Spring知识点整理
目录
Spring是什么?
对AOP的理解
解释一下Spring AOP里面的几个名词
Spring AOP 和AspectJ AOP有什么区别?
JDK动态代理和CGLIB动态代理的区别
JavaConfig方式如何启用AOP ?如何强制使用cglib?
什么情况下AOP会失效,怎么解决?
Spring的AOP是在哪里创建的动态代理?
AOP的实现流程
对IOC的理解
IOC容器的加载过程
BeanFactory和FactoryBean有什么区别
BeanFactory和ApplicationContext有什么区别?
BeanDefinition的作用及加载过程
如何在所有的BeanDefinition注册完成后做扩展?
如何在Spring所有Bean创建完后做扩展
Spring容器启动时,为什么先加载BeanFactoryPostProcess
Bean的创建顺序是什么样的?
简述Spring Bean的生命周期
Spring的循环依赖及三级缓存
多线程创建时怎么避免获取到不完整的Bean
Spring支持的几种bean的作用域
Spring框架中的单例Bean是线程安全的么?
Spring框架中都用到了哪些设计模式?
Spring事务
事务传播行为实现原理
bean的自动装配(注入)及方式
关于@Autowired
使用@Autowired注解自动装配的过程是怎样的?
自动装配有哪些限制
配置Bean有哪几种方式
Spring实例化bean方式的几种方式
JavaConfig是如何替代xml的
@Component, @Controller, @Repository, @Service有何区别?
@Configuration作用及原理
@lmport可以有几种用法?
Spring Boot、Spring MVC和Spring的区别
SpringMVC工作流程
Spring和SpringMVC为什么需要父子容器?
SpringMVC的拦截器和过滤器有什么区别?执行顺序
Spring Boot自动配置原理?
SpringBoot内置Tomcat启动原理
Spring是如何整合Mybaits将Mapper接口注册为Bean的(了解)
如何理解Spring Boot中的Starter
为什么SpringBoot的jar包可以直接运行
SpringBoot的启动原理
SpringBoot读取配置文件的原理是什么?加载顺序是怎样的?
如何在SpringBoot的基础上做扩展
什么是嵌入式服务器?为什么要使用嵌入式服务器?
Spring是什么?
轻量级的开源的J2EE框架。它是一个容器框架,用来装javabean (java对象) ,中间层框架(万能胶)可以起一个连接作用,比如说把Struts和hibernate粘合在一 起运用, 可以让我们的企业开发更快、更简洁
Spring是一个轻量级的控制反转(IoC)和面向切面(AOP) 的容器框架
- 从大小与开销两方面而言Spring都是轻量级的。
- 通过控制反转(l0C)的技术达到松耦合的目的
- 提供了面向切面编程的丰富支持,允许通过分离应用的业务逻辑与系统级服务进行内聚性的开发
- 包含并管理应用对象(Bean)的配置和生命周期,这个意义上是一个容器。
- 将简单的组件配置、组合成为复杂的应用,这个意义上是-个框架。
对AOP的理解
系统是由许多不同的组件所组成的,每一个组件各负责一 块特定功能。 除了实现自身核心功能之外,这些组件还经常承担着额外的职责。例如日志、事务管理和安全这样的核心服务经常融入到自身具有核心业务逻辑的组件中去。这些系统服务经常被称为横切关注点,因为它们会跨越系统的多个组件。当我们需要为分散的对象引入公共行为的时候,OOP(面向对象)则显得无能为力。也就是说,OOP允许你定义从上到下的关系,但并不适合定义从左到右的关系。例如日志功能。日志代码往往水平地散布在所有对象层次中,而与它所散布到的对象的核心功能毫无关系。在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。AOP:将程序中的交叉业务逻辑(比如安全,日志,事务等),封装成一个切面,然后注入到目标对象(具体业务逻辑)中去。AOP可以对某个对象或某些对象的功能进行增强,比如对象中的方法进行增强,可以在执行某个方法之前额外的做一些事情, 在某个方法执行之后额外的做一些事情
解释一下Spring AOP里面的几个名词
- 切面(Aspect) :在Spring Aop指定就是"切面类”,切面类会管理着切点通知。
- 连接点(Join point) :指定就是被 增强的业务方法
- 通知(Advice) :就是需要增加到业务方法中的公共代码, 通知有 很多种类型分别可以在需要增加的业务方法不同位置进行执行(前置通知、
- 后置通知、异常通知、返回通知、环绕通知)
- 切点(Pointcut) :由他决定哪些方法需要增强、 哪些不需要增强,结合 切点表达式进行实现
- 目标对象(Target Object) :指定是增强的对象
- 织入(Weaving) : spring aop用的织入方式:动态代理。就是为 目标对象创建动态代理的过程就叫织入。
Spring切面可以应用5种类型的通知:
1.前置通知(Before) :在目标方法被调用之前调用通知功能;
2.后置通知(After) :在目标方法完成之后调用通知,此时不会关心方法的输出是什么;
3.返回通知(After-returning ) :在目标方法成功执行之后调用通知;
4.异常通知(After-throwing) :在目标方法抛出异常后调用通知;|
5.环绕通知(Around) :通知包裹了被通知的方法,在被通知的方法调用之前和调用之后执行自定义的行为。
Spring AOP 和AspectJ AOP有什么区别?
关系:
当在Spring中要使用@Aspect. @Before等这些注解的时候, 就需要添加AspectJ相关依赖
org. aspectj
aspectjweaver
1.9.5
Spring Aop提供了AspectJ的支持,但只用到的AspectJ的切点解析和匹配。@Aspect. @Before 等这些注解都是由AspectJ发明的
AOP实现的关键在于代理模式,AOP代理主要分为静态代理和动态代理。静态代理的代表为AspectJ; 动态代理则以Spring AOP为代表。
区别:
(1) Spring AOP使用的动态代理,它基于动态代理来实现。默认地,如果使用接口的,用JDK提供的动态代理实现,如果没有接口,使用CGLIB实现。
(2) AspectJ是静态代理的增强, 所谓静态代理,就是AOP框架会在编译阶段生成AOP代理类,因此也称为编译时增强,他会在编译阶段将AspectJ(切面)织入到Java字节码中,运行的时候就是增强之后的AOP对象。
- 属于静态织入,它是通过修改代码来实现的
- AspectJ能干很多Spring AOP干不了的事情,它是AOP编程的完全解决方案。Spring AOP致力于解决的是企业级开发中最普遍的AOP需求(方法织入),而不是力求成为一个像AspectJ -样的AOP编程完全解决方案。
- 因为AspectJ在实际代码运行前完成了织入,所以大家会说它生成的类是没有额外运行时开销的。
- 很多人会对比 Spring AOP和AspectJ的性能,Spring AOP是基于代理实现的,在容器启动的时候需要生成代理实例,在方法调用上也会增加
栈的深度,使得Spring AOP的性能不如AspectJ那么好。
JDK动态代理和CGLIB动态代理的区别
Spring AOP中的动态代理机制主要有两种方式,JDK动态代理和CGLIB动态代理:
JDK动态代理只提供接口的代理,不支持类的代理。
- JDK会在运行时为目标类生成一 个动态代理类$proxy* .class
- 该代理类是实现了接目标类接口,并且代理类会实现接口所有的方法增强代码。
- 调用时先去调用处理类进行增强,再通过反射的方式进行调用目标方法。从而实现AOP
如果代理类没有实现接口,那么Spring AOP会选择使用CGLIB来动态代理目标类。
- CGLIB的底层是通过ASM(字节码生成库)在运行时动态的生成目标类的一个子类(还有其他相关类主要是为增强调用时效率) 会生成多个
- 并且会重写父类所有 的方法增强代码,
- 调用时先通过代理类进行增强, 再直接调用父类对应的方法进行调用目标方法。从而实现AOP。
- CGLIB是通过继承的方式做的动态代理,因此如果某个类被标记为final,那么它是无法使用CGLIB做动态代理的。
- CGLIB除了生成目标子类代理类,还有一个FastClass(路由类), 可以(但不是必须)让本类方法调用进行增强,而不会像jk代理那样本类方法调用增强会失效
JavaConfig方式如何启用AOP ?如何强制使用cglib?
