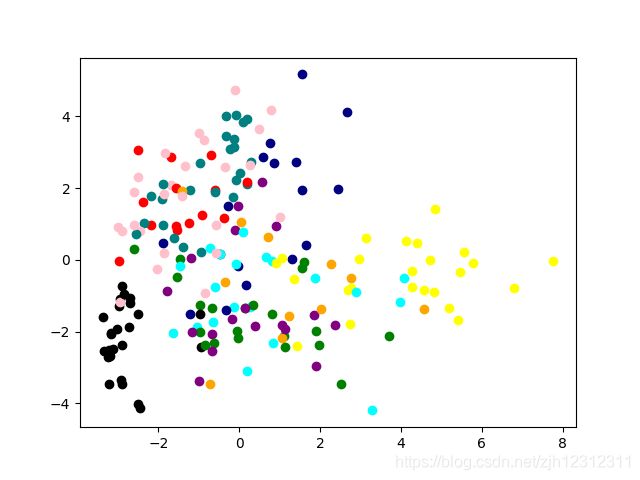
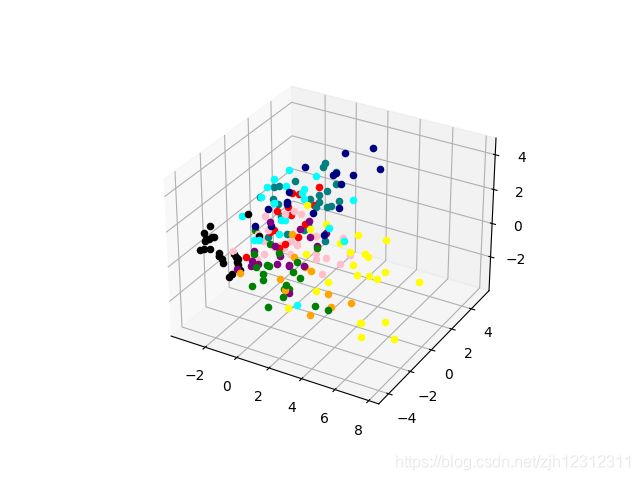
1. pytorch,使用 torch.pca_lowrank 函数
A,要处理的数据, q要保留的维度,返回(S,V,D)元组,中间的V为降维后的维度
代码
import torch
import torchvision.datasets as data
from torch.utils.data import DataLoader
import torchvision.transforms as T
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
# 颜色设置
color = ['yellow','black','aqua','green','teal','orange','navy','pink','purple','red']
# 绘图
def show(v2,y):
for i in range(len(v2)):
plt.scatter(v2[i][0],v2[i][1],color=color[y[i]])
plt.show()
def show3d(v3,y):
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for i in range(len(v3)):
ax.scatter(v3[i][0],v3[i][1],v3[i][2],color=color[y[i]])
plt.show()
trans = T.Compose([
T.ToTensor(),
T.Normalize(mean=0, std=1)
])
mnist = data.MNIST('../mnist',train=True,download=False, transform=trans)
loader_train = DataLoader(mnist, batch_size=200, shuffle=True) # 可视化200个点
for (x,y) in loader_train:
x = torch.squeeze(x) # 去掉维度为1的, 也就是以28x28来分,结果不太好
# x = x.flatten(start_dim=2,end_dim=-1) #方法2: 压平,以1x784来分
print(x.shape)
# pca
v3 = []
for i in range(len(x)):
v3.append(torch.pca_lowrank(x[i],q=3)[1].numpy()) # 3维
v2 = []
for i in range(len(x)):
v2.append(torch.pca_lowrank(x[i],q=2)[1].numpy()) # 2维
print(v2)
# 画图
show(v2,y)
show3d(v3,y)
break
结果:效果特别差,找不到原因。后来使用sklearn的要好很多
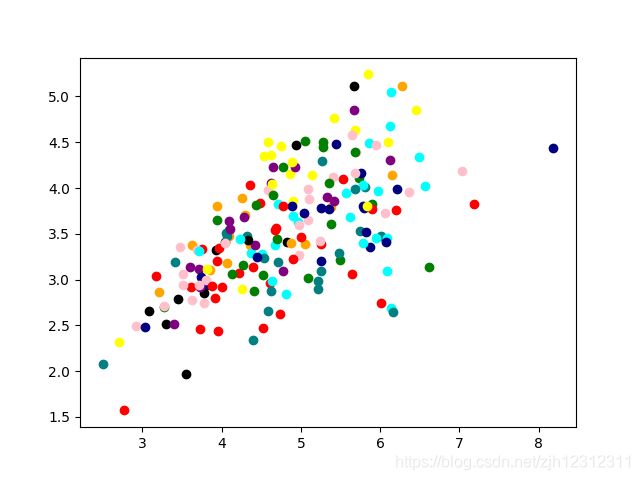
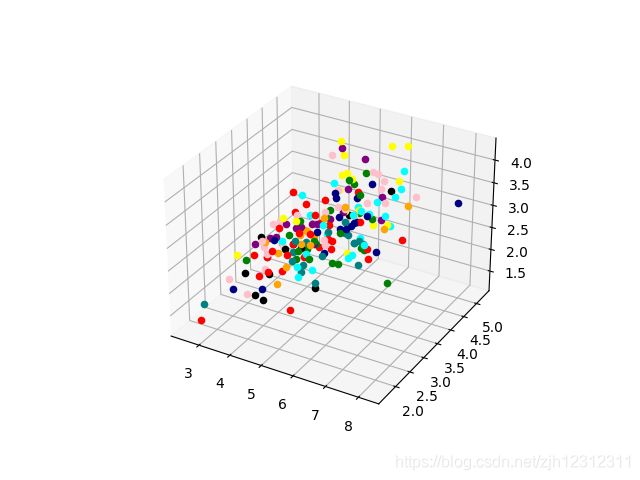
