从0开始的cifar100数据集实战
作为一名C++程序员,为了研究生毕业,只能转头去搞人工智能了。从7月份到现在,我学习了2个多月,这不马上要开题了,我用下tensorflow中的数据集cifar100,来逐次应用我所学到的知识。这个数据集中有100个类,每个类中有600张图片,这是一个典型的多分类问题。
环境:tensorflow2.5.0 python:3.9.0
一开始,我使用最简单的深度学习网络,当然,数据预处理也得进行,代码如下:
from tensorflow.keras.datasets import cifar100
from tensorflow.keras import Input,layers,Model
from tensorflow.keras.utils import to_categorical
import tensorflow as tf
(x_train,y_train),(x_test,y_test)=cifar100.load_data()
x_train=tf.cast(x_train,dtype=tf.float32)
x_test=tf.cast(x_test,dtype=tf.float32)
x_train=x_train/255.0
x_test=x_test/255.0
y_test=to_categorical(y_test)
y_train=to_categorical(y_train)
input_tensor=Input(shape=x_train.shape[1:])
def Model1(input_tensor):
conv1=layers.Conv2D(128,3,activation="relu")(input_tensor)
max_pool1=layers.MaxPooling2D(strides=2)(conv1)
conv2=layers.Conv2D(64,3,activation="relu")(max_pool1)
max_pool2=layers.MaxPooling2D(strides=2)(conv2)
conv3=layers.Conv2D(32,5,activation="relu")(max_pool2)
FC=layers.Flatten()(conv3)
FC1=layers.Dense(128,activation="relu")(FC)
FC2=layers.Dense(100,activation="softmax")(FC1)
return FC2在Model1这个函数中,我只用了最简单的模型,一共只用8层(我是按照行数来统计的),调用这个函数如下:
model=Model(input_tensor,Model1(input_tensor))
model.compile(optimizer="rmsprop",loss="categorical_crossentropy",metrics=["acc"])
history=model.fit(x_train,y_train,batch_size=200,epochs=20,validation_data=(x_test,y_test))
print(model.summary())
#绘制训练正确率和验证损失率
import matplotlib.pyplot as plt
acc=history.history["acc"]
val_acc=history.history["val_acc"]
loss=history.history["loss"]
val_loss=history.history["val_loss"]
epochs=range(1,len(acc)+1)
plt.plot(epochs,acc,"bo",label="Training acc")
plt.plot(epochs,val_acc,"b",label="Validation acc")
plt.title("Training and validation accuracy")
plt.legend()
# plt.figure()
# plt.plot(epochs,loss,"bo",label="Training loss")
# plt.plot(epochs,val_loss,"b",label="Validation loss")
# plt.title("Training and validation loss")
# plt.legend()
plt.show()模型的优化器和损失函数都是用的现成的,我还使用了matplotlib库来绘制训练和验证的正确率。
结果如下:
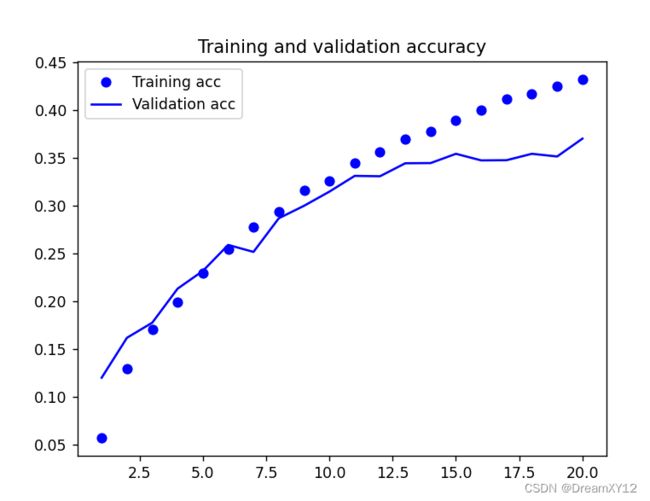
最终训练和验证的正确率不高,其实这也是预料到的,毕竟网络层次太简单,不够复杂,而且由于数据集的图片过小,导致卷积的次数在没有设置padding="same"的情况下,不能过多的卷积。
Model1函数中模型的参数如下:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 30, 30, 128) 3584
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 15, 15, 128) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 13, 13, 64) 73792
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 6, 6, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 2, 2, 32) 51232
_________________________________________________________________
flatten (Flatten) (None, 128) 0
_________________________________________________________________
dense (Dense) (None, 128) 16512
_________________________________________________________________
dense_1 (Dense) (None, 100) 12900
=================================================================
Total params: 158,020
Trainable params: 158,020
Non-trainable params: 0
_________________________________________________________________
None看到没有,如果仅仅使用卷积的默认参数,不设置填充的话,在图片比较小的情况下,是不能多次卷积的。
接下来就是稍微的改进了,如下:
def Model2(input_tensor):
conv1 = layers.Conv2D(64, 3, activation="relu", padding="same")(input_tensor)
conv2 = layers.Conv2D(64, 3, activation="relu", padding="same")(conv1)
max_pool1 = layers.MaxPooling2D((2, 2), strides=2, padding="same")(conv2)
conv3 = layers.Conv2D(32, 5, activation="relu", padding="same")(max_pool1)
conv4 = layers.Conv2D(32, 5, activation="relu", padding="same")(conv3)
max_pool2 = layers.MaxPooling2D((2, 2), strides=2)(conv4)
FC = layers.Flatten()(max_pool2)
FC1 = layers.Dense(128, activation="relu")(FC)
FC2 = layers.Dense(100, activation="softmax")(FC1)
return FC2我是模块化编写的,在调用的时候把函数名改下就可以了,其他的都没变。
这个模型是9层,而且我设置了padding为“same”,表示输出的参数形状和输入的一样,对了,在第一次最大池化中,由于使用步长为2,所以特征图的长和宽还是缩小了一半,padding的那个参数好像没有用。另外,由于我的电脑显存只有4个G,在卷积的时候不敢将过滤器设置的太大,因为我设置了padding这个参数,如果将卷积的过滤器设置为128,那参数数量将会很大,在运行程序的时候会报警告。
运行的结果如下:

模型的参数如下:
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 32, 32, 3)] 0
_________________________________________________________________
conv2d (Conv2D) (None, 32, 32, 64) 1792
_________________________________________________________________
conv2d_1 (Conv2D) (None, 32, 32, 64) 36928
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 16, 16, 32) 51232
_________________________________________________________________
conv2d_3 (Conv2D) (None, 16, 16, 32) 25632
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 8, 8, 32) 0
_________________________________________________________________
flatten (Flatten) (None, 2048) 0
_________________________________________________________________
dense (Dense) (None, 128) 262272
_________________________________________________________________
dense_1 (Dense) (None, 100) 12900
=================================================================
Total params: 390,756
Trainable params: 390,756
Non-trainable params: 0
_________________________________________________________________
None在第一次改进后,虽然验证的正确率貌似没有什么大的提升,但训练的正确率已经有了大幅度的提升了。同时模型参数的数量上升了一倍多,所以模型参数数量的优化也是一个可以研究的点。
你可能会问我,为什么训练的正确率会上升,其实我现在的状态是能使用tensorflow中的函数去实现或者接近论文或者期刊中的模型,但你要问我为什么这样做,我只能说通过加深网络,增加参数,可以更好的提取图像中的信息。淦,我的论文难搞啊。
总之,通过这一次改动,确实是提升了模型的准确率,但验证的正确率还是不够,接下来我会继续更新,争取将注意力机制,特征融合,残差网络,inception模块都加到这里面去。就这样了,下次见。