向量化方式优化Bihash searching研究报告
简要
什么是Bihash?
Bihash 是如何工作?
基础性能表现.
查询函数的底层指令和CPU微架构的Top-Down分析法.
向量化方式优化searching.
优化前后性能对比
结论
什么是Bihash?
摘抄一段来自VPP官网的描述:
Vpp uses bounded-index extensible hashing to solve a variety of exact-match (key, value) lookup problems. Benefits of the current implementation:
Very high record count scaling, tested to 100,000,000 records.
Lookup performance degrades gracefully as the number of records increases
No reader locking required
Template implementation, it’s easy to support arbitrary (key,value) types
Bounded-index extensible hashing has been widely used in databases for decades.
From: https://s3-docs.fd.io/vpp/23.02/developer/corearchitecture/bihash.html?highlight=bihash

Bihash是如何工作的?
如何获取一个K/V?
实际上,查询一个K/V 可以被描述成如下的图示:

这些操作步骤又可以拆解成这6步:
V = M(O(C (B (H (Key)))))
H(hashing): 根据输入的key,生产hash的功能.
B(bucket): 计算bucket的地址,在它上面存储了一些基础的信息,比如‘offset’ 和‘log2_pages’这些变量会被后续的步骤用到.
C(condition): 检测该bucket下面的状态,如‘lock’, ’offset’, ’log2_page’, 从而决定下一步如何执行.
O(offset): 获取偏移量和标志位为进一步获取KV数组提供参数修正内存地址.
M(match): 根据上述3,选择正确的分支: Linear or log2_pages , 然后进行迭代查询并对key值比较,寻找目标key。
V(value): 如果找到匹配key则返回对应的KV结构.
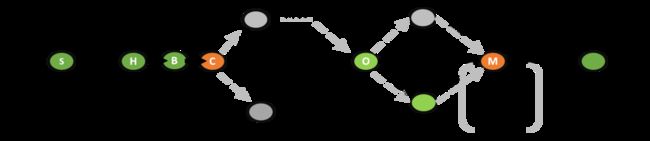
Bihash 查询的几种可能分支
后续你已经注意到了,在‘O’ 这一步后面有3条件路径也反映了不同的bucket地址和不同的KV数组的偏移,为了方便后面的讨论,这里用如下3种类型进行标注:
TYPEI – low collision case--低碰撞case
TYPEII - Log2page case--log2page case
TYPEIII – Linear case--线性case
TYPEI – low collision case
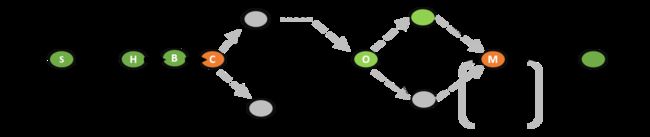
TYPEII - Log2page case
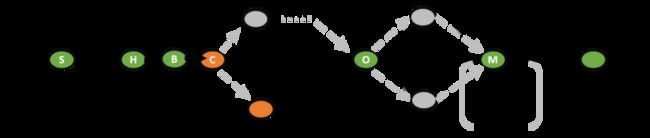
TYPEIII – Linear case
这些类型怎么来的呢?
总的来说,Bihash的算法为了更好管理不同程度的冲突而演进出来的, 不同的冲突程度下,如果平衡内存和性能,从而要求Bihash考虑空闲、普通和高密度的情况下,需要有足够的适应能力。
详细的解释可以参考 VPP’s document(vpp/docs/developer/corearchitecture/bihash.rst):
When sufficient collisions occur to fill the backing pages for a given
bucket, we double the bucket size, rehash, and deal the bucket contents
into a double-sized set of backing pages. In the future, we may
represent the size as a linear combination of two powers-of-two, to
increase space efficiency.
To solve the “jackpot case” where a set of records collide under hashing
in a bad way, the implementation will fall back to linear search across
2**log2_size backing pages on a per-bucket basis.

