一、实验说明
1. 环境登录
无需密码自动登录,系统用户名shiyanlou,密码shiyanlou 若不小心登出后,直接刷新页面即可
2. 环境使用
完成实验后可以点击桌面上方的“实验截图”保存并分享实验结果到微博,向好友展示自己的学习进度。实验楼提供后台系统截图,可以真实有效证明您已经完成了实验。 实验记录页面可以在“我的主页”中查看,其中含有每次实验的截图及笔记,以及每次实验的有效学习时间(指的是在实验桌面内操作的时间,如果没有操作,系统会记录为发呆时间)。这些都是您学习的真实性证明。
3. 课程来源
VIM 在线手册
二、vim模式介绍
以下介绍内容来自维基百科Vim
从vi演生出来的Vim具有多种模式,这种独特的设计容易使初学者产生混淆。几乎所有的编辑器都会有插入和执行命令两种模式,并且大多数的编辑器使用了与Vim截然不同的方式:命令目录(鼠标或者键盘驱动),组合键(通常通过control键(CTRL)和alt键(ALT)组成)或者鼠标输入。Vim和vi一样,仅仅通过键盘来在这些模式之中切换。这就使得Vim可以不用进行菜单或者鼠标操作,并且最小化组合键的操作。对文字录入员或者程序员可以大大增强速度和效率。
Vim具有6种基本模式和5种派生模式,我们这里只简单介绍下6种基本模式:
- 普通模式(Normal mode)
在普通模式中,用的编辑器命令,比如移动光标,删除文本等等。这也是Vim启动后的默认模式。这正好和许多新用户期待的操作方式相反(大多数编辑器默认模式为插入模式)。
Vim强大的编辑能来自于其普通模式命令。普通模式命令往往需要一个操作符结尾。例如普通模式命令dd删除当前行,但是第一个"d"的后面可以跟另外的移动命令来代替第二个d,比如用移动到下一行的"j"键就可以删除当前行和下一行。另外还可以指定命令重复次数,2dd(重复dd两次),和dj的效果是一样的。用户学习了各种各样的文本间移动/跳转的命令和其他的普通模式的编辑命令,并且能够灵活组合使用的话,能够比那些没有模式的编辑器更加高效的进行文本编辑。
在普通模式中,有很多方法可以进入插入模式。比较普通的方式是按a(append/追加)键或者i(insert/插入)键。
- 插入模式(Insert mode)
在这个模式中,大多数按键都会向文本缓冲中插入文本。大多数新用户希望文本编辑器编辑过程中一直保持这个模式。
在插入模式中,可以按ESC键回到普通模式。
- 可视模式(Visual mode)
这个模式与普通模式比较相似。但是移动命令会扩大高亮的文本区域。高亮区域可以是字符、行或者是一块文本。当执行一个非移动命令时,命令会被执行到这块高亮的区域上。Vim的"文本对象"也能和移动命令一样用在这个模式中。
- 选择模式(Select mode)
这个模式和无模式编辑器的行为比较相似(Windows标准文本控件的方式)。这个模式中,可以用鼠标或者光标键高亮选择文本,不过输入任何字符的话,Vim会用这个字符替换选择的高亮文本块,并且自动进入插入模式。
- 命令行模式(Command line mode)
在命令行模式中可以输入会被解释成并执行的文本。例如执行命令(:键),搜索(/和?键)或者过滤命令(!键)。在命令执行之后,Vim返回到命令行模式之前的模式,通常是普通模式。
- Ex模式(Ex mode)
这和命令行模式比较相似,在使用:visual命令离开Ex模式前,可以一次执行多条命令。
这其中我们常用到就是普通模式、插入模式和命令行模式,本课程也只涉及这三个常用模式的内容
2.三种常用模式的切换
vim启动进入普通模式,处于插入模式或命令行模式时只需要按Esc或者Ctrl+[(这在vim课程环境中不管用)即可进入普通模式。普通模式中按i(插入)或a(附加)键都可以进入插入模式,普通模式中按:进入命令行模式。命令行模式中输入wq回车后保存并退出vim。
三、进入vim
1.使用vim命令进入vim界面
vim后面加上你要打开的已存在的文件名或者不存在(则作为新建文件)的文件名。 打开Xfce终端,输入以下命令
$ vim practice_1.txt
直接使用vim也可以打开vim编辑器,但是不会打开任何文件。
$ vim
进入命令行模式后输入:e 文件路径 同样可以打开相应文件。
2.游标移动
在进入vim后,按下i键进入插入模式。在该模式下您可以输入文本信息,下面请输入如下三行信息:
12345678
abcdefghijk
shiyanlou.com
按Esc进入普通模式,在该模式下使用方向键或者h,j,k,l键可以移动游标。
| 按键 |
说明 |
| h |
左 |
| l |
右(小写L) |
| j |
下 |
| k |
上 |
| w |
移动到下一个单词 |
| b |
移动到上一个单词 |
请尝试在普通模式下使用方向键移动光标到shiyanlou这几个字母上面。
四、进入插入模式
1.进入插入模式
在普通模式下使用下面的键将进入插入模式,并可以从相应的位置开始输入
| 命令 |
说明 |
| i |
在当前光标处进行编辑 |
| I |
在行首插入 |
| A |
在行末插入 |
| a |
在光标后插入编辑 |
| o |
在当前行后插入一个新行 |
| O |
在当前行前插入一个新行 |
| cw |
替换从光标所在位置后到一个单词结尾的字符 |
请尝试不同的从普通模式进入插入模式的方法,在最后一行shiyanlou前面加上www.,注意每次要先回到普通模式才能切换成以不同的方式进入插入模式
五、保存文档
1.命令行模式下保存文档
从普通模式输入:进入命令行模式,输入w回车,保存文档。输入:w 文件名可以将文档另存为其他文件名或存到其它路径下
六、退出vim
1.命令行模式下退出vim
从普通模式输入:进入命令行模式,输入wq回车,保存并退出编辑
以下为其它几种退出方式:
| 命令 |
说明 |
| :q! |
强制退出,不保存 |
| :q |
退出 |
| :wq! |
强制保存并退出 |
| :w <文件路径> |
另存为 |
| :saveas 文件路径 |
另存为 |
| :x |
保存并退出 |
| :wq |
保存并退出 |
2.普通模式下退出vim
普通模式下输入Shift+zz即可保存退出vim
七、删除文本
1.普通模式下删除vim文本信息
进入普通模式,使用下列命令可以进行文本快速删除:
| 命令 |
说明 |
| x |
删除游标所在的字符 |
| X |
删除游标所在前一个字符 |
| Delete |
同x |
| dd |
删除整行 |
| dw |
删除一个单词(不适用中文) |
| d$或D |
删除至行尾 |
| d^ |
删除至行首 |
| dG |
删除到文档结尾处 |
| d1G |
删至文档首部 |
除此之外,你还可以在命令之前加上数字,表示一次删除多行,如:
2dd表示一次删除2行
我们来做如下练习:
$ cp /etc/protocols .
$ vim protocols
一、vim重复命令
1.重复执行上次命令
在普通模式下.(小数点)表示重复上一次的命令操作
拷贝测试文件到本地目录
$ cp /etc/protocols .
打开文件进行编辑
$ vim protocols
普通模式下输入x,删除第一个字符,输入.(小数点)会再次删除一个字符,除此之外也可以重复dd的删除操作
2.执行指定次数相同的命令
进入普通模式输入N,N表示重复后面的次数,下面来练习以下:
打开文件文件进行编辑
$ vim protocols
下面你可以依次进行如下操作练习:
- 输入
10x,删除10个连续字符 - 输入
3dd,将会删除3行文本
在普通模式下,你还可以使用dw或者daw(delete a word)删除一个单词,所以你可以很容易的联想到dnw(n替换为相应数字)表示删除n个单词
二、游标的快速跳转
普通模式下,下列命令可以让光标快速调转到指定位置,我们分别讨论快速实现行间跳转和行内跳转
1.行间跳转
| 命令 |
说明 |
|
|
游标移动到第 n 行(如果默认没有显示行号,请先进入命令模式,输入 |
|
|
游标移动到到第一行 |
|
|
到最后一行 |
还是来练习一下吧:
使用vim打开练习文档
$ vim protocols
依次进行如下操作练习:
- 快速跳转到第9行,然后将其该行删除
- 回到第一行,向下删除8行
- 跳转到文档末,然后删除该行
小技巧:你在完成依次跳转后,可以使用Ctrl+o快速回到上一次(跳转前)光标所在位置,这个技巧很实用,比如当你在写代码时,忽然想起有个bug,需要修改,这时候你跳过去改好了,只需要按下Ctrl+o就可以回到你之前的位置。vim中会用很多类似的小技巧就等着你去发掘。
2.行内跳转
普通模式下使用下列命令在行内按照单词为单位进行跳转
| 命令 |
说明 |
|
|
到下一个单词的开头 |
|
|
到下一个单词的结尾 |
|
|
到前一个单词的开头 |
|
|
到前一个单词的结尾 |
|
|
到行头 |
|
|
到行尾 |
|
|
向后搜索<字母>并跳转到第一个匹配的位置(非常实用) |
|
|
向前搜索<字母>并跳转到第一个匹配的位置 |
|
|
向后搜索<字母>并跳转到第一个匹配位置之前的一个字母(不常用) |
|
|
向前搜索<字母>并跳转到第一个匹配位置之后的一个字母(不常用) |
依次进行如下操作练习:
- 在普通模式下,任意跳转到一行,使用
w跳转到一个单词的开头,然后使用dw删除这个单词 - 在普通模式下,使用
e跳转到一个单词的结尾,并使用~将游标所在字母变成大写或小写
三、复制粘贴和剪切
1.复制及粘贴文本
- 普通模式中使用
y复制 - 普通模式中,
yy复制游标所在的整行(3yy表示复制3行) - 普通模式中,
y^复制至行首,或y0。不含光标所在处字符。 - 普通模式中,
y$复制至行尾。含光所在处字符。 - 普通模式中,
yw复制一个单词。 - 普通模式中,
y2w复制两个单词。 - 普通模式中,
yG复制至文本末。 - 普通模式中,
y1G复制至文本开头。 - 普通模式中使用
p粘贴 - 普通模式中,
p(小写)代表粘贴至光标后(下) - 普通模式中,
P(大写)代表粘贴至光标前(上)
打开文件进入普通模式练习上述命令,这会儿你就可以随意yy了,一 一+
$ vim protocols
2.剪切及粘贴
其实前面讲得dd删除命令就是剪切,你每次dd删除文档内容后,便可以使用p来粘贴,也这一点可以让我们实现一个很爽快的功能——交换上下行:
ddp,就这么简单,即实现了快速交换光标所在行与它下面的行
四、总结
这一小节你应该掌握了几个经常使用到的操作,包括快速行间移动和快速行内移动,以及剪切和复制粘贴等操作,希望你能够多加练习熟练掌握,一旦当你熟练了这些操作将会极大地提高你的工作效率。
一、多文件编辑
1.使用vim编辑多个文件
编辑多个文件有两种形式,一种是在进入vim前使用的参数就是多个文件。另一种就是进入vim后再编辑其他的文件。 同时创建两个新文件并编辑
$vim1.txt2.txt
默认进入1.txt文件的编辑界面
- 命令行模式下输入
:n编辑2.txt文件,可以加!即:n!强制切换,之前一个文件的输入没有保存,仅仅切换到另一个文件 - 命令行模式下输入
:N编辑1.txt文件,可以加!即:N!强制切换,之前文件内的输入没有保存,仅仅是切换到另一个文件 - 命令行模式下输入
:e 3.txt打开新文件3.txt - 命令行模式下输入
:e#回到前一个文件 - 命令行模式下输入
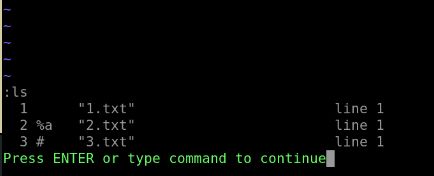
:ls可以列出以前编辑过的文档 - 命令行模式下输入
:b 2.txt(或者编号)可以直接进入文件2.txt编辑 - 命令行模式下输入
:bd 2.txt(或者编号)可以删除以前编辑过的列表中的文件项目 - 命令行模式下输入
:e! 4.txt,新打开文件4.txt,放弃正在编辑的文件 - 命令行模式下输入
:f显示正在编辑的文件名 - 命令行模式下输入
:f new.txt,改变正在编辑的文件名字为new.txt
2.进入vim后打开新文件
3.恢复文件
如果因为断电等原因造成文档没有保存,可以采用恢复方式,vim -r进入文档后,输入:ewcover 1.txt来恢复
$vim -r1.txt
二、可视模式
1.可视模式命令简介
- 在普通模式下输入
v(小写),进入字符选择模式,就可以移动光标,光标走过的地方就会选取。再次按下v会后就会取消选取。 - 在普通模式下输入
Shift+v(小写),进入行选择模式,按下V之后就会把整行选取,您可以上下移动光标选更多的行,同样,再按一次Shift+v就可以取消选取。 - 在普通模式下输入
Ctrl+v(小写),这是区域选择模式,可以进行矩形区域选择,再按一次Ctrl+v取消选取。 - 在普通模式下输入
d删除选取区域内容 - 在普通模式下输入
y复制选取区域内容
2.可视模式命令练习
拷贝练习文件到当前目录
$ cp /etc/protocols .