2. sklearn,使用 from sklearn import decomposition
代码
import torch
import torchvision.datasets as data
from torch.utils.data import DataLoader
import torchvision.transforms as T
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import decomposition
# 颜色设置
color = ['yellow','black','aqua','green','teal','orange','navy','pink','purple','red']
# 绘图
def show(v2,y):
for i in range(len(v2)):
plt.scatter(v2[i][0],v2[i][1],color=color[y[i]])
plt.show()
def show3d(v3,y):
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
for i in range(len(v3)):
ax.scatter(v3[i][0],v3[i][1],v3[i][2],color=color[y[i]])
plt.show()
trans = T.Compose([
T.ToTensor(),
T.Normalize(mean=0, std=1)
])
mnist = data.MNIST('../mnist',train=True,download=False, transform=trans)
loader_train = DataLoader(mnist, batch_size=200, shuffle=True) # 可视化1000个点
for (x,y) in loader_train:
# x = torch.squeeze(x) # 方法一:去掉维度为1的, 也就是以28x28来分,结果不太好
x = x.flatten(start_dim=2,end_dim=-1) #方法2: 压平,以1x784来分
x = torch.squeeze(x) # 去掉维度为1的
print(x.shape)
# pca
pca2 = decomposition.PCA(2)
pca3 = decomposition.PCA(3)
# 3维
v3 = []
pca3.fit(x) # sklearn的pca要求输入是(m,n)m为样本数,n为维数
temp = pca3.fit_transform(x)
v3.append(temp) # 3维
print(len(v3[0]))
# 2维
v2 = []
pca2.fit(x)
print('ssss',pca2.explained_variance_ratio_) #看每个特征可以百分之多少表达整个数据集
v2.append(pca2.fit_transform(x)) # 2维
print(v2)
# 画图
show(v2[0],y)
show3d(v3[0],y)
break
pca = decomposition.PCA()
pca.fit(x)
结果