@EnableAspectJAutoProxy
//(proxyTargetClass = true) //强制GLIB
//(exposeProxy m true) 在线程中暴露代理对象@EnableAspectJAutoroxyAOP几种实现方式
●Spring 1.2 基于接口的配置:最早的Spring AOP是完全基于几个接口的
●Spring 2.0 schema-based配置: Spring 2.0以后使用XML的方式配置使用命名空间
●Spring 2.0 @AspectJ配置:使用注解的方式来配置,这种方式感觉是最方便的,还有,这里虽然叫做@AspectJ,但是这个和AspectJ其实没啥关系。
●AspectJ 方式,这种方式其实和Spring没有关系,采用AspectJ 进行动态织入的方式实现AOP,需要用AspectJ单独编译。
什么情况下AOP会失效,怎么解决?
失效原因:内部调用不会触发AOP.
1.方法是private也会失效,解决:改成public
2.目标类没有配置为Bean也会失效,解决: 配置为Bean
3.切点表达式没有配置正确
内部调用解决方式:必须走代理,重新拿到代理对象再次执行方法才能进行增强
1.在本类中自动注入当前的bean(@Autowire)
2.设置暴露当前代理对象到本地线程,可以通过AopContext currentProxy()拿到当前正在调用的动态代理对象
@EnableAspectJAutoProxy(exposeProxy = true )
Spring的AOP是在哪里创建的动态代理?
1.正常的Bean会在Bean的生命周期的初始化后,通过BeanPostProcessorpostProcssteritialization创建 aop的动态代理
2.还有一种特殊情况:循环依赖的Bean会在Bean的生命周期 属性注入时,也会为循环依赖的Bean通过MergedBeanDefnitionPostProcessor. postProcessMergedBeanDefinition创建aop
AOP的实现流程
AOP的实现大致分为三大步: 以JavaConfig来说
当有@EnableAspectJAutoProxy注解会通过@Import注册一个BeanPostProcessor处理AOP
1.解析切面:在Bean创建之前的第一个Bean后置处理器会去解析切面(解析切面中通知、切点,一个通知就会解析成一个advisor通知、切点)
2.创建动态代理正常的Bean初始化后调用BeanPostProcessor拿到之前缓存的advisor,再通过advisor中pointcut 判断当前Bean是否被切点表达式匹配,如果匹配,就会为Bean创建动态代理(创建方式1 jdk动态代理2 cglib)。
3.调用:拿到动态代理对象,调用方法就会判断当前方法是否增强的方法,如果是就会通过调用链的方式依次去执行通知.
对IOC的理解
容器概念、控制反转、依赖注入
ioc容器概念:实际上就是个map (key, value) ,里面存的是各种对象(在xml里配置的bean节点、@repository、@service、@controller. @component) ,在项目启动的时候会读取配置文件里面的bean节点,根据全限定类名使用反射创建对象放到map里、扫描到加了上述注解的类还是通过反射创建对象放到map里。
这个时候map里就有各种对象了,接下来我们在代码里需要用到里面的对象时,再通过Dl注入(autowired、resource等注解,xml里bean节点内的ref属性,项目启动的时候会读取xm|节点ref属性根据id注入,也会扫描这些注解,根据类型或id注入; id就是对象名) 。
控制反转:
没有引入I0C容器之前,对象A依赖于对象B,那么对象A在初始化或者运行到某一点的时候, 自己必须主动去创建对象B或者使用已经创建的对象B。无论是创建还是使用对象B,控制权都在自己手上。
引入IOC容器之后,对象A与对象B之间失去了直接联系,当对象A运行到需要对象B的时候,I0C容器会 主动创建一个对象B注入到对象A需要的地方。
通过前后的对比,不难看出来:对象A获得依赖对象B的过程,由主动行为变为了被动行为,控制权颠倒过来了,这就是“控制反转这个名称的由来。
依赖注入:
“获得依赖对象的过程被反转了"。控制被反转之后,获得依赖对象的过程由自身管理变为了由IOC容器主动注入。依赖注入是实现IOC的方法,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中。
IOC容器的加载过程
在创建一个Spring容器/Spring上下文的时候就开始了IOC
- 实例化一个ApplicationContext的对象;
- 调用bean工厂后置处理器完成扫描;
- 循环解析扫描出来的类信息;
- 实例化-个BeanDefinition对象来存储解析出来的信息;
- 把实例化好的beanDefnition对象put到beanDfintionMap当中缓存起来,以便后面实例化bean;
- 再次调用其他bean工厂后置处理器
- 当然spring还会干很多事情, 比如国际化,比如注册BeanPostProcessor等等,如果我们只关心如何实例化-个bean的话那么这一 步就是spring调用finishBeanacriylntialization方法来实例化单例的bean,实例化之前spring要做验证,需要遍历所有扫3描出来的类,依次判断这个bean是否Lazy. 是否prototype, 是否abstract等等;
- 如果验证完成spring在实例化-个bean之前需要推断构造方法, 因为spring实例化对象是通过构造方法反射,故而需要知道用哪个构造方法;
- 推断完构造方法之后spring调用构造方法反射实例化一个对象; 注意我这里说的是对象、对象、对象;这个时候对象已经实例化出来了,但是并不是一个完整的bean,最简单的体现是这个时候实例化出来的对象属性是没有注入,所以不是一个完整的bean;
- spring处理 合并后的beanDefinition
- 判断是否需要完成属性注入
- 如果需要完成属性注入,则开始注入属性
BeanFactory和FactoryBean有什么区别
BeanFactory是一个工厂 ,也就是一个容器, 是来管理和生产bean的;
FactoryBean是一个bean, 所以也是由BeanFactory来管理的,只不过FactoryBean不是一个普通的Bean,是一个接口必须被一个Bean去实现。
它会表现出工厂模式的样子,是一个能产生或者修饰对象生成的工厂"Bean,里面的getObject()就是用来获取FactoryBean产生的对象,可以是任何一个对象。所以在BeanFactory中使用"&"来得到FactoryBean本身
//通过&依然可以获得原实例
UserMapper userMapper = (UserMapper) context . getBean( name: "&userMapper");BeanFactory和ApplicationContext有什么区别?