打开练习文件
$ vim protocols
- 在普通模式下
9G跳转到第9行,输入Shift+v(小写V),进入可视模式进行行选择,选中5行,按下>>缩进,将5行整体缩进一个shiftwidth - 在普通模式下输入
Ctrl+v(小写v),进入可视模式进行矩形区域选择,选中第一列字符然后x删除整列
三、视窗操作
1.视窗操作简介
vim可以在一个界面里打开多个窗口进行编辑,这些编辑窗口称为vim的视窗。 打开方法有很多种,例如可以使用在命令行模式下输入:new 打开一个新的vim视窗,并进入视窗编辑一个新文件(普通模式下输入Ctrl+w也可以,但是Ctrl+w在chrome下会与chrome关闭标签页的快捷键冲突,所以使用该快捷键你可以在IE或其它浏览器进行练习),除了:new命令,下述列举的多种方法也可以在命令模式或普通模式下打开新的视窗:
- 命令行模式下输入
:sp 1.txt打开新的横向视窗来编辑1.txt - 命令行模式下输入
:vsp 2.txt打开新的纵向视窗来编辑1.txt - 普通模式下
Ctrl-w s将当前窗口分割成两个水平的窗口 - 普通模式下
Ctrl-w v将当前窗口分割成两个垂直的窗口 - 普通模式下
Ctrl-w q即 :q 结束分割出来的视窗。如果在新视窗中有输入需要使用强制符!即:q! - 普通模式下
Ctrl-w o打开一个视窗并且隐藏之前的所有视窗 - 普通模式下
Ctrl-w j移至下面视窗 - 普通模式下
Ctrl-w k移至上面视窗 - 普通模式下
Ctrl-w h移至左边视窗 - 普通模式下
Ctrl-w l移至右边视窗 - 普通模式下
Ctrl-w J将当前视窗移至下面 - 普通模式下
Ctrl-w K将当前视窗移至上面 - 普通模式下
Ctrl-w H将当前视窗移至左边 - 普通模式下
Ctrl-w L将当前视窗移至右边 - 普通模式下
Ctrl-w -减小视窗的高度 - 普通模式下
Ctrl-w +增加视窗的高度
2.视窗操作练习
打开练习文件
$vim1.txt
- 命令行模式下输入
:new打开一个新的vim视窗 - 命令行模式下输入
:sp 2.txt打开新的横向视窗来编辑2.txt - 命令行模式下输入
:vsp 3.txt打开新的横向视窗来编辑3.txt - 如果使用非chrome浏览器可以使用
Ctrl+w进行视窗间的跳转 - 分别在不同视窗的命令行模式下输入
:q!退出多视窗编辑
四、文档加密
1.创建加密文档
$ vim -x file1
输入您的密码 确认密码 这样在下一次打开时,vim就会要求你输入密码
五、在vim执行外部命令
在命令行模式中输入!可以执行外部的shell命令
:!ls用于显示当前目录的内容:!rm FILENAME用于删除名为 FILENAME 的文件:w FILENAME可将当前 VIM 中正在编辑的文件另存为 FILENAME 文件- 普通模式下按
F1打开vim自己预设的帮助文档 - 命令行模式下输入
:h shiftwidth打开名为shiftwidth的帮助文件 - 命令行模式下输入
:ver显示版本及参数
六、帮助系统
1.vim中的查看帮助
七、功能设定
1.vim的功能设定
可以在编辑文件的时候进行功能设定,如命令行模式下输入:set nu(显示行数),设定值退出vim后不会保存。要永久保存配置需要修改vim配置文件。 vim的配置文件~/.vimrc,可以打开文件进行修改,不过务必小心不要影响vim正常使用
2.获取目前的设定
- 命令行模式下输入
:set或者:se显示所有修改过的配置 - 命令行模式下输入
:set all显示所有的设定值 - 命令行模式下输入
:set option?显示option的设定值 - 命令行模式下输入
:set nooption取消当期设定值 - 命令行模式下输入
:set autoindent(ai)设置自动缩进 - 命令行模式下输入
:set autowrite(aw)设置自动存档,默认未打开 - 命令行模式下输入
:set background=dark或light,设置背景风格 - 命令行模式下输入
:set backup(bk)设置自动备份,默认未打开 - 命令行模式下输入
: set cindent(cin)设置C语言风格缩进
3.set功能的说明
更多详细参数请参考vim手册
八、总结
通过这四章的简单学习,相应你应该掌握了vim的基本操作和使用,但本课程的主要目的是为了让你在学习实验楼上面其他需要用到vim的课程中不会有任何问题。如果你想单纯的学习并熟练掌握vim编辑器,通过各类教程包括本课程的学习是不能够满足的,因为要熟练掌握是跟你个人的选择有关,这需要你不断的联系并坚持长期使用vim完成各种编辑操作才能达到,同时你还需要掌握如何更改和编写vim的配置文件及安装各类vim插件来实现各种强大的功能满足你的各种苛刻的需求,最后希望你在实验楼玩得愉快
1 Linux命令
如果使用GUI,Linux和Windows没有什么区别。Linux学习应用的一个特点是通过命令行进行使用。
登录Linux后,我们就可以在#或$符后面去输入命令,有的时候命令后面还会跟着选项(options)或参数(arguments)。即Linux中命令格式为:
command [options] [arguments] //中括号代表是可选的,即有些命令不需要选项也不需要参数
选项是调整命令执行行为的开关,选项不同决定了命令的显示结果不同。
参数是指命令的作用对象。
如ls命令,ls或ls .显示是当前目录的内容,这里“.”就是参数,表示当前目录,是缺省的可以省略。我们可以用ls -a .显示当前目录中的所有内容,包括隐藏文件和目录。其中“-a” 就是选项,改变了显示的内容,如下图所示:
以上简要说明了选项及参数的区别,但具体Linux中哪条命令有哪些选项及参数,需要我们靠经验积累或者查看Linux的帮助了。
2 man命令
不论学习编程还是Linux命令,掌握帮助文档的使用都是很重要的,是举一反三的重要途径。 man是manul的缩写,我们可以通过man man来查看man的帮助,如下图:
帮助文档包含:
1 Executable programs or shell commands(用户命令帮助)
2 System calls (系统调用帮助)
3 Library calls (库函数调用帮助)
4 Special files (usually found in /dev)
5 File formats and conventions eg /etc/passwd(配置文件帮助)
6 Games
7 Miscellaneous (including macro packages and conventions), e.g. man(7), groff(7)
8 System administration commands (usually only for root)
9 Kernel routines [Non standard]
解释一下:
1是普通的Linux命令
2是系统调用,操作系统的提供的服务接口
3是库函数, C语言中的函数
5是指文件的格式,比如passwd, 就会说明这个文件中各个字段的含义
6是给游戏留的,由各个游戏自己定义
7是附件还有一些变量,比如向environ这种全局变量在这里就有说明
8是系统管理用的命令,这些命令只能由root使用,如ifconfig
其中1,2,3是我们学习的重点,区别大家练习一下就知道了,比如printf是C语言的库函数,也是一个Linux命令,大家尝试一下man printf,man 1 printf,man 3 printf,体会一下区别。
知道printf 命令也好,printf函数也好,查找帮助文档都很容易。man有一个-k 选项用起来非常好,这个选项让你学习命令,编程时有了一个搜索引擎,可以举一反三。 我们通过一个例子来说明,比如数据结构中学过排序(sort),我不知道C语言中有没有完成这个功能的函数,可以通过“man -k sort”来搜索,因为是找C库函数,我们关注带3的,qsort好像是个好选项,如下图:
结合后面学习的grep 命令和管道,可以多关键字查找:
man -k key1 | grep key2 | grep key3 | ...
如下图,可以更好的找到qsort:
3 cheat 命令
man 虽然很重要,但有些命令看了帮助还不会用,初学者需要例子,cheat就是这个身边的小抄。 cheat 命令不是Linux自带的,大家参考这篇文章(英文版)安装,实验楼课程实验系统中已经安装了。
cheat是作弊,小抄的意思。
cheat命令是在GNU通用公共许可证下,为Linux命令行用户发行的交互式备忘单应用程序。它提供显示Linux命令使用案例,包括该命令所有的选项和简短但尚可理解的功能。
使用cheat命令作弊是可以的。:)
4 其他核心命令
和查找相关的核心命令还有find,locate,grep,whereis,which,其中:
- find查找一个文件在系统中的什么位置,locate是神速版本的find(Windows下有个Everything工具和locate类似).
