【学习笔记】K-Means聚类算法
目录
- 所属知识体系
- 思想
- 相关概念
- 算法流程
- 代码实现
- k值的选取
- 初始中心点的选取
- K-Means缺点
- 参考文章
- 参考文献
所属知识体系
K-Means聚类算法∈无监督学习算法∈机器学习
思想
将相似的对象归到同一个簇中,根据样本之间的距离或者说是相似性(亲疏性),把越相似、差异越小的样本聚成一类(簇),最后形成多个簇,使同一个簇内部的样本相似度高,不同簇之间差异性高。
相关概念
K值——要得到的簇的个数
质心——每个簇的均值向量,即向量各维取平均即可
距离量度——常用欧几里得距离和余弦相似度(先标准化)
算法流程
1、首先确定一个k值,即我们希望将数据集经过聚类得到k个集合。
2、从数据集中随机选择k个数据点作为质心。
3、对数据集中每一个点,计算其与每一个质心的距离(如欧式距离),离哪个质心近,就划分到那个质心所属的集合。
4、把所有数据归好集合后,一共有k个集合。然后重新计算每个集合的质心。
5、如果新计算出来的质心和原来的质心之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),我们可以认为聚类已经达到期望的结果,算法终止。
6、如果新质心和原质心距离变化很大,需要迭代3~5步骤。
代码实现
运行结果见参考文章:
数据挖掘十大算法(二):K-means聚类算法原理与实现
# K-means Algorithm is a clustering algorithm
import numpy as np
import matplotlib.pyplot as plt
import random
def get_distance(p1, p2):
diff = [x - y for x, y in zip(p1, p2)]
distance = np.sqrt(sum(map(lambda x: x ** 2, diff)))
return distance
# 计算多个点的中心
# cluster = [[1,2,3], [-2,1,2], [9, 0 ,4], [2,10,4]]
def calc_center_point(cluster):
N = len(cluster)
m = np.matrix(cluster).transpose().tolist()
center_point = [sum(x) / N for x in m]
return center_point
# 检查两个点是否有差别
def check_center_diff(center, new_center):
n = len(center)
for c, nc in zip(center, new_center):
if c != nc:
return False
return True
# K-means算法的实现
def K_means(points, center_points):
N = len(points) # 样本个数
n = len(points[0]) # 单个样本的维度
k = len(center_points) # k值大小
tot = 0
while True: # 迭代
temp_center_points = [] # 记录中心点
clusters = [] # 记录聚类的结果
for c in range(0, k):
clusters.append([]) # 初始化
# 针对每个点,寻找距离其最近的中心点(寻找组织)
for i, data in enumerate(points):
distances = []
for center_point in center_points:
distances.append(get_distance(data, center_point))
index = distances.index(min(distances)) # 找到最小的距离的那个中心点的索引,
clusters[index].append(data) # 那么这个中心点代表的簇,里面增加一个样本
tot += 1
print(tot, '次迭代 ', clusters)
k = len(clusters)
colors = ['r.', 'g.', 'b.', 'k.', 'y.'] # 颜色和点的样式
for i, cluster in enumerate(clusters):
data = np.array(cluster)
data_x = [x[0] for x in data]
data_y = [x[1] for x in data]
plt.subplot(2, 3, tot)
plt.plot(data_x, data_y, colors[i])
plt.axis([0, 1000, 0, 1000])
# 重新计算中心点(该步骤可以与下面判断中心点是否发生变化这个步骤,调换顺序)
for cluster in clusters:
temp_center_points.append(calc_center_point(cluster))
# 在计算中心点的时候,需要将原来的中心点算进去
for j in range(0, k):
if len(clusters[j]) == 0:
temp_center_points[j] = center_points[j]
# 判断中心点是否发生变化:即,判断聚类前后样本的类别是否发生变化
for c, nc in zip(center_points, temp_center_points):
if not check_center_diff(c, nc):
center_points = temp_center_points[:] # 复制一份
break
else: # 如果没有变化,那么退出迭代,聚类结束
break
plt.show()
return clusters # 返回聚类的结果
# 随机获取一个样本集,用于测试K-means算法
def get_test_data():
N = 1000
# 产生点的区域
area_1 = [0, N / 4, N / 4, N / 2]
area_2 = [N / 2, 3 * N / 4, 0, N / 4]
area_3 = [N / 4, N / 2, N / 2, 3 * N / 4]
area_4 = [3 * N / 4, N, 3 * N / 4, N]
area_5 = [3 * N / 4, N, N / 4, N / 2]
areas = [area_1, area_2, area_3, area_4, area_5]
k = len(areas)
# 在各个区域内,随机产生一些点
points = []
for area in areas:
rnd_num_of_points = random.randint(50, 200)
for r in range(0, rnd_num_of_points):
rnd_add = random.randint(0, 100)
rnd_x = random.randint(area[0] + rnd_add, area[1] - rnd_add)
rnd_y = random.randint(area[2], area[3] - rnd_add)
points.append([rnd_x, rnd_y])
# 自定义中心点,目标聚类个数为5,因此选定5个中心点
center_points = [[0, 250], [500, 500], [500, 250], [500, 250], [500, 750]]
return points, center_points
if __name__ == '__main__':
points, center_points = get_test_data()
clusters = K_means(points, center_points)
print('#######最终结果##########')
for i, cluster in enumerate(clusters):
print('cluster ', i, ' ', cluster)
k值的选取
在面对实际的数据时,我们并不知道数据应该聚成几类(实际中我们是不太可能看得到高维数据有很明显的分割的)。
在论文[1]中,就用一个最简单的指标——sum of squared error (SSE)组内平方误差和来确定最佳聚类数目。
计算公式如下:
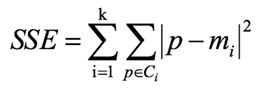
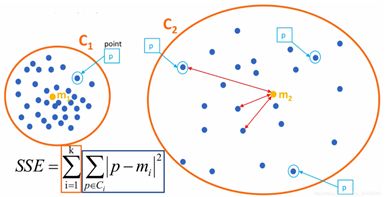
根据上图,p表示簇中的点,m表示该簇的中心点,求出所有簇的组内误差平方和之后再求和即可得到SSE,又叫做WSS方法。
一般k不会很大,大概在2~10之间,因此可以作出这个范围内的SSE-k的曲线,再选择一个拐点,作为合适的k值。怎么才算合适呢?
论文[1]中给出了一个曲线:
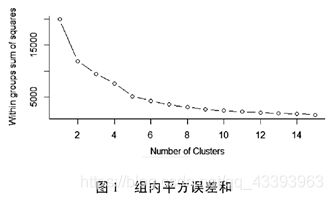
“从图1 看出,当K 值大于5 时,随着K 值的增大,类中总的平方值对聚类数量的曲线趋于平缓,表明进一步增大聚类数聚类效果也并不能增强,因此确定最佳聚类数为5.”
初始中心点的选取
一般来说,初始中心点的选取是随机的,但是不同初始中心点,会导致聚类的效果不同。一个原则是:初始中心点之间的间距应该较大。因此,可以采取的策略是:
step1:计算所有样本点之间的距离,选择距离最大的一个点对(两个样本C1, C2)作为2个初始中心点,从样本点集中去掉这两个点。
step2:如果初始中心点个数达到k个,则终止。如果没有,在剩余的样本点中,选一个点C3,这个点优化的目标是:max { min { |C3-C1| ,|C3-C2| } }
即选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点,以此类推,直至选出K个初始类簇中心点。
K-Means缺点
1、需要确定K的值。K的取值需要事先确定,然而在无监督聚类任务上,由于并不知道数据集究竟有多少类别,所以很难确定K的取值。
2、对异常点敏感。K-Means很容易受到异常点(outliers)的影响,由于K-Means在更新时取的是簇内样本均值,那么就会很容易受到异常点的影响,比如某个簇内样本在某个维度上的值特别大,这就使得聚簇中心偏向于异常点,从而导致不太好的聚类效果。
3、凸形聚类。K-Means由于采用欧氏距离来衡量样本之间相似度,所以得到的聚簇都是凸的,就不能解决“S型”数据分布的聚类,这就使得K-Means的应用范围受限,难以发现数据集中一些非凸的性质。
4、聚簇中心初始化,收敛到局部最优,未考虑密度分布等等。
参考文章
K-Means聚类算法:
https://www.jianshu.com/p/4f032dccdcef
无监督学习K-means聚类算法笔记-Python:
https://www.jianshu.com/p/bbfafb4454be
机器学习中 K近邻法(knn)与k-means的区别:
https://www.cnblogs.com/PiPifamily/p/8520405.html
数据挖掘十大算法(二):K-means聚类算法原理与实现:
https://blog.csdn.net/ten_sory/article/details/81016748
四种常用聚类及代码(一):K-Means:
https://blog.csdn.net/weixin_43526820/article/details/89493751
简单粗暴理解与实现机器学习之聚类算法(四):
https://blog.csdn.net/qq_35456045/article/details/104645015
参考文献
[1] 唐慧祥,常啸,宋来敏.基于数据挖掘的淘宝精准营销策略研究[J].哈尔滨师范大学自然科学学报,2020,36(03):19-24.