为什么索引能提高查询速度
先从 MySQL 的基本存储结构说起
MySQL的基本存储结构是页(记录都存在页里边):

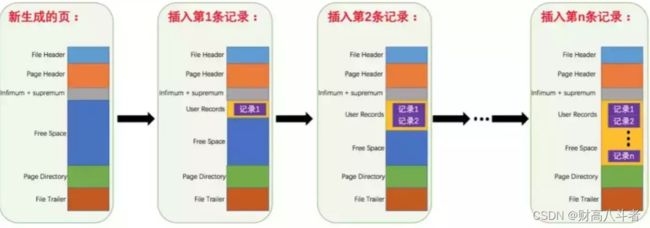
- 各个数据页可以组成一个双向链表
- 每个数据页中的记录又可以组成一个单向链表每个数据页都会为存储在它里边儿的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录
- 以其他列(非主键)作为搜索条件:只能从最小记录开始依次遍历单链表中的每条记录。
所以说,如果我们写select * from user where indexname = 'xxx'这样没有进行任何优化的sql语句,默认会这样做:
- 定位到记录所在的页:需要遍历双向链表,找到所在的页
- 从所在的页内中查找相应的记录:由于不是根据主键查询,只能遍历所在页的单链表了
很明显,在数据量很大的情况下这样查找会很慢!这样的时间复杂度为O(n)。
使用索引之后
索引做了些什么可以让我们查询加快速度呢?其实就是将无序的数据变成有序(相对):

要找到id为8的记录简要步骤:
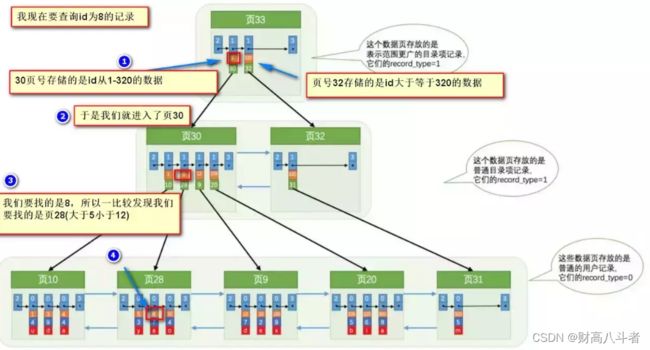
很明显的是:没有用索引我们是需要遍历双向链表来定位对应的页,现在通过 “目录” 就可以很快地定位到对应的页上了!(二分查找,时间复杂度近似为O(logn))
其实底层结构就是B+树,B+树作为树的一种实现,能够让我们很快地查找出对应的记录。
关于索引其他重要的内容补充
以下内容整理自:《Java工程师修炼之道》
最左前缀原则
MySQL中的索引可以以一定顺序引用多列,这种索引叫作联合索引。如User表的name和city加联合索引就是(name,city),而最左前缀原则指的是,如果查询的时候查询条件精确匹配索引的左边连续一列或几列,则此列就可以被用到。如下:
select * from user where name=xx and city=xx ; //可以命中索引 select * from user where name=xx ; // 可以命中索引 select * from user where city=xx; // 无法命中索引
这里需要注意的是,查询的时候如果两个条件都用上了,但是顺序不同,如 city= xx and name =xx,那么现在的查询引擎会自动优化为匹配联合索引的顺序,这样是能够命中索引的.
由于最左前缀原则,在创建联合索引时,索引字段的顺序需要考虑字段值去重之后的个数,较多的放前面。ORDERBY子句也遵循此规则。
注意避免冗余索引
冗余索引指的是索引的功能相同,能够命中 就肯定能命中 ,那么 就是冗余索引如(name,city )和(name )这两个索引就是冗余索引,能够命中后者的查询肯定是能够命中前者的 在大多数情况下,都应该尽量扩展已有的索引而不是创建新索引。
MySQLS.7 版本后,可以通过查询 sys 库的 schema_redundant_indexes 表来查看冗余索引
Mysql如何为表字段添加索引???
1.添加PRIMARY KEY(主键索引)
ALTER TABLE `table_name` ADD PRIMARY KEY ( `column` )
2.添加UNIQUE(唯一索引)
ALTER TABLE `table_name` ADD UNIQUE ( `column` )
3.添加INDEX(普通索引)
ALTER TABLE `table_name` ADD INDEX index_name ( `column` )
4.添加FULLTEXT(全文索引)
ALTER TABLE `table_name` ADD FULLTEXT ( `column`)
5.添加多列索引
ALTER TABLE `table_name` ADD INDEX index_name ( `column1`, `column2`, `column3` )