- grep 可以对文件全文检索,支持正则表达式,正则表达式也是一个重要的元知识。
- whereis,which告诉你使用的命令工具装在什么地方。
实验二 Linux下C语言编程基础
一、实验目的
1. 熟悉Linux系统下的开发环境
2. 熟悉vi的基本操作
3. 熟悉gcc编译器的基本原理
4. 熟练使用gcc编译器的常用选项
5 .熟练使用gdb调试技术
6. 熟悉makefile基本原理及语法规范
7. 掌握静态库和动态库的生成
二、实验步骤
1. 快捷键
Ubuntu中:
2. vim
VIM是一个非常好的文本编辑器,很多专业程序员使用VIM编辑代码,即使以后你不编写程序,只要跟文本打交道,都应该学学VIM,可以浏览参考一下普通人的编辑利器——Vim。
VIM学习曲线非常陡峭,各种编辑器学习曲线如下图(有调侃的意思):
VI来说,一开始就需要相当大的技能,但一旦掌握这些技能,则你将会越来越熟练,这跟五笔打字很类似。我们建议通过实践练习来学习具体来说通过VIMTUTOR或玩游戏(Vim大冒险或PacVim)来学习。
玩游戏去Vim大冒险或PacVim通关就学会了VIM。
VIMTUTOR是个实践教程,通过实践30分钟让你对VIM编辑器入门,只要在命令行中输入vimtutor,然后跟着教程练习就可以了。如下图:
然后你可以把这张图做计算机的桌面背景,每天学习一两个键:
想当程序员用这张专门给程序员的键盘图:
程序员有几个键提示一下:
- 大写“K”可以用来查找函数的帮助信息:查看 man page,命令模式下,将光标放在函数名上,按"K"可以直接察看 man page。
- 几个设置
:set nu 显示行号
:set ai 自动缩行
:set ts=4 设置一个 TAB 键等于几个空格
- 移动光标
[[ 转到上一个位于第一列的"{"
]] 转到下一个位于第一列的"{"
{ 转到上一个空行
} 转到下一个空行
gd 转到当前光标所指的局部变量的定义
深入学习参考:
- 简明 Vim 练级攻略
- 七个高效的文本编辑习惯(以Vim为例)(视频)
- 所需即所获:像 IDE 一样使用 vim
- VIM教程与学习资料汇总
3. gcc
GNU CC(简称为gcc)是GNU项目中符合ANSI C标准的编译系统,能够编译用C、C++和Object C等语言编写的程序。gcc又是一个交叉平台编译器,它能够在当前CPU平台上为多种不同体系结构的硬件平台开发软件,因此尤其适合在嵌入式领域的开发编译。
GCC编译代码的过程如下:
我们可以把编译过程分成四步,以编译hello.c生成可执行文件hello为例,如下图:
- 预处理:gcc –E hello.c –o hello.i;gcc –E调用cpp
- 编 译:gcc –S hello.i –o hello.s;gcc –S调用ccl
- 汇 编:gcc –c hello.s –o hello.o;gcc -c 调用as
- 链 接:gcc hello.o –o hello ;gcc -o 调用ld
编译过程比较难记,我们简化一下,前三步,GCC的参数连起来是“ESc”,相应输入的文件的后缀是“iso”,这样记忆起来就容易多了。
学习GCC的另外一个重点是:参考教材《深入理解计算机系统》 7.6,7.10节,学习静态库,动态库的制作。
4. gdb
建议使用CGDB,比GDB好用,熟悉VC的调试方式,可以使用DDD。 注意使用GCC编译时要加“-g”参数。 参考gdb参考卡GDB最基本的命令有:
- gdb programm(启动GDB)
- b 设断点(要会设4种断点:行断点、函数断点、条件断点、临时断点)
- run 开始运行程序
- bt 打印函数调用堆栈
- p 查看变量值
- c 从当前断点继续运行到下一个断点
- n 单步运行
- s 单步运行
- quit 退出GDB
问题:GDB的n(next)命令让GDB执行下一行,然后暂停。 s(step)命令的作用与此类似,只是在函数调用时step命令会进入函数,那么实际使用中应该优先选用哪个?为什么?
其他几个我认为应该掌握的调试命令有:
- display 跟踪变量值的改变
- until 跳出循环
- finish 跳出函数
- help 帮助
本实验所有的源代码都可下载:
git clone http://git.shiyanlou.com/shiyanlou/Linux-c-code
GCC 的使用
一、实验说明
1. 课程说明
工欲善其事, 必先利其器,因此会从编程工具gcc,gdb入手逐步讲解Linux系统编程。本节课程讲解 gcc 编译器的使用。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、 编译器gcc的使用
1. gcc 支持编译的一些源文件后缀名
| 后缀 |
源文件 |
| .c |
C语言源文件 |
| .C .cc .cxx |
C++源文件 |
| .m |
Object-C源文件 |
| .i |
经过预处理后的C源文件 |
| .ii |
经过预处理后的C++源文件 |
| .s .S |
汇编语言源文件 |
| .h |
预处理文件(头文件) |
| .o |
目标文件 |
| .a |
存档文件 |
3. gcc 编译程序的流程
Tips:
- Linux的可执行文件并没有像 Windows 那样有明显的.exe后缀名, 只需向其分配x(可执行)权限即可
sudo chmod u+x excutefile - 作为Linux程序员,我们可以让gcc在编译的任何阶段结束,以便检查或使用该阶段的输出(这个很重要)
3. 用 gcc 编译一个经典 C 程序
注意:可以使用GVim编辑器进行代码输入,代码块中的注释可以不需输入。
打开的gvim环境中输入i进入编辑模式,输入以下代码
// filename: hello.c
#include
int main(int argc, char **argv)
{printf("Hello, Shi-Yan-Lou!");
} /**
*在XfceTerminal打开后的界面中输入:$gcc hello.c -o hello
*如果没有error,说明编译成功,将会在当前目录生成一个可执行文件 hello
*继续输入:./hello 就会运行该程序,在bash上打印出 Hello, Shi-Yan-Lou!
**/
保存为hello.c文件
Tips;
gcc hello.c -o hello--- 第二个hello为文件名,名字任意取定(但是不能违反bash的规则)gcc hello.c -o "(-_-|||)", 但是作为一名优秀的程序员还是取个有意义的名字吧!- 从程序员的角度来看,一个简单的-o选项可以省略很多中间步骤一次性输出可执行文件; 但从编译器的角度来看,这条命令的背后是一系列的繁杂的工作。
4. gcc 到底背着我们做了什么
首先gcc会调用预处理程序cpp,由它负责展开在源程序中定义的宏(上例:#include ),向其中插入#include语句所包含的内容(原地展开stdio.h包含的代码)
在Xfce终端中输入
$ gcc -E hello.c -o hello.i还记得.i后缀吗?hello.i这是一个经过预处理器处理之后的C源文件,在bash试试这个命令,然后用vim打开它。
gcc的-E参数可以让gcc在预处理结束后停止编译过程。
第二步,将hello.i编译为目标代码,gcc默认将.i文件看成是预处理后的C语言源代码,因此它会直接跳过预处理,开始编译过程。
$ gcc -c hello.i -o hello.o同样,用vim打开.o文件看看和.i .c文件有什么不同?应该是一片乱码,是吧?(它已经是二进制文件了)
Tips:
- 请记住,gcc预处理源文件的时候(第一步),不会进行语法错误的检查
- 语法检查会在第二步进行,比如花括号不匹配、行末尾没有分号、关键字错误......
第三步,gcc连接器将目标文件链接为一个可执行文件,一个大致的编译流程结束
gcc hello.o -o hello三、gcc 编译模块化的程序
现在很多软件都是采用的模块化开发,通常一个程序都是有很多个源文件组成,相应的就形成了多个编译单元。gcc能够很好的处理这些编译单元,最终形成一个可执行程序
代码编辑和输入参考上述使用gvim程序输入,并在XfceTerminal界面使用gcc进行编译。
// hello.h
extern void print();
这是个头文件,将会在hello_main.c中调用
// hello_print.c
#include
void print()
{printf("Hello, Shi-Yan-Lou\n");
}// hello_main.c
#include "hello.h"
void print();
int main(int argc, char **argv)
{ print();} // XfceTerminal中 $gcc hello_print.c hello_main.c -o hello 进行编译
// 将会打印出 Hello, Shi-Yan-Lou
Tips: 以上的gcc hello_print.c hello_main.c -o hello可以看成是执行了一下3条命令
$ gcc -c hello_print.c -o hello_print.o$ gcc -c hello_main.c -o hello_main.o$ gcc hello_print.o hello_main.o -o hello
GDB 使用
一、实验说明
1. 课程说明
工欲善其事, 必先利其器,因此会从编程工具gcc,gdb入手逐步讲解Linux系统编程。上次我们讲解了 gcc 编译器的使用,然而没有什么事物是完美无缺的,往往写出来的程序都会有不同程度的缺陷,因此本节课程将讲解 gdb 调试器(Debug)的使用,它可以帮助我们找出程序之中的错误和漏洞等等。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、gdb 概 述
当程序编译完成后,它可能无法正常运行;或许程序会彻底崩溃;或许只是不能正常地运行某些功能;或许它的输出会被挂起;或许不会提示要求正常的输入。无论在何种情况下,跟踪这些问题,特别是在大的工程中,将是开发中最困难的部分,我们将学习gdb(GNU debugger)调试程序的方法,该程序是一个调试器,是用来帮助程序员寻找程序中的错误的软件。
gdb是GNU开发组织发布的一个强大的UNIX/Linux下的程序调试工具。或许,有人比较习惯图形界面方式的,像VC、BCB等IDE环境,但是在UNIX/Linux平台下做软件,gdb这个调试工具有比VC、BCB的图形化调试器更强大的功能。所谓“寸有所长,尺有所短”就是这个道理。 一般来说,gdb主要帮忙用户完成下面4个方面的功能:
- 启动程序,可以按照用户自定义的要求随心所欲的运行程序。
- 可让被调试的程序在用户所指定的调试的断点处停住 (断点可以是条件表达式)。
- 当程序停住时,可以检查此时程序中所发生的事。
- 动态地改变程序的执行环境。
- 从上面来看,gdb和一般的调试工具区别不大,基本上也是完成这些功能,不过在细节上,会发现gdb这个调试工具的强大。大家可能习惯了图形化的调试工具,但有时候,命令行的调试工具却有着图形化工具所不能完成的功能。
gdb.c
#include
int func(int n)
{
int sum=0,i;
for(i=0; i
sum+=i;
}
return sum;
}
int main(void)
{
int i;
long result = 0;
for(i=1; i<=100; i++) {
result += i;
}
printf("result[1-100] = %ld \n", result );
printf("result[1-250] = %d \n", func(250) );
}
编译生成执行文件(Linux下):
$ gcc –g gdb.c -o testgdb
使用gdb调试:
$ gdb testgdb <---------- 启动gdb
.......此处省略一万行
键入 l命令相当于list命令,从第一行开始列出源码:
$ gdb testgdb
.......此处省略一万行
(gdb) l
7 {
8 sum+=i;
9 }
10 return sum;
11 }
12
13 int main(void)
14 {
15 int i;
16 long result = 0;
(gdb)
17 for(i=1; i<=100; i++)
18 {
19 result += i;
20 }
21 printf("result[1-100] = %ld \n", result );
22 printf("result[1-250] = %d \n", func(250) );
23 }
(gdb) break 16 <-------------------- 设置断点,在源程序第16行处。
Breakpoint 1 at 0x804836a: file test.c, line 16.
(gdb) break func <-------------------- 设置断点,在函数func()入口处。
Breakpoint 2 at 0x804832e: file test.c, line 5.
