Sklearn学习笔记3 model_selection模块
3 Model selection and evaluation
- 1 sklearn.model_selection: Model Selection
-
- 1.1 Splitter Classes(分组)
- 1.2 Splitter Functions(拆分训练集与测试集)
- 1.3 Hyper-parameter optimizers(超参数优化)
- 1.4 Model validation(模型验证)
- 1.5 验证曲线:绘制分数来评价模型
- 2 Evaluation:Metrics and scoring
- 2.1 scoring参数:定义模型评价规则
-
-
- 2.1.1 常见情况:预定义值
- 2.1.2. 通过度量函数定义得分策略
- 2.1.3. 实现自己的计分对象
- 2.1.4. 使用多个度量评估
- 2.2 分类指标
- 2.3 多标签排名指标
- 2.4 回归指标
- 2.5 聚类指标
- 2.6 虚假估算器(Dummy estimators)
-
https://scikit-learn.org/stable/modules/classes.html#module-sklearn.model_selection
用户指南:请参阅交叉验证:评估估计器性能,调整估计器的超参数和 学习曲线部分,以了解更多详细信息。
1 sklearn.model_selection: Model Selection
1.1 Splitter Classes(分组)

1.2 Splitter Functions(拆分训练集与测试集)
![]()
1.3 Hyper-parameter optimizers(超参数优化)

某些模型可以为某个参数的某个值范围拟合数据,其效率几乎与为一个参数的单个值拟合估算值的效率相同。可以利用此功能来执行更有效的交叉验证,以用于此参数的模型选择。
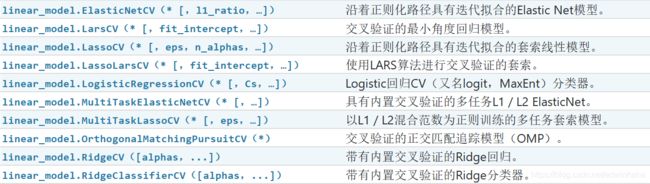
1.4 Model validation(模型验证)