基础性能表现
每种类型的表现如何?
考虑到每种类型的执行路径有差异可能需要不同的efforts,从而影响到性能结果,这里枚举三种类型的实际情况。首先我们构造用于三种类型的数据集来初始化Bihash,从而使其内部形成对应的存储结构。我的方法约束nbuckets和nItems,控制使用密度从而产生不同程度的碰撞如下图所示:

然后用这个表格的数据对bihash的性能表现进行一个测量,最终得到以下的基准数据表:

Table 1
小结:
1>Bihash 拥有3种不同方式进行管理不同碰撞密度下的KV结构,主要由冲突的程度决定,总体而言越大的数据密度越容易产生碰撞。
2>不同的类型下,查询一个结果需要消耗CPU cycles差异明显,但是在大部分情况下我们使用的都是TYPEII。而这个类型下的表现为74~120已经平均值94.18(cycles/search)。

查询函数的底层指令和CPU微架构的Top-Down分析法
少数上层的开发者会关注到查询函数的底层运作和CPU的指令相关的调度。为了更好的了解CPU的指令行为,我们可以通过使用一个叫‘VPP-TOYS’的工具进行测验,该工具也是由Dmarion实现(Nobody didn’t know in the FD.io community).
这里是测试工具的一个运行截图:

在搞清这些指标前,我们需要学一点CPU指令相关的知识,这里摘抄了两段话,更多请参考(learn more): https://www.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/methodologies/top-down-microarchitecture-analysis-method.html
微架构
The pipeline of a modern high-performance CPU is quite complex. In the simplified view blow, the pipeline is divided conceptually into two halves, the Front-end and the Back-end. The Front-end is responsible for fetching the program code represented in architectural instructions and decoding them into one or more low-level hardware operations called micro-ops(uOps). The uOps are then fed to the Back-end in a process called allocation. Once allocated, the Back-end is responsible for monitoring when uOp’s data operands are available and executing the uOp in an available execution unit. The completion of a uOp’s execution is called retirement, and is where results of the uOp are committed to the architectural state (CPU registers or written back to memory). Usually, most uOps pass completely through the pipeline and retire, but sometimes speculatively fetched uOps may get cancelled before retirement – like in the case of mis-predicted branches.

If the processor is not stalled then a pipeline slot will be filled with a uOp at the allocation point. In this case, the determining factor for how to classify the slot is whether the uOp eventually retires. If it does retire, the slot is classified as Retiring. If it does not, either because of incorrect branch predictions by the Front-end or a clearing event like a pipeline flush due to Self-Modifying-Code, the slot will be classified as Bad Speculation. These four categories make up the top level of the Top-Down Characterization. To characterize an application, each pipeline slot is classified into exactly one of these four categories:
指令与指标

以及如何根据指标判断程序是否被很好的优化:

Table 2
Retiring: 10%->100%, 越高越好
Bad Speculation: 0-10%->100%, 越低越好
Front-End: 0-10%->100%, 越低越好
Back-End: 20%-60% ->100%, 越低越好
回到vpp-toys’s 结果:

Table 3
通过表3,‘Front-End’和‘Speculation’这两个metric有点超出了推荐的指标,也给我们留下了优化的空间,尤其是‘Speculation’。
(推荐另外一个性能分析的工具 tools: Intel® VTune™ Profiler, 比徒手工收集数据和性能分析,提供了更强更便利的GUI 工具)
此外Vtune工具还提供了很多高效,强大的功能,可以分析函数调用的trace,程序热点,性能报表等等丰富的性能分析套件。
(learn more about Vtune: https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler.html)

向量化优化工作流
我们回顾一下这个数据, 并且考虑这两种不同密度的数据集用于分析热点:

哪里出现了热点?显然,C和M就是,C (condition check) 这一步消费了30%的cycles。或许我们可以考虑采用batch处理的方式对工作量进行优化,并在匹的基础上使用AVX512指令进行进一步的并行化优化。
在开始编写代码前,我们分析下可能的优化方案。