ApplicationContext是BeanFactory的子接口
ApplicationContex提供了更完整的功能(继承后完成了一些扩展多出的功能如下):
①继承MessageSource,因此支持国际化。
⑦統-的资源文件访问方式(比如Resource接口就是统一的文件访问)。
③提供在监听器中注册bean的事件。
④同时加载多个配置文件。
⑤载入多个(有继承关系)上下文,使得每一个上下文都专注于-个特定的层次, 比如应用的web层。
●BeanFactroy采用的是延迟加载形式来注入Bean的,即只有在使用到某个Bean时(调用getBean()), 才对该Bean进行加载实例化。这样,我们就不能发现-一些存在的Spring的配置问题。 如果Bean的某一 个属性没有注入,BeanFacotry加载后,直至第一次使用调用getBean方法才 会抛出异常。
●ApplicationContext, 它是在容器启动时,-次性创建了所有的Bean。这样,在容器启动时,我们就可以发现Spring中存在的配置错误,这样有利于检查所依赖属性是否注入。ApplicationContext启动后预载 入所有的单实例Bean,通过预载入单实例bean ,确保当你需要的时候,你就不用等待,因为它们已经创建好了。本身不生成Bean而是通知FactoryBean来进行生产。
●相对于基本的BeanFactory, ApplicationContext唯-的不足是占用内存空间。当应用程序配置Bean较多时,程序启动较慢。
●BeanFactory通 常以编程的方式被创建,ApplicationContext还能以声明的方式创建, 如使用ContextLoader.
●BeanFactory和ApplicationContext都支持BeanPostProcessor. BeanFactoryPostProcessor的使用, 但两者之间的区别是: BeanFactory需要 手动注册,而ApplicationContext则是自动注册。
BeanDefinition的作用及加载过程
它主要负责存储Bean的定义信息:决定Bean的生产方式。
如: spring.xml
后续BeanFactory根据这些信息就行生产Bean:比如实例化 可以通过class进行反射进而得到实例对象,比如lazy 则不会在ioc加载时创建Bean

如何在所有的BeanDefinition注册完成后做扩展?
利用BeanFactoryPostProcessor(Bean工厂后置处理器)BeanFactoryPostProcessor可以获取到所有的BeanDefinition,获取之后就可以做扩展了对已注册的BeanDeintion进行修改、或者通过它的子接口BeanDefinitionRegistryPostProcessor再进行注册
如何在Spring所有Bean创建完后做扩展
哪里才算所有的Bean创建完: new AplicactioContext()-->refresh()-->finishBeanFactorynitilizationn (循环所有的BeanDefinition,通过BeanFactory getBean()生成所有的Bean) 这个循环结束之后所有的bean也就创建完了
方式一基于SmathitializingSingleton接口
在创建所有单例Bean的方法中:finishBeanFactoryInitialization( beanFactory);
SmartlnitializingSingleton接口是在所有的Bean实例化完成以后, Spring回调的方法,所以这
里也是一个扩展点,可以在单例bean全部完成实例化以后做处理。
方式二:通过发布的ContextRefreshedEvent事件
Spring容器启动时,为什么先加载BeanFactoryPostProcess
1.因为BeanDefnition会在ioc容器加载的先注册,而BeanFactoryPostProcess就是在所有的BeanDefinition注册完后做 展的,所以要先加载BeanFactoryPostProcess
2.因为要解析配置类,用到解析配置类的组件,而配置类组件实现了BeanFactoryPostProcess, 所以要先去加载BeanFactoryPostProcess
Bean的创建顺序是什么样的?
Bean的创建顺序是由BeanDeinition的注册顺序来决定的,当然依赖关系也会影响Bean创建顺序(A-B)。
BeanDefinition的注册顺序由什么来决定的?
主要是由注解(配置)的解析顺序来决定:@Order也可以决定顺序
1. @Configuration
2. @Component
3. @lmport----导入一个类.
4. @Bean
5. @lmport--- ImportBeanDefinitionRegistrar
简述Spring Bean的生命周期
UserService类--->无参的构造方法--->生成对象--->依赖注入--->初始化前(@PostConstruct等)--->初始化(InitializingBean)--->初始化后(AOP)--->得到代理对象--->放入Map单例池--->Bean对象

1、解析类得到BeanDefinition
2、如果有多个构造方法,则要推断构造方法
3、确定好构造方法后,进行实例化得到一个对象
4、对加了@Autowired注解的对象属性进行属性填充完成依赖注入(自动装配阶段。循环依赖也是在这产生的)
5、回调Aware方法,比如BeanNameAware, BeanFactoryAware
6、调用BeanPostProcessor的初始化前的方法
7、调用初始化方法
8、调用BeanPostProcessor的初始化后的方法,在这里会进行AOP 动态代理的创建
9、如果当前创建的bean是单例的则会把bean放入单例池
10、使用bean
11、Spring容器关闭时调用DisposableBean中destory0方法
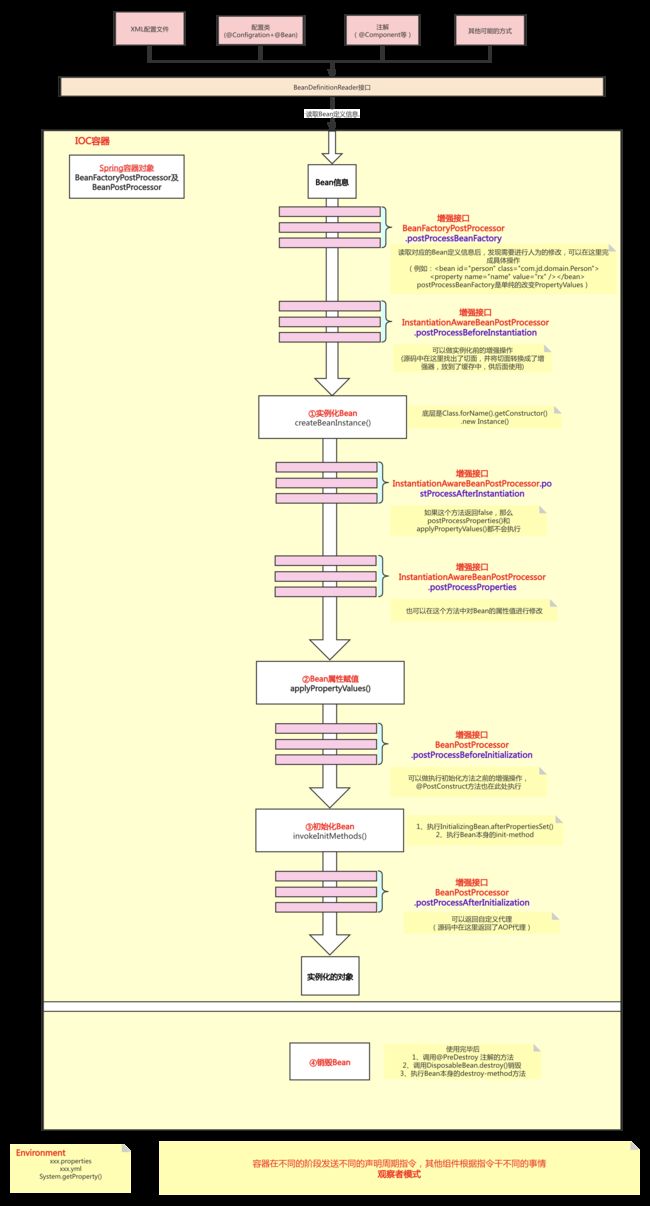
图自:https://blog.csdn.net/weixin_43244698/article/details/109338537
加到构造方法上,构造方法注入时,根据@Autowired 注解获取对象时是先根据type再根据名字获取,如果只根据名字的话名字随便起,所以有可能获取出问题,所以先根据type找,如果只根据 type找的话,spring容器中可能会有多个相同类型的Bean
加在属性上时也是先根据type再根据name
Spring的循环依赖及三级缓存
多个Bean之间相互依赖,形成一个闭环
两种注入方式对循环依赖的影响
- 构造器注入:容易造成无法解决的循环依赖,不推荐使用(If you use predominantly constructor injection, it is possible to create an unresolvable circular dependency scenario.)