1.5 验证曲线:绘制分数来评价模型
![]()
2 Evaluation:Metrics and scoring
https://scikit-learn.org/stable/modules/model_evaluation.html#
有3种不同的API可用于评估模型预测的质量:
- 估计器评分方法:估计器score提供了一种方法,用于为其设计要解决的问题提供默认的评估标准。本页中没有讨论此问题,但是每个估算器的文档中都对此进行了讨论。
- 评分参数:使用交叉验证(例如 model_selection.cross_val_score和 model_selection.GridSearchCV)的模型评估工具 依赖于内部评分策略。在评分参数:定义模型评估规则一节中对此进行了讨论。
- 指标功能:该metrics模块实现了针对特定目的评估预测误差的功能。这些度量在“ 分类”度量,“ 多标签排名”度量,“ 回归”度量和“ 聚类”度量的各节中详细介绍。
最后,虚拟估计器对于获取这些度量的基准值以进行随机预测很有用。
2.1 scoring参数:定义模型评价规则
模型选择和评估使用工具,如 model_selection.GridSearchCV和 model_selection.cross_val_score,取一scoring参数,用于评估估计什么指标控制。
2.1.1 常见情况:预定义值
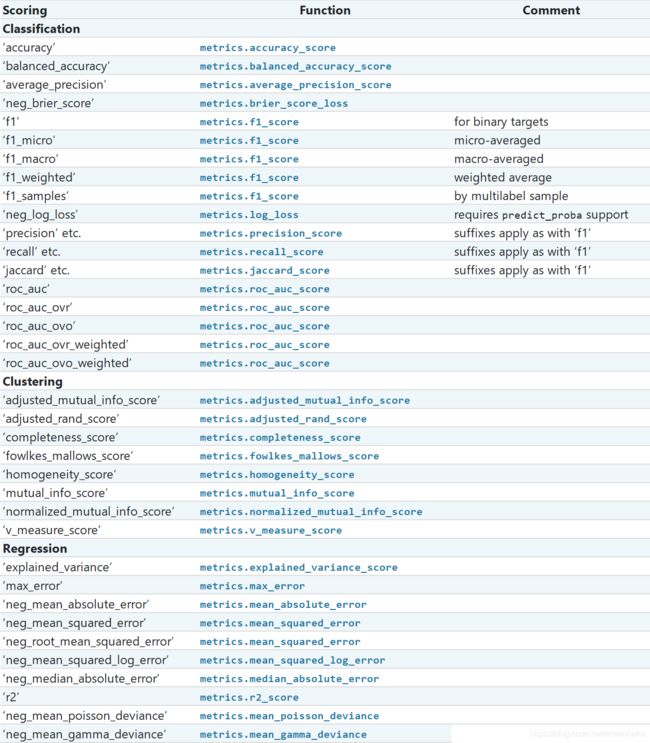
2.1.2. 通过度量函数定义得分策略
该模块sklearn.metrics还提供了一组简单的函数,这些函数在给定地面真实性和预测的情况下测量预测误差:
- 以结尾的函数_score返回一个最大化的值,越高越好。
- 以结尾_error或_loss返回值最小化的函数,值越低越好。使用转换为得分手对象时make_scorer,将greater_is_better参数设-置为False(默认为True;请参见下面的参数说明)。
以下各节详细介绍了可用于各种机器学习任务的指标。
许多度量未指定名称用作scoring值,有时是因为它们需要其他参数,例如 fbeta_score。在这种情况下,您需要生成一个适当的计分对象。生成可计分对象进行评分的最简单方法是使用make_scorer。该函数将指标转换为可用于模型评估的可调用对象。
一种典型的用例是使用非默认值为其参数包装库中的现有度量标准函数,例如beta该fbeta_score函数的参数:
>>> from sklearn.metrics import fbeta_score, make_scorer
>>> ftwo_scorer = make_scorer(fbeta_score, beta=2)
>>> from sklearn.model_selection import GridSearchCV
>>> from sklearn.svm import LinearSVC
>>> grid = GridSearchCV(LinearSVC(), param_grid={'C': [1, 10]},
... scoring=ftwo_scorer, cv=5)
第二个用例是使用make_scorer,从一个简单的python函数构 建一个完全自定义的Scorer对象,该函数可以采用多个参数:
- 您要使用的python函数(my_custom_loss_func 在下面的示例中)
- python函数返回分数(greater_is_better=True默认值)还是损失(greater_is_better=False)。如果丢失,则计分器对象将否定python函数的输出,这符合交叉验证约定,即计分器返回较高的值以获得更好的模型。
- 仅适用于分类指标:您提供的python函数是否需要持续的决策确定性(needs_threshold=True)。默认值为False。
- 任何其他参数,例如beta或labels中f1_score。
以下是构建自定义评分器并使用greater_is_better参数的示例 :
>>> import numpy as np
>>> def my_custom_loss_func(y_true, y_pred):
... diff = np.abs(y_true - y_pred).max()
... return np.log1p(diff)
...
>>> # score will negate the return value of my_custom_loss_func,
>>> # which will be np.log(2), 0.693, given the values for X
>>> # and y defined below.
>>> score = make_scorer(my_custom_loss_func, greater_is_better=False)
>>> X = [[1], [1]]
>>> y = [0, 1]
>>> from sklearn.dummy import DummyClassifier
>>> clf = DummyClassifier(strategy='most_frequent', random_state=0)
>>> clf = clf.fit(X, y)
>>> my_custom_loss_func(clf.predict(X), y)
0.69...
>>> score(clf, X, y)
-0.69...
2.1.3. 实现自己的计分对象
您无需使用make_scorer工厂就可以从头开始构建自己的评分对象,从而生成更加灵活的模型评分器。要使可呼叫者成为记分员,它需要满足以下两个规则所指定的协议:
- 可以使用参数调用,其中 是应该评估的模型,是验证数据,是(在有监督情况下)或(在无人监督情况下)的地面真实目标。(estimator, X, y)estimatorXyXNone
- 它返回一个浮点数,该浮点数参考来量化 estimator预测质量。同样,按照惯例,数字越大越好,因此,如果您的计分员返回亏损,则该值应为负。Xy
>>> from custom_scorer_module import custom_scoring_function
>>> cross_val_score(model,
... X_train,
... y_train,
... scoring=make_scorer(custom_scoring_function, greater_is_better=False),
... cv=5,
... n_jobs=-1)
2.1.4. 使用多个度量评估
Scikit学习也允许在多个指标的评估GridSearchCV, RandomizedSearchCV和cross_validate。
有两种方法可以为scoring 参数指定多个评分指标:
- 作为字符串度量的可迭代项:
>>> scoring = ['accuracy', 'precision']
- 作为一个dict映射得分手名字打分函数::
>>> from sklearn.metrics import accuracy_score
>>> from sklearn.metrics import make_scorer
>>> scoring = {'accuracy': make_scorer(accuracy_score),
... 'prec': 'precision'}
请注意,字典值可以是记分器功能或预定义的度量标准字符串之一。
当前,只有返回单个分数的那些计分器函数才能在dict中传递。不允许返回多个值的记分器函数,并且需要包装器返回单个度量标准:
>>> from sklearn.model_selection import cross_validate
>>> from sklearn.metrics import confusion_matrix
>>> # A sample toy binary classification dataset
>>> X, y = datasets.make_classification(n_classes=2, random_state=0)
>>> svm = LinearSVC(random_state=0)
>>> def tn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 0]
>>> def fp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[0, 1]
>>> def fn(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 0]
>>> def tp(y_true, y_pred): return confusion_matrix(y_true, y_pred)[1, 1]
>>> scoring = {'tp': make_scorer(tp), 'tn': make_scorer(tn),
... 'fp': make_scorer(fp), 'fn': make_scorer(fn)}
>>> cv_results = cross_validate(svm.fit(X, y), X, y, cv=5, scoring=scoring)
>>> # Getting the test set true positive scores
>>> print(cv_results['test_tp'])
[10 9 8 7 8]
>>> # Getting the test set false negative scores
>>> print(cv_results['test_fn'])
[0 1 2 3 2]
2.2 分类指标
其中一些仅限于二进制分类的情况:
![]()
其他也可以在多类情况下工作:

有些在多标签的情况下也可以使用:

还有一些解决二进制和多标签(但不是多类)问题的方法:
![]()
2.3 多标签排名指标

2.4 回归指标
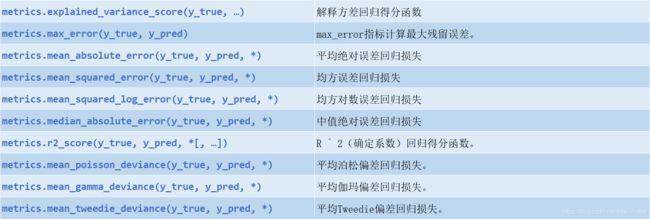
2.5 聚类指标
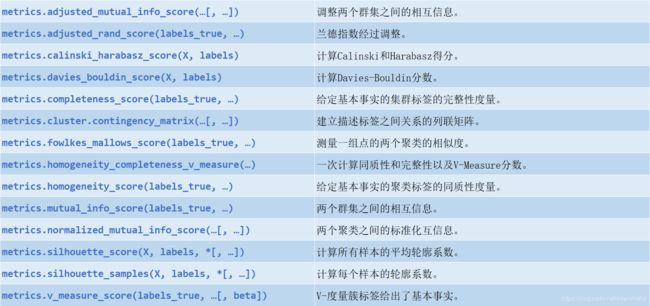
2.6 虚假估算器(Dummy estimators)
**包含DummyClassifier和DummyRegressor。**提供了简单的分类和回归策略。其他算法如果效果不如Dummy estimators或与之相当,则说明有问题:如模型选择不正确/超参数未正确调整/数据不平衡等。
在进行监督学习时,简单的健全性检查包括将自己的估计量与简单的经验法则进行比较。DummyClassifier 实现几种简单的分类策略:
- stratified 通过遵守训练集类别分布来生成随机预测。
- most_frequent 总是预测训练集中最频繁的标签。
- prior总是预测使该类优先级最大化的类(例如most_frequent)并predict_proba返回该类优先级。
- uniform 随机均匀地生成预测。
- constant 总是预测用户提供的恒定标签。这种方法的主要动机是当阳性类别为少数时,进行F1评分。
请注意,使用所有这些策略,该predict方法将完全忽略输入数据!
为了说明这一点DummyClassifier,首先让我们创建一个不平衡的数据集:
>>> from sklearn.datasets import load_iris
>>> from sklearn.model_selection import train_test_split
>>> X, y = load_iris(return_X_y=True)
>>> y[y != 1] = -1
>>> X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
接下来,让我们比较的准确性SVC和most_frequent:
>>> from sklearn.dummy import DummyClassifier
>>> from sklearn.svm import SVC
>>> clf = SVC(kernel='linear', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.63...
>>> clf = DummyClassifier(strategy='most_frequent', random_state=0)
>>> clf.fit(X_train, y_train)
DummyClassifier(random_state=0, strategy='most_frequent')
>>> clf.score(X_test, y_test)
0.57...
我们看到这SVC并没有比虚拟分类器好得多。现在,让我们更改内核:
>>> clf = SVC(kernel='rbf', C=1).fit(X_train, y_train)
>>> clf.score(X_test, y_test)
0.94...
我们看到准确性提高到几乎100%。如果CPU成本不是很高,建议使用交叉验证策略以更好地估计准确性。有关更多信息,请参见“ 交叉验证:评估估计器性能” 部分。此外,如果要在参数空间上进行优化,强烈建议使用适当的方法。 有关详细信息,请参见调整估计器的超参数部分。
更一般而言,当分类器的准确性太接近随机性时,这可能意味着出了点问题:功能无济于事,超参数未正确调整,分类器正遭受类不平衡之苦,等等……
DummyRegressor 还实现了四个简单的回归经验法则:
- mean 总是预测训练目标的平均值。
- median 总是预测训练目标的中位数。
- quantile 总是预测用户提供的训练目标的分位数。
- constant 总是预测用户提供的恒定值。
在所有这些策略中,该predict方法完全忽略了输入数据。