(gdb) info break <-------------------- 查看断点信息。
Num Type Disp Enb Address What
1 breakpoint keep y 0x0804836a in main at test.c:16
2 breakpoint keep y 0x0804832e in func at test.c:5
(gdb) r <--------------------- 运行程序,run命令简写
Starting program: /home/shiyanlou/testgdb
Breakpoint 1, main () at test.c:16 <---------- 在断点处停住。
16 long result = 0;
(gdb) n <--------------------- 单条语句执行,next命令简写。
17 for(i=1; i<=100; i++)
(gdb) n
19 result += i;
(gdb) n
17 for(i=1; i<=100; i++)
(gdb) n
19 result += i;
(gdb) n
17 for(i=1; i<=100; i++)
(gdb) c <--------------------- 继续运行程序,continue命令简写。
Continuing.
result[1-100] = 5050 <----------程序输出。
Breakpoint 2, func (n=250) at test.c:5
5 int sum=0,i;
(gdb) n
6 for(i=0; i
(gdb) p I <--------------------- 打印变量i的值,print命令简写。
$1 = 1107620064
(gdb) n
8 sum+=i;
(gdb) n
6 for(i=0; i
(gdb) p sum
$2 = 0
(gdb) bt <--------------------- 查看函数堆栈。
#0 func (n=250) at test.c:6
#1 0x080483b2 in main () at test.c:22
#2 0x42015574 in __libc_start_main () from /lib/tls/libc.so.6
(gdb) finish <--------------------- 退出函数。
Run till exit from #0 func (n=250) at test.c:6
0x080483b2 in main () at test.c:22
22 printf("result[1-250] = %d /n", func(250) );
Value returned is $3 = 31125
(gdb) c <--------------------- 继续运行。
Continuing.
result[1-250] = 31125
Program exited with code 027. <--------程序退出,调试结束。
(gdb) q <--------------------- 退出gdb。
有了以上的感性认识,下面来系统地学习一下gdb。
三、使 用 gdb
gdb主要调试的是C/C++的程序。要调试C/C++的程序,首先在编译时,必须要把调试信息加到可执行文件中。使用编译器(cc/gcc/g++)的 -g 参数即可。如:
$ gcc -g hello.c -o hello
$ g++ -g hello.cpp -o hello
如果没有-g,将看不见程序的函数名和变量名,代替它们的全是运行时的内存地址。当用-g把调试信息加入,并成功编译目标代码以后,看看如何用gdb来调试。 启动gdb的方法有以下几种:
- gdb
program也就是执行文件,一般在当前目录下。 - gdb
core 用gdb同时调试一个运行程序和core文件,core是程序非法执行后,core dump后产生的文件。 - gdb
如果程序是一个服务程序,那么可以指定这个服务程序运行时的进程ID。gdb会自动attach上去,并调试它。program应该在PATH环境变量中搜索得到。 gdb启动时,可以加上一些gdb的启动开关,详细的开关可以用gdb -help查看。下面只列举一些比较常用的参数: -symbols -s 从指定文件中读取符号表。 -se file 从指定文件中读取符号表信息,并把它用在可执行文件中。 -core -c 调试时core dump的core文件。 -directory -d 加入一个源文件的搜索路径。默认搜索路径是环境变量中PATH所定义的路径。
Makefile 使用
一、实验说明
1. 课程说明
在先前的课程中,我们已经学习了 gcc 和 gdb 的使用。本节课程中,我们将介绍 Makefile 的使用。Makefile带来的好处就是——“自动化编译”,一但写好,只需要一个 make 命令,整个工程便可以完全编译,极大的提高了软件的开发效率(特别是对于那些项目较大、文件较多的工程)。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、Makefile 简介
读者经常看到一个C程序的项目常常由很多的文件组成,那么,多文件的好处到底在哪里呢?一个最简单也最直接有力的理由就是,这样可以将一个大项目分成多个小的部分,独立开来,利于结构化管理。在修改和维护的时候,优势就更明显了。例如,需要对代码做一点小的改动,如果这个项目所有的代码都在一个文件中,那么就要重新编译所有这些代码,这是很耗时的,不仅效率低,而且维护难度更大。但是,如果是多个不同的文件,那么只需要重新编译这些修改过的文件就行了,而且其他源文件的目标文件都已经存在,没有必要重复编译,这样就会快捷很多。
因此,通过合理有效的划分,将一个项目分解为多个易于处理的文件,是非常明智的做法。多文件的管理方式非常正确的选择。
一个工程中的源文件不计其数,按其类型、功能、模块分别放在若干个目录中。makefile定义了一系列的规则来指定,哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至进行更复杂的功能操作(因为makefile就像一个shell脚本一样,可以执行操作系统的命令)。
makefile带来的好处就是——“自动化编译”,一但写好,只需要一个make命令,整个工程完全编译,极大的提高了软件的开发效率。make是一个命令工具,是一个及时makefile中命令的工具程序。
make工具最主要也是最基本的功能就是根据makefile文件中描述的源程序至今的相互关系来完成自动编译、维护多个源文件工程。而makefile文件需要按某种语法进行编写,文件中需要说明如何编译各个源文件并链接生成可执行文件,要求定义源文件之间的依赖关系。
二、Makefile 基本规则
下面从一个简单实例入手,介绍如何编写Makefile。假设现在有一个简单的项目由几个文件组成:prog.c、 code.c、 code.h。这些文件的内容如下:
prog.c
#include
#include "code.h"
int main(void) { int i = 1; printf ("myfun(i) = %d\n", myfun(i)); } code.c
#include "code.h"
int myfun(int in) { return in + 1; } code.h
extern int myfun(int); 这些程序都比较短,结构也很清晰,因此使用下面的命令进行编译:
$ gcc -c code.c -o code.o
$ gcc -c prog.c -o prog.o
$ gcc prog.o code.o -o test
如上所示,这样就能生成可执行文件test,由于程序比较简单,而且数量也比较少,因此看不出来有多麻烦。但是,试想如果不只上面的3个文件,而是几十个或者是成百上千个甚至更多,那将是非常复杂的问题。
那么如何是好呢?这里就是makefile的绝佳舞台,下面是一个简单的makefile的例子。
首先$ vim Makefile
test: prog.o code.o
gcc prog.o code.o -o test
prog.o: prog.c code.h
gcc -c prog.c -o prog.o
code.o: code.c code.h
gcc -c code.c -o code.o
clean:
rm -f *.o test
有了这个Makefile,不论什么时候修改源文件,只要执行一下make命令,所有必要的重新编译将自动执行。make程序利用Makefile中的数据,生成并遍历以test为根节点的树;现在我们以上面的实例,来学习一下Makefile的一般写法:
test(目标文件): prog.o code.o(依赖文件列表)
tab(至少一个tab的位置) gcc prog.o code.o -o test(命令)
.......
一个Makefile文件主要含有一系列的规则,每条规则包含一下内容:一个目标,即make最终需要创建的文件,如可执行文件和目标文件;目标也可以是要执行的动作,如‘clean’;一个或多个依赖文件的列表,通常是编译目标文件所需要的其他文件。之后的一系列命令,是make执行的动作,通常是把指定的相关文件编译成目标文件的编译命令,每个命令占一行,并以tab开头(初学者务必注意:是tab,而不是空格) 执行以上Makefile后就会自动化编译:
$ make
gcc -c prog.c -o prog.o
gcc -c code.c -o code.o
gcc prog.o code.o -o test
最后就会多产生: porg.o code.o test这三个文件,执行./test查看结果
还记得Makefile中的clean吗? make clean就会去执行rm -f *.o test这条命令,完成 clean 操作。
四、使用带宏的 Makefile
Makefile还可以定义和使用宏(也称做变量),从而使其更加自动化,更加灵活,在Makefile中定义宏的格式为:
macroname = macrotext
使用宏的格式为:
$(macroname)
五、作业思考
用 “宏” 的方式,来改写上面的 Makefile 例子。
参考答案:
OBJS = prog.o code.o CC = gcc test: $(BOJS) $(CC) $(OBJS) -o test prog.o: prog.c code.h $(CC) -c prog.c -o prog.o code.o: code.c code.h $(CC) -c code.c -o code.o clean: rm -f *.o test
文件 IO(一)
一、实验说明
1. 课程说明
本节课程介绍 Linux 系统的文件 IO,除了介绍其基本概念,最主要的是讲解其基本 APIs,包括 open、close、read、write 等等。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、文件 I\O 介绍
1. Linux系统调用
Linux系统调用(system call)是指操作系统提供给用户程序的一组“特殊接口”,用户程序可以通过这组“特殊”接口来获得操作系统提供的特殊服务。
为了更好的保护内核空间,将程序的运行空间分为内核空间和用户空间,他们运行在不同的级别上,在逻辑上是相互隔离的。在Linux中,用户程序不能直接访问内核提供的服务,必须通过系统调用来使用内核提供的服务。
Linux中的用户编程接口(API)遵循了UNIX中最流行的应用编程界面标准——POSIX。这些系统调用编程接口主要是通过C库(libc)实现的。
2. 文件描述符
对内核而言,所有打开文件都由文件描述符引用。文件描述符是一个非负整数。当打开一个现存文件或创建一个新文件时,内核向进程返回一个文件描述符。当写一个文件时,用open或create返回的文件描述符标识该文件,将其作为参数传送给read或write。
在POSIX应用程序中,整数0、1、2应被代换成符号常数:
- STDIN_FILENO(标准输入,默认是键盘)
- STDOUT_FILENO(标准输出,默认是屏幕)
- STDERR_FILENO(标准错误输出,默认是屏幕)
这些常数都定义在头文件
可用的文件I\O函数很多,包括:打开文件,读文件,写文件等。大多数Linux文件I\O只需要用到5个函数:open,read,write,lseek以及close。
三、 基本API
1. open
需要包含的头文件:
int open(const str * pathname, int oflag, [..., mode_t mode]) 功能:打开文件 返回值:成功则返回文件描述符,出错返回-1 参数:
pathname: 打开或创建的文件的全路径名 oflag:可用来说明此函数的多个选择项, 详见后。 mode:对于open函数而言,仅当创建新闻件时才使用第三个参数,表示新建文件的权限设置。
详解oflag参数: oflag 参数由O_RDONLY(只读打开)、O_WRONLY(只写打开)、O_RDWR(读写打开)中的一个于下列一个或多个常数 O_APPEND: 追加到文件尾 O_CREAT: 若文件不存在则创建它。使用此选择项时,需同时说明第三个参数mode,用其说明新闻件的访问权限 O_EXCL: 如果同时指定O_CREAT,而该文件又是存在的,报错;也可以测试一个文件是否存在,不存在则创建。 O_TRUNC: 如果次文件存在,而且为读写或只写成功打开,则将其长度截短为0 O_SYNC: 使每次write都等到物理I\O操作完成
用open创建一个文件: open.c
#include
#include
#include #include #include #define FILE_PATH "./test.txt" int main(void) { int fd; if ((fd = open(FILE_PATH, O_RDWR | O_CREAT | O_EXCL, 0666)) < 0) { printf("open error\n"); exit(-1); } else { printf("open success\n"); } return 0; } 如果当前目录下以存在test.txt,屏幕上就会打印“open error”;不存在则创建该文件,并打印“open success”
2. read
需要包含的头文件:
函数原型:
