在Pytorch中使用VGG16进行迁移学习
什么是迁移学习?
我们总是被告知“熟能生巧”,我们被要求在不同领域练习大量问题,为期末考试做好准备。我们解决的问题越多,我们就越能更好地利用这些知识以解决新问题。如果有一种方法可以应用相同的技术来解决分类、回归或聚类问题呢?
迁移学习是一种技术,通过它我们可以使用在 ImageNet 等标准数据集上训练的模型权重来提高给定任务的效率。
为什么要使用迁移学习?
在我们进一步了解迁移学习的工作原理之前,让我们先看看进行迁移学习后我们获得的好处。迁移学习的学习过程为:
快速 - 普通的卷积神经网络需要几天甚至几周的时间来训练,但你可以通过迁移学习来缩短这个过程。
准确 - 通常,迁移学习模型的性能比自定义模型好 20%。
需要较少的训练数据 - 在大型数据集上进行训练,该模型已经可以检测特定特征,并且需要较少的训练数据来进一步改进模型。
图像数据的迁移学习
为了在这里演示迁移学习,我选择了一个简单的二元分类器数据集,可以在这里找到:
https://www.kaggle.com/shaunthesheep/microsoft-catsvsdogs-dataset/code
该数据由猫和狗组成,即猫的 2.5k 图像和狗的 2.5k 图像。
VGG 架构
VGG 有两种模型,VGG-16 和 VGG-19。在这篇博客中,我们将使用 VGG-16 对我们的数据集进行分类。VGG-16主要有三部分:卷积层、池化层和全连接层。
卷积层:在这一层中,过滤器用于从图像中提取特征。最重要的参数是内核的大小和步幅。
池化层:它的功能是减小空间大小以减少网络中的参数和计算量。
全连接层:这些完全连接到前面的层,就像一个简单的神经网络。
给定的图显示了模型的架构:
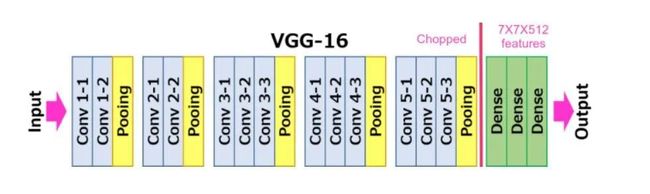
要执行迁移学习,请使用 PyTorch 导入预训练模型,根据你的要求移除最后一个全连接层或在最后添加一个额外的全连接层(因为该模型提供 1000 个输出,我们可以对其进行自定义以提供所需的数量输出)并运行模型。
预处理
在训练前预处理图像是避免错误的非常重要的步骤。预处理可以将图像大小调整到相同的维度,并对每个图像进行统一变换。torchvison.transforms 中可用的不同转换工具用于此过程。
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.1, hue=0.1),
transforms.RandomAffine(degrees=40, translate=None, scale=(1, 2), shear=15, resample=False, fillcolor=0),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))
])
图像使用 ImageFolder 加载并保存到数据加载器中。ImageFolder 根据图像所在的文件夹保存图像及其各自的标签,数据加载器将数据分成不同的批次进行训练。在这里,选择的批量大小为 8。
可视化数据集
在训练数据之前可视化数据集是一个很好的做法。这可用于确保正确加载数据及其标签,并成功应用转换。
对于这个过程,图像以张量格式保存在网格中,并从字典中提取标签。
import torchvision
def imshow(inp, title=None):
"""Imshow for Tensor."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
plt.imshow(inp)
if title is not None:
plt.title(title)
plt.pause(0.001) # pause a bit so that plots are updated
# Get a batch of training data
inputs, classes = next(iter(trainloader))
# Make a grid from batch
out = torchvision.utils.make_grid(inputs)
imshow(out,title=[class_names[x] for x in classes])

导入和训练模型
可以使用 Pytorch 导入预训练模型。该设备可以进一步转为使用GPU,这样可以减少训练时间。
import torchvision.models as models
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model_ft = models.vgg16(pretrained=True)
数据集进一步分为训练集和验证集以避免过度拟合。该模型在训练时使用的一些参数如下:
标准-交叉熵损失
优化器-随机梯度下降,学习率=0.01,动量=0.9
指数学习率调度程序 - 每 7 步将学习率值降低 gamma=0.1 倍。
最后加入一个线性全连接层,使输出收敛,给出两个预测标签。
num_ftrs = model_ft.fc.in_features
# Here the size of each output sample is set to 2.
# Alternatively, it can be generalized to nn.Linear(num_ftrs, len(class_names)).
model_ft.fc = nn.Linear(num_ftrs, 2)
#model_ft = model_ft.to(device)
criterion = nn.CrossEntropyLoss()
# Observe that all parameters are being optimized
optimizer_ft = optim.SGD(model_ft.parameters(), lr=0.001, momentum=0.9)
# Decay LR by a factor of 0.1 every 7 epochs
exp_lr_scheduler = lr_scheduler.StepLR(optimizer_ft, step_size=7, gamma=0.1)
这些参数可以根据自己的需要和数据集来选择。
最初,我们将输入和标签传递给模型,然后我们得到标签的预测值作为输出。该预测值和标签的实际值用于计算交叉熵损失,该损失进一步用于反向传播以更新权重和偏差的值。
def train_model(model, criterion, optimizer, scheduler, num_epochs=25):
since = time.time()
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
running_corrects = 0
# Iterate over data.
for inputs, labels in trainloader:
inputs = inputs.to(device)
labels = labels.to(device)
# zero the parameter gradients
optimizer.zero_grad()
# forward
# track history if only in train
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# backward + optimize only if in training phase
if phase == 'train':
loss.backward()
optimizer.step()
# statistics
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
if phase == 'train':
scheduler.step()
epoch_loss = running_loss / dataset_sizes
epoch_acc = running_corrects.double() / dataset_sizes
print('{} Loss: {:.4f} Acc: {:.4f}'.format(
phase, epoch_loss, epoch_acc))
# deep copy the model
print()
time_elapsed = time.time() - since
print('Training complete in {:.0f}m {:.0f}s'.format(
time_elapsed // 60, time_elapsed % 60))
# load best model weights
model.load_state_dict(best_model_wts)
return model
model_ft = train_model(model_ft, criterion, optimizer_ft, exp_lr_scheduler,
num_epochs=25)
在这一步之后,你已经成功地训练了模型。
☆ END ☆
如果看到这里,说明你喜欢这篇文章,请转发、点赞。微信搜索「uncle_pn」,欢迎添加小编微信「 woshicver」,每日朋友圈更新一篇高质量博文。
↓扫描二维码添加小编↓