基于原先的注解:
V = M(O(C (B (H (Key)))))
很容易的推导出可能存在的优化组合:
Vx8 = Mx8(Ox8(Cx8 (Bx8 (Hx8 (Key)))))
那么如果全部都优化起来, 我们可以得到总计2x2x2x2x2 = 32 个变种的实现。
遗憾的是,大部分的节点是无法合并且需排除的:
For Mx8: Bihash is a template based,由于Bihash是模板里函数,考虑到key value的长短是随意的例如: 8_8, 16_8, 40_8, 并且要在找到目标后需要尽快的返回,而且在实践中如果添加额外的preload 以及 ‘_mm512_cmp_ xxx’ 反而影响到原先的性能,故排除。
For Bx8: 由于load和store的指令会增加额外的cycles。
For Hx8: 最长指令 _mm_crc32_u64. 限制了数据位宽。
剩余
Cx8: clib_bihash_bucket_is_empty => clib_bihash_bucket_is_empty_u64x8。
Ox8: 对linear和log_page2 的分类,有可能存在并行化的操作。
最终,看起来只留下了Cx8 and Ox8这两个节点可以被进一步并行化优化。
为了更容易理解这个过程,这里画了一张插图用来解释形成两个新API的过程。即‘Vec1’ 和‘Vec2’,当然还有一个叫‘Burst’ API这个API有单个查询绑定批处理形成。


优化前后性能对比
采取前面一样的测试数据集,然后根据类型进行优化前后的对比:
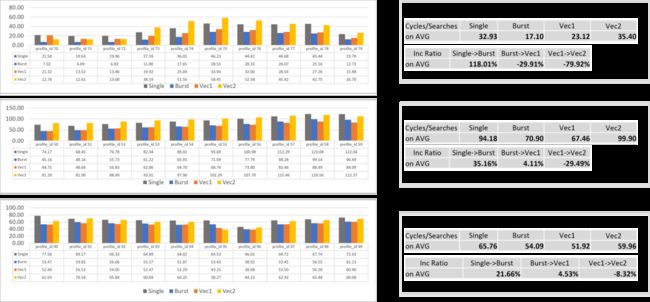
抓出 Figure12的重点数据:
Perf (Single-> Burst): 21.6%~118.01%
Perf (Single-> Vec1): 25.6%~88.01%
Perf (Burst-> Vec1): -30% ~ +4%
从这里,我们是否得出 Vec1 API 拥有最好的性能表现吗?还不行,这里的数据可能会片面,还需要看下底层的实现。
我们重新使用一下 Top-Down 方法:

Clocks/op 作为最重要的指标,但我们把其他相关的4个指令放在同一个表里做分析:

Table 4
小结
批处理‘Burst’在实现上通过汇集相同的操作到一个函数中去,这在某种程度上实现了保持cache的作用,但它也同时带来了overhead,需要调用前准备参数并在输出的结果上进行还原等额外的开销。
通过对比表4中的 ‘Single’ ‘Burst’ and ’Vec1’这几列, 完成相同的查询任务下,‘Single’用了最小的开销,尽管retiring ratio并不是最好, 但是我们可以从 ‘Speculation’ metric找到原因。
排名:Original > Vec1 ≈ Burst。
结论
Bihash 拥有3种不同方式进行管理不同碰撞密度下的KV结构,主要冲突的程度影响,总体而言越大的数据密度越容易产生碰撞,基于目前的采样测试结果中的表现:TYPEI > TYPEIII >TYPEII。
在大部分情况下我们使用的都是TYPEII。而74~120 已经平均值94.18(cycles/search) 可以作为参考的一个性能表现值。
通过对单一查询函数捆绑和填充形成 ‘Burst’的新接口在某种程度有助于保持CPU中的Cache并且带来性能的提升,但是它也会带来新的overhead,在集成中验证下来性能并没有提升。
最终性能排列:Original > Burst > Vec1 > Vec2。换而言之,当前的查询 API 已经非常出色。
Top-down 分析方法,可以更好的了解底层指令以及CPU硬件使用率和发现潜在的优化对象。

Reference
[1] VPP https://s3-docs.fd.io/vpp/23.02/
[2] vpp-toys https://github.com/dmarion/vpp-toys
[3] Top-down method: https://www.intel.com/content/www/us/en/develop/documentation/vtune-cookbook/top/methodologies/top-down-microarchitecture-analysis-method.html
[4] intel-Vtune: https://www.intel.com/content/www/us/en/developer/tools/oneapi/vtune-profiler.html


转载须知
DPDK与SPDK开源社区
公众号文章转载声明
推荐阅读
Secure Access Service Edge Experience Kit 22.05 版本发布
欢迎参加SPDK线上中文讨论会议
Private Wireless Experience Kit 22.04 版本发布
SPDK发布v22.09版本


点点“赞”和“在看”,给我充点儿电吧~