ssize_t read(int fd, void * buf, size_t count) 功能:从打开的文件中读取数据。 返回值:实际读到的字节数;已读到文件尾返回0,出错的话返回-1,ssize_t是系统头文件中用typedef定义的数据类型相当于signed int 参数: fd:要读取的文件的描述符 buf:得到的数据在内存中的位置的首地址 count:期望本次能读取到的最大字节数。size_t是系统头文件中用typedef定义的数据类型,相当于unsigned int
3. write
需要包含的头文件:
ssize_t write(int fd, const void * buf, size_t count) 功能:向打开的文件写数据 返回值:写入成功返回实际写入的字节数,出错返回-1
不得不提的是,返回-1的常见原因是:磁盘空间已满,超过了一个给定进程的文件长度
参数: fd:要写入文件的文件描述符 buf:要写入文件的数据在内存中存放位置的首地址 count:期望写入的数据的最大字节数
read和write使用范例:
#include
#include
#include int main(void) { char buf[100]; int num = 0; // 获取键盘输入,还记得POSIX的文件描述符吗? if ((num = read(STDIN_FILENO, buf, 10)) == -1) { printf ("read error"); error(-1); } else { // 将键盘输入又输出到屏幕上 write(STDOUT_FILENO, buf, num); } return 0; } 4. close
需要包含的头文件:int close(int filedes) 功能:关闭一个打开的文件 参数:需要关闭文件的文件描述符
当一个进程终止的时候,它所有的打开文件都是由内核自动关闭。很多程序都使用这一功能而不显式地调用close关闭一个已打开的文件。 但是,作为一名优秀的程序员,应该显式的调用close来关闭已不再使用的文件。
5. lseek
每个打开的文件都有一个“当前文件偏移量”,是一个非负整数,用以度量从文件开始处计算的字节数。通常,读写操作都是从当前文件偏移量处开始,并使偏移量增加所读或写的字节数。默认情况下,你打开一个文件时(open),除非指定O_APPEND参数,不然位移量被设为0。
需要包含的头文件:
off_t lseek(int filesdes, off_t offset, int whence) 功能:设置文件内容读写位置 返回值:成功返回新的文件位移,出错返回-1;同样off_t是系统头文件定义的数据类型,相当于signed int 参数:
- whence是SEEK_SET, 那么该文件的位移量设置为据文件开始处offset个字节
- whence是SEEK_CUR, 那么该文件的位移量设置为当前值加offset。offset可为正或负
- whence是SEEK_END, 那么盖文佳的位移量设置为文件长度加offset。offset可为正或负
#include
#include
#include #include #include int main(int argc, char * argv[]) { int fd; char buf[100]; if ((fd = open(argv[1], O_RDONLY)) < 0) { perror("open"); exit(-1); } read(fd, buf, 1); write(STDOUT_FILENO, buf, 1); lseek(fd, 2, SEEK_CUR); read(fd, buf, 1); write(STDOUT_FILENO, buf, 1); lseek(fd, -1, SEEK_END); read(fd, buf, 1); write(STDOUT_FILENO, buf, 1); lseek(fd, 0, SEEK_SET); read(fd, buf, 1); write(STDOUT_FILENO, buf, 1); close(fd); printf("\n"); return 0; } 6. select
之前的read函数可以监控一个文件描述符(eg:键盘)是否有输入,当键盘没有输入,read将会阻塞,直到用户从键盘输入为止。用相同的方法可以监控鼠标是否有输入。但想同时监控鼠标和键盘是否有输入,这个方法就不行的了。
// /dev/input/mice 是鼠标的设备文件
fd = open("/dev/input/mice", O_RDONLY);
read(0, buf, 100);
read(fd, buf, 100); 在上面的程序中,当read键盘的时候,若无键盘输入则程序阻塞在第2行,此时即使鼠标有输入,程序也没有机会执行第3行获得鼠标的输入。这种情况就需要select同时监控多个文件描述符。
需要包含的头文件:
int select(int maxfd, fd_set \* readset, fd_set \* writeset, fd_set \* exceptset, const struct timeval \* timeout) 返回值:失败返回-1,成功返回readset,writeset,exceptset中所有,有指定变化的文件描述符的数目(若超时返回0)
参数: maxfd:要检测的描述符个数, 因此值应为最大描述符+1 readset:被监控是否有输入的文件描述符集。不监控时,设为NULL writeset:被监控是否可以输入的文件描述符集。不监控时,设为NULL exceptset:被监控是否有错误产生的文件描述符集。不监控时,设为NULL timeval:监控超时时间。设置为NULL表示一直阻塞到有文件描述符被监控到有指定变化。
Tips: readset,writeset,exceptset这三个描述符集指针均是值—结果参数,调用的时候,被监控描述符相应位需要置1;返回时,未就绪的描数字相应位会被清0,而就绪的会被置1。 下面的系统定义的宏,和select配套使用 FD_ZERO(&rset):将文件描述符集rset的所有位清0FD_SET(4, &reset):设置文件描述符集rset的bit 4FD_CLR(fileno(stdin), &rset):将文件描述符集rset的bit 0清0FD_ISSET(socketfd, &rset):若文件描述符集rset中的socketfd位置1
#include
#include
#include #include #define MAXNUM 100 #define OPEN_DEV "/dev/input/mice" int main(void) { fd_set rfds; struct timeval tv; int retval, fd; char buf[MAXNUM]; fd = open(OPEN_DEV, O_RDONLY); while (1) { FD_ZERO(&rfds); FD_SET(0, &rfds); FD_SET(fd, &rfds); tv.tv_sec = 5; tv.tv_usec = 0; retval = select(fd+1, &rfds, NULL, NULL, &tv); if (retval < 0) printf ("error\n"); if (retval == 0) printf ("No data within 5 seconds\n"); if (retval > 0) { if (FD_ISSET(0, &rfds)) { printf ("Data is available from keyboard now\n"); read(0, buf, MAXNUM); } if (FD_ISSET(fd, &rfds)) { printf ("Data is available from mouse now\n"); read(fd, buf, MAXNUM); } } } return 0; }
文件 IO(二)
一、实验说明
1. 课程说明
本节课程继续介绍 Linux 系统的文件 IO。主要介绍 stat 的使用(查看文件相关信息,例如文件类型、文件权限等等),以及目录相关(打开、读取、关闭目录)的操作。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、stat 的使用
Linux有个命令,ls -l,效果如下:
$ ls -l
-rw-rw-r-- 1 shiyanlou shiyanlou 978 Sep 19 02:13 hello.c 这个命令能显示文件的类型、操作权限、硬链接数量、属主、所属组、大小、修改时间、文件名。它是怎么获得这些信息的能,这一节我们将拨开迷雾。
1. stat 的基本使用
系统调用stat的作用是获取文件的各个属性。
需要包含的头文件:
int stat(const char \* path, struct stat \* buf) 功能:查看文件或目录属性。将参数path所指的文件的属性,复制到参数buf所指的结构中。 参数: path:要查看属性的文件或目录的全路径名称。 buf:指向用于存放属性的结构体。stat成功调用后,buf的各个字段将存放各个属性。struct stat是系统头文件中定义的结构体,定义如下:
struct stat {
dev_t st_dev;
ino_t st_ino;
mode_t st_mode;
nlink_t st_nlink;
uid_t st_uid;
gid_t st_gid;
dev_t st_rdev;
off_t st_size;
blksize_t st_blksize;
blkcnt_t st_blocks;
time_t st_atime;
time_t st_mtime;
time_t st_ctime;
};
st_ino:节点号 st_mode:文件类型和文件访问权限被编码在该字段中 st_nlink:硬连接数 st_uid:属主的用户ID st_gid:所属组的组ID st_rdev:设备文件的主、次设备号编码在该字段中 st_size:文件的大小 st_mtime:文件最后被修改时间
返回值:成功返回0;失败返回-1
#include
#include
#include #include #include int main(int argc, char **argv) { struct stat buf; if(argc != 2) { printf("Usage: stat "); exit(-1); } if(stat(argv[1], &buf) != 0) { printf("stat error."); exit(-1); } printf("#i-node: %ld\n", buf.st_ino); printf("#link: %d\n", buf.st_nlink); printf("UID: %d\n", buf.st_uid); printf("GID: %d\n", buf.st_gid); printf("Size %ld\n", buf.st_size); exit(0); } 2. 文件类型的判定
上一小节中struct stat中有个字段为st_mode,可用来获取文件类型和文件访问权限,我们将陆续学到从该字段解码我们需要的文件信息。 st_mode中文件类型宏定义:
| 宏定义 | 文件类型 |
|---|---|
| S_ISREG() | 普通文件 |
| S_ISDIR() | 目录文件 |
| S_ISCHR() | 字符设备文件 |
| S_ISBLK() | 块设备文件 |
| S_ISFIFO() | 有名管道文件 |
| S_ISLNK() | 软连接(符号链接)文件 |
| S_ISSOCK() | 套接字文件 |
我们修改上面的例子:
#include
#include
#include #include #include int main(int argc, char **argv) { struct stat buf; char * file_mode; if(argc != 2) { printf("Usage: stat \n"); exit(-1); } if(stat(argv[1], &buf) != 0) { printf("stat error.\n"); exit(-1); } if (S_ISREG(buf.st_mode)) file_mode = "-"; else if (S_ISDIR(buf.st_mode)) file_mode = "d"; else if (S_ISCHR(buf.st_mode)) file_mode = "c"; else if(S_ISBLK(buf.st_mode)) file_mode = "b"; printf("#i-node: %ld\n", buf.st_ino); printf("#link: %d\n", buf.st_nlink); printf("UID: %d\n", buf.st_uid); printf("GID: %d\n", buf.st_gid); printf("Size %ld\n", buf.st_size); printf("mode: %s\n", file_mode); exit(0); } 3. 文件权限的判定
文件类型与许可设定被一起编码在st_mode字段中,同上面一样,我们也需要一组由系统提供的宏来完成解码。
| 宏定义 | 文件类型 |
|---|---|
| S_ISUID | 执行时,设置用户ID |
| S_ISGID | 执行时,设置组ID |
| S_ISVTX | 保存正文 |
| S_IRWXU | 拥有者的读、写和执行权限 |
| S_IRUSR | 拥有者的读权限 |
| S_IWUSR | 拥有者的写权限 |
| S_IXUSR | 拥有者的执行权限 |
| S_IRWXG | 用户组的读、写和执行权限 |
| S_IRGRP | 用户组的读权限 |
| S_IWGRP | 用户组的写权限 |
| S_IXGRP | 用户组的执行权限 |
| S_IRWXO | 其它读、写、执行权限 |
| S_IROTH | 其它读权限 |
| S_IWOTH | 其它写权限 |
| S_IXOTH | 其它执行权限 |
三、 目录操作
当目标是目录而不是文件的时候,ls -l的结果会显示目录下所有子条目的信息,怎么去遍历整个目录呢?答案马上揭晓!
