YOLOv5 在 OpenVINO 上的优化实践
基于强大的目标检测能力和较快的推理速度,YOLOv5 已经逐渐成为实时性目标检测任务中的首选模型。因此,YOLOv5 模型的优化和部署是落地任务中非常重要的部分。在 CPU 中部署 AI模型存在着大量的需求,Intel CPU 因其强劲的性能,丰富的软件生态,是我们在 CPU 上部署的首选硬件。本文主要研究了 YOLOv5 模型的知识蒸馏以及在 Intel CPU 上使用 OpenVINO 进行部署优化实践。通过采用知识蒸馏和量化的方法,在不损失精度的条件下,实现了 YOLOv5 模型在 OpenVINO 上 2 倍的推理速度提升。相关代码已开源在Adlik代码库中:https://github.com/Adlik/yolov5
1、知识蒸馏
现有的目标检测蒸馏方法主要对两阶段目标检测(如 RCNN 系列)较为有效,而这些蒸馏方法对于单阶段的目标检测器如 YOLOv5 模型精度几乎没有提升。因此,我们主要采用论文 《Object detection at 200 Frames Per Second》中对单阶段目标检测器的蒸馏方法。该论文研究了单阶段目标检测器使用普通知识蒸馏的问题和面临的挑战。
1.1 Objectness scaled Distillation
单级目标检测方法使用普通知识蒸馏的问题。单阶段目标检测器的预测是一个密集的候选集合。老师网络(YOLO 模型)预测图像背景区域中的边界框。在推理过程中,背景区域预测的边界框会被忽略。然而,标准的蒸馏方法会将这些背景检测转移到了学生模型学习中。它会影响边界框的训练 ,因为学生网络会从老师网络预测的背景区域中学习错误的边界框。两阶段的目标检测方法(如 RCNN)通过使用 RPN 网络来规避这个问题,因为 RPN 网络预测相对较少的候选区域。为了避免学习老师网络对背景区域的预测,论文中定义蒸馏损失为 objectness scaled function。其思想学生网络只学习老师网络预测的目标概率值较高的边界框位置和类别概率。
YOLO 目标损失函数由三部分组成:regression loss(回归损失函数), objectness loss (目标损失函数)和 classification loss(分类损失函数)。
目标损失函数部分不需要目标缩放,因为对于背景区域的预测的目标概率值比较低,因此,知识蒸馏的目标损失函数定义如下:
学生网络的目标缩放分类函数:
其中,上述损失函数的第一部分对应原始的目标分类损失函数,而第二部分是目标分类蒸馏损失部分。学生网络的目标缩放边界框位置损失函数:
402 Payment Required
老师网络将非常低的目标概率值作为大多数与背景相对应的预测框的权重。基于目标函数的缩放算法是一种用于单阶段目标检测器中蒸馏过滤器的缩放算法,因为该算法分配给背景预测框的权值很低。损失函数形式保持不变,但对于知识蒸馏损失函数,只是用老师网络的输出代替标签值。训练阶段总的损失函数为:
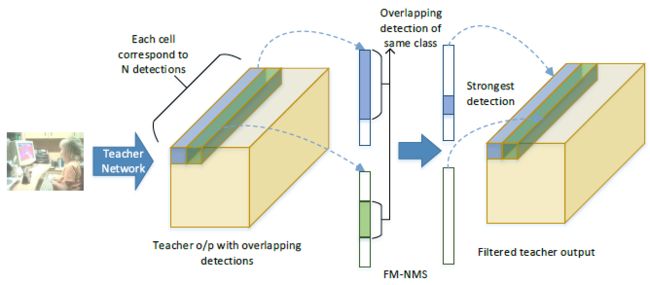
1.2 Feature Map-NMS
单级目标检测方法蒸馏时面临的挑战: 该网络经过训练,可以从一个单元的单个锚定框(anchor)预测一个框,但实际上,许多单元和锚定框最终会预测图像中的同一对象。因此,NMS 作为目标检测器中的后处理步骤是必不可少的。然而,NMS 步骤应用于端到端网络架构之外,高度重叠的预测仍然会在目标检测器的最后卷积层中表示。当这些预测从老师网络转移到学生网络时,会产生冗余信息。因此,上述蒸馏损失导致性能损失,因为老师网络最终传输高度重叠检测的信息损失
为了克服重叠检测带来的问题,论文提出了 Feature Map-NMS (FM-NMS)。该方法的思想是,如果 单元邻域中的多个候选框对应于同一类别,则它们很可能对应于图像中的相同目标。因此,我们只选择一个具有最高的目标概率值的候选框。我们检查最后一层特征图中对应于类别概率(是指 objectness 还是 class 的概率)的激活,将对应于同一类别的激活设置为零。
2、在 OpenVINO 上的量化
2.1 OpenVINO 量化工具介绍
从 OpenVINO 2020.1 发行版开始,所有量化模型使用所谓的 FakeQuantize 层来表示,这个层是一个具有表现力的原语,能够表示 Quantize、Dequantize、Requantize 等等运算。该运算在量化过程中被插入到模型中,旨在存储层的量化参数。为了执行这种“假量化”模型,OpenVINO 有一个低精度运行时,它是推理引擎的一部分,由一个将模型转换为实整数表示的通用组件和在相应硬件插件中实施的硬件特定部分组成。
OpenVINO 提供两种量化工具,对应两种不同的量化方式:
训练后优化工具 (POT),OpenVINO 工具套件本身的一部分。
神经网络压缩框架 (NNCF),构建在 PyTorch 框架之上的独立工具,与 OpenVINO 高度一致。
