MindSpore实现生成对抗网络(1)
MindSpore实现生成对抗网络-GAN (1)
生成对抗网络(GAN)问世已经有好几年的时间了,其属于生成模型的一种,是现在比较热门的一个研究方向。GAN由两个部分组成——判别器和生成器。生成器用于生成样本,判别器判断其输入样本是真实的还是生成的。Mindspore是一个新生的AI框架,相关的资源较少,所以考虑用MindSpore实现一些简单的GAN来作为一个MindSpore相关的教程,算是给MindSpore社区贡献一点点代码。
暂时考虑写3篇相关的教程:
1.使用简单的GAN生成高斯分布
2.使用DCGAN生成MNIST手写数字
3.使用CGAN生成MNSIT手写数字
使用简单的GAN生成高斯分布
先完成一个简单的,用GAN生成服从均值为0,方差为1的一维高斯分布的数据。
关于GAN的基本理论,网上能够找到很多的讲解,所以,这里不再对原理做相关的介绍,而是侧重于怎么用Mindspore框架实现GAN的相关算法。总的来说,Gan是一种通过对抗的方式去学习训练数据分布的生成模型。首先,它包含两个网络,一个叫做判别器,另一个叫生成器。顾名思义,生成器的作用是生成我们想要的数据,判别器的作用是判断数据是生成的还是真实的。训练时,生成器尽可能生成逼真的样本去欺骗判别器,判别器网络则尽可能去判断输入的样本是真实样本还是生成样本。二者就在这样的相互对抗过程当中训练提升自己的性能,如下所示(latent code是生成器的输入,通常为随机噪声)。

各个模块的设计
所使用的mindspore版本为GPU-1.0。这里建议使用conda安装或者使用docker。
先导入会用到的包
from mindspore import nn
from mindspore import Tensor
from mindspore.common import dtype as mstype
from mindspore import context
import mindspore.ops.operations as P
import mindspore.ops.functional as F
import mindspore.ops.composite as C
from mindspore.parallel._utils import (_get_device_num, _get_gradients_mean,
_get_parallel_mode)
from mindspore.context import ParallelMode
from mindspore.nn.wrap.grad_reducer import DistributedGradReducer
import os
import numpy as np
import matplotlib.pyplot as plt
1.判别器和生成器
这一步没有太多要说的,使用简单的全连接网络就可以获得不错的效果。判别器判断一个样本的真假,可以视作一个二分类任务,所以其输出只有一个单值,表示这个样本是真的概率。因为接下来定义的损失函数会对输出做sigmoid运算,所以判别器输出层不使用Sigmoid激活。
class Discriminator(nn.Cell):
def __init__(self, hidden_dim, auto_prefix=True):
super().__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell([
nn.Dense(1, hidden_dim),
nn.LeakyReLU(),
nn.Dense(hidden_dim, 1)
])
def construct(self, x):
return self.model(x)
class Generator(nn.Cell):
def __init__(self, input_dim, hidden_dim, auto_prefix=True):
super().__init__(auto_prefix=auto_prefix)
self.model = nn.SequentialCell([
nn.Dense(input_dim, hidden_dim),
nn.ReLU(),
nn.Dense(hidden_dim, 1)
])
def construct(self, x):
return self.model(x)
2.损失函数
根据判别器的结构,我们使用Sigmoid交叉熵损失作为损失函数。但是mindspore的官方实现里没有这个Cell,所以可以自定义一个。
class SigmoidCrossEntropyWithLogits(nn.loss.loss._Loss):
def __init__(self):
super().__init__()
self.cross_entropy = P.SigmoidCrossEntropyWithLogits()
def construct(self, data, label):
x = self.cross_entropy(data, label)
return self.get_loss(x)
3.WithLossCell
mindspore将损失函数,优化器等操作都封装到了Cell中。以当前版本的框架来说,这种设计给实现GAN带来了一些不方便。因为GAN结构上的特殊性,它和一般的分类网络不同,损失由判别器损失和生成器损失组成,是多输出的。如果用官方包提供的Cell,框架会不知道Loss和网络是如何连接的,会导致无法训练。所以,我们需要自定义WithLossCell,将网络和Loss连接起来。
用1表示真标签,代表这个样本是真实样本。反之,0表示假标签,代表这个样本是生成样本。这里直接将标签写到了计算图的构造当中,也可以将标签作为construct的参数,训练的时候手动传入标签。
class GenWithLossCell(nn.Cell):
def __init__(self, netG, netD, loss_fn, auto_prefix=True):
super(GenWithLossCell, self).__init__(auto_prefix=auto_prefix)
self.netG = netG