1. 打开目录
需要包含的头文件:DIR * opendir(const char * name) 功能:opendir()用来打开参数name指定的目录,并返回DIR *形态的目录流 返回值:成功返回目录流;失败返回NULL
2. 读取目录
函数原型:struct dirent * readdir(DIR * dir) 功能:readdir()返回参数dir目录流的下一个子条目(子目录或子文件) 返回值: 成功返回结构体指向的指针,错误或以读完目录,返回NULL
函数执行成功返回的结构体原型如下:
struct dirent { ino_t d_ino; off_t d_off; unsigned short d_reclen; unsigned char d_type; char d_name[256]; };其中 d_name字段,是存放子条目的名称
3. 关闭目录
函数原型:int closedir(DIR * dir) 功能:closedir()关闭dir所指的目录流 返回值:成功返回0;失败返回-1,错误原因在errno中
我们来学习一个综合的例子吧:
#include
#include
#include int main(int argc, char *argv[]) { DIR *dp; struct dirent *entp; if (argc != 2) { printf("usage: showdir dirname\n"); exit(0); } if ((dp = opendir(argv[1])) == NULL) { perror("opendir"); exit(-1); } while ((entp = readdir(dp)) != NULL) printf("%s\n", entp->d_name); closedir(dp); return 0; }
多进程编程(一)
一、实验说明
1. 课程说明
本节课程介绍 Linux 系统多进程编程。会先阐述一些理论知识,重点在于内存布局以及 进程 fork 的知识点。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、 概述
进程的概念这里就不再过多的赘述了,市面上几乎关于计算机操作系统的书都有详细的描述。 在基本的概念里我们学习一下Linux进程状态:
R (TASK_RUNNING),可执行状态。
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进程调度器的任务就是从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为 TASK_RUNNING状态。
S (TASK_INTERRUPTIBLE),可中断的睡眠状态。
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。 绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。(参见《linux内核异步中断浅析》) 在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。执行vfork系统调用后,父进程将进入TASK_UNINTERRUPTIBLE状态,直到子进程调用exit或exec(参见《神奇的vfork》)。 通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:
$ ps -ax | grep a\.out 4371 pts/0 D+ 0:00 ./a.out 4372 pts/0 S+ 0:00 ./a.out 4374 pts/1 S+ 0:00 grep a.out然后我们可以试验一下TASK_UNINTERRUPTIBLE状态的威力。不管kill还是kill -9,这个TASK_UNINTERRUPTIBLE状态的父进程依然屹立不倒。
T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。(SIGSTOP与SIGKILL信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。) 向进程发送一个SIGCONT信号,可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态。
当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
对于进程本身来说,TASK_STOPPED和TASK_TRACED状态很类似,都是表示进程暂停下来。 而TASK_TRACED状态相当于在TASK_STOPPED之上多了一层保护,处于TASK_TRACED状态的进程不能响应SIGCONT信号而被唤醒。只能等到调试进程通过ptrace系统调用执行PTRACE_CONT、PTRACE_DETACH等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复TASK_RUNNING状态。
Z (TASK_DEAD – EXIT_ZOMBIE),退出状态,进程成为僵尸进程。
进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。 之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。 当然,内核也可以将这些信息保存在别的地方,而将task_struct结构释放掉,以节省一些空间。但是使用task_struct结构更为方便,因为在内核中已经建立了从pid到task_struct查找关系,还有进程间的父子关系。释放掉task_struct,则需要建立一些新的数据结构,以便让父进程找到它的子进程的退出信息。
父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。 子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收尸”。这个信号默认是SIGCHLD,但是在通过clone系统调用创建子进程时,可以设置这个信号。
$ ps -ax | grep a\.out 10410 pts/0 S+ 0:00 ./a.out 10411 pts/0 Z+ 0:00 [a.out] 0413 pts/1 S+ 0:00 grep a.out只要父进程不退出,这个僵尸状态的子进程就一直存在。那么如果父进程退出了呢,谁又来给子进程“收尸”? 当进程退出的时候,会将它的所有子进程都托管给别的进程(使之成为别的进程的子进程)。托管给谁呢?可能是退出进程所在进程组的下一个进程(如果存在的话),或者是1号进程。所以每个进程、每时每刻都有父进程存在。除非它是1号进程。
1号进程,pid为1的进程,又称init进程。 linux系统启动后,第一个被创建的用户态进程就是init进程。它有两项使命: 1、执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙); 2、在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作; init进程不会被暂停、也不会被杀死(这是由内核来保证的)。它在等待子进程退出的过程中处于TASK_INTERRUPTIBLE状态,“收尸”过程中则处于TASK_RUNNING状态。
X (TASK_DEAD – EXIT_DEAD),退出状态,进程即将被销毁。
而进程在退出过程中也可能不会保留它的task_struct。比如这个进程是多线程程序中被detach过的进程(进程?线程?参见《linux线程浅析》)。或者父进程通过设置SIGCHLD信号的handler为SIG_IGN,显式的忽略了SIGCHLD信号。(这是posix的规定,尽管子进程的退出信号可以被设置为SIGCHLD以外的其他信号。) 此时,进程将被置于EXIT_DEAD退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
以上内容均摘自博文:http://blog.csdn.net/huzia/article/details/18946491
1. 进程标识
获取进程标志号(pid)的API,主要有两个函数:getpid和getppid
需要包含的头文件:
函数原型:pid_t getppid(void) 功能:获取父进程ID 返回值:调用进程的父进程ID
pid_ppid.c
#include
#include
#include int main(void) { pid_t pid = getpid(); pid_t ppid = getppid(); printf ("pid = %d\n", pid); printf ("ppid = %d\n", ppid); return 0; } 三、精解 Linux 下 C 进程内存布局
1. C 进程内存布局说明
text:代码段。存放的是程序的全部代码(指令),来源于二进制可执行文件中的代码部分
initialized data(简称data段)和uninitialized data(简称bss段)组成了数据段。
其中data段存放的是已初始化全局变量和已初始化static局部变量,来源于二进制可执行文件中的数据部分;bss段存放的是未初始化全局变量和未初始化static局部变量,其内容不来源于二进制可执行文件中的数据部分(也就是说:二进制可执行文件中的数据部分没有未初始化全局变量和未初始化static局部变量)。根据C语言标准规定,他们的初始值必须为0,因此bss段存放的是全0。将bss段清0的工作是由系统在加载二进制文件后,开始执行程序前完成的,系统执行这个清0操作是由内核的一段代码完成的,这段代码就是即将介绍的exec系统调用。至于exec从内存什么地方开始清0以及要清0多少空间,则是由记录在二进制可执行文件中的信息决定的(即:二进制文件中记录了text、data、bss段的大小)
malloc是从heap(堆)中分配空间的
stack(栈)存放的是动态局部变量。
当子函数被调用时,系统会从栈中分配空间给该子函数的动态局部变量(注意:此时栈向内存低地址延伸);当子函数返回时,系统的栈会向内存高地址延伸,这相当于释放子函数的动态局部变量的内存空间。我们假设一下,main函数在调用子函数A后立即调用子函数B,那么子函数B的动态局部变量会覆盖原来子函数A的动态局部变量的存储空间,这就是子函数不能互相访问对方动态局部变量的根本物理原因。
内存的最高端存放的是命令行参数和环境变量,将命令行参数和环境变量放到指定位置这个操作是由OS的一段代码(exec系统调用)在加载二进制文件到内存后,开始运行程序前完成的
Linux下C进程内存布局可以由下面的程序的运行结果来获得验证:
memery.c
1 #include
2 #include 3 4 int global_init_val = 100; 5 int global_noninit_val; 6 extern char **environ; 7 8 int main(int argc, char *argv[], char *envp[]) 9 { 10 static int localstaticval = 10; 11 char *localval; 12 localval = malloc(10); 13 printf("address of text is : %p\n", main); 14 printf("address of data is : %p, %p\n", &global_init_val, &localstaticval); 15 printf("address of bss is : %p\n", &global_noninit_val); 16 printf("address of heap is : %p\n", localval); 17 printf("address of stack is : %p\n", &localval); 18 free(localval); 19 20 printf("&environ = %p, environ = %p\n", &envp, envp); 21 printf("&argv = %p, argv = %p\n", &argv, argv); 22 return 0; 23 } 运行结果,如下:
1 address of text is : 0x8048454
2 address of data is : 0x804a01c, 0x804a020 3 address of bss is : 0x804a02c 4 address of heap is : 0x96e1008 5 address of stack is : 0xbffca8bc 6 &environ = 0xbffca8d8, environ = 0xbffca97c 7 &argv = 0xbffca8d4, argv = 0xbffca974 运行结果分析: 运行结果的第1(2、3、4、5、6、7)行是由程序的第13(14、15、16、17、20、21)行打印的。 由运行结果的第1、2、3、4行可知,存放的是程序代码的text段位于进程地址空间的最低端;往上是存放已初始化全局变量和已初始化static局部变量的data段;往上是存放未初始化全局变量的bss段;往上是堆区(heap)。 由运行结果的第7、6、5行可知,命令行参数和环境变量存放在进程地址空间的最高端;往下是存放动态局部变量的栈区(stack)。
2. 环境变量的获取与设置
坏境变量在内存中通常是一字符串环境变量名=环境变量值的形式存放。对坏境变量含义的急事依赖于具体的应用程序。我们的程序可能会调用Linux系统的环境变量,甚至修改环境变量,所以,Linux向我们提供了这种API。
需要包含的头文件:
函数原型: char * getenc(const char * name) 返回字符指针,该指针指向变量名为name的环境变量的值字符串。
int putenv(const char * str) 将“环境变量=环境变量值”形式的字符创增加到环境变量列表中;如果该环境变量已存在,则更新已有的值。
int setenv(const char * name, const char * value, int rewrite) 设置名字为name的环境变量的值为value;如果该环境变量已存在,且rewrite不为0,用新值替换旧值;rewrite为0,就不做任何事。
env.c
#include
#include
#include int main(int argc, char *argv[], char *envp[]) { char **ptr; for (ptr = envp; *ptr != 0; ptr++) /* and all env strings */ printf ("%s\n", *ptr); printf ("\n\n--------My environment variable-------\n\n"); printf ("USERNAME is %s\n", getenv("USERNAME")); putenv ("USERNAME=shiyanlou"); printf ("USERNAME is %s\n", getenv("USERNAME")); setenv ("USERNAME", "shiyanlou-2", 0); printf ("USERNAME is %s\n", getenv("USERNAME")); setenv ("USERNAME", "shiyanlou-2", 1); printf ("USERNAME is %s\n", getenv("USERNAME")); return 0; } 四、进程控制天字第1号系统调用 — fork
1. fork 的机制与特性
#include
#include
#include int main(void) { pid_t pid; if ((pid = fork()) == 0) { getchar(); exit(0); } getchar(); } 父进程调用fork将会产生一个子进程。此时会有2个问题:
- 子进程的代码从哪里来?
- 子进程首次被OS调度时,执行的第1条代码是哪条代码?