- Setter 注入:推荐使用 setter 方式注入单例 bean
- 结论:我们 AB 循环依赖问题只要 A 的注入方式是 setter 且 singleton,就不会有循环依赖问题
只有单例的bean会通过三级缓存提前暴露来解决循环依赖的问题,因为单例的时候只有一份,随时复用,那么就放到缓存里面 ,所以一定要有一个缓存保存它的早期对象作为死循环的出口。而多例的bean,每次从容器中荻取都是—个新的对象,都会重新创建,所以非单例的bean是没有缓存的,不会将其放到三级缓存中。
第一级缓存:Map
第二级缓存:Map
第三级缓存:Map
- 缓存是函数接口:通过lamda把方法传进去( 把Bean的实例和Bean名字传进去(aop创建) )
- 不会立即调: (如果在实例化后立 即调用的话:所有的aop不管bean是否循环依赖都会在实例化后创建proxy代理对象,对于正常Bean其实spring还是希望遵循生命周期在初始化创建动态代理,只能循环依赖才创建)
- 会在ABA (第二次getBean(A)才会去调用三级缓存(如果实现了aop才会创建动态代理,如果没有实现依然返回的Bean的实例) )
- 放入二级缓存(避免車复创建)
四大方法
- getSingleton():从容器里面获得单例的bean,没有的话则会创建 bean
- doCreateBean():执行创建 bean 的操作(在 Spring 中以 do 开头的方法都是干实事的方法)
- populateBean():创建完 bean 之后,对 bean 的属性进行填充
- addSingleton():bean 初始化完成之后,添加到单例容器池中,下次执行 getSingleton() 方法时就能获取到
注:关于三级缓存 Map
循环依赖的执行步骤
- 调用doGetBean()方法,想要获取beanA,于是调用getSingleton()方法从缓存中查找beanA
- 在getSingleton()方法中,从一级缓存中查找,没有,返回null
- doGetBean()方法中获取到的beanA为null,于是走对应的处理逻辑,调用getSingleton()的重载方法(参数为ObjectFactory的)
- 在getSingleton()方法中,先将beanA_name添加到一个集合中,用于标记该bean正在创建中。然后回调匿名内部类的creatBean()方法
- 进入AbstractAutowireCapableBeanFactory#doCreateBean(),先反射调用构造器创建出beanA的实例,然后判断。是否为单例、是否允许提前暴露引用(对于单例一般为true)、是否正在创建中〈即是否在第四步的集合中)。判断为true则将beanA添加到【三级缓存】中
- 对beanA进行属性填充,此时检测到beanA依赖于beanB,于是开始查找beanB
- 调用doGetBean()方法,和上面beanA的过程一样,到缓存中查找beanB,没有则创建,然后给beanB填充属性
- 此时beanB依赖于beanA,调用getsingleton()获取beanA,依次从一级、二级、三级缓存中找,此时从三级缓存中获取到beanA的创建工厂,通过创建工厂获取到singletonObject,此时这个singletonObject指向的就是上面在doCreateBean()方法中实例化的beanA
- 这样beanB就获取到了beanA的依赖,于是beanB顺利完成实例化,并将beanA从三级缓存移动到二级缓存中
- 随后beanA继续他的属性填充工作,此时也获取到了beanB,beanA也随之完成了创建,回到getsingleton()方法中继续向下执行,将beanA从二级缓存移动到一级缓存中

总结
| Spring创建bean主要分为两个步骤,创建原始bean对象,接着去填充对象属性和初始化 |
| 每次创建bean之前,我们都会从缓存中查下有没有该bean,因为是单例,只能有一个 |
| 当我们创建 beanA的原始对象后,并把它放到三级缓存中,接下来就该填充对象属性了,这时候发现依赖了beanB,接着就又去创建beanB,同样的流程,创建完 beanB填充属性时又发现它依赖了beanA又是同样的流程。 不同的是:这时候可以在三级缓存中查到刚放进去的原始对象beanA,所以不需要继续创建,用它注入beanB,完成beanB的创建 |
| 既然 beanB创建好了,所以beanA就可以完成填充属性的步骤了,接着执行剩下的逻辑,闭环完成 |
AB两对象在三级缓在中的迁移
1、A创建过程中需要B.于是A将自己放到三级缓存里面,去实例化B
2、B实例化的时候发现需要A.于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A。然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A
3、B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态)然后回来接着创建A.此时B已经创建结束,直接从一级缓存里面拿到B。然后完成创建,并将A自己放到一级缓存里面。延展问题:
1.二级缓存能不能解决循环依赖?
a.如果只是死循环的问题: 一 级缓存就可以解决但无法避免在并发下获取不完整的Bean
b.二级缓存也可以解决循环依赖:只不过如果出现重复循环依赖 会多次创建aop的动态代理
2. Spring有没有解决多例Bean的循坏依赖?
a.多例不会使用缓存进行存储(多例Bean每次使用都需要重新创建)