模型优化工作流程,它包含两个主要组件:训练后量化和量化感知训练(QAT)。第一个组件是获得优化模型的最简单方法,当第一个组件无法给出准确结果时,可以将后者视为替代或补充。

Step 0:模型启用。在此步骤,我们应当确保在目标数据集上训练的模型可以使用浮点精度的 OpenVINO 推理引擎实现成功推理。此过程需要使用模型优化器工具,将模型从源框架转换为 OpenVINO 中间表示 (IR),并使用推理引擎在 CPU 上运行。
Step 1:训练后量化。作为优化的第一步,我们建议使用来自 POT 的 INT8 量化,在大多数情况下可以获得准确的量化模型。在这一步,您不需要重新训练模型。唯一需要的是一个有代表性的数据集,通常是数百张图像,用于在量化过程中收集统计数据。训练后量化也非常快,通常需要几分钟,具体取决于模型大小和使用的硬件。
Step2:量化感知训练:如果量化模型的精度不满足精度标准,则有第二步,这意味着使用与 OpenVINO 兼容的训练框架进行 QAT。在此步骤,我们假设用户拥有一个在 TensorFlow* 或 PyTorch* 上编写的模型的原始训练管道。在这一步之后,您可以获得一个准确的优化模型,该模型可以使用模型优化器组件转换为 OpenVINO 中间表示 (IR),并使用 OpenVINO 推理引擎进行推理。
POT 源文件在镜像中的位置:
2.2 训练后量化工具 (POT)
训练后优化 (POT) 不需要训练,只需要:
浮点精度模型 FP32 或 FP16,转换为 OpenVINO™ 中间表示 (IR) 格式并使用 OpenVINO™ 在 CPU 上运行。
一个代表用例场景的代表性校准数据集,例如 300 张图像。
目前,POT 提供了两种 8 位量化算法:
DefaultQuantization 是一种默认方法,可以为 8 位量化提供快速且在大多数情况下准确的结果。有关详情,请参阅 DefaultQuantization 算法文档。
AccuracyAwareQuantization 以性能改进为代价,在量化后保持在预定义的精度下降范围内。可能需要更多时间进行量化。有关详情,请参阅 AccuracyAwareQuantization 算法文档。
树结构 Parzen 估计器 (TPE) 与 AccuracyAwareQuantization 相似,以性能改进为代价,能够保持在预定义的精度下降范围内,但会额外尝试提供最佳可能的性能改进。与 AccuracyAwareQuantization 相比,需要更多的时间进行量化,但可能获得更好的性能改进。有关详情,请参阅树结构 Parzen 估计器 (TPE)文档。
2.3 使用 POT 对 yolov5s 模型进行量化
由于 yolov5 没有直接可用的精度检测器。因此我们首先选择 DefaultQuantization 算法的 simplified 模式,其只需要提供校准数据集。我们测试了 preset 的两种模式:performance 和 mixed。performance(默认)代表权重和激活的对称量化,这是在所有硬件中性能最高的。mixed 代表权重的对称量化和激活的非对称量化,此模式可用于 NN 的量化,NN 在量化操作中具有负输入值和正输入值,例如基于非 ReLU 的 CNN。根据我们在两种模式上的测试数据,mixed 对于非 ReLU 的 CNN 模型具有更高的精度。
如果只使用 DefaultQuantization 算法的 simplified 模式进行量化,模型的精度损失较大,对于 yolov5s 量化后最好的精度 mAP = 34.0%,仍有 3.2% 的精度损失。通过一些系列实验的分析,yolov5 在推理时导出的模型 Detect 层对输出进行了后处理,后处理中存在较多的 Mul、Add 和 Pow 算子,如下图所示,对这部分算子进行量化使得模型精度损失较大。
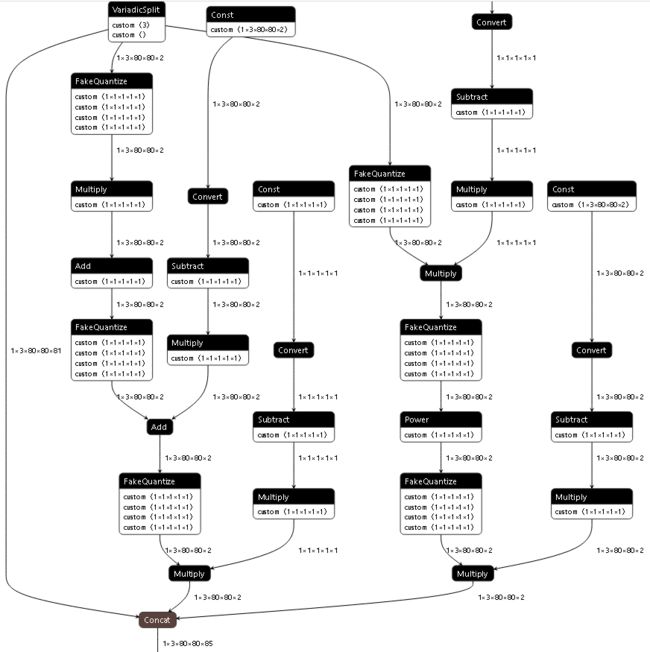
因此,我们将导出模型的 Detect 层的后处理部分不使用量化,同时实验结果表明,该部分不进行量化对推理速度基本没有影响,相比原始模型,量化后模型精度只损失 0.7%。最终的量化配置如下:
{
"model": {
"model_name": "yolov5s",
"model": "./yolov5s.xml",
"weights": "./yolov5s.bin"
},
"engine": {
"type": "simplified",
"data_source": "/root/work/Object_detection/datasets/coco_calib" // 校准数据集路径
},
"compression": {
"algorithms": [
{
"name": "DefaultQuantization",
"params": {
"preset": "mixed",
"stat_subset_size": 1000, // Not less than 300,
"ignored": {
"scope": ["Mul_222","Add_226", "Mul_228", "Mul_235", "Pow_237","Mul_239", "Mul_347",
