朴素贝叶斯--实现垃圾邮件分类
一、贝叶斯定理
贝叶斯定理是关于随机事件和 B的条件概率的一则定理。其中 P( A| B)是在 B发生的情况下 A发生的可能性。
二、朴素贝叶斯分类算法原理
朴素贝叶斯分类算法是基于贝叶斯定理和特征条件独立假设的分类方法。对于给定的训练数据集,首先基于特征条件独立假设学习输入输出的联合概率分布;然后基于此模型,对给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
朴素:假设的各个特征之间相互独立
相关概念
先验概率P(X):先验概率是指根据以往经验和分析得到的概率。
后验概率P(Y|X):事情已发生,要求这件事情发生的原因是由某个因素引起的可能性的大小,后验分布P(Y|X)表示事件X已经发生的前提下,事件Y发生的概率,称事件X发生下事件Y的条件概率。朴素贝叶斯公式
设有样本数据集D{d1,d2,d3,..,dn},对应样本数据的特征属性集X={x1,x2,x3,...,xn},类变量为Y={y1,y2,y3,...,yn},即D可以分为yn个类别。其中x1,x2,x3,...,xn相互独立且随机,则Y的先验概率P1=P(Y),Y的后验概率P2=P(Y|X),由朴素贝叶斯算法可得,后验概率可以由先验概率P1=P(Y)、证据P(X)、类条件概率P(X|Y)计算出:
朴素贝叶斯基于各特征之间相互独立,在给定类别为y的情况下,上式可以进一步表示为式:
由以上两式可以计算出后验概率为:
其中d为属性数目,xi为第i个属性上的值。
由于对所有的类别P(X)相同,因此最终的朴素贝叶斯表达式就为:
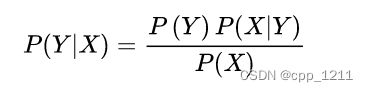
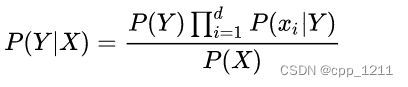
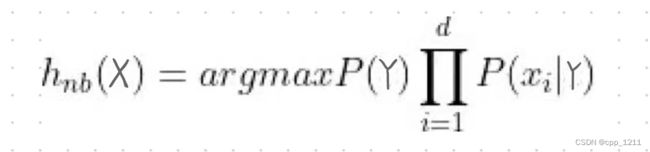
三、拉普拉斯修正
拉普拉斯修正:若某个属性值在训练集中没有与某个类同时出现过,则训练后的模型会出现 over-fitting 现象。比如训练集中没有该样例,因此连乘式计算的概率值为0,这显然不合理。因为样本中不存在(概率为0),不代该事件一定不可能发生。所以为了避免其他属性携带的信息,被训练集中未出现的属性值“ 抹去” ,在估计概率值时通常要进行“拉普拉斯修正”。
令 N 表示训练集 D 中可能的类别数, 表示第i个属性可能的取值数,则贝叶斯公式可修正为:
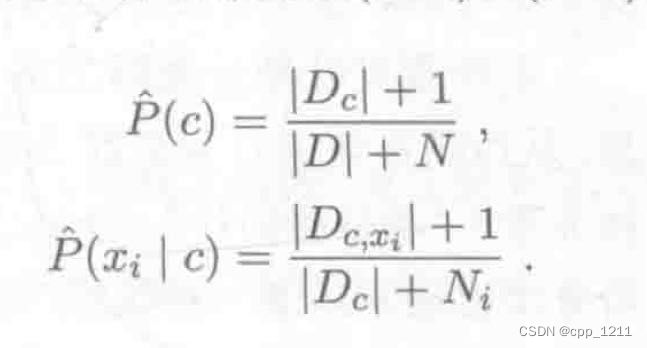
四、朴素贝叶斯优缺点
优点
1. 朴素贝叶斯模型有稳定的分类效率。
2. 对小规模的数据表现很好,能处理多分类任务,适合增量式训练,尤其是数据量超出内存时,可以一批批的去增量训练。
3. 对缺失数据不太敏感,算法也比较简单,常用于文本分类。
缺点
1. 理论上,朴素贝叶斯模型与其他分类方法相比具有最小的误差率。
2. 需要知道先验概率,且先验概率很多时候取决于假设,假设的模型可以有很多种,因此在某些时候会由于假设的先验模型的原因导致预测效果不佳。
3. 由于我们是通过先验和数据来决定后验的概率从而决定分类,所以分类决策存在一定的错误率。
4. 对输入数据的表达形式很敏感。
五、代码实现
5.1 数据集准备
在本次实验中我准备了25条正常邮件内容和25条垃圾邮件内容,以及准备了两条测试数据
5.2 实现词表向向量的转换函数
def loadDataSet(): postingList = [['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'], ['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'], ['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'], ['stop', 'posting', 'stupid', 'worthless', 'garbage'], ['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'], ['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']] classVec = [0, 1, 0, 1, 0, 1] # 1代表侮辱性文字,0代表正常言论 return postingList, classVec # 创建词汇表 def createVocabList(dataSet): vocabSet = set([]) # 创建一个空集 for document in dataSet: vocabSet = vocabSet | set(document) # |表示求并操作 return list(vocabSet) # 返回一个不重复的列表 # 输出文档向量 def setOfwords2Vec(vocabList, inputSet): returnVec = [0] * len(vocabList) # 创建一个等长向量并设置为0 for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] = 1 # 若出现了单词表中的单词,则将对应值设置为1 else: print("单词:%s 不存在!" % word) return returnVec # 测试函数效果 # 创建实验样本 listPosts, listClasses = loadDataSet() print('数据集\n', listPosts) # 创建词汇表 myVocabList = createVocabList(listPosts) print('词汇表:\n', myVocabList) # 输出文档向量 print(setOfwords2Vec(myVocabList, listPosts[5]))测试结果如下:
5.3 定义朴素贝叶斯分类器函数
# 训练朴素贝叶斯分类器 def trainNB0(trainMatrix, trainCategory): # 获得训练文档总数 numTrainDocs = len(trainMatrix) # 计算每篇文档的词总数 numWords = len(trainMatrix[0]) pAbusive = sum(trainCategory) / float(numTrainDocs) p0Num = zeros(numWords) p1Num = zeros(numWords) p0Denom = 0.0 p1Denom = 0.0 for i in range(numTrainDocs): if trainCategory[i] == 1: # 向量相加,统计侮辱类的条件概率,即p(w0|1),p(w1|1),p(w2|1).. p1Num += trainMatrix[i] # 累加每篇文档的总词量 p1Denom += sum(trainMatrix[i]) else: p0Num += trainMatrix[i] p0Denom += sum(trainMatrix[i]) p1Vect = p1Num / p1Denom p0Vect = p0Num / p0Denom return p0Vect, p1Vect, pAbusive5.4 朴素贝叶斯分类函数
def classifyNB(vec2Classify,p0Vec,p1Vec,pClass1): p1=sum(vec2Classify*p1Vec)+log(pClass1) p0=sum(vec2Classify*p0Vec)+log(1.0-pClass1) if p1>p0:#比较类别概率 return 1 else: return 05.5 文档词袋模型
def bagOfWords2VecMN(vocabList, inputSet): # 词袋模型 returnVec = [0] * len(vocabList) for word in inputSet: if word in vocabList: returnVec[vocabList.index(word)] += 1 return returnVec5.6 文件解析 切分文本
def textParse(bigString): # 切分文本 import re listOfTokens = re.split(r'\W+', bigString) return [tok.lower() for tok in listOfTokens if len(tok) > 2]5.7 垃圾邮件测试函数
# 垃圾邮件测试 def spamTest(): docList = [] classList = [] fullText = [] for i in range(1, 26): wordList = textParse(open('D:/pycode/机器学习作业/email/spam/%d.txt' % i).read()) docList.append(wordList) fullText.extend(wordList) classList.append(1) # 将垃圾邮件标记为1 wordList = textParse(open('D:/pycode/机器学习作业/email/ham/%d.txt' % i).read()) docList.append(wordList) fullText.extend(wordList) classList.append(0) # 将正常邮件标记为0 vocabList = createVocabList(docList) trainingSet = list(range(50)) testSet = [] for i in range(10): randIndex = int(random.uniform(0, len(trainingSet))) testSet.append(trainingSet[randIndex]) del (trainingSet[randIndex]) trainMat = [] trainClasses = [] for docIndex in trainingSet: # 遍历训练集 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) trainClasses.append(classList[docIndex]) p0V, p1V, pSpam = trainNB1(array(trainMat), array(trainClasses)) print('词表:\n', vocabList) print('p0v:\n', p0V) print('p1v:\n', p1V) print('pSpam:\n', pSpam) errorCount = 0 for docIndex in testSet: # 遍历测试集 wordVector = bagOfWords2VecMN(vocabList, docList[docIndex]) if classifyNB(array(wordVector), p0V, p1V, pSpam) != classList[docIndex]: errorCount += 1 print('分类错误集', docList[docIndex]) print('错误率:', float(errorCount) / len(testSet)) # 计算错误率 return float(errorCount) / len(testSet) spamTest()构建了一个训练集和测试集,其中测试集是训练集中随机抽选出10封,用来评价该垃圾邮件的错误率。
测试结果:
第一次测试
第二次测试
第三次测试
每次测试运行的结果都不相同,可以多次测试结果,取错误率的平均值
5.8 垃圾邮件分类
# 邮件分类器 def classifyEmail(): docList = [] # 文档列表 classList = [] # 文档标签 fullText = [] # 全部文档内容集合 for i in range(1, 26): # 遍历垃圾邮件和非垃圾邮件各25个 wordList = textParse(open('D:/pycode/机器学习作业/email/spam/%d.txt' % i).read()) # 读取垃圾邮件,将大字符串并将其解析为字符串列表 docList.append(wordList) # 垃圾邮件加入文档列表 fullText.extend(wordList) # 把当前垃圾邮件加入文档内容集合 classList.append(1) # 1表示垃圾邮件,标记垃圾邮件 wordList = textParse(open('D:/pycode/机器学习作业/email/ham/%d.txt' % i).read()) # 读非垃圾邮件,将大字符串并将其解析为字符串列表 docList.append(wordList) # 非垃圾邮件加入文档列表 fullText.extend(wordList) # 把当前非垃圾邮件加入文档内容集合 classList.append(0) # 0表示垃圾邮件,标记非垃圾邮件, vocabList = createVocabList(docList) # 创建不重复的词汇表 trainingSet = list(range(50)) # 为训练集添加索引 trainMat = [] # 创建训练集矩阵训练集类别标签系向量 trainClasses = [] # 训练集类别标签 for docIndex in trainingSet: # for循环使用词向量来填充trainMat列表 trainMat.append(bagOfWords2VecMN(vocabList, docList[docIndex])) # 把词集模型添加到训练矩阵中 trainClasses.append(classList[docIndex]) # 把类别添加到训练集类别标签中 p0V, p1V, pSpam = trainNB0(array(trainMat), array(trainClasses)) # 朴素贝叶斯分类器训练函数 testList = textParse(open('D:/pycode/机器学习作业/email/test/2.txt').read()) # 读取邮件,将大字符串并将其解析为字符串列表 testVector = bagOfWords2VecMN(vocabList, testList) # 获得测试集的词集模型 if classifyNB(array(testVector), p0V, p1V, pSpam): result = "垃圾邮件" else: result = "正常邮件" print("输入邮件内容为: ") print(' '.join(testList)) print('该邮件被分类为: ', result)测试结果: