【论文笔记】Ripple Net:融合知识图谱的推荐模型
“ 本文介绍了一种融合知识图谱进行用户兴趣偏好预测的方法Ripple Net”
文章来源:RecLismCat https://zhuanlan.zhihu.com/p/96126747
为了解决协同过滤的稀疏性和冷启动问题,研究人员通常利用社会网络或项目属性等侧信息来提高推荐性能。本文将知识图作为边信息的来源。为了解决现有基于嵌入和基于路径的知识图感知推荐方法的局限性,我们提出了RippleNet,这是一种端到端的框架,它自然地将知识图合并到推荐系统中。与在水面上传播的实际涟漪类似,「RippleNet通过沿着知识图中的链接自动、迭代地扩展用户的潜在兴趣,从而刺激用户对一组知识实体的偏好的传播。因此,由用户以往单击过的项目激活的多个“涟漪”叠加起来,形成用户相对于候选项目的偏好分布,该分布可用于预测最终的单击概率。」通过对真实数据集的大量实验,我们证明了RippleNet在多个最先进的基线上,在各种场景(包括电影、书籍和新闻推荐)中取得了巨大的收益。
据我们所知,这是在kg感知推荐中结合基于嵌入和基于路径的方法的第一个工作。我们提出了RippleNet,这是一个利用KG来辅助推荐系统的端到端框架。
RippleNet通过在KG中迭代传播用户首选项,自动发现用户分层潜在兴趣。
我们在三个真实的推荐场景中进行了实验,结果证明了RippleNet在几个最先进的基线上的有效性。
问题形式化
一个典型推荐系统中,令U=u1,u2,...,}和V={v1,v2,...}分别定义为用户集和物品集。User- item交互矩阵Y={yuvu∈U,v∈V是根据用户的隐式反馈定义的:

除了交互矩阵Y之外,我们还有一个可获得的知识图G=(E,R),它包含了大量“实体-关系- 实体”的三元组(g,r,t)。其中,h∈E,r∈R,t∈E分别是head,relation和tail。E和R定义了知识图中的实体集和关系集。在许多推荐场景中,数据集的一个物品对应着更多KG中的实体。例如,用户所点击的一个新闻标题为“震惊!法国的一个熊猫生了宝宝”则对应于图内的法国和熊猫两个实体。
在已知交互矩阵Y和知识图G的情况下,我们的目标是预测use ru是否对item v有潜在的兴趣,而useru之前从未与itemv有过交互。我们的目标是学习预测函数
, 其中,
表示用户u将点击物品v的概率 , Θ表示函数F的模型参数。
RippleNet网络结构
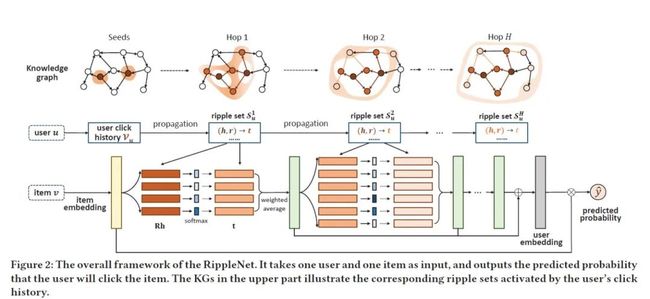
Input:user u 和 item v
Output:user u 将要点击item v 的概率
对于输入的user u,它的偏好历史集合Vu被视作是KG中的seeds,然后沿着连接扩散,形成多个ripplesets
。一个ripple set是来自seed set Vu的一组k- hops知识三元组的子集。这些rippleset与item嵌入(黄色块)迭代交互,获得用户u对项目v(绿色块)的响应,然后将这些响应组合成最终的用户嵌入(灰色块)。最后,我们使用用户u和项目v的嵌入来计算预测概率。
定义1(相关实体):给出用户的交互矩阵Y和知识图G,k-hop相关实体的集合可以被定义为如下形式:
其中,
表示用户过去点击物品的历史,也就是KG当中的seeds。
相关实体可以被视为用户对KG的历史兴趣的自然扩展。根据相关实体的定义,定义用户u的k-hop ripple集合如下:
定义2:(ripple set):用户u的k-hop ripple set 被定义为从
开始的知识三元组集合:
“ripple”这个词有两层含义:
与多个雨滴产生的真实涟漪类似,用户对实体的潜在兴趣被其历史偏好激活,然后沿着KG中的连接从近到远逐层传播。我们通过图3中所示的同心圆来可视化这个类比。
随着跳数k的增加,用户在纹波集合中的潜在偏好强度逐渐减弱,这与真实纹波振幅逐渐衰减相似。图3中渐褪的蓝色显示了中心和周围实体之间不断减少的关联性。
关于纹波集的一个问题是,随着跳数k的增加,它们的大小可能会变得太大。要解决这个问题,请注意:
(1) 实际KG中的大量实体是sink实体,这意味着它们只有传入链接而没有传出链接,如图3中的“2004”和“PG-13”。
(2) 在特定的推荐场景中,如电影或书籍推荐,可以将关联限制在与场景相关的类别中,以减少ripple集合的大小,提高实体之间的相关性。例如,在图3中,所有关系都与电影相关,并在它们的名称中包含单词“film”。
(3)实践中,最大跳数H通常不是太大,因为与用户历史距离太远的实体可能比正信号带来更多的噪声。我们将在实验部分讨论H的选择。(4)在RippleNet中,我们可以抽样一个固定大小的邻居集合,而不是使用一个完整的ripple集合,从而进一步减少计算开销。设计这样的采样器是未来工作的一个重要方向,特别是为了更好地捕捉用户的层次潜在兴趣而设计的非均匀采样器。
「偏好传播」
传统的基于cf的方法及其变体学习用户和项目的潜在表示,然后通过直接将特定函数应用于用户和项目的表示(如内积)来预测未知的评级。在RippleNet中,为了以更细粒度的方式对用户和项之间的交互进行建模,我们提出了一种偏好传播技术,以探索用户在其ripple集合中的潜在兴趣。
如图2,每一个item v 都与一个item嵌入v ∈ Rd 关联,d是嵌入维度。在一个应用场景下,Item嵌入可以合并一个物品的ID,属性,词包的one- hot或上下文信息。给出item嵌入 v 和用户的1-hop的rippe set,通过将item v与这个三元组的head hi,relation ri 进行比较,Su1中的每一个三元组(hi,ri,ti)都被赋予了一个相关概率:
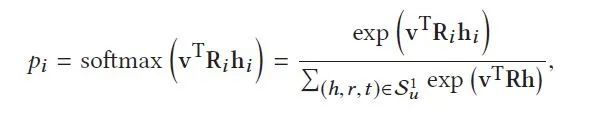
在得到了这样的一个相关概率后,注意计算时需要考虑嵌入矩阵Ri,计算项目v与实体hi的相关性时需要考虑嵌入矩阵Ri,因为item- 实体对在通过不同关系度量时可能具有不同的相似性。例如,《阿甘正传》(Forrest Gump)和《荒山余生》(Cast Away)在考虑导演或明星时高度相似,但如果以体裁或作家来衡量,它们的共同点就少了。
在得到关联概率后,我们将S1u中tail之和乘以相应的关联概率,得到向量o1u:
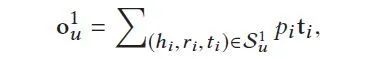
考虑tail的物理意义:例如,(张杰,唱歌,明天过后)& (张杰,唱歌,我是歌手)
可以被看做是用户u的点击历史Vu中关于item v的一个1阶反馈。这本质上和基于item的CF很相似。
通过上述过程,用户的兴趣从他的历史数据集Vu转移到
中link的1跳相关实体
的集合,这在RippleNet中称为偏好传播。
通过将V替换为
,我们可以重复这个偏好传播过程来得到用户的二阶响应
,以此迭代。因此,一个用户的偏好从他的历史点击序列传播到了H hop的距离,我们可以用户u在不同阶上的多种反馈:
。然后,结合所有的o来计算 user u的嵌入向量:
注意,虽然最后一跳
的用户响应理论上包含了前一跳的所有信息,但在计算用户嵌入时仍有必要考虑小跳k的
,因为它们可能会被
稀释。最后,将用户嵌入和项目嵌入相结合,输出预测的点击概率,激活函数为sigmoid:
完)

