吴恩达机器学习系列课程笔记——第四章:多变量线性回归(Linear Regression with Multiple Variables)
4.1 多维特征
https://www.bilibili.com/video/BV164411b7dx?p=18
目前为止,我们探讨了单变量/特征的回归模型,现在我们对房价模型增加更多的特征,例如房间数、楼层、楼屋年限等,构成一个含有多个变量的模型,模型中的特征为(x1,x2,…,xn)。

增添更多特征后,我们引入一系列新的注释:
n 代表特征的数量
x(i)代表第 i 个训练实例,是特征矩阵中的第i行,是一个**向量**(**vector**)。
比方说,上图的,x(2)=[14163240]
xj(i)代表特征矩阵中第 i 行的第 j 个特征,也就是第 i 个训练实例的第 j 个特征。
如上图的x2(2)=3,x3(2)=2

支持多变量的假设 h 表示为:hθ(x)=θ0+θ1x1+θ2x2+…+θnxn,
这个公式中有n+1个参数和n个变量,为了使得公式能够简化一些,引入x0=1,这样就有n+1个参数和n+1个变量,只是以后我们都固定设x0=1,则公式转化为:hθ(x)=θ0x0+θ1x1+θ2x2+…+θnxn

此时模型中的参数是一个n+1维的向量,任何一个训练实例也都是n+1维的向量,特征矩阵X的维度是 m∗(n+1)。 因此公式可以简化为:hθ(x)=θT × X,其中上标T代表矩阵转置。
4.2 多变量梯度下降
https://www.bilibili.com/video/BV164411b7dx?p=19
与单变量线性回归类似,在多变量线性回归中,我们也构建一个代价函数,则这个代价函数是所有建模误差的平方和,即:

其中:

我们的目标和单变量线性回归问题中一样,是要找出使得代价函数最小的一系列参数。 多变量线性回归的批量梯度下降算法为:

我们再回到用两个参数的梯度下降来推演多个参数的梯度下降
两个参数θ0,θ1:

多个参数θ j,(j = 0,1,2…)

通过这个求导后的公式,我们能发现,实际上用θ0和θ1为例,这两个函数都是相同的(多参数的x0=1,所以还是相同),唯一的区别就是求导后多出的x j,(j = 0,1,2…)

4.3 梯度下降法实践1-特征缩放
https://www.bilibili.com/video/BV164411b7dx?p=20
这节课讲的是关于梯度下降运算的使用技巧,一种称为特指缩放的方法
以房价问题为例,假设我们使用两个特征,房屋的尺寸和房间的数量,尺寸的值为 0-2000平方英尺,而房间数量的值则是0-5,以两个参数分别为横纵坐标,绘制代价函数的等高线图能,看出图像会显得很扁,梯度下降算法需要非常多次的迭代才能收敛。越是扁平,情况越严重(如左边)

解决方式:在我们面对多维特征问题的时候,我们要保证这些特征都具有相近的尺度,这将帮助梯度下降算法更快地收敛。即尽可能的缩小特征的取值范围,使得各个特征都有个相近且不大的尺度。直观的图像就是圆形图像。那么梯度下降算法就会快速的收敛。如图:

实际上,缩放的方式有很多,如上图就是使用直接除以m,使得所有特征的尺度缩放到-1到1,但并不是都要用这种缩放方式,也不是一定要缩放到-1到1,我们可以按照自己的需求进行缩放比如

先减去μ(平均值),再除以(标准差:最大值减去最小值),得到的尺度在-0.5到0.5左右
方法多样,尺度也没有固定的,但过大的尺度范围(-100到100)和过小的尺度范围(-0.00001到0.00001)都是不合适的。
但核心都是为了找出一个合适的尺度,使得梯度下降算法收敛的更快,这就是特指缩放方法
4.4 梯度下降法实践2-学习率
https://www.bilibili.com/video/BV164411b7dx?p=21
梯度下降算法收敛所需要的迭代次数根据模型的不同而不同,我们不能提前预知,我们可以绘制迭代次数和代价函数的图表来观测算法在何时趋于收敛。所以要学会如何挑选学习率α

梯度下降算法的每次迭代受到学习率的影响
如果学习率α过小,则达到收敛所需的迭代次数会非常高(蓝色);