子进程的代码是父进程代码的一个完全相同拷贝。事实上不仅仅是text段,子进程的全部进程空间(包括:text/data/bss/heap/stack/command line/environment variables)都是父进程空间的一个完全拷贝。 下一个问题是:谁为子进程分配了内存空间?谁拷贝了父进程空间的内容到子进程的内存空间?fork当仁不让!事实上,查看fork实现的源代码,由4部分工作组成:首先,为子进程分配内存空间;然后,将父进程空间的全部内容拷贝到分配给子进程的内存空间;然后在内核数据结构中创建并正确初始化子进程的PCB(包括2个重要信息:子进程pid,PC的值=善后代码的第1条指令地址);最后是一段善后代码。 由于子进程的PCB已经产生,所以子进程已经出生,因此子进程就可以被OS调度到来运行。子进程首次被OS调度时,执行的第1条代码在fork内部,不过从应用程序的角度来看,子进程首次被OS调度时,执行的第1条代码是从fork返回。这就导致了fork被调用1次,却返回2次:父、子进程中各返回1次。对于应用程序员而言,最重要的是fork的2次返回值不一样,父进程返回值是子进程的pid,子进程的返回值是0。 至于子进程产生后,父、子进程谁先运行,取决于OS调度策略,应用程序员无法控制。 以上分析了fork的内部实现以及对应用程序的影响。如果应用程序员觉得难以理解的话,可以暂时抛开,只要记住3个结论即可:
- fork函数被调用1次(在父进程中被调用),但返回2次(父、子进程中各返回一次)。两次返回的区别是子进程的返回值是0,而父进程的返回值则是子进程的进程ID。
- 父、子进程完全一样(代码、数据),子进程从fork内部开始执行;父、子进程从fork返回后,接着执行下一条语句。
- 一般来说,在fork之后是父进程先执行还是子进程先执行是不确定的,应用程序员无法控制。
2. fork 实例分析
fork.c
1 #include
2 #include 3 #include 4 #include 5 6 #define err_sys(info) 7 { 8 printf ("%s\n", info); 9 exit(0); 10 } 11 12 int glob = 6; /* external variable in initialized data */ 13 char buf[ ] = "a write to stdout\n"; 14 15 int main(void) 16 { 17 int var; /* automatic variable on the stack */ 18 pid_t pid; 19 var = 88; 20 21 if ((write(STDOUT_FILENO, buf, sizeof(buf)-1) != sizeof(buf)-1)) 22 err_sys("write error"); 23 24 printf("before fork\n"); /* we don't flush stdout */ 25 26 if ( (pid = fork()) < 0) { 27 err_sys("fork error"); 28 } else if (pid == 0) { /* child */ 29 glob++; /* modify variables */ 30 var++; 31 } else { 32 sleep(2); /* parent */ 33 } 34 35 printf("pid = %d, ppid = %d, glob = %d, var = %d\n", getpid(),getppid(), glob, var); 36 exit(0); 37 } 运行结果:
1 a write to stdout
2 before fork
3 pid = 9009, ppid = 9008, glob = 7, var = 89 4 pid = 9008, ppid = 8979, glob = 6, var = 88 运行结果分析: 结果的第1行是由父进程的21行打印; 结果的第2行是由父进程的24行打印; 由于父进程在24行睡眠了2秒,因此fork返回后,子进程先于父进程运行是大概率事件,所以子进程运行到25行打印出结果中的第3行。由于子进程会拷贝父进程的整个进程空间(这其中包括数据),因此当子进程26行从fork返回后,子进程中的glob=6,var=88(拷贝自父进程的数据)。此时子进程中pid=0,因此子进程会执行29、30行,当子进程到达35行时,将打印glob=7,var=89。
虽然,子进程改变了glob和var的值,但它仅仅是改变了子进程中的glob和var,而影响不了父进程中的glob和var。在子进程出生后,父、子进程的进程空间(代码、数据等)就是独立,互不干扰的。因此当父进程运行到35行,将会打印父进程中的glob和var的值,他们分别是6和88,这就是运行结果的第4行。
多进程编程(二)
一、实验说明
1. 课程说明
本节继续介绍 Linux 系统多进程编程。上节课程主要介绍了 fork,这节课程将介绍另一个重要的进程相关的 exec。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、揭秘文件描述符的本质
1. 文件描述符的本质是数组元素的下标
右侧的表称为i节点表,在整个系统中只有1张。该表可以视为结构体数组,该数组的一个元素对应于一个物理文件。
中间的表称为文件表,在整个系统中只有1张。该表可以视为结构体数组,一个结构体中有很多字段,其中有3个字段比较重要:
- file status flags:用于记录文件被打开来读的,还是写的。其实记录的就是open调用中用户指定的第2个参数
- current file offset:用于记录文件的当前读写位置(指针)。正是由于此字段的存在,使得一个文件被打开并读取后,下一次读取将从上一次读取的字符后开始读取
- v-node ptr:该字段是指针,指向右侧表的一个元素,从而关联了物理文件。
左侧的表称为文件描述符表,每个进程有且仅有1张。该表可以视为指针数组,数组的元素指向文件表的一个元素。最重要的是:数组元素的下标就是大名鼎鼎的文件描述符。
open系统调用执行的操作:新建一个i节点表元素,让其对应打开的物理文件(如果对应于该物理文件的i节点元素已经建立,就不做任何操作);新建一个文件表的元素,根据open的第2个参数设置file status flags字段,将current file offset字段置0,将v-node ptr指向刚建立的i节点表元素;在文件描述符表中,寻找1个尚未使用的元素,在该元素中填入一个指针值,让其指向刚建立的文件表元素。最重要的是:将该元素的下标作为open的返回值返回。
这样一来,当调用read(write)时,根据传入的文件描述符,OS就可以找到对应的文件描述符表元素,进而找到文件表的元素,进而找到i节点表元素,从而完成对物理文件的读写。
2. fork 对文件描述符的影响
fork会导致子进程继承父进程打开的文件描述符,其本质是将父进程的整个文件描述符表复制一份,放到子进程的PCB中。因此父、子进程中相同文件描述符(文件描述符为整数)指向的是同一个文件表元素,这将导致父(子)进程读取文件后,子(父)进程将读取同一文件的后续内容。
案例分析(forkfd.c):
1 #include
2 #include 3 #include 4 #include 5 #include 6 #include 7 8 int main(void) 9 { 10 int fd, pid, status; 11 char buf[10]; 12 if ((fd = open("./test.txt", O_RDONLY)) < 0) { 13 perror("open"); exit(-1); 14 } 15 if ((pid = fork()) < 0) { 16 perror("fork"); exit(-1); 17 } else if (pid == 0) { //child 18 read(fd, buf, 2); 19 write(STDOUT_FILENO, buf, 2); 20 } else { //parent 21 sleep(2); 23 lseek(fd, SEEK_CUR, 1); 24 read(fd, buf, 3); 25 write(STDOUT_FILENO, buf, 3); 26 write(STDOUT_FILENO, "\n", 1); 27 } 28 return 0; 29 } 假设,./test.txt的内容是abcdefg。那么子进程的18行将读到字符ab;由于,父、子进程的文件描述符fd都指向同一个文件表元素,因此当父进程执行23行时,fd对应的文件的读写指针将移动到字符d,而不是字符b,从而24行读到的是字符def,而不是字符bcd。程序运行的最终结果是打印abdef,而不是abbcd。
相对应的,如果是两个进程独立调用open去打开同一个物理文件,就会有2个文件表元素被创建,并且他们都指向同一个i节点表元素。两个文件表元素都有自己独立的current file offset字段,这将导致2个进程独立的对同一个物理文件进行读写,因此第1个进程读取到文件的第1个字符后,第2个进程再去读取该文件时,仍然是读到的是文件的第1个字符,而不是第1个字符的后续字符。
对应用程序员而言,最重要结论是: 如果子进程不打算使用父进程打开的文件,那么应该在fork返回后立即调用close关闭该文件。
三、父子进程同步的功臣— wait
1. wait 的作用
在forkbase.c中,fork出子进程后,为了保证子进程先于父进程运行,在父进程中使用了sleep(2)的方式让父进程睡眠2秒。但实际上这样做,并不能100%保证子进程先于父进程运行,因为在负荷非常重的系统中,有可能在父进程睡眠2秒期间,OS并没有调度到子进程运行,并且当父进程睡醒后,首先调度到父进程运行。那么,如何才能100%保证父、子进程完全按程序员的安排来进行同步呢?答案是:系统调用wait!
需要包含的头文件:
wait函数用于使父进程阻塞,直到一个子进程结束。父进程调用wait,该父进程可能会:
- 阻塞(如果其所有子进程都还在运行)。
- 带子进程的终止状态立即返回(如果一个子进程已终止,正等待父进程存取其终止状态)。
- 出错立即返回(如果它没有任何子进程)。
2. 调用 wait 的实例
wait.c
1 #include
2 #include 3 #include 4 #include 5 #include 6 void pr_exit(intstatus); 7 int main(void) 8 { 9 pid_t pid; 10 int status; 11 if ( (pid = fork()) < 0) 12 { perror("fork");exit(-1); } 13 else if (pid == 0) { /* child */ 14 sleep(1); 15 printf("inchild\n"); 16 exit(101); 17 } 18 if (wait(&status) != pid) /* wait for child */ 19 { perror("wait");exit(-2); } 20 printf("in parent\n"); 21 pr_exit(status); /* and print itsstatus */ 22 if ( (pid = fork()) < 0) 23 { perror("fork");exit(-1); } 24 else if (pid == 0) /*child */ 25 abort(); /* generates SIGABRT */ 26 if (wait(&status) != pid) /* wait for child */ 27 { perror("wait");exit(-2); } 28 pr_exit(status); /* and printits status */ 29 if ( (pid = fork()) < 0) 30 { perror("fork");exit(-1); } 31 else if (pid == 0) /*child */ 32 status /= 0; /* divide by 0 generates SIGFPE */ 33 if (wait(&status) != pid) /* wait for child */ 34 { perror("wait");exit(-1); } 35 pr_exit(status); /* and printits status */ 36 exit(0); 37 } 38 void pr_exit(int status) { 39 if (WIFEXITED(status)) 40 printf("normallytermination, low-order 8 bit of exit status = %d\n", WEXITSTATUS(status)); 41 else if(WIFSIGNALED(status)) 42 printf("abnormallytermination, singal number = %d\n", WTERMSIG(status)); 43 } 运行结果分析:
11行创建了一个子进程,13行根据fork的返回值区分父、子进程。 我们先看父进程,父进程从18行运行,这里调用了wait函数等待子进程结束,并将子进程结束的状态保存在status中。这时,父进程就阻塞在wait这里了,这样就保证了子进程先运行。子进程从13行开始运行,然后sleep 1秒,打印出“in child”后,调用exit函数退出进程。这里exit中有个参数101,表示退出的值是101。.子进程退出后,父进程wait到了子进程的状态,并把状态保存到了status中。后面的pr_exit函数是用来对进程的退出状态进行打印。接下来,父进程又创建一个子进程,然后又一次调用wait函数等待子进程结束,父进程这时候阻塞在了wait这里。子进程开始执行,子进程里面只有一句话:abort(),abort会结束子进程并发送一个SIGABORT信号,唤醒父进程。所以父进程会接受到一个SIGABRT信号,并将子进程的退出状态保存到status中。然后调用pr_exit函数打印出子进程结束的状态。然后父进程再次创建了一个子进程,依然用wait函数等待子进程结束并获取子进程退出时的状态。子进程里面就一句status/= 0,这里用0做了除数,所以子进程会终止,并发送一个SIGFPE信号,这个信号是用来表示浮点运算异常,比如运算溢出,除数不能为0等。这时候父进程wait函数会捕捉到子进程的退出状态,然后调用pr_exit处理。 pr_exit函数将status状态传入,然后判断该状态是不是正常退出,如果是正常退出会打印出退出值;不是正常退出会打印出退出时的异常信号。这里用到了几个宏,简单解释如下:
WIFEXITED: 这个宏是用来判断子进程的返回状态是不是为正常,如果是正常退出,这个宏返回真。 WEXITSTATUS: 用来返回子进程正常退出的状态值。WIFSIGNALED: 用来判断子进程的退出状态是否是非正常退出,若非正常退出时发送信号,则该宏返回真。 WTERMSIG: 用来返回非正常退出状态的信号number。 所以这段代码的结果是分别打印出了三个子进程的退出状态和异常结束的信号编号。
四、进程控制地字第1号系统调用 — exec
当一个程序调用fork产生子进程,通常是为了让子进程去完成不同于父进程的某项任务,因此含有fork的程序,通常的编程模板如下:
if ((pid = fork()) == 0) {
dosomething in child process;
exit(0); } do something in parent process; 这样的编程模板使得父、子进程各自执行同一个二进制文件中的不同代码段,完成不同的任务。这样的编程模板在大多数情况下都能胜任,但仔细观察这种编程模板,你会发现它要求程序员在编写源代码的时候,就要预先知道子进程要完成的任务是什么。这本不是什么过分的要求,但在某些情况下,这样的前提要求却得不到满足,最典型的例子就是Linux的基础应用程序 —— shell。你想一想,在编写shell的源代码期间,程序员是不可能知道当shell运行时,用户输入的命令是ls还是cp,难道你要在shell的源代码中使用if--elseif--else if--else if ……结构,并拷贝 ls、cp等等外部命令的源代码到shell源代码中吗?退一万步讲,即使这种弱智的处理方式被接受的话,你仍然会遇到无法解决的难题。想一想,如果用户自己编写了一个源程序,并将其编译为二进制程序test,然后再在shell命令提示符下输入./test,对于采用前述弱智方法编写的shell,它将情何以堪?