b.不缓存早期对象就无法解决循环
3. Spring有没有解决构造函数参数Bean的循环依赖?
a.构造函数的循环依赖也是会报错
b.默认不可以,但可以通过@Lazy注解
i.就不会立即创建依赖的bean了
ii.而是等到用到才通过动态代理进行创建
 多线程创建时怎么避免获取到不完整的Bean
多线程创建时怎么避免获取到不完整的Bean
不完整的Bean:只完成了实例化没有进行属性赋值和初始化的Bean。
产生原因:多个线程同时访问getBean(a)获取BeanA,第一个线程先到达并且A不存在一级缓存,开始进行创建,经过实例化时将不完整的Bean放到三级缓存,此时线程2过来访问,会在三级缓存获取到,这样就获取到了不完整的A。
Spring一级解决了这个问题——双重检查锁:

问题来了:为什么一级缓存没有加到锁中?为了避免已经创建好的Bean阻塞而等待产生性能问题
Spring支持的几种bean的作用域
●singleton: 默认,每个容器中只有一个bean的实例(并不是在应用中只有一个实例,自己去new的话肯定还会有别的实例), 单例的模式由BeanFactory自身来维护。 该对象的生命周期是与Spring I0C容器一致的(但在第一次被注入时才会创建)。单例Bean的好处:
- 减少了新生成实例的消耗新生成实例消耗包括两方面,第一, spring会通过反射或者cglib来生成bean实例这都是耗性能的操作,其次给对象分配内存也会涉及复杂算法。提高了服务器内存的利用率。
- 减少jvm垃圾回收由于不会给每个请求都新生成bean实例,所以自然回收的对象少了。
- 可以快速获取到bean因为单例的获取bean操作除了第一-次生成之 外其余的都是从缓存里获取的所以很快。
●prototype: 为每一个bean请求提供一 个实例(每一次getBean都会创建一个实例)。在每次注入时都会创建一个新的对象
●request: bean被定义为在每个HTTP请求中创建一个单例对象, 也就是说在单个请求中都会复用这一个单例对象。请求结束,实例被回收
. ●session: 与request范围类似,确保每个session中有-个bean的实例,在session过期后, bean会随之失效。
●application: bean被定义为在ServletContext的生命周期中复用一个单例对象。
●websocket: bean被定义为在websocket的生命周期中复用一个单例对象。
global-session(了解):全局作用域,global-session和Portlet应用相关。 当你的应用部署在Portlet容器中工作时, 它包含很多portlet。如果你想要声明让所有的portlet共用全局的存储变量的话,那么这全局变量需要存储在 global-session中。全局作用域与Servlet中的session作用域效果相同。
Spring框架中的单例Bean是线程安全的么?
线程不安全的三要素:多线程环境、访问同一个资源、资源具有状态性
Spring中的Bean默认是单例模式的,框架并没有对bean进行多线程的封装处理。
如果Bean是有状态的(比如存储了数据,有值如count= 10)那就需要开发人员自己来进行线程安全的保证,最简单的办法就是改变bean的作用域把 "singleton"改为"protopyte'(将Bean声明成多利@Bean @Scope("prototype"))这样每次请求Bean就相当于是new Bean(这样就可以保证线程的安全了。
- 有状态就是有数据存储功能
- 无状态就是不会保存数据 controller. service和dao层本身并不是线程安全的, 只是如果只是调用里面的方法,而且多线程调用一个实例的方法, 会在内存中复制变量,这是自己的线程的工作内存,是安全的。
Dao会操作数据库Connection, Connection是带有状态的, 比如说数据库事务,Spring的事务 管理器使用 Threadlocal为不同线程维护了-套独立的connection副本, 保证线程之间不会互相影响(Spring 是如何保证事务 获取同一个Connection的)
不要在bean中声明任何有状态的实例变量或类变量,如果必须如此,可以把变量声明在方法中。或者使用ThreadLocal把变量变为线程私有的。如果bean的实例变量或类变量需要在多个线程之间共享,那么就只能使用同步锁synchronized. lock. CAS等这些实现线程同步的方法了。
Spring框架中都用到了哪些设计模式?
简单工厂:由一个工厂类根据传入的参数,动态决定应该创建哪一个产品类。Spring中的BeanFactory就是简单工厂”模式的体现,根据传入一个唯一的标识来获得Bean对象(getBean), 但是否是在传入参数后创建还是传入参数前创建这个要根据具体情况来定。
工厂方法:实现了FactoryBean接口的bean是一类叫做factory的bean. 其特点是,spring会 在使用getBeanO)调用获得该bean时,会自动调用该bean的getobject()方法,所以返回的不是factory这个bean,而是这个bean. getojbect()方法的返回值(如A实现了getobject的方法并在getobject方法中返回B那么spring调getBean拿到的是B对象而不是A)。
单例模式:保证一个类仅有一个实例, 并提供一个访问它的全局访问点spring对单例的实现: spring中的单例模式完成 了后半句话,即提供了全局的访问点BeanFactory.但没有从构造器级别去控制单例,这是因为spring管理的是任意的java对象。
适配器模式: spring定义了一个适配接口,使得每一种Controller有 - 种对应的适配器实现类,让适配器代替contro1ler执行相应的方法。这样在扩展Controller时,只需要增加一个适配器类就完成了springMVC的扩展了。
装饰器模式:动态地给一个对象添加一 些额外的职责。 就增加功能来说,Decorator模式相比生成子类更为灵活。Spring中用到的包装器模式在类名上有两种表现: - 种是类名中含有Wrapper,另-种是类名中含有Decorator。
动态代理: 切面在应用运行的时刻被织入。一般情况下, 在织入切面时,AOP 容器会为目标对象创建动态的创建- 个代理对象。SpringAOP就是以这种方式织入切面的。织入:把切面应用到目标对象并创建新的代理对象的过程。
观察者模式: spring的事件驱动模型使用的是观察者模式,Springtobserver 模式常用的地方listener的实现。
策略模式: spring框架的资源访问Resource接口。该接口提供了更强的资源访问能力,Spring 框架本身大量使用了Resource接口来访问底层资源。
模板方法模式:几乎所有外接扩展都用这种模式
Spring事务
事务的实现方式在使用Spring框架时,可以有两种使用事务的方式,一种是编程式的(在程序中手动代码实现begin,commit等),一种是申明式的,@Transactional注解就是申明式的。
首先,事务这个概念是数据库层面的,Spring只是基于数据库中的事务进行了扩展,以及提供了一些能让程序员更加方便操作事务的方式。 比如我们可以通过在某个方法上增加@Transactional注解,就可以开启事务,这个方法中所有的sq都会在一个事务中执行,统一成功或失败。在-一个方法上加了@Transactional注解后,Spring会基于这个类生成一 个代理对象, 会将这个代理对象作为 bean,当在使用这个代理对象的方法时,如果这个方法上存在@Transactional注解,那么代理逻辑会先把事务的自动提交设置为false,然后再去执行原本的业务逻辑方法,如果执行业务逻辑方法没有出现异常,那么代理逻辑中就会将事务进行提交,如果执行业务逻辑方法出现了异常,那么则会将事务进行回滚。
当然,针对哪些异常回滚事务是可以配置的,可以利用@Transactional注解中的rollbackFor属性进行配置, 默认情况下会对RuntimeException和Error进行回滚。
原子性、一致性、隔离性、持久性是事务的四大特性
多线程时是不保证事务的一致性的,因为Spring的事务信息是存在ThreadLocal中的Connection,所以一个线程永远只能有一个事务可以通过编程式事务,或者通过分布式事务的思路:二阶段提交方式
spring事务隔离级别就是数据库的隔离级别:外加一个默认级别
●read uncommitted (未提交读) 可能出现的问题脏读、幻读、不可重复读
●read committed (提交读、不可重复读) 幻读、不可重复读
●repeatable read (可重复读) 需要锁行 幻读
●serializable (可串行化) 需要锁表 都不会出现
数据库的配置隔离级别是Read Commited,而Spring配置的隔离级别是Repeatable Read, 请问这时隔离级别是以哪一个为准?