如果学习率α过大,每次迭代可能不会减小代价函数,可能会越过局部最小值导致无法收敛。

通常可以考虑尝试些学习率α(取3倍):
…,0.001,0.003,0.01,0.03,0.1,0.3,1…
4.5 特征和多项式回归
https://www.bilibili.com/video/BV164411b7dx?p=22
如房价预测问题,若我们使用房屋的临街宽度为参数θ1,房屋的纵向深度为θ2
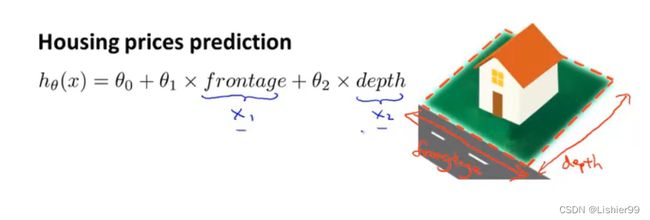
hθ(x)=θ0+θ1×frontage+θ2×depth
实际上我们可以自己创造新的特征,即宽度和深度都是为了求出房屋的面积,也就是房屋的大小实际上就是
x = θ1 × θ2
则:hθ(x)=θ0+θ1x
而线性回归(直线)并不适用于所有数据,有时我们需要曲线来适应我们的数据
比如一个二次方模型,不过存在二次方模型之后会下降的趋势

或者三次方模型,避免后期有下降的趋势

甚至其他更复杂的函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KWleDk9c-1657956978553)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220714175705337.png)]
注:如果我们采用多项式回归模型,在运行梯度下降算法前,特征缩放非常有必要,否则尺度太大了,影响梯度下降算法的收敛速度。

总之,这节课的目的在于告诉我们:我们依据对平方根函数的图像的了解(二次会下降,所以引出三次),以及对数据的形状的了解,通过选中不同的特征(不使用长宽两个特征,而用面积),能够得出更好的模型,采用二次函数或者三次函数来拟合我们的数据。虽然听起来好像很难抉择,但之后的课程,我们会用一些算法来自动选择用什么特征,并选择使用一个二次函数还是三次或者别的函数来拟合数据。
但现在我们只需要知道:我们可以自由的选择特征,并且通过设计不同的特征,用复杂的函数来拟合数据
4.6 正规方程
https://www.bilibili.com/video/BV164411b7dx?p=23
实际上,我们要求出代价函数的最小值,其实就是在求θ。而梯度下降算法就是经过很多步的梯度下降迭代来收敛全局最小值

相反的,正规方程提供了一种解析解法来求θ,我们不需要运行迭代算法,而直接一次性地求出最优解θ
实际上,正规方程也有一些优点和缺点,以及在确认什么时候使用正规方程的时候,我们先对这个算法有个直观的理解,以下由梯度下降算法为例引出正规算法

如果是 J (θ) 是一个二元函数,如何获得最优解呢,如果学过微积分,我们知道只要置导数=0的点就是最优解
这样通过迭代求导,就能求出所有θ的最优解,但我们不是以后都这么做,因为太浪费时间了

第二个例子,假如我有m=4(为了方便,加上一列x0=1)的训练数据,为了实现正规方程,我要构建一个矩阵X,它记录了所有的特征,而预测值作为一个向量y,利用正规方程解出向量
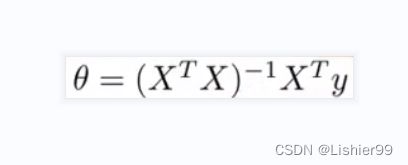
接下来,解释一下各个变量的含义
X的含义,就和上面的那个X一样,一个实例是一个列向量含有多个特征,将其转置,那么在X中,一行就是一个实例,每列就是这个实例的特征。