self.netD = netD
self.loss_fn = loss_fn
def construct(self, latent_code):
fake_data = self.netG(latent_code)
fake_out = self.netD(fake_data)
loss_G = self.loss_fn(fake_out, F.ones_like(fake_out))
return loss_G
class DisWithLossCell(nn.Cell):
def __init__(self, netG, netD, loss_fn, auto_prefix=True):
super(DisWithLossCell, self).__init__(auto_prefix=auto_prefix)
self.netG = netG
self.netD = netD
self.loss_fn = loss_fn
def construct(self, real_data, latent_code):
fake_data = self.netG(latent_code)
real_out = self.netD(real_data)
real_loss = self.loss_fn(real_out, F.ones_like(real_out))
fake_out = self.netD(fake_data)
fake_loss = self.loss_fn(fake_out, F.zeros_like(fake_out))
loss_D = real_loss + fake_loss
return loss_D
4.TrainOneStepCell
有了上面的定义的WithLossCell之后,就可以使用官方包里的TrainIOneStepCell训练网络。但是需要分别为判别器和生成器定义一个TrainOneStepCell,这样训练比较灵活。也可以自己实现TrainOneStepCell,直接将判别器和生成器的训练封装到一起。这里我选择了后者。
具体的实现和官方的TrainOneStepCell差不多,只是多了一个网络和优化器。在并行处理的地方,需要定义两个处理,分别为判别器和生成器使用。
class TrainOneStepCell(nn.Cell):
def __init__(
self,
netG: GenWithLossCell,
netD: DisWithLossCell,
optimizerG: nn.Optimizer,
optimizerD: nn.Optimizer,
sens=1.0,
auto_prefix=True,
):
super(TrainOneStepCell, self).__init__(auto_prefix=auto_prefix)
self.netG = netG
self.netG.set_grad()
self.netG.add_flags(defer_inline=True)
self.netD = netD
self.netD.set_grad()
self.netD.add_flags(defer_inline=True)
self.weights_G = optimizerG.parameters
self.optimizerG = optimizerG
self.weights_D = optimizerD.parameters
self.optimizerD = optimizerD
self.grad = C.GradOperation(get_by_list=True, sens_param=True)
self.sens = sens
# 并行处理的定义
self.reducer_flag = False
self.grad_reducer_G = F.identity
self.grad_reducer_D = F.identity
self.parallel_mode = _get_parallel_mode()
if self.parallel_mode in (ParallelMode.DATA_PARALLEL,
ParallelMode.HYBRID_PARALLEL):
self.reducer_flag = True
if self.reducer_flag:
mean = _get_gradients_mean()
degree = _get_device_num()
self.grad_reducer_G = DistributedGradReducer(
self.weights_G, mean, degree)
self.grad_reducer_D = DistributedGradReducer(
self.weights_D, mean, degree)
# 训练判别器
def trainD(self, real_data, latent_code, loss, loss_net, grad, optimizer,
weights, grad_reducer):
sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens)
grads = grad(loss_net, weights)(real_data, latent_code, sens)
grads = grad_reducer(grads)
return F.depend(loss, optimizer(grads))
# 训练生成器
def trainG(self, latent_code, loss, loss_net, grad, optimizer, weights,
grad_reducer):
sens = P.Fill()(P.DType()(loss), P.Shape()(loss), self.sens)
grads = grad(loss_net, weights)(latent_code, sens)
grads = grad_reducer(grads)
return F.depend(loss, optimizer(grads))
def construct(self, real_data, latent_code):