以Spring配置的为准,如果spring设置的隔离级别数据库不支持,效果取决于数据库
事务的传播
多个事务方法相互调用时,事务如何在这些方法间传播 方法A是一个事务的方法,方法A执行过程中调用了方法B,那么方法B有无事务以及方法B对事务的要求不同都会对方法A的 事务具体执行造成影响,同时方法A的事务对方法B的事务执行也有影响,这种影响具体是什么就由两个方法所定义的事务 传播类型所决定。 @Transactional的参数
REQUIRED(Spring默认的事务传播类型):如果当前没有事务,则自己新建一个事务,如果当前存在事务,则加入这个事务 SUPPORTS:当前存在事务,则加入当前事务,如果当前没有事务,就以非事务方法执行 MANDATORY:当前存在事务,则加入当前事务,如果当前事务不存在,则抛出异常。 REQUIRES_ NEW:创建一个新事务,如果存在当前事务,则挂起该事务(互不影响)。 NOT_ SUPPORTED:以非事务方式执行,如果当前存在事务,则挂起当前事务 NEVER:不使用事务,如果当前事务存在,则抛出异常 NESTED:如果当前事务存在,则在嵌套事务中执行,否则REQUIRED的操作-样(开启-个事务)

事务传播行为实现原理
融入外部事务
try{
3.内嵌:判断ThreadLocal是否已经有Connection.有的话说明是内嵌事务,判断当前事务的传播行为
融入:不会创建Connection,返回事务状态信息(TransactionInfo. newTransaction=false)
1.外部:创建一个数据库连接Connection存入ThreadLocal,并且修改数据库连接的autoCommit属性为false,返 回事务状态信息(TransactionInfo. newTransact=true)
2.外部:然后执行目标方法(调用了内部事务方法)方法中会执行数据库操作sq1
4.内嵌:然后执行目标方法,方法中会执行数据库操作sq1
}
catch{
如果出现了异常,并且这个异常是需要回滚的就会回滚事务,否则仍然提交事务
}
5.内嵌:判图newTransaction==true就提交事务
6.外部:判断newTransaction==true 拿到ThreadLocal 中的Connection进行提交创建新事务
try{
3.内嵌:判断ThreadLocal是否已经有Connection,有就说明是一个内嵌事务,判断当前事务的传播行为
创建新事务:会把外层事务相关的事务信总(Connection. 隔高级别、是否只读....暂存同时会把外层事务的ThreadLoca1存储的事务信总都置空)
创建Connection放入ThreadLocal,返回事务状态信 息 (TransactionInfo.newTransaction=ture,TransactionInfo.外部事务的信息管存)
1外部.创建一个数据库连接Connection存入ThreadLocal,并修改数据库连接的autoCommit属性为false.返回 事务状态信息(TransactionInfo. newTransact=true 一个新事务)
2外部.然后执行目标方法(调用了内部事务方法)方法中会执行数据库操作sql
4.内嵌:然后执行目标方法,方法中会执行数据库操作sql
catch{
如果出现了异常,并且这个异常是需要回滚的就会回浪事务,否则仍然提交事务
}
5内嵌:判断newTransaction==true就提交事务,判断是否暂存事务,把暂存事信息回归ThreadLocal
6.外部:判新newTransaction-=true.拿到ThreadLocal中 的Connection进行提交 Spring事务什么时候会失效
spring事务的原理是AOP,进行了切面增强,那么失效的根本原因是这个AOP不起作用了!常见情况有如下几种
1.发生自调用,类里面使用this调用本类的方法(this通常省略),此时这个this对象不是代理类,而是UserService对象本身。解决方法很简单,让那个this变成UserService的代理类即可(用@Autoware注入的那个对象调用,自己注入自己)如图2中虽然a方法上加了注解但是无效的,而test是userService的代理对象在执行test方法,只有是userService的代理对象执行a方法@Transactional注解才有效
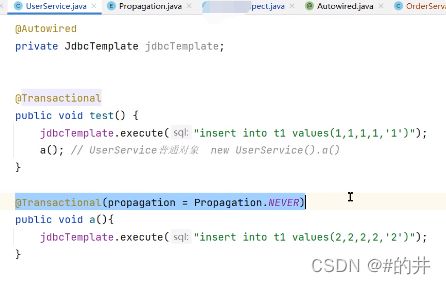
2、方法不是public的@Transactional只能用于public的方法上,否则事务不会失效,如果要用在非public方法上,可以开启AspectJ代理模式。
3、数据库不支持事务
4、没有被spring管理 (类不属于IOC容器中如:没有加@Service注解)
5、异常被吃掉,事务不会回滚(或者抛出的异常没有被定义,默认为RuntimeException)
bean的自动装配(注入)及方式
开启自动装配,只需要在xml配置文件
●byType-根据bean的类型进行自动装配。
Cutomer的属性名称是person,spring会将person类型通过setter方法进行自动装配
●constructor-.类似byType, 不过是应用于构造器的参数。如果一个bean与构造器参的类型相同,则进行自动装配,否则导致异常。
Cutomer构造函数的多数person的类型为Person, spring会将Person类型通过构造方法进行自动装配。
●autodetect-如果有默认的构造器, 则通过constructor方式进行自动装配, 否则使用byType方式进行自动装配。3.0之后已经弃用
如果有默认的构造器,则通过constructor 方式进行自动装配,否则使用byType方式进行自动装配。
关于@Autowired
@Autowired自动装配bean,可以在字段、setter方法、 构造函数上使用。
自动注入Bean时加@Autowired(required=false)参数即使没有找到依赖Bean时也不会报错
多个实现类同时实现相同接口时,@Service找到多个,会报错,实现类上除了@Service再加@Primary(表示这是主要的bean)即可
@Autowired与@Resource之间的区别:
| @Autowired | @Resource |
| 属于Spring | 属于JDK |
| 先根据类型到容器中匹配,没匹配到再根据名字 |
先根据名字到容器中匹配,没匹配到再根据类型 |
使用@Autowired注解自动装配的过程是怎样的?
@Autowired 通过Bean的后道处理器进行解析的
- 在创建一个Spring 上下文的时候冉构造粗数中进行注册AutowiredAnnotationBeanPostProcessor
- 在Bean的创建过程中进行解析
a. 在属性注入真正的解析(拿到上- 步缓存的元數据去ioc容器帮进行查找,并且返回注入)
b.在实例化后预解析(解析@Autovwired标主的属性、方法比如: 把属性的类型、名称属性所在的类...元數据缓存起)
首先恨据预解析的元数据拿到尖型去容器中进行查找
- 如果查询结果刚好为一个。就将该bean装配给@Aulowired指定的数据:.