假设,我只有一个特征(加上x1=0)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SgDWoBTc-1657956978558)(C:\Users\admin\AppData\Roaming\Typora\typora-user-images\image-20220714185316077.png)\
在 Octave 中,正规方程写作:
pinv(X'*X)*X'*y
注:对于那些不可逆的矩阵(通常是因为特征之间不独立,如同时包含英尺为单位的尺寸和米为单位的尺寸两个特征,也有可能是特征数量大于训练集的数量),正规方程方法是不能用的。
梯度下降与正规方程的比较:
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率α | 不需要 |
| 需要多次迭代 | 一次运算得出 |
| 当特征数量n大时也能较好适用 | 需要计算(XTX)−1 如果特征数量n较大则运算代价大,因为矩阵逆的计算时间复杂度为O(n^3),通常来说当n小于10000 时还是可以接受的 |
| 适用于各种类型的模型 | 只适用于线性模型,不适合逻辑回归模型等其他模型 |
总结一下,只要特征变量的数目并不大,标准方程是一个很好的计算参数θ的替代方法。具体地说,只要特征变量数量小于一万,我通常使用标准方程法,而不使用梯度下降法。
随着我们要讲的学习算法越来越复杂,例如,当我们讲到分类算法,像逻辑回归算法,我们会看到,实际上对于那些算法,并不能使用标准方程法。对于那些更复杂的学习算法,我们将不得不仍然使用梯度下降法。因此,梯度下降法是一个非常有用的算法,可以用在有大量特征变量的线性回归问题。或者我们以后在课程中,会讲到的一些其他的算法,因为标准方程法不适合或者不能用在它们上。但对于这个特定的线性回归模型,标准方程法是一个比梯度下降法更快的替代算法。所以,根据具体的问题,以及你的特征变量的数量,这两种算法都是值得学习的。
正规方程的python实现:
import numpy as np
def normalEqn(X, y):
theta = np.linalg.inv(X.T@X)@X.T@y #X.T@X等价于X.T.dot(X)
return theta
4.7 正规方程及不可逆性(可选)
https://www.bilibili.com/video/BV164411b7dx?p=24
在这段视频中谈谈正规方程 ( normal equation ),以及它们的不可逆性。 由于这是一种较为深入的概念,并且总有人问我有关这方面的问题,因此,我想在这里来讨论它,由于概念较为深入,所以对这段可选材料大家放轻松吧,也许你可能会深入地探索下去,并且会觉得理解以后会非常有用。但即使你没有理解正规方程和线性回归的关系,也没有关系。
我们要讲的问题如下:θ=(XTX)−1XTy
备注:本节最后我把推导过程写下。
有些同学曾经问过我,当计算 θ=inv(X'X ) X'y ,那对于矩阵X′X的结果是不可逆的情况咋办呢? 如果你懂一点线性代数的知识,你或许会知道,有些矩阵可逆,而有些矩阵不可逆。我们称那些不可逆矩阵为奇异或退化矩阵。 问题的重点在于X′X的不可逆的问题很少发生,在Octave里,如果你用它来实现θ的计算,你将会得到一个正常的解。在Octave里,有两个函数可以求解矩阵的逆,一个被称为pinv(),另一个是inv(),这两者之间的差异是些许计算过程上的,一个是所谓的伪逆,另一个被称为逆。使用pinv() 函数可以展现数学上的过程,这将计算出θ的值,即便矩阵X′X是不可逆的。
在pinv() 和 inv() 之间,又有哪些具体区别呢 ?
其中inv() 引入了先进的数值计算的概念。例如,在预测住房价格时,如果x1是以英尺为尺寸规格计算的房子,x2是以平方米为尺寸规格计算的房子,同时,你也知道1米等于3.28英尺 ( 四舍五入到两位小数 ),这样,你的这两个特征值将始终满足约束:x1=x2∗(3.28)2。 实际上,你可以用这样的一个线性方程,来展示那两个相关联的特征值,矩阵X′X将是不可逆的。
第二个原因是,在你想用大量的特征值,尝试实践你的学习算法的时候,可能会导致矩阵X′X的结果是不可逆的。 具体地说,在m小于或等于n的时候,例如,有m等于10个的训练样本也有n等于100的特征数量。要找到适合的(n+1) 维参数矢量θ,这将会变成一个101维的矢量,尝试从10个训练样本中找到满足101个参数的值,这工作可能会让你花上一阵子时间,但这并不总是一个好主意。因为,正如我们所看到你只有10个样本,以适应这100或101个参数,数据还是有些少。
稍后我们将看到,如何使用小数据样本以得到这100或101个参数,通常,我们会使用一种叫做正则化的线性代数方法,通过删除某些特征或者是使用某些技术,来解决当m比n小的时候的问题。即使你有一个相对较小的训练集,也可使用很多的特征来找到很多合适的参数。 总之当你发现的矩阵X′X的结果是奇异矩阵,或者找到的其它矩阵是不可逆的,我会建议你这么做。
首先,看特征值里是否有一些多余的特征,像这些x1和x2是线性相关的,互为线性函数。同时,当有一些多余的特征时,可以删除这两个重复特征里的其中一个,无须两个特征同时保留,将解决不可逆性的问题。因此,首先应该通过观察所有特征检查是否有多余的特征,如果有多余的就删除掉,直到他们不再是多余的为止,如果特征数量实在太多,我会删除些 用较少的特征来反映尽可能多内容,否则我会考虑使用正规化方法。 如果矩阵X′X是不可逆的,(通常来说,不会出现这种情况),如果在Octave里,可以用伪逆函数pinv() 来实现。这种使用不同的线性代数库的方法被称为伪逆。即使X′X的结果是不可逆的,但算法执行的流程是正确的。总之,出现不可逆矩阵的情况极少发生,所以在大多数实现线性回归中,出现不可逆的问题不应该过多的关注XTX是不可逆的。