看来天字1号虽然很牛,但亦难以独木擎天,必要情况下,也需要地字1号予以协作,啊,伟大的团队精神!
1. exec 的机制和用法
下面就详细介绍一下进程控制地字第1号系统调用——exec的机制和用法。
(1)exec 的机制:
在用fork函数创建子进程后,子进程往往要调用exec函数以执行另一个程序。 当子进程调用exec函数时,会将一个二进制可执行程序的全路径名作为参数传给exec,exec会用新程序代换子进程原来全部进程空间的内容,而新程序则从其main函数开始执行,这样子进程要完成的任务就变成了新程序要完成的任务了。 因为调用exec并不创建新进程,所以前后的进程ID并未改变。exec只是用另一个新程序替换了当前进程的正文、数据、堆和栈段。进程还是那个进程,但实质内容已经完全改变。呵呵,这是不是和中国A股的借壳上市有异曲同工之妙? 顺便说一下,新程序的bss段清0这个操作,以及命令行参数和环境变量的指定,也是由exec完成的。
(2)exec 的用法:
函数原型: int execle(const char * pathname,const char * arg0, ... (char *)0, char * const envp [] )
返回值: exec执行失败返回-1,成功将永不返回(想想为什么?)。哎,牛人就是有脾气,天字1号是调用1次,返回2次;地字1号,干脆就不返回了,你能奈我何?
参数: pathname:新程序的二进制文件的全路径名 arg0:新程序的第1个命令行参数argv[0],之后是新程序的第2、3、4……个命令行参数,以(char*)0表示命令行参数的结束 envp:新程序的环境变量
2. exec 的使用实例
echoall.c
1 #include
2 #include 3 #include 4 5 int main(int argc, char*argv[]) 6 { 7 int i; 8 char **ptr; 9 extern char **environ; 10 for (i = 0; i < argc; i++) /* echo all command-line args */ 11 printf("argv[%d]:%s\n", i, argv[i]); 12 for (ptr = environ; *ptr != 0;ptr++) /* and all env strings */ 13 printf("%s\n",*ptr); 21 } 将此程序进行编译,生成二进制文件命名为echoall,放在当前目录下。很容易看出,此程序运行将打印进程的所有命令行参数和环境变量。
!源文件过长,请直接查看源代码 exec.c
程序运行结果:
1 argv[0]: echoall
2 argv[1]: myarg1
3 argv[2]: MY ARG2 4 USER=unknown 5 PATH=/tmp 6 argv[0]: echoall 7 argv[1]: only 1 arg 8 ORBIT_SOCKETDIR=/tmp/orbit-dennis 9 SSH_AGENT_PID=1792 10 TERM=xterm 11 SHELL=/bin/bash 12 XDG_SESSION_COOKIE=0a13eccc45d521c3eb847f7b4bf75275-1320116445.669339 13 GTK_RC_FILES=/etc/gtk/gtkrc:/home/dennis/.gtkrc-1.2-gnome2 14 WINDOWID=62919986 15 GTK_MODULES=canberra-gtk-module 16 USER=dennis ....... 运行结果分析: 1-5行是第1个子进程14行运行新程序echoall的结果,其中:1-3行打印的是命令行参数;4、5行打印的是环境变量。 6行之后是第2个子进程23行运行新程序echoall的结果,其中:6、7行打印的是命令行参数;8行之后打印的是环境变量。之所以第2个子进程的环境变量那么多,是因为程序23行调用execlp时,没有给出环境变量参数,因此子进程就会继承父进程的全部环境变量。
多进程编程(三)
一、实验说明
1. 课程说明
本节是介绍 Linux 系统多进程编程的最后一节课程。会涉及一些 gdb 在调试多进程程序方面的技巧,以及经进程消亡相关的知识点。
2. 如果首次使用Linux,建议首先学习:
- Linux基础入门
- Vim编辑器
3. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到桌面上的程序: 1.命令行终端: Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2.Firefox及Opera:浏览器,可以用在需要前端界面的课程里,只需要打开环境里写的HTML/JS页面即可
3.gvim:非常好用的Vim编辑器,最简单的用法可以参考课程Vim编辑器
4.gedit及Brackets:如果您对gvim的使用不熟悉,可以用这两个作为代码编辑器,其中Brackets非常适用于前端代码开发
二、gdb 调试多进程程序的技巧
对多进程程序进行调试,存在一个较大的难题,那就是当程序调用fork产生子进程后,gdb跟踪的是父进程,无法进入到子进程里去单步调试子进程。这样一来,如果子进程中的代码运行出错的话,将无法进行调试。
因此想调试子进程的话,需要一点技巧:
- 在子进程的入口处加入sleep(20)函数,以使子进程在被创建后能暂时停止。
- 用ps查看子进程的pid,假定pid为222,则输入命令:gdb程序名称222。从而再运行一个调试程序,使得gdb attach到子进程。
- 用gdb的break命令在子进程中设定断点。
- 用gdb的continue,恢复子进程的运行。
- 等待sleep的睡眠时间到达,从而子进程将在断点处停下来。
三、进程的消亡
1. 启动例程与 main 函数
从程序员的角度看,C应用程序从main函数开始运行。但事实上,当C应用程序被内核通过exec启动时,一个启动例程会先于main函数运行,它会为main函数的运行准备好环境后,调用main函数。而main函数正常结束后return语句将使得main函数返回到启动例程,启动例程在完成必要的善后处理后将最终调用_exit结束进程。
有5冲方式结束进程: 正常结束: 1.从main函数返回 2.调用exit 3.调用_exit
非正常结束: 4.调用abort 5.被信号中止
2. exit 函数与 _exit 函数
需要包含的头文件:void exit(int status)、void _exit(int status)
这两个函数的功能都是使进程正常结束。 _exit:立即返回内核,它是一个系统调用exit:在返回内核钱会执行一些清理操作,这些清理操作包括调用exit handler,以及彻底关闭标准I/O流(这回使得I/O流的buffer中的数据被刷新,即被提交给内核),它是标准C库中的一个函数。
3. I/O 流和 I/O 库缓存
上一节提到I/O流以及I/O流的buffer,我们现在来了解一下。
iocache.c
1 #include
2 #include 3 4 int main(void) 5 { 6 printf("hello"); 7 //printf("hello\n"); 8 //write(1, "hello", 5); 9 sleep(100); 10 return 0; 11 } 你将会看到的是,没有任何输出!为什么呢?
当应用程序调用printf时,将字符串"hello"提交给了标准I/O库的I/O库缓存。I/O库缓存大致可以认为是printf实现中定义的全局字符数组,因此它位于用户空间,可见"hello"并没有被提交给内核(所以也不可能出现内核将"hello"打印到屏幕的操作),所以没有打印出任何东西。只有当某些条件满足时,标准I/O库才会刷新I/O库缓存,这些条件包括:
- 用户空间的I/O库缓存已被填满
- I/O库缓存遇到了换行符(‘\n’),并且输出目标是行缓冲设备(屏幕就是这种设备)。因此将上面的代码第6行注释掉,并取消第7行的注释,就可以看到打印出了hello
- I/O流被关闭,上节中的exit函数就会关闭I/O流
Tips: 当标准I/O库缓存时,会调用以前的我们学过的系统调用,例如:write,将I/O库缓存中的内容提交给内核。 so,上述代码也可以这样:第6行注释,第7行注释,第8行取消注释。也可以在屏幕上看见"hello"
4. Exit handler
Exit handler 是程序员编写的函数,进程正常结束时,它们会被系统调回。这使程序员具备了在进程正常结束时,控制进程执行某些善后操作的能力。 使用Exit handler,需要程序员完成两件事情:编写Exit handler函数;调用atexit或on_exit向系统注册Exit handler(即告知系统需要回调的Exit handler函数是谁)
需要包含头的文件:
int atexit(void (* func)(void)) int on_exit(void (* func)(int, void *),) 功能: atexit注册的函数func没有参数;on_exit注册的函数func有一个int型参数,系统调用回调func时将向该参数传入进程的退出值,func的另一个void *类型参数将会是arg。
ANSI C中,进程最多可以注册32个Exit handler函数,这些函数按照注册时的顺序被逆序调用。
#include
#include
#include static void my_exit0(int, void *); static void my_exit1(void); static void my_exit2(void); char str[9]="for test"; int main(void) { //char str[9]="for test"; if (atexit(my_exit2) != 0) { perror("can't register my_exit2"); exit(-1); } if (atexit(my_exit1) != 0) { perror("can't register my_exit1"); exit(-1); } if (on_exit(my_exit0,(void *)str) !=0) { perror("can't register my_exit0"); exit(-1); } printf("main is done\n"); printf("abc"); //_exit(1234); exit(1234); } static void my_exit0(int status, void *arg) { printf("zero exit handler\n"); printf("exit %d\n", status); printf("arg=%s\n",(char *)arg); } static void my_exit1(void) { printf("first exit handler\n"); } static void my_exit2(void) { printf("second exit handler\n"); }
实验截图:



实验中存在的问题:
主要问题是:GDB部分实验过程较为简略,没有详细实验过程很难弄清楚。