- 如果查询的结果不止一个, 那么@Autowirod会根据名称来查找;
- 如果上述查找的结果为空。那么会抛出异常。解决方法时,使用required=false。
自动装配有哪些限制
一定要声明set方法
覆盖:你仍可以用< constructor-arg >和< property>配置来定义依赖,这些配将始终覆盖自动注入。
基本数据类型:不能自动装配简单的属性,如基本数据类型、字符串和类。手动可以注入基本数据类型@Value等
模糊特性:自动装配不如显式装配精确。如果有可能尽使用显示装配。
所以更推荐手动装配@Autowired 等,比较灵活和清晰。
配置Bean有哪几种方式
- xml:
Spring实例化bean方式的几种方式 - 构造器方式(反射) ;
- 静态工厂方式;
- 实例工厂方式(@Bean);
- FactoryBean方式 getObject
JavaConfig是如何替代xml的
从应用层面
1.Xml
- Spring容器ClassPathXmlApplicationContext("xml')
- Spring.xml
- 扫描包:
- 引入外部属性配置文件
- kproperty name=' password" value="S(mysql.password}">
- 指定其他配置文件:
2. javaconfig
- Spring容器: AnnotationConfigAplicationContetijavaconfig.class)
- 配置类@Configuration
- @Bean @Scope @Lazy
- 扫描包: @ComponentScan
- 引入外部属性配置文件@PropertySource("lasspath:db. properties")
- @Value("$(mysql.password}")
- @Import @lmpor({配置类)) 使用比较灵活
从源码层面

@Component, @Controller, @Repository, @Service有何区别?
@Component:这将java类标记为bean。它是任何Spring管理组件的通用构造型。spring 的组件扫描机制现在可以将其拾取并将其拉入应用程序环境中。是另外3个注解的原注解
@Controller:这将一个类标记为Spring Web MVC控制器。标有它的Bean会自动导入到loC容器中。
@Service:此注解是组件注解的特化。它不会对@Component注解提供任何其他行为。您可以在服务层类中使用@Service而不是@Component,因为它以更好的方式指定了意图。
@Repository:这个注解是具有类似用途和功能的@Component注解的特化。它为DAO提供了额外的好处。它将DAO导入loC容器,并使未经检查的异常有资格转换为Spring DataAccessException。@Component 和 @Bean 的区别
@Component 和 @Bean 是两种使用注解来定义bean的方式
@Component(和@Service和@Repository)用于自动检测和使用类路径扫描自动配置bean。注释类和bean之间存在隐式的一对一映射(即每个类一个bean)。这种方法对需要进行逻辑处理的控制非常有限,因为它纯粹是声明性的。@Compent 作用就相当于 XML配置。
@Bean用于显式声明单个bean,而不是让Spring像上面那样自动执行它。它将bean的声明与类定义分离,并允许您精确地创建和配置bean。@Bean常和@Configuration注解搭配使用
为什么有了@Compent,还需要@Bean呢?
如果想将第三方的类变成组件装配到你的应用中,你又没有没有源代码,也就没办法使用@Component进行自动配置,这种时候使用@Bean就比较合适了。不过同样的也可以通过xml方式来定义(如果不嫌麻烦的话)。
另外@Bean注解的方法返回值是对象,可以在方法中为对象设置属性。另外可以了解一下Spring的Starter机制,就是通过@Bean注解来定义bean。可以搭配@ConditionalOnMissingBean注解 @ConditionalOnMissingClass注解,如果本项目中没有定义该类型的bean则会生效。
要避免在某个项目中定义或者通过congfig注解来声明大量重复的bean。
@Configuration作用及原理
作用:
@Configuration用来代替xml配置方式spring.xm配置文件
2.没有@Configuration也是可以配置@Bean
3. @Configuration加与不加有什么区别
4.加了@Configuration会为配置类创建cglib动态代理(保证配置类@Bean方法调用Bean的单例),@Bean方法的调用就会通过容器getBean进行获取
@Bean之间的方法调用是怎么保证单例的?- 如果希望@bean的方法返回是对象是单例需要在类上面加上@Configuration,
- Spring会在invokeBeanFactoryPostProcessor通过内置BeanFactoryPostProcessor中会CGLib生成动态代理
- 当@Bean方法进行互调时,则会通过CGLIB进行增强, 通过调用的方法名作为bean的名称去ioc容器中获取,进而保证了@Bean方法的单例
原理:
- 创建Spring上"下文的时候会注册一一个解析配置的处理器ConfigurationClassPostProcessor (实现BeanFactoryPostProcesso和BeanDefinitionRegistryPostProcessor)
- 在调用invokeBeanFactoryPostProcessor,就会去调用ConfigurationClassPostProcessor.postProcessBeanDefinitionRegistry进行解析配置(解析配置类说白就是去解析各种注解(@Bean @Configuratin@lmport @Component ...就是注册BeanDefntion)
- ConflguratlonClassPostProcessor.postProcessBeanFactory去创建cglib动态代理
@lmport可以有几种用法?
- 直接指定类(如果配置类会按配置类正常解析、 如果是个普通类就会解析成Bean)
- 通过ImportSelector可以一次性注册多个,返回一个string()每一个值就是类的完整类路径
- 通过DeferredlmportSelector可以- -次性注册多个. 返回一个string[ ]每一个值就是类的完整类路径
- 区别: DeferredImportSelector 顺序靠后
- 通过DeferredlmportSelector可以- -次性注册多个. 返回一个string[ ]每一个值就是类的完整类路径
- 通过ImpotBeanDefnitionRegistrar可以一次性注册多个,通过BeanDefinitionRegistry米动态注册BeanDefintion
Spring Boot、Spring MVC和Spring的区别
spring是一个IOC容器, 用来管理Bean,使用依赖注入实现控制反转,可以很方便的整合各种框架,提供AOP机制弥补OOP的代码重复问题、更方便将不同类不同方法中的共同处理抽取成切面、自动注入给方法执行,比如日志异常等
springmvc是spring对web框架的一个解决方案, 提供了一个总的前端控制器Servlet, 用来接收请求,然后定义了一套路由策略 (urI到handle的映射)及适配执行handle, 将handle结果使用视图解析技术生成视图展现给前端
springboot是spring提供的一个快速开发工具包,让程序员能更方便、更快速的开发spring+springmvc应用, 简化了配置(约定了默认配置,约定大于配置), 整合了一系列的解决方案(starter机制引入框架的start包就不用手动配置xml配置bean了) 、redis. mongodb. es,可以开箱即用。
SpringMVC工作流程
1)用户发送请求至前端控制器DispatcherServlet。
2) DispatcherServlet 收到请求调用HandlerMapping处理器映射器,维护url到handler的映射。
3)处理器映射器找到具体的处理器(可以根据xml配置、注解进行查找),生成处理器及处理器拦截器(如果有则生 成)一并返回给DispatcherServlet。
4) DispatcherServlet 调用HandlerAdapter处理器适配器。
5) HandlerAdapter 经过适配调用具体的处理器(Controller,也叫后端控制器)
6) Controller 执行完成返回ModelAndView。
7) HandlerAdapter 将controller执行结果ModelAndView返回给DispatcherServlet。
8) DispatcherServlet将ModelAndView传给ViewReslover视图解析器。
9) ViewReslover 解析后返回具体View。
10) DispatcherServlet 根据View进行渲染视图(即将模型数据填充至视图中)。
11) DispatcherServlet 响应用户。
Spring和SpringMVC为什么需要父子容器?
