces overfitting on tasks with smaller training set sizes.每一层都可以接触到来自损失函数和输入信息的梯度,从而导致了隐式的深度监督,这有助于训练更深的网络,并且有正则化的效果,减少对较少数据集的过拟合。一般浅层特征更倾向于边缘,纹理等梯度大的信息,越深的特征提取越抽象,和loss关联,越和数据集像契合,因此浅层和深层相结合确实有助于减少过拟合现象,提高泛化能力。
2.Densenet
densenet的结构设计上面的材料介绍的很清楚。
 3.discussion
3.discussion
model compactness.
 相同测试误差下,参数更少,0.8m的densenet-bc-100要比10.2m的resnet-1001的测试误差更小,不过有个问题,densenet明显在训练的前150,误差震动的幅度要高很多,之前我在学校用3D-densenet训练高光谱分类模型时,也有这个趋势,看来loss想要同时监督高层特征和浅层特征的梯度还是很有难度的,不好训的。
相同测试误差下,参数更少,0.8m的densenet-bc-100要比10.2m的resnet-1001的测试误差更小,不过有个问题,densenet明显在训练的前150,误差震动的幅度要高很多,之前我在学校用3D-densenet训练高光谱分类模型时,也有这个趋势,看来loss想要同时监督高层特征和浅层特征的梯度还是很有难度的,不好训的。
Implicit deep supervision.
One explanation for the improved accuracy of dense convolutional networks may be that individual layers receive additional supervision from the loss function through the shorter connections. One can interpret DenseNets to perform a kind of “deep supervision”.密集卷积网络精度提高的一种解释可能是单个层通过较短的连接从损失函数接收额外的监督.可以将 DenseNets 解释为执行一种“深度监督”。DenseNets 以隐式方式执行类似的深度监督:网络顶部的单个分类器通过最多两个或三个转换层为所有层提供直接监督。 然而,DenseNets 的损失函数和梯度要简单得多,因为所有层共享相同的损失函数。这个观点目前也可以在很多结构上看到,比如yolov3的输出,其实是一种多尺度信息的融合。
feature reuse
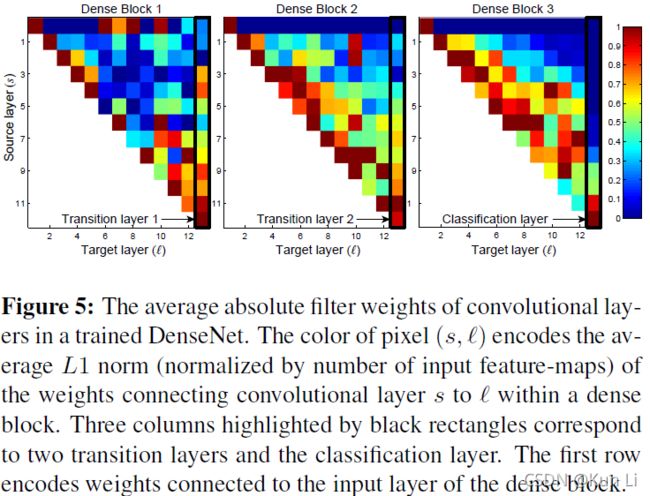
作者在CARFA10数据集上饰演了L=40,k=12,每个block12个conv,L=10,有3个dense block,(densenet的conv比resenet多很多的,主要还是因为通道数少,每个block的最后concat一下,通道维数就上来了,所以densenet121的参数量都比resnet50要小)用average weight做了下实验。纵坐标表示每一层的前一层,横坐标表示每一层,最后一列表示transition层。
1.所有层的权重确实在block中都得到了传播和使用。
2.transotion layer的特征也是有浅有深的....
后面这几条我觉得也看不出来
整体来说,densenet其实算是提高了一个dense block中conv的多尺度信息,不能简单说densenet更好,二者比较,ResNet是更一般的模型,DenseNet是更特化的模型。DenseNet用于图像处理可能比ResNet表现更好,本质是DenseNet更能和图像的信息分布特点匹配,是使用了多尺度的Kernel。densenet也有自己很大问题,在同一个dense block中的feature map要一致保存,会占用很大的现存。最直接的计算就是一次推断中所产生的所有feature map数目。有些框架会有优化,自动把比较靠前的层的feature map释放掉,所以显存就会减少,或者inplace操作通过重新计算的方法减少一部分显存,但是densenet因为需要重复利用比较靠前的feature map,所以无法释放,导致显存占用过大。
在基础架构上使用shortcut去调节网络的差分,这里面Deep networks with stochastic depth揭示了其实resnet后面很多的都趋向于恒等映射了,resnet论文里也写了,resnet网络越深,其实恒等映射的激活是越高的,conv那边线几乎是没有什么信息损失和回流梯度的,因此densenet认为浅层的特征也很重要,既然深层是恒等映射多一点,那我就不一个个模块的做映射了,直接把浅层的特征给传下来了,论文其实也不是很出彩吧,对resnet的网络模仿很高,也吃现存,实际工程中,我尝试过的项目最终densenet的效果都不算太好,直接还改过east的backbone,用densenet,希望可以扩大感受野(每个block12个conv,感受野确实大了),加强长文本检测,效果也不好。
2021.12.8.paperwithcode上imagenet上,densenet-264,top1精度:77.85%,top5:93,densenet-201,top1:77.42%,top5:93.66%,densenet-169,top1:76.2%,top5:93.15%.