目标检测算法——YOLOv5/YOLOv7改进之结合PP-LCNet(轻量级CPU网络)

>>>深度学习Tricks,第一时间送达<<<
目录
PP-LCNet——轻量级且超强悍的CPU级骨干网络!!
(一)前沿介绍
1.PP-LCNet主要模块
2.相关实验结果
(二)YOLOv5/YOLOv7改进之结合PP-LCNet
1.配置common.py文件
2.配置yolo.py文件
3.配置yolov5/yolov7_PP-LC.yaml文件
关于YOLO算法改进及论文投稿可关注并留言博主的CSDN/QQ
>>>一起交流!互相学习!共同进步!<<<
PP-LCNet——轻量级且超强悍的CPU级骨干网络!!
(一)前沿介绍
论文题目:PP-LCNet: A Lightweight CPU Convolutional Neural Network
论文地址:https://arxiv.org/abs/2109.15099
代码地址:https://github.com/ngnquan/PP-LCNet

先看一下小海带将YOLOv5与PP-LCNet结合后的实验训练情况:还不错吧!
![]()
发现问题:随着模型特征提取能力的增加以及模型参数和FLOPs数量的增加,在基于移动设备的ARM架构的基础上或基于CPU设备的架构上实现快速推理速度变得困难。在这种情况下,已经提出了许多优秀的移动网络,但由于MKLDNN的限制,这些网络的速度在启用了MKLDNN的IntelCPU上并不理想。
解决方法:针对此问题,作者提出了一个基于MKLDNN加速策略的轻量级CPU网络,命名为PP-LCNet,它提高了轻量级模型在多任务上的性能。论文还列出了可以在延迟几乎不变的情况下提高网络准确性的技术。通过这些改进,PP-LCNet在相同的分类推理时间下,它优于最先进的模型,准确率可以大大超过以前的网络结构。并且对于计算机视觉的下游任务,也表现非常出色,比如物体检测、语义分割等等。
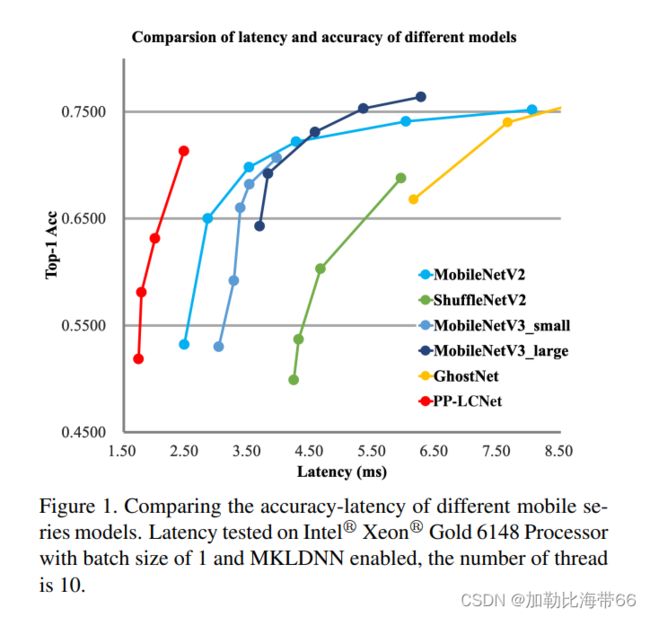
PP-LCNet 在同样精度的情况下,速度远超当前所有的骨架网络!它应用在比如目标检测、语义分割等任务算法上,也可以使原本的网络有大幅度的性能提升。由下图可看出,PP-LCNet 不仅精度提升相当明显,而且比MobileNetV3快几乎3倍!!
PP-LCNet的主要贡献有以下4点:
1.更好的激活函数。
由ReLU换成了H-Swish,性能有了很大的提升,而推理时间几乎没有变化。
2.合适的位置添加SE模块
实验发现当SE模块放到最后的时候比较好,因此将SE模块放在网络最后部分,在SE层中使用的激活函数为relu和h-sigmoid。
3.更大的卷积核
作者实验发现发现在模型的最后将3x3卷积核换成5x5的效果比较好。
4.GAP后更高维度的1x1卷积层
GAP后面的维度很小,直接在他后面添加分类层会损失很多特征信息,为了增强模型的鲁棒性,在最终的GAP层之后附加了一个1280维大小的1 × 1 conv(相当于FC层),在几乎不增加推理时间的情况下存储更多的模型。
1.PP-LCNet主要模块

2.相关实验结果

(二)YOLOv5/YOLOv7改进之结合PP-LCNet
改进方法和其他模块一样,分三步走:
1.配置common.py文件
class SELayer(nn.Module):
def __init__(self, inp, oup, reduction=4):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(oup, _make_divisible(inp // reduction), 1, 1, 0,),
nn.ReLU(),
nn.Conv2d(_make_divisible(inp // reduction), oup, 1, 1, 0),
HardSigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x)
y = self.fc(y).view(b, c, 1, 1)
return x * y
class DepSepConv(nn.Module):
def __init__(self, inp, oup, kernel_size, stride, use_se):
super(DepSepConv, self).__init__()
assert stride in [1, 2]
padding = (kernel_size - 1) // 2
if use_se:
self.conv = nn.Sequential(
# dw
nn.Conv2d(inp, inp, kernel_size, stride, padding, groups=inp, bias=False),
nn.BatchNorm2d(inp),
HardSwish(),
# SE
SELayer(inp, inp),
# pw-linear
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
HardSwish(),
)
else:
self.conv = nn.Sequential(
# dw
nn.Conv2d(inp, inp, kernel_size, stride, padding, groups=inp, bias=False),
nn.BatchNorm2d(inp),
HardSwish(),
# pw-linear
nn.Conv2d(inp, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
HardSwish()
)
def forward(self, x):
return self.conv(x)2.配置yolo.py文件
加入DepthSepConv模块。

3.配置yolov5/yolov7_PP-LC.yaml文件
具体配置和之前一样。