就功能性来说不用子父容器也可以完成(参考: SpringBoot 就没用子父容器)
1.所以父子容器的主要作用应该是划分框架边界。有点单一职责的味道。service.、dao层 我们一般使用spring框架来管理、controller层交给springmvc管理
2.规范整体架构使父容器service无法访问子容器controller.子容器controller可以访问父容器service
3.方便子容器的切换。如果现在我们想把web层从spring mvc替换成struts,那么只需要将spring-mvc. xml替换成strut:的配置文件struts. xml即可,而spring-core. xml不需要改变。SpringMVC的拦截器和过滤器有什么区别?执行顺序
拦截器不依赖与sefvlet容器,过滤器依赖与servlet容器。
拦截器只能对action(DispatcherServlet映射的请求)请求起作用,而过滤器则可以对几乎所有的请求起作用。
拦截器可以访间action上下文、值栈里的对象(访问容器中的Bean),而过滤器不能访问(基于spring注册的过滤器也可以访问容器中的bean)。
Spring Boot自动配置原理?
@lmport + @Configuration(还有@Bean)+ Spring spi机制
自动配置类由各个starter提供,使用@Configuration + @Bean定义配置类,放到META-INF/spring.factories下使用Spring spi扫描META-INF/spring.factories'下的配置类
使用@Import导入自动配置类
1.通过@SpringBootConfiguTation引入了@EnableAutoContiguration (负责启动自动配置功能)
2.@EnableAutoConfiguration引入了@lmport
3.Spring容器启动时:加载loc容 器时会解析@lmport注解
4.@Import导入了一个deferredImportSelector, 它会使SpringBoot的自动配置类的顺序在最后, 这样方便我们扩展和覆盖?
5.然后读取所有的/META-INF/spring.factories文件(SPI)
6.过滤出所有AutoConfigurtionClass类型的类
7.最后通过@ConditioOnXXX排除无效的自动配置类
概括:Spring Boot启动的时候会通过@EnableAutoConfiguration注解找到META-INF/spring.factories配置文件中的所有自动配置类,并对其进行加载,而这些自动配置类都是以AutoConfiguration结尾来命名的,它实际上就是一个JavaConfig形式的Spring容器配置类,它能通过以Properties结尾命名的类中取得在全局配置文件中配置的属性如:server.port,而XxxProperties类是通过@ConfigurationProperties注解与全局配置文件中对应的属性进行绑定的。SpringBoot内置Tomcat启动原理
- 当依赖Spring-boot-starter-web依赖时会在SpringBoot中添加: ServletWebServerFactoryAutoConfiguration servlet容器自动配置类
- 该自动配置类通过@Import导入了可用(通过@ConditionalOnClass判断决定使用哪一个的Web容器工厂(默认Tomcat)
- 在内嵌Tomcat类中配置了一 个TomcatServletWebServerFactory的Bean (Web容器工厂)
- 它会在SpringBoot启动时加载ioc容器(efresh) OnRefersh 创建内嵌的Tomcat并启动
Spring是如何整合Mybaits将Mapper接口注册为Bean的(了解)
1.首先MyBatis的Mapper接口核心是JDK动态代理
2. Spring会排除接口,无法注册到IOC容器中
3. MyBatis实现了BeanDefinitionRegistryPostProcessor可以动态注册BeanDefnition
4.需要自定义扫描器I继承Spring内部扫描器ClassPathBeanDefinitionScanner负责扫描指定包路径并判断是否有@Componet及是否为接口或抽象类) 重写写排除接口的方法(IDCandidateComponent)
5.但是接口虽然注册成了BeanDefinition但是无法实例化Bean因为接口无法实例化
6.需要将BeanDefinition的BeanClass替换成JDK动态代理的实例(偷天换日)
7. Mybatis通过FactoryBean的工厂方法设计模式可以自由控制Bean的实例化过程,可以在getObject方法中创建JDK动态代理如何理解Spring Boot中的Starter
使用spring + springmvc使用,如果需要引入mybatis等框架,需要到xml中定义mybatis需要的bean(使用bean标签等) 用starter就是定义一个starter的jar包,写一个@Configuration配置类、将这些bean定义在里面,然后在starter包的META-INF/spring.factories中写入该配置类,springboot会按照约定来加载该配置类开发人员只需要将相应的starter包依赖进应用,进行相应的属性配置(使用默认配置时,不需要配置)。就可以直接进行代码开发,使用对应的功能了,比如mybatis spring boot-starter, spring boot-starter-redis
为什么SpringBoot的jar包可以直接运行
1.SpringBoot提供了一个插件spring-boot-maven-plugin用于 把程序打包成一个可执行的jar包。
2.Spring Boot应用打包之后,生成一个Fat jar(jar包中包含jar),包含了应用依赖的jar包和Spring Boot loader相关的类。
3.java jar会去找jar中的manifest文件(清单文件),在那里面找到真正的启动类(Main-Class);
4.Fat jar的启动Main函数是JarLauncher,它负责创建一个LaunchedURLClassLoader来加载boot-lib下面的jar,并以一个新线程启动应用的Main函数(找到mainifest中的start-class)。SpringBoot的启动原理
- 运行main方法: 初始化SpringApplication从spring. factories 读取listener ApplicationContetnitializer
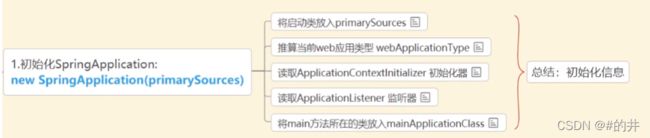
- 运行run方法
- 读取环境变量配置信息.....
- 创建springApplication上"下文:ServletWebServerApplicationContext
- 预初始化上下文:将启动类作为配置类进行读取-->将配置类注册为BeanDefintion
- 调用refresh加载ioc容器
- 加载所有的自动配置类
- onRefresh创建(内置)servlet容器
- 在这个过程springboot会调用很多监听器对外进行扩展
SpringBoot读取配置文件的原理是什么?加载顺序是怎样的?
通过事件监听的方式读取的配置文件: ConfigFileApplicationListener
优先级从高到低,高优先级的配置覆盖低优先级的配置,所有配置会形成互补配置。
./config/ xxx.properties > ./config/ xxx/xxx. properties > ./ application. properties > classpath: config/ > classpath:如何在SpringBoot的基础上做扩展
首先肯定要确认扩展的技术点(比如要扩展的是aop)
打开aop自动配直类:
重点关注@ConditionalOnXXX它可以帮助开启或关团某些功能
深入看源码有些自动配置类提供对外的展接口,去实现接口也可以进行扩展什么是嵌入式服务器?为什么要使用嵌入式服务器?
节省了下载安装tomcat,应用也不需要再打war包,然后放到webapp日录下再运行 只需要一个安装了Java的虚拟机,就可以直接在上面部署应用程序了 。springboot已经内置了tomcat.jar,运行main方法时会去启动tomcat,并利用tomcat的spi机制加载springmvc