loss_D = self.netD(real_data, latent_code)
loss_G = self.netG(latent_code)
d_out = self.trainD(real_data, latent_code, loss_D, self.netD, self.grad,
self.optimizerD, self.weights_D,
self.grad_reducer_D)
g_out = self.trainG(latent_code, loss_G, self.netG, self.grad,
self.optimizerG, self.weights_G,
self.grad_reducer_G)
return d_out, g_out
SigmoidCrossEntropyWithLogits、WithLossCell和TrainOneStepCell是可以复用的,可以把它们写到一个单独的文件中。接下来就可以开始训练GAN了。
训练
首先定义一个能够产生服从高斯分布的数据产生器,用它来提供训练数据
class DataGenerator:
def __init__(self, mu, sigma):
self.mu = mu
self.sigma = sigma
def sample(self, N):
samples = np.random.normal(self.mu, self.sigma, size=N)
return samples
有了数据之后,就可以开始训练了。
分别定义判别器和生成器,然后使用WithLossCell将它们分别与损失相连。接着,分别为它们定义优化器。最后,定义TrainOneStepCell,开始训练。
此外,还定义了一个draw方法,用来展示GAN训练的过程。其表示的是生成数据逐渐逼近真实数据的过程。
np.random.seed(58)
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
batch_size = 256
input_dim = 1
hidden_dim = 10
steps = 20000
lr = 0.0001
netG = Generator(input_dim, hidden_dim)
netD = Discriminator(hidden_dim)
loss = SigmoidCrossEntropyWithLogits()
netG_with_loss = GenWithLossCell(netG, netD, loss)
netD_with_loss = DisWithLossCell(netG, netD, loss)
optimizerG = nn.Adam(netG.trainable_params(), lr, beta1=0.5)
optimizerD = nn.Adam(netD.trainable_params(), lr, beta1=0.5)
net_train = TrainOneStepCell(netG_with_loss, netD_with_loss, optimizerG,
optimizerD)
netG.set_train()
netD.set_train()
dataset = DataGenerator(0, 1)
for step in range(steps):
real_data = dataset.sample((batch_size, 1))
real_data = Tensor(real_data, dtype=mstype.float32)
latent_code = Tensor(np.random.uniform(low=0.0, high=1.0,size=(batch_size, input_dim)),dtype=mstype.float32)
dout, gout = net_train(real_data, latent_code)
if (step+1) % 500 == 0:
print("step {}, d_loss is {:.4f}, g_loss is {:.4f}".format(
step+1, dout.asnumpy(), gout.asnumpy()))
latent_code = Tensor(np.random.uniform(low=0.0, high=1.0,size=(batch_size, input_dim)),dtype=mstype.float32)
gen_data = netG(latent_code).asnumpy()
draw(gen_data,step+1)
# 高斯分布概率密度函数
def normfun(x, mu, sigma):
return np.exp(-((x - mu)**2) / (2 * sigma**2)) / (sigma * np.sqrt(2 * np.pi))
def draw(gen_data, step):
x = np.arange(-5, 5, 0.2)
y = normfun(x, 0, 1)
plt.plot(x, y, 'r', linewidth=3)
mean = gen_data.mean()
std = gen_data.std()
y = normfun(x, mean, std)
plt.plot(x, y, 'b', linewidth=3)
plt.xlabel('value')
plt.ylabel('Probability')
plt.savefig("./images/step{}.png".format(step))
plt.clf()
下面是训练的结果,红色图像是真实分布,蓝色图像是生成分布:
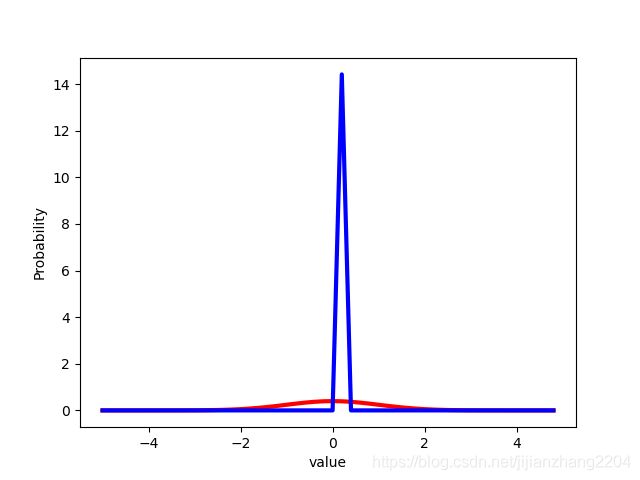
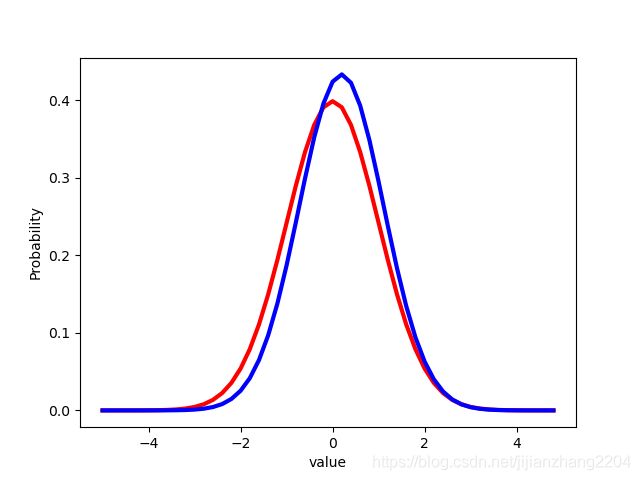
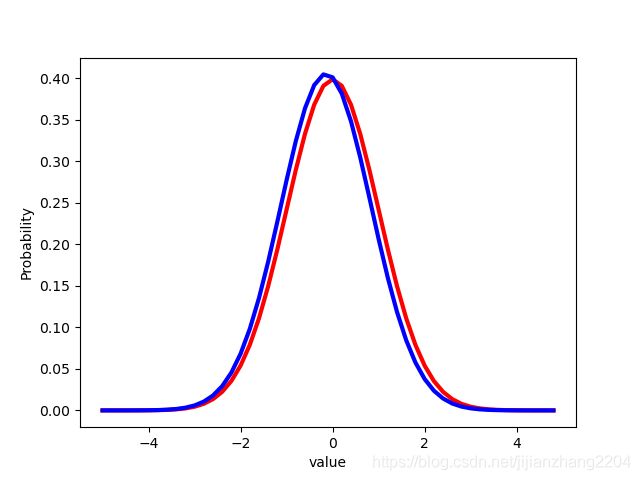
一个简单的GAN的实现到这里就结束了。实现中的重点在于WithLossCell的定义,也就是得将Loss和网络手动连接到一起,使得多输出的网络变为单输出的,从而使得训练能够进行。有了这几个模块,接下来要实现的DCGAN和CGAN都将变得比较简单。