"Mul_276","Add_280", "Mul_282","Mul_289","Pow_291","Mul_293", "Mul_330","Add_334",
"Mul_336","Mul_343","Pow_345","Mul_347"]
}
}
}
]
}
}3、实验结果
3.1 知识蒸馏
在 COCO2017 数据集上训练和测试。我们使用 8 块 V100 GPU,batch size = 256,epochs = 1000。
| Student model | Teacher model | Input size [h, w] |
mAPval 0.5:0.95 |
|---|---|---|---|
| yolov5s | baseline | [640, 640] | 37.2 |
| yolov5s | yolov5m | [640, 640] | 39.3 |
上表是我们测试的蒸馏结果,我们使用 yolov5m 作为老师网络,对 yolov5s 模型进行蒸馏,训练使用 1000 epochs,模型精度提升 2.1%。
3.2 量化
测试环境: Intel(R) Xeon(R) Platinum 8260 CPU,异步推理采用 12 个线程。
| CPU 型号 | 物理 CPU 个数 | 每个物理 CPU 的 core 数 | 逻辑 CPU 个数 |
|---|---|---|---|
| Intel(R) Xeon(R) Platinum 8260 CPU | 2 | 24 | 96 |
POT 中 DefaultQuantization 算法采用不同的量化模式的实验结果
| INT8 量化方式 | 同步 Latency (ms) | 异步 Latency (ms) | mAP |
|---|---|---|---|
| performance | 7.31 | 24.97 | 32.6 |
| mixed | 6.93 | 24.89 | 34.0 |
| mixed, use_fast_bias=false | 7.18 | 25.05 | 33.6 |
| mixed, ignored Mul_222,... | 6.56 | 24.07 | 36.5 |
yolov5s 模型优化后的精度对比
| Model | Compression strategy |
Input size [h, w] |
mAPval 0.5:0.95 |
|---|---|---|---|
| yolov5s | baseline | [640, 640] | 37.2 |
| yolov5s | quantization | [640, 640] | 36.5 |
| yolov5s | distillation + quantization | [640, 640] | 38.6 |
yolov5s 不同数据类型和模型文件类型推理时间
| Model | Type | Inputs [b, c, h, w] |
CPU Latency (sync) |
CPU Latency (async) |
CPU FPS (sync) |
CPU FPS (async) |
|---|---|---|---|---|---|---|
| yolov5s | FP32, onnx | [1, 3, 640, 640] | 15.72 ms | 58.25 ms | 63.61 | 204.19 |
| yolov5s | FP32, IR | [1, 3, 640, 640] | 12.95 ms | 55.53 ms | 77.22 | 215.39 |
| yolov5s | INT8, IR | [1, 3, 640, 640] | 6.56 ms | 24.07 ms | 152.51 | 497.28 |
4、未来展望
虽然对 yolov5s 模型的蒸馏有一定的效果,但其训练时间较长。未来将继续研究更高效的单阶段目标检测模型知识蒸馏方法。
下一阶段,我们将继续研究 YOLOv5 模型在 Intel CPU 上使用 OpenVINO 进行部署优化,并实现 3 倍推理速度的提升。
我们的模型都可以在 Adlik Serving 上进行快速部署。希望大家试用和验证。
参考文献
[1] Mehta R, Ozturk C. Object detection at 200 frames per second[C]//Proceedings of the European Conference on Computer Vision (ECCV) Workshops. 2018: 0-0. [2] https://docs.openvino.ai/cn/latest/pot_docs_BestPractices.html [3] https://docs.openvino.ai/latest/index.html
Adlik 等你来关注!

Adlik Github代码仓库

